 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Relatedly: Scaffolding Literature Reviews with Existing Related Work Sections
Feb 13, 2023
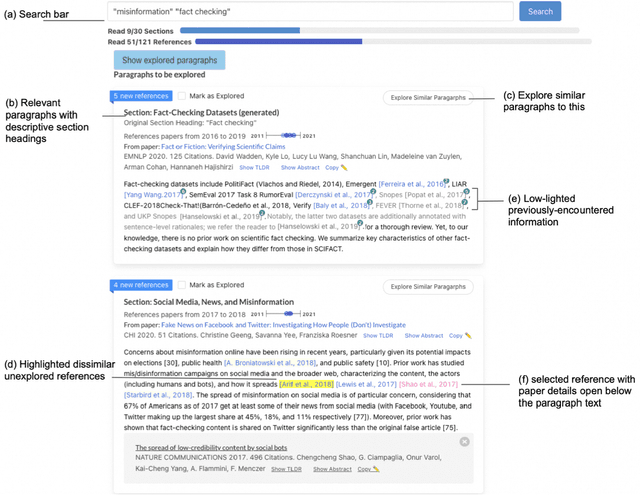

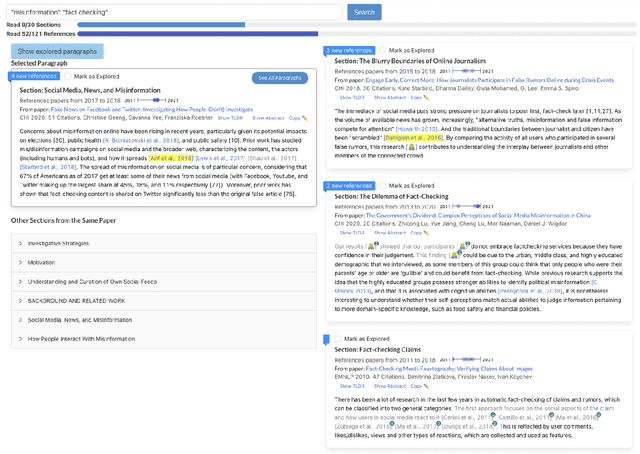
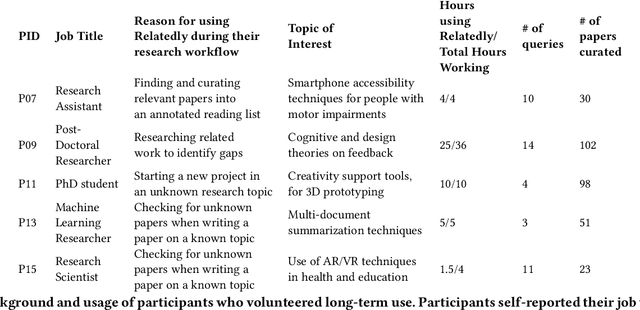
Scholars who want to research a scientific topic must take time to read, extract meaning, and identify connections across many papers. As scientific literature grows, this becomes increasingly challenging. Meanwhile, authors summarize prior research in papers' related work sections, though this is scoped to support a single paper. A formative study found that while reading multiple related work paragraphs helps overview a topic, it is hard to navigate overlapping and diverging references and research foci. In this work, we design a system, Relatedly, that scaffolds exploring and reading multiple related work paragraphs on a topic, with features including dynamic re-ranking and highlighting to spotlight unexplored dissimilar information, auto-generated descriptive paragraph headings, and low-lighting of redundant information. From a within-subjects user study (n=15), we found that scholars generate more coherent, insightful, and comprehensive topic outlines using Relatedly compared to a baseline paper list.
