 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset of Natural Language Queries for E-Commerce
Feb 13, 2023Shopping online is more and more frequent in our everyday life. For e-commerce search systems, understanding natural language coming through voice assistants, chatbots or from conversational search is an essential ability to understand what the user really wants. However, evaluation datasets with natural and detailed information needs of product-seekers which could be used for research do not exist. Due to privacy issues and competitive consequences, only few datasets with real user search queries from logs are openly available. In this paper, we present a dataset of 3,540 natural language queries in two domains that describe what users want when searching for a laptop or a jacket of their choice. The dataset contains annotations of vague terms and key facts of 1,754 laptop queries. This dataset opens up a range of research opportunities in the fields of natural language processing and (interactive) information retrieval for product search.
Starting Conversations with Search Engines -- Interfaces that Elicit Natural Language Queries
Feb 13, 2023


Search systems on the Web rely on user input to generate relevant results. Since early information retrieval systems, users are trained to issue keyword searches and adapt to the language of the system. Recent research has shown that users often withhold detailed information about their initial information need, although they are able to express it in natural language. We therefore conduct a user study (N = 139) to investigate how four different design variants of search interfaces can encourage the user to reveal more information. Our results show that a chatbot-inspired search interface can increase the number of mentioned product attributes by 84% and promote natural language formulations by 139% in comparison to a standard search bar interface.
Categorising Fine-to-Coarse Grained Misinformation: An Empirical Study of COVID-19 Infodemic
Jul 08, 2021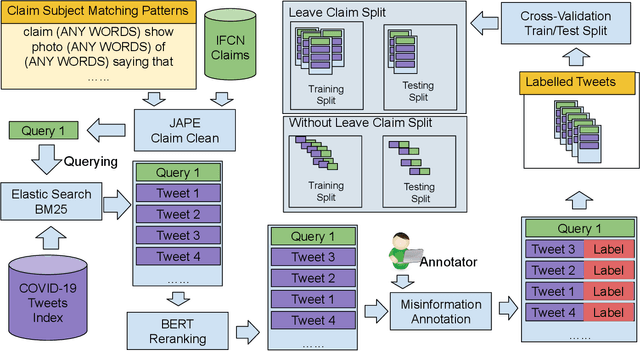
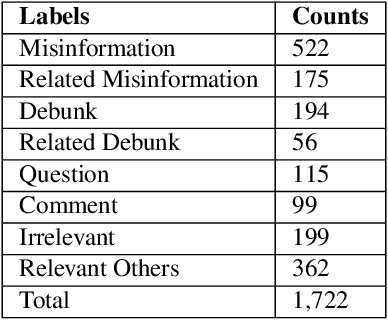
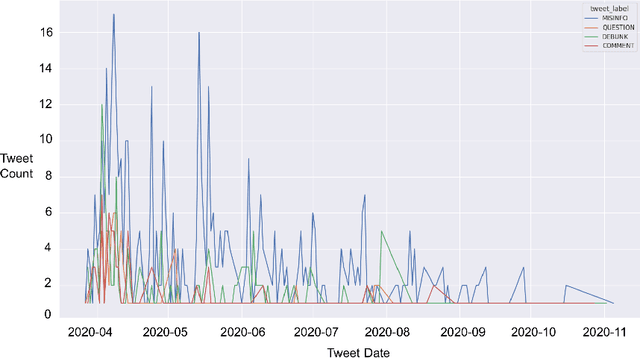
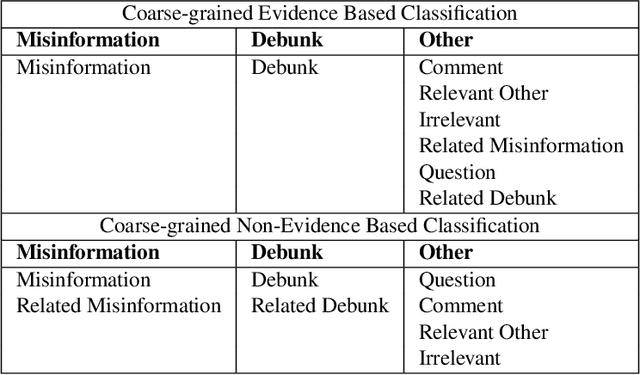
The spreading COVID-19 misinformation over social media already draws the attention of many researchers. According to Google Scholar, about 26000 COVID-19 related misinformation studies have been published to date. Most of these studies focusing on 1) detect and/or 2) analysing the characteristics of COVID-19 related misinformation. However, the study of the social behaviours related to misinformation is often neglected. In this paper, we introduce a fine-grained annotated misinformation tweets dataset including social behaviours annotation (e.g. comment or question to the misinformation). The dataset not only allows social behaviours analysis but also suitable for both evidence-based or non-evidence-based misinformation classification task. In addition, we introduce leave claim out validation in our experiments and demonstrate the misinformation classification performance could be significantly different when applying to real-world unseen misinformation.
Detection and Resolution of Rumours in Social Media: A Survey
Apr 03, 2018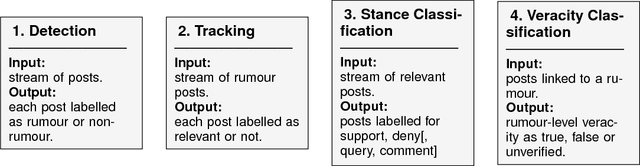
Despite the increasing use of social media platforms for information and news gathering, its unmoderated nature often leads to the emergence and spread of rumours, i.e. pieces of information that are unverified at the time of posting. At the same time, the openness of social media platforms provides opportunities to study how users share and discuss rumours, and to explore how natural language processing and data mining techniques may be used to find ways of determining their veracity. In this survey we introduce and discuss two types of rumours that circulate on social media; long-standing rumours that circulate for long periods of time, and newly-emerging rumours spawned during fast-paced events such as breaking news, where reports are released piecemeal and often with an unverified status in their early stages. We provide an overview of research into social media rumours with the ultimate goal of developing a rumour classification system that consists of four components: rumour detection, rumour tracking, rumour stance classification and rumour veracity classification. We delve into the approaches presented in the scientific literature for the development of each of these four components. We summarise the efforts and achievements so far towards the development of rumour classification systems and conclude with suggestions for avenues for future research in social media mining for detection and resolution of rumours.
* ACM Computing Surveys
Simple Open Stance Classification for Rumour Analysis
Sep 14, 2017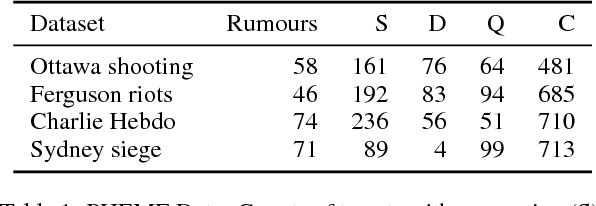
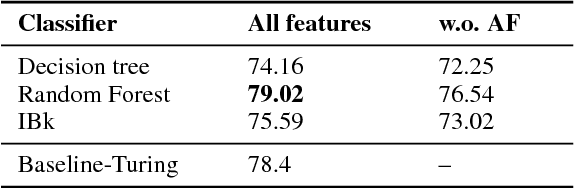


