 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GazeMotion: Gaze-guided Human Motion Forecasting
Mar 14, 2024
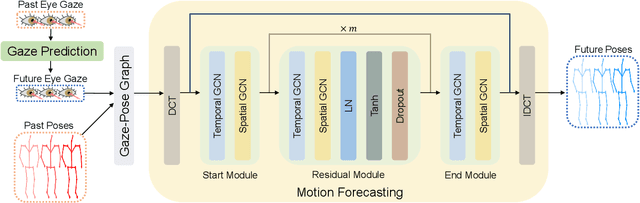
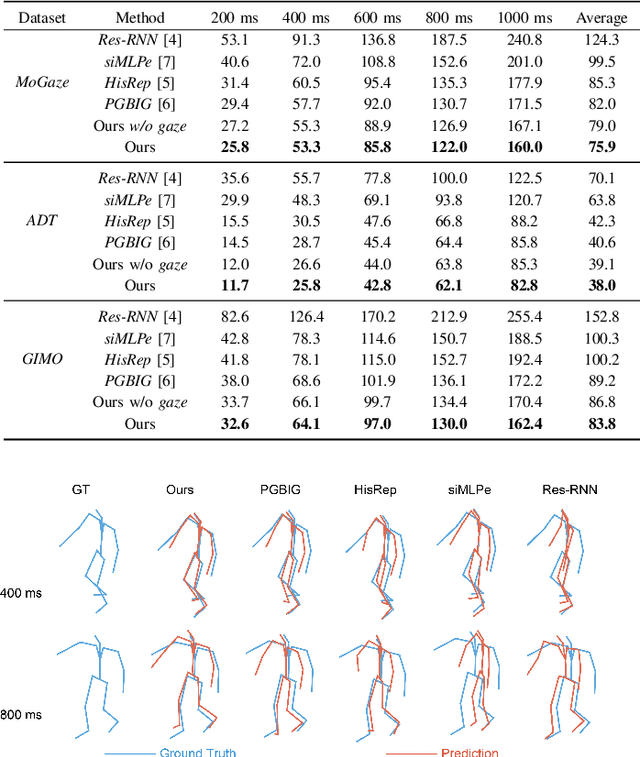
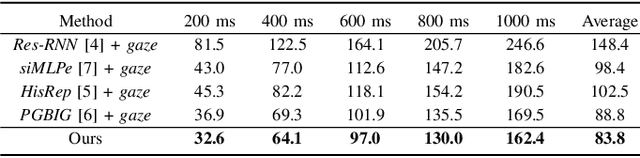
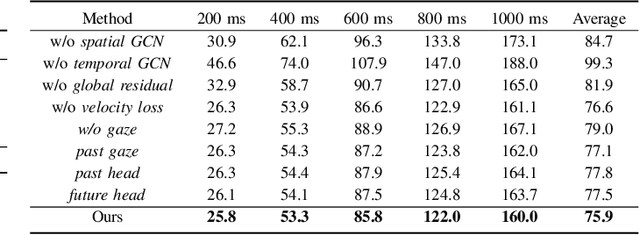
We present GazeMotion, a novel method for human motion forecasting that combines information on past human poses with human eye gaze. Inspired by evidence from behavioural sciences showing that human eye and body movements are closely coordinated, GazeMotion first predicts future eye gaze from past gaze, then fuses predicted future gaze and past poses into a gaze-pose graph, and finally uses a residual graph convolutional network to forecast body motion. We extensively evaluate our method on the MoGaze, ADT, and GIMO benchmark datasets and show that it outperforms state-of-the-art methods by up to 7.4% improvement in mean per joint position error. Using head direction as a proxy to gaze, our method still achieves an average improvement of 5.5%. We finally report an online user study showing that our method also outperforms prior methods in terms of perceived realism. These results show the significant information content available in eye gaze for human motion forecasting as well as the effectiveness of our method in exploiting this information.
Learning under Singularity: An Information Criterion improving WBIC and sBIC
Feb 22, 2024We introduce a novel Information Criterion (IC), termed Learning under Singularity (LS), designed to enhance the functionality of the Widely Applicable Bayes Information Criterion (WBIC) and the Singular Bayesian Information Criterion (sBIC). LS is effective without regularity constraints and demonstrates stability. Watanabe defined a statistical model or a learning machine as regular if the mapping from a parameter to a probability distribution is one-to-one and its Fisher information matrix is positive definite. In contrast, models not meeting these conditions are termed singular. Over the past decade, several information criteria for singular cases have been proposed, including WBIC and sBIC. WBIC is applicable in non-regular scenarios but faces challenges with large sample sizes and redundant estimation of known learning coefficients. Conversely, sBIC is limited in its broader application due to its dependence on maximum likelihood estimates. LS addresses these limitations by enhancing the utility of both WBIC and sBIC. It incorporates the empirical loss from the Widely Applicable Information Criterion (WAIC) to represent the goodness of fit to the statistical model, along with a penalty term similar to that of sBIC. This approach offers a flexible and robust method for model selection, free from regularity constraints.