Dataset of Natural Language Queries for E-Commerce
Feb 13, 2023
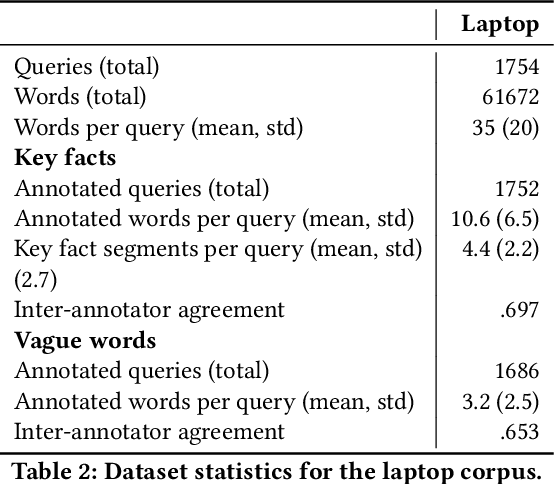
Shopping online is more and more frequent in our everyday life. For e-commerce search systems, understanding natural language coming through voice assistants, chatbots or from conversational search is an essential ability to understand what the user really wants. However, evaluation datasets with natural and detailed information needs of product-seekers which could be used for research do not exist. Due to privacy issues and competitive consequences, only few datasets with real user search queries from logs are openly available. In this paper, we present a dataset of 3,540 natural language queries in two domains that describe what users want when searching for a laptop or a jacket of their choice. The dataset contains annotations of vague terms and key facts of 1,754 laptop queries. This dataset opens up a range of research opportunities in the fields of natural language processing and (interactive) information retrieval for product search.
Multi-Source Soft Pseudo-Label Learning with Domain Similarity-based Weighting for Semantic Segmentation
Mar 02, 2023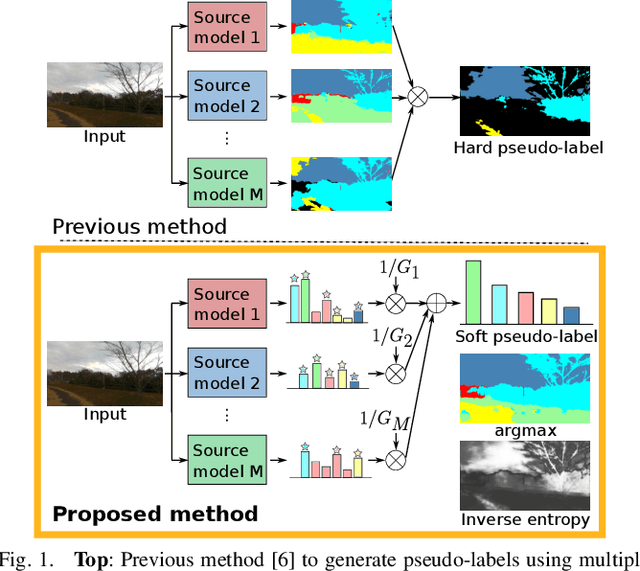
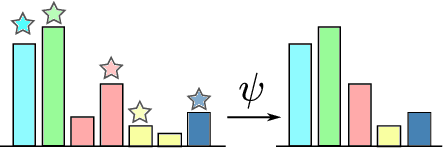
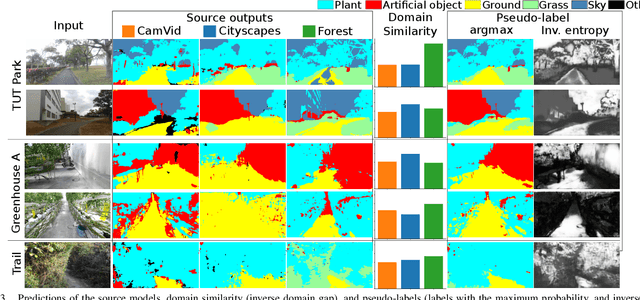
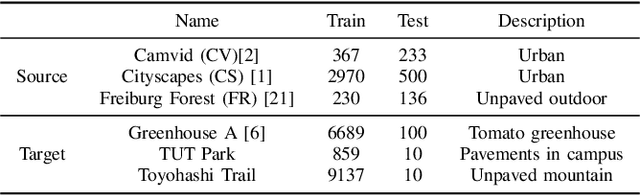
This paper describes a method of domain adaptive training for semantic segmentation using multiple source datasets that are not necessarily relevant to the target dataset. We propose a soft pseudo-label generation method by integrating predicted object probabilities from multiple source models. The prediction of each source model is weighted based on the estimated domain similarity between the source and the target datasets to emphasize contribution of a model trained on a source that is more similar to the target and generate reasonable pseudo-labels. We also propose a training method using the soft pseudo-labels considering their entropy to fully exploit information from the source datasets while suppressing the influence of possibly misclassified pixels. The experiments show comparative or better performance than our previous work and another existing multi-source domain adaptation method, and applicability to a variety of target environments.