Stance classification determines the attitude, or stance, in a (typically short) text. The task has powerful applications, such as the detection of fake news or the automatic extraction of attitudes toward entities or events in the media. This paper describes a surprisingly simple and efficient classification approach to open stance classification in Twitter, for rumour and veracity classification. The approach profits from a novel set of automatically identifiable problem-specific features, which significantly boost classifier accuracy and achieve above state-of-the-art results on recent benchmark datasets. This calls into question the value of using complex sophisticated models for stance classification without first doing informed feature extraction.
Gold Standard Online Debates Summaries and First Experiments Towards Automatic Summarization of Online Debate Data
Aug 15, 2017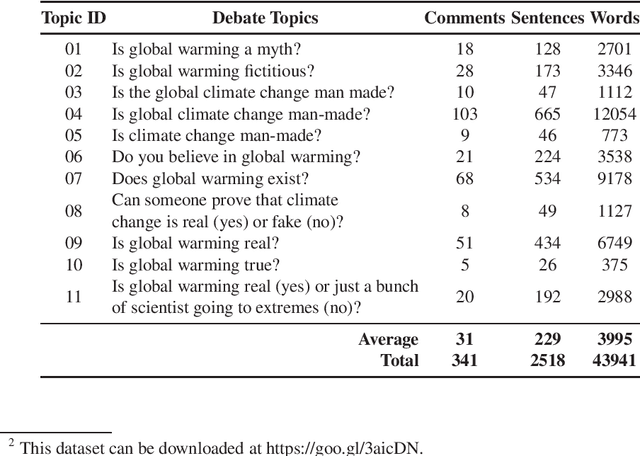
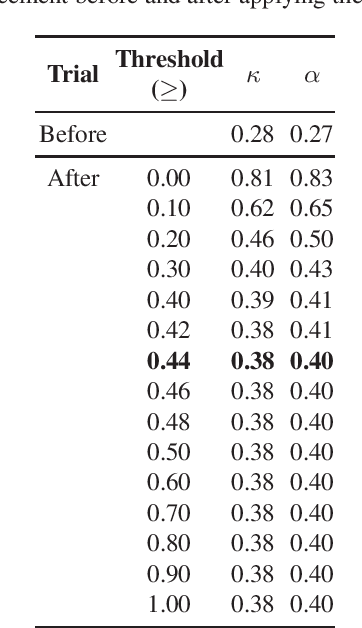