Fast Inference of Removal-Based Node Influence
Mar 16, 2024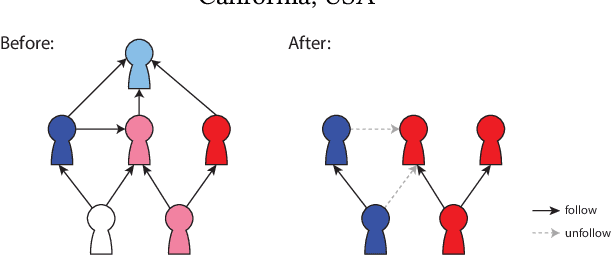


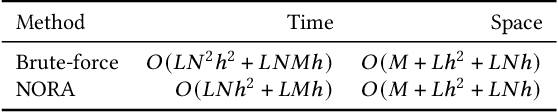
Graph neural networks (GNNs) are widely utilized to capture the information spreading patterns in graphs. While remarkable performance has been achieved, there is a new trending topic of evaluating node influence. We propose a new method of evaluating node influence, which measures the prediction change of a trained GNN model caused by removing a node. A real-world application is, "In the task of predicting Twitter accounts' polarity, had a particular account been removed, how would others' polarity change?". We use the GNN as a surrogate model whose prediction could simulate the change of nodes or edges caused by node removal. Our target is to obtain the influence score for every node, and a straightforward way is to alternately remove every node and apply the trained GNN on the modified graph to generate new predictions. It is reliable but time-consuming, so we need an efficient method. The related lines of work, such as graph adversarial attack and counterfactual explanation, cannot directly satisfy our needs, since their problem settings are different. We propose an efficient, intuitive, and effective method, NOde-Removal-based fAst GNN inference (NORA), which uses the gradient information to approximate the node-removal influence. It only costs one forward propagation and one backpropagation to approximate the influence score for all nodes. Extensive experiments on six datasets and six GNN models verify the effectiveness of NORA. Our code is available at https://github.com/weikai-li/NORA.git.
EffiPerception: an Efficient Framework for Various Perception Tasks
Mar 18, 2024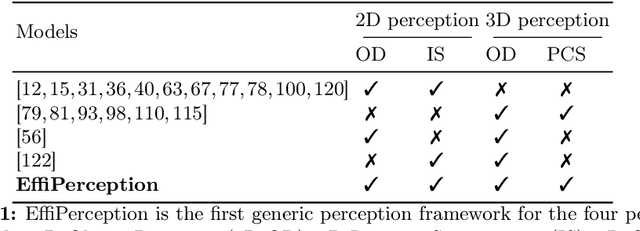
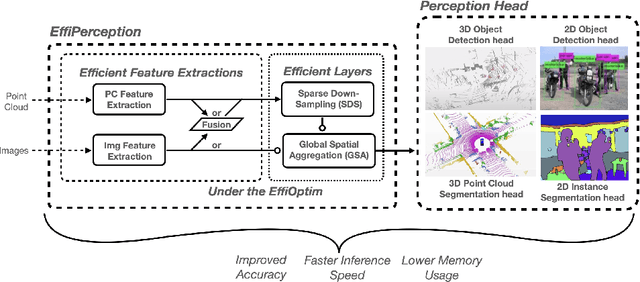
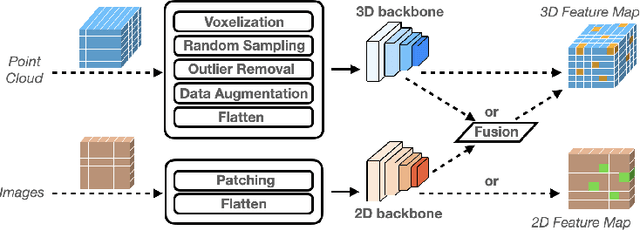
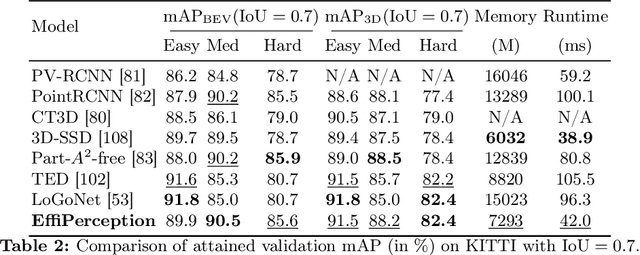
The accuracy-speed-memory trade-off is always the priority to consider for several computer vision perception tasks. Previous methods mainly focus on a single or small couple of these tasks, such as creating effective data augmentation, feature extractor, learning strategies, etc. These approaches, however, could be inherently task-specific: their proposed model's performance may depend on a specific perception task or a dataset. Targeting to explore common learning patterns and increasing the module robustness, we propose the EffiPerception framework. It could achieve great accuracy-speed performance with relatively low memory cost under several perception tasks: 2D Object Detection, 3D Object Detection, 2D Instance Segmentation, and 3D Point Cloud Segmentation. Overall, the framework consists of three parts: (1) Efficient Feature Extractors, which extract the input features for each modality. (2) Efficient Layers, plug-in plug-out layers that further process the feature representation, aggregating core learned information while pruning noisy proposals. (3) The EffiOptim, an 8-bit optimizer to further cut down the computational cost and facilitate performance stability. Extensive experiments on the KITTI, semantic-KITTI, and COCO datasets revealed that EffiPerception could show great accuracy-speed-memory overall performance increase within the four detection and segmentation tasks, in comparison to earlier, well-respected methods.