Matching-based Term Semantics Pre-training for Spoken Patient Query Understanding
Mar 02, 2023
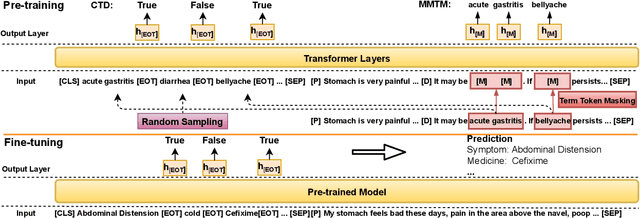
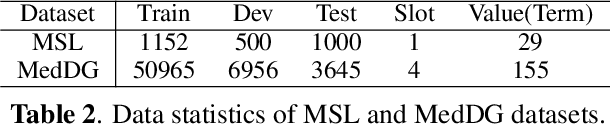
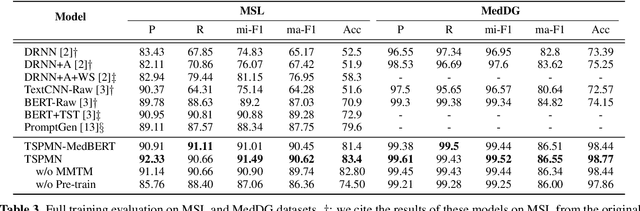
Medical Slot Filling (MSF) task aims to convert medical queries into structured information, playing an essential role in diagnosis dialogue systems. However, the lack of sufficient term semantics learning makes existing approaches hard to capture semantically identical but colloquial expressions of terms in medical conversations. In this work, we formalize MSF into a matching problem and propose a Term Semantics Pre-trained Matching Network (TSPMN) that takes both terms and queries as input to model their semantic interaction. To learn term semantics better, we further design two self-supervised objectives, including Contrastive Term Discrimination (CTD) and Matching-based Mask Term Modeling (MMTM). CTD determines whether it is the masked term in the dialogue for each given term, while MMTM directly predicts the masked ones. Experimental results on two Chinese benchmarks show that TSPMN outperforms strong baselines, especially in few-shot settings.
Attention-based Graph Convolution Fusing Latent Structures and Multiple Features for Graph Neural Networks
Mar 03, 2023
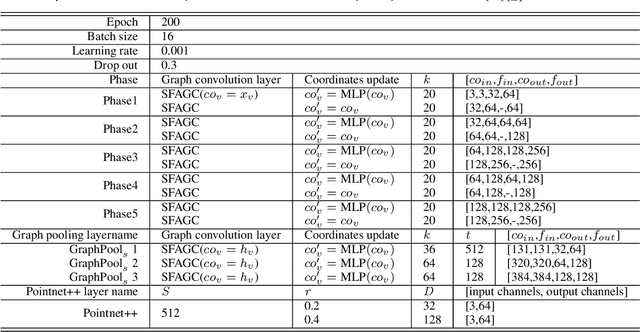
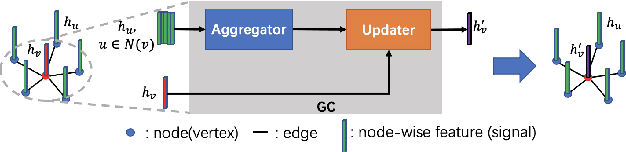
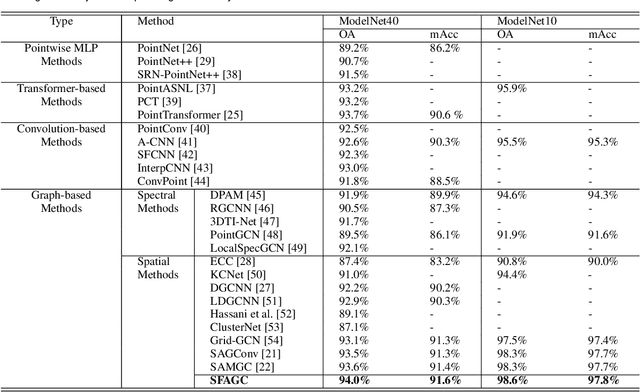
We present an attention-based spatial graph convolution (AGC) for graph neural networks (GNNs). Existing AGCs focus on only using node-wise features and utilizing one type of attention function when calculating attention weights. Instead, we propose two methods to improve the representational power of AGCs by utilizing 1) structural information in a high-dimensional space and 2) multiple attention functions when calculating their weights. The first method computes a local structure representation of a graph in a high-dimensional space. The second method utilizes multiple attention functions simultaneously in one AGC. Both approaches can be combined. We also propose a GNN for the classification of point clouds and that for the prediction of point labels in a point cloud based on the proposed AGC. According to experiments, the proposed GNNs perform better than existing methods. Our codes open at https://github.com/liyang-tuat/SFAGC.