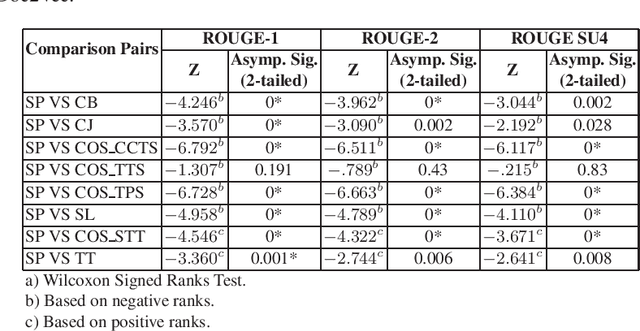
Usage of online textual media is steadily increasing. Daily, more and more news stories, blog posts and scientific articles are added to the online volumes. These are all freely accessible and have been employed extensively in multiple research areas, e.g. automatic text summarization, information retrieval, information extraction, etc. Meanwhile, online debate forums have recently become popular, but have remained largely unexplored. For this reason, there are no sufficient resources of annotated debate data available for conducting research in this genre. In this paper, we collected and annotated debate data for an automatic summarization task. Similar to extractive gold standard summary generation our data contains sentences worthy to include into a summary. Five human annotators performed this task. Inter-annotator agreement, based on semantic similarity, is 36% for Cohen's kappa and 48% for Krippendorff's alpha. Moreover, we also implement an extractive summarization system for online debates and discuss prominent features for the task of summarizing online debate data automatically.
Automatic Summarization of Online Debates
Aug 15, 2017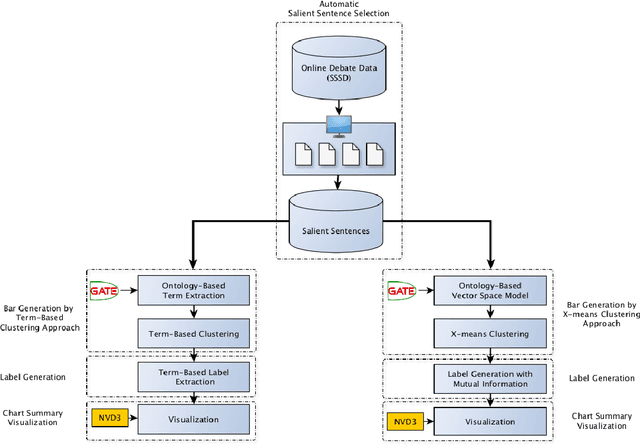

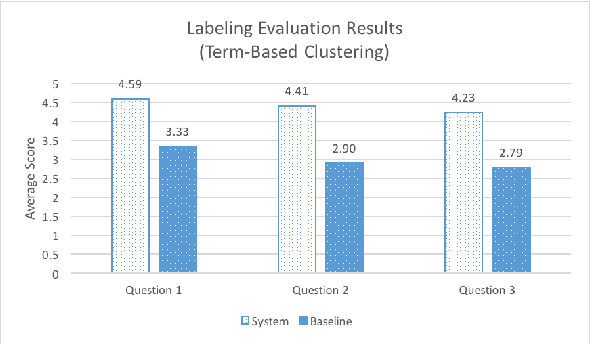

Debate summarization is one of the novel and challenging research areas in automatic text summarization which has been largely unexplored. In this paper, we develop a debate summarization pipeline to summarize key topics which are discussed or argued in the two opposing sides of online debates. We view that the generation of debate summaries can be achieved by clustering, cluster labeling, and visualization. In our work, we investigate two different clustering approaches for the generation of the summaries. In the first approach, we generate the summaries by applying purely term-based clustering and cluster labeling. The second approach makes use of X-means for clustering and Mutual Information for labeling the clusters. Both approaches are driven by ontologies. We visualize the results using bar charts. We think that our results are a smooth entry for users aiming to receive the first impression about what is discussed within a debate topic containing waste number of argumentations.