Learning Useful Representations of Recurrent Neural Network Weight Matrices
Mar 18, 2024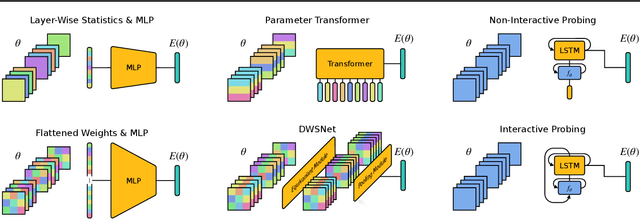

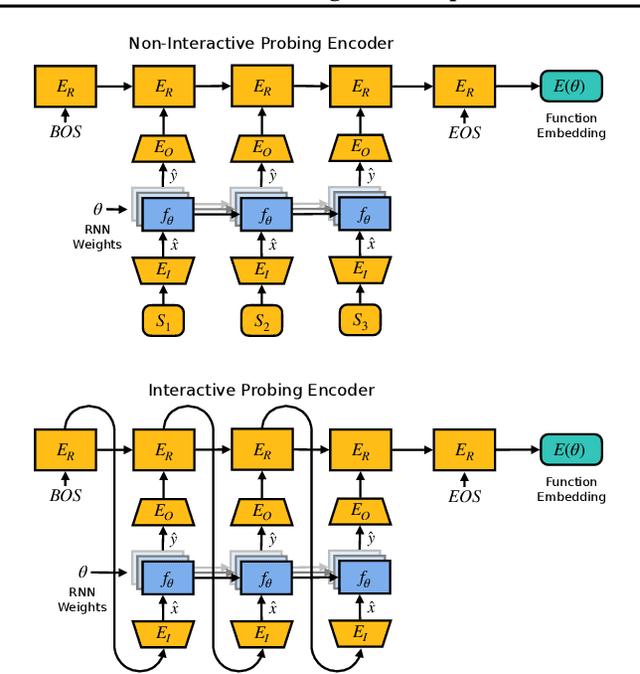
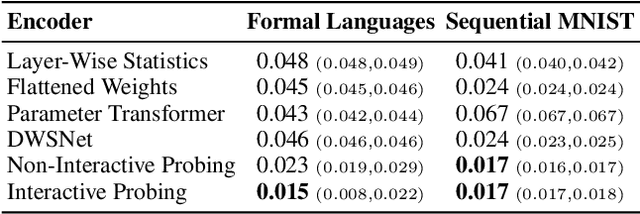
Recurrent Neural Networks (RNNs) are general-purpose parallel-sequential computers. The program of an RNN is its weight matrix. How to learn useful representations of RNN weights that facilitate RNN analysis as well as downstream tasks? While the mechanistic approach directly looks at some RNN's weights to predict its behavior, the functionalist approach analyzes its overall functionality -- specifically, its input-output mapping. We consider several mechanistic approaches for RNN weights and adapt the permutation equivariant Deep Weight Space layer for RNNs. Our two novel functionalist approaches extract information from RNN weights by 'interrogating' the RNN through probing inputs. We develop a theoretical framework that demonstrates conditions under which the functionalist approach can generate rich representations that help determine RNN behavior. We create and release the first two 'model zoo' datasets for RNN weight representation learning. One consists of generative models of a class of formal languages, and the other one of classifiers of sequentially processed MNIST digits. With the help of an emulation-based self-supervised learning technique we compare and evaluate the different RNN weight encoding techniques on multiple downstream applications. On the most challenging one, namely predicting which exact task the RNN was trained on, functionalist approaches show clear superiority.
Using Generative Text Models to Create Qualitative Codebooks for Student Evaluations of Teaching
Mar 18, 2024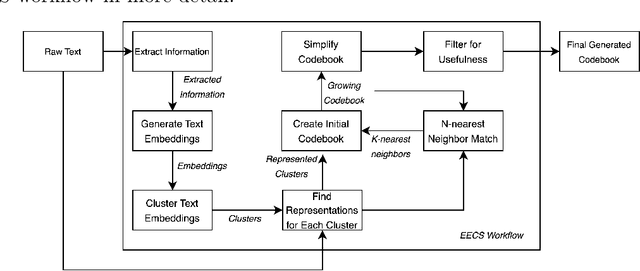