Fine-Grained ImageNet Classification in the Wild
Mar 04, 2023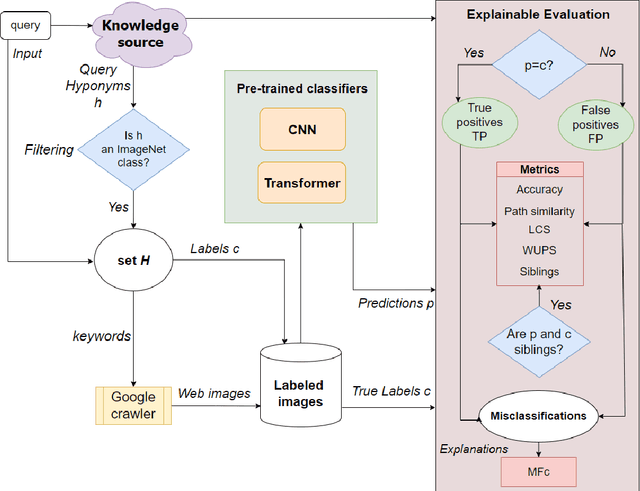
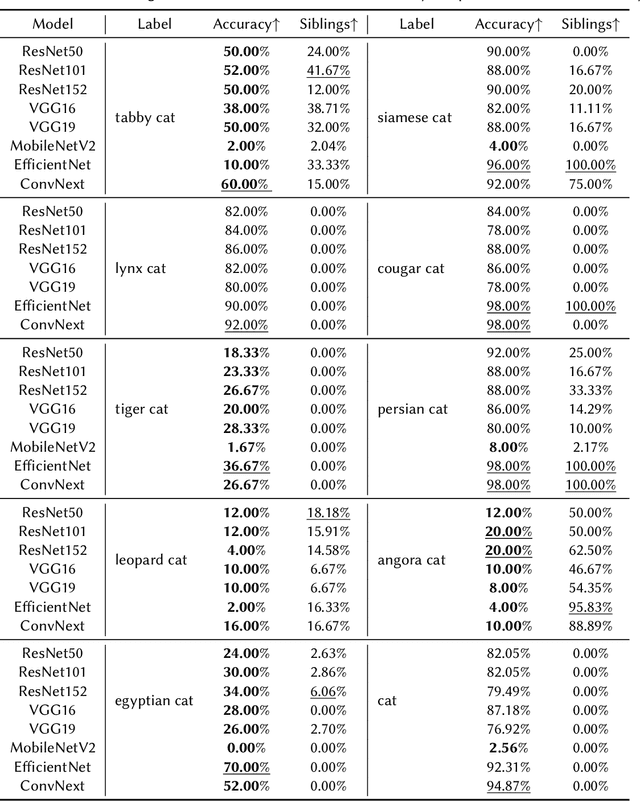
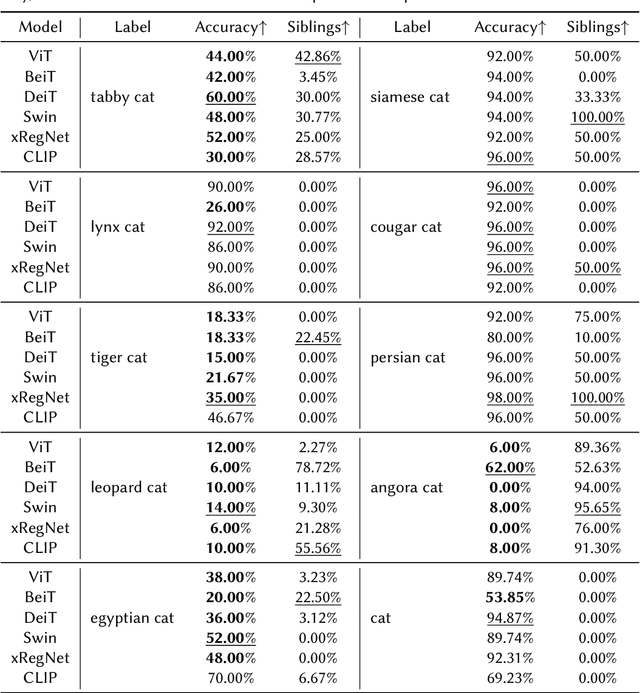
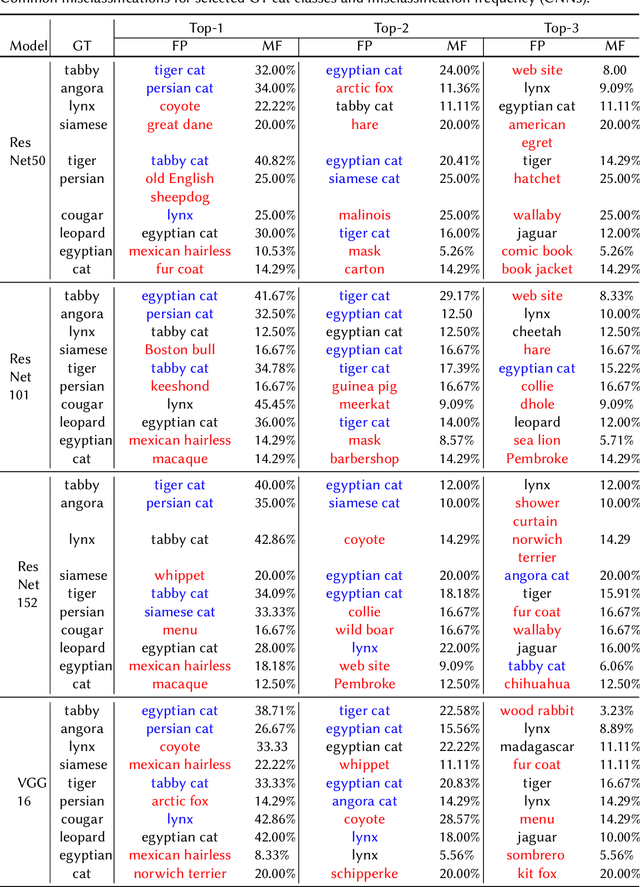
Image classification has been one of the most popular tasks in Deep Learning, seeing an abundance of impressive implementations each year. However, there is a lot of criticism tied to promoting complex architectures that continuously push performance metrics higher and higher. Robustness tests can uncover several vulnerabilities and biases which go unnoticed during the typical model evaluation stage. So far, model robustness under distribution shifts has mainly been examined within carefully curated datasets. Nevertheless, such approaches do not test the real response of classifiers in the wild, e.g. when uncurated web-crawled image data of corresponding classes are provided. In our work, we perform fine-grained classification on closely related categories, which are identified with the help of hierarchical knowledge. Extensive experimentation on a variety of convolutional and transformer-based architectures reveals model robustness in this novel setting. Finally, hierarchical knowledge is again employed to evaluate and explain misclassifications, providing an information-rich evaluation scheme adaptable to any classifier.
Tagging before Alignment: Integrating Multi-Modal Tags for Video-Text Retrieval
Jan 30, 2023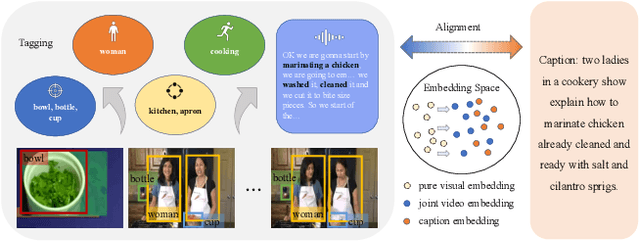
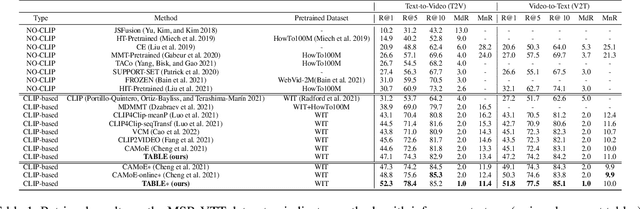
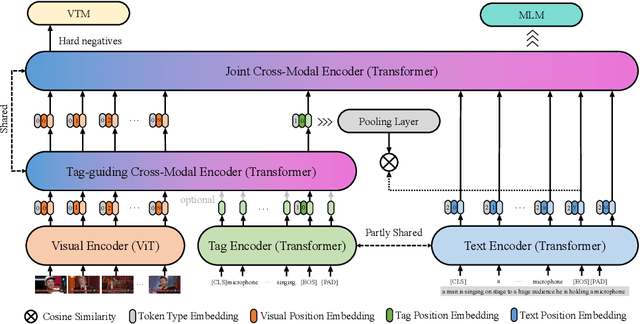
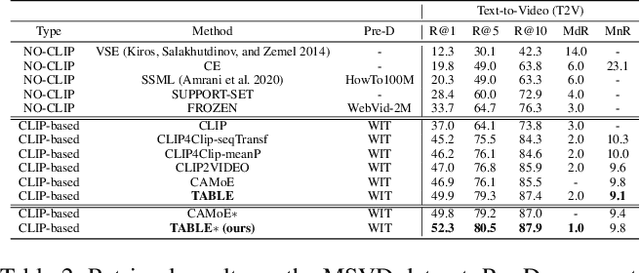
Vision-language alignment learning for video-text retrieval arouses a lot of attention in recent years. Most of the existing methods either transfer the knowledge of image-text pretraining model to video-text retrieval task without fully exploring the multi-modal information of videos, or simply fuse multi-modal features in a brute force manner without explicit guidance. In this paper, we integrate multi-modal information in an explicit manner by tagging, and use the tags as the anchors for better video-text alignment. Various pretrained experts are utilized for extracting the information of multiple modalities, including object, person, motion, audio, etc. To take full advantage of these information, we propose the TABLE (TAgging Before aLignmEnt) network, which consists of a visual encoder, a tag encoder, a text encoder, and a tag-guiding cross-modal encoder for jointly encoding multi-frame visual features and multi-modal tags information. Furthermore, to strengthen the interaction between video and text, we build a joint cross-modal encoder with the triplet input of [vision, tag, text] and perform two additional supervised tasks, Video Text Matching (VTM) and Masked Language Modeling (MLM). Extensive experimental results demonstrate that the TABLE model is capable of achieving State-Of-The-Art (SOTA) performance on various video-text retrieval benchmarks, including MSR-VTT, MSVD, LSMDC and DiDeMo.
Human-Centric Multimodal Machine Learning: Recent Advances and Testbed on AI-based Recruitment
Feb 13, 2023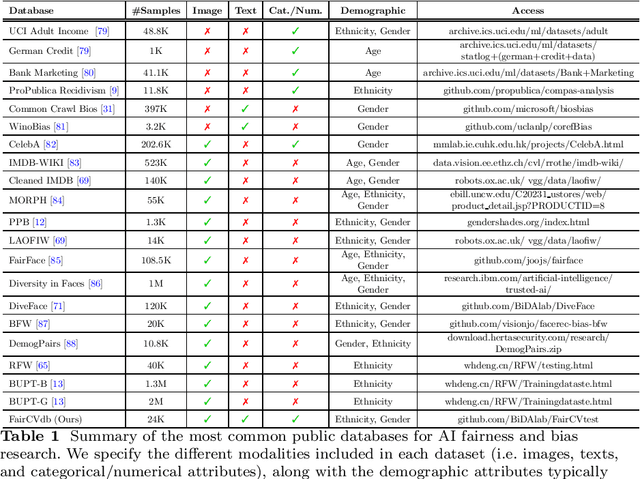
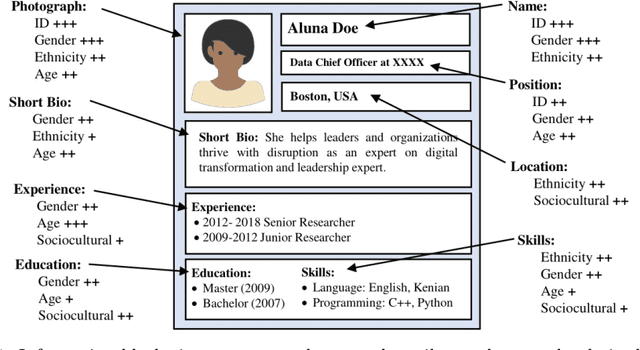
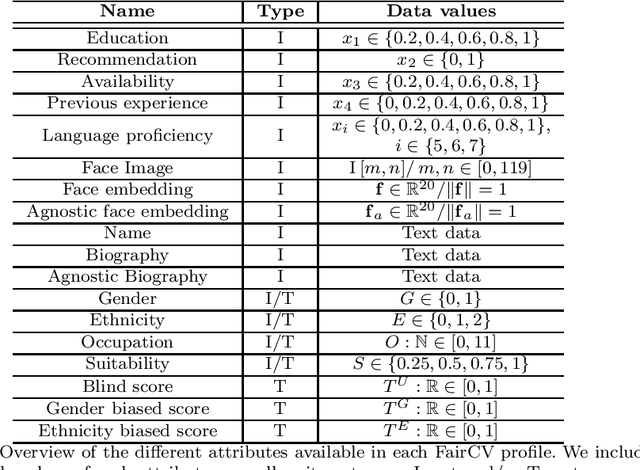

The presence of decision-making algorithms in society is rapidly increasing nowadays, while concerns about their transparency and the possibility of these algorithms becoming new sources of discrimination are arising. There is a certain consensus about the need to develop AI applications with a Human-Centric approach. Human-Centric Machine Learning needs to be developed based on four main requirements: (i) utility and social good; (ii) privacy and data ownership; (iii) transparency and accountability; and (iv) fairness in AI-driven decision-making processes. All these four Human-Centric requirements are closely related to each other. With the aim of studying how current multimodal algorithms based on heterogeneous sources of information are affected by sensitive elements and inner biases in the data, we propose a fictitious case study focused on automated recruitment: FairCVtest. We train automatic recruitment algorithms using a set of multimodal synthetic profiles including image, text, and structured data, which are consciously scored with gender and racial biases. FairCVtest shows the capacity of the Artificial Intelligence (AI) behind automatic recruitment tools built this way (a common practice in many other application scenarios beyond recruitment) to extract sensitive information from unstructured data and exploit it in combination to data biases in undesirable (unfair) ways. We present an overview of recent works developing techniques capable of removing sensitive information and biases from the decision-making process of deep learning architectures, as well as commonly used databases for fairness research in AI. We demonstrate how learning approaches developed to guarantee privacy in latent spaces can lead to unbiased and fair automatic decision-making process.
PointPatchMix: Point Cloud Mixing with Patch Scoring
Mar 12, 2023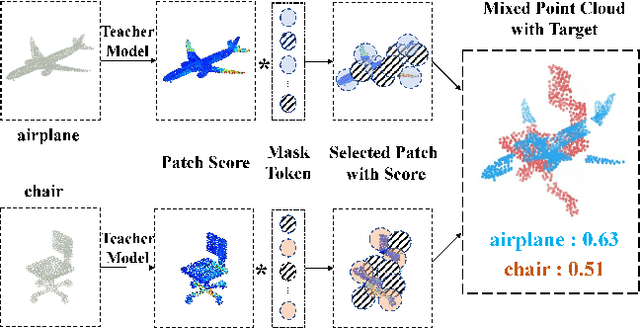
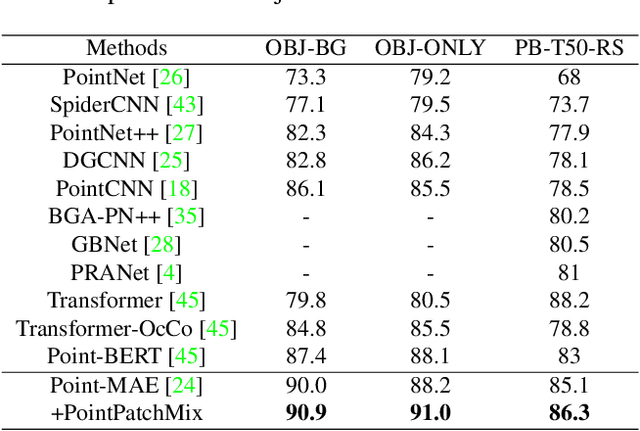
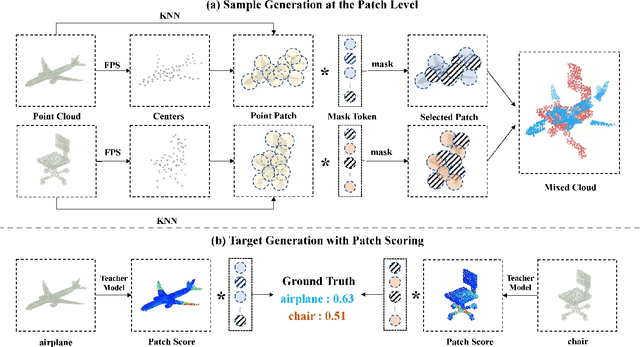
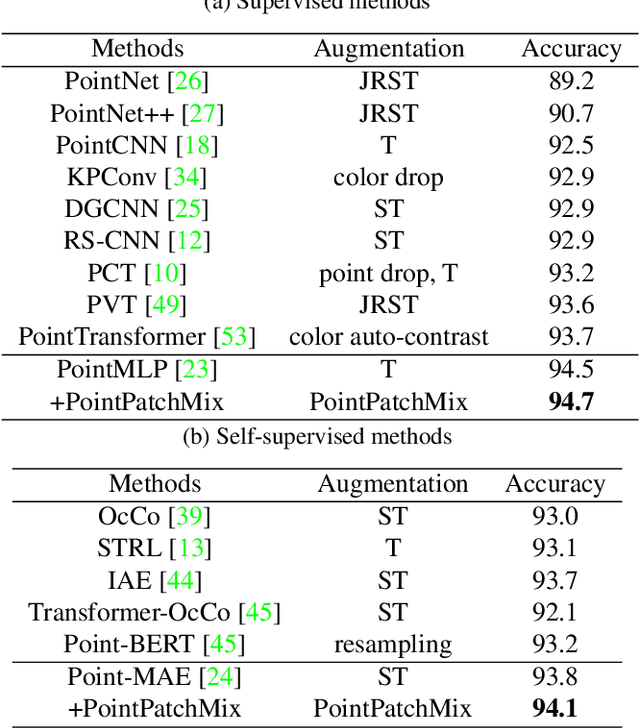
Data augmentation is an effective regularization strategy for mitigating overfitting in deep neural networks, and it plays a crucial role in 3D vision tasks, where the point cloud data is relatively limited. While mixing-based augmentation has shown promise for point clouds, previous methods mix point clouds either on block level or point level, which has constrained their ability to strike a balance between generating diverse training samples and preserving the local characteristics of point clouds. Additionally, the varying importance of each part of the point clouds has not been fully considered, cause not all parts contribute equally to the classification task, and some parts may contain unimportant or redundant information. To overcome these challenges, we propose PointPatchMix, a novel approach that mixes point clouds at the patch level and integrates a patch scoring module to generate content-based targets for mixed point clouds. Our approach preserves local features at the patch level, while the patch scoring module assigns targets based on the content-based significance score from a pre-trained teacher model. We evaluate PointPatchMix on two benchmark datasets, ModelNet40 and ScanObjectNN, and demonstrate significant improvements over various baselines in both synthetic and real-world datasets, as well as few-shot settings. With Point-MAE as our baseline, our model surpasses previous methods by a significant margin, achieving 86.3% accuracy on ScanObjectNN and 94.1% accuracy on ModelNet40. Furthermore, our approach shows strong generalization across multiple architectures and enhances the robustness of the baseline model.
Finite Littlestone Dimension Implies Finite Information Complexity
Jun 27, 2022We prove that every online learnable class of functions of Littlestone dimension $d$ admits a learning algorithm with finite information complexity. Towards this end, we use the notion of a globally stable algorithm. Generally, the information complexity of such a globally stable algorithm is large yet finite, roughly exponential in $d$. We also show there is room for improvement; for a canonical online learnable class, indicator functions of affine subspaces of dimension $d$, the information complexity can be upper bounded logarithmically in $d$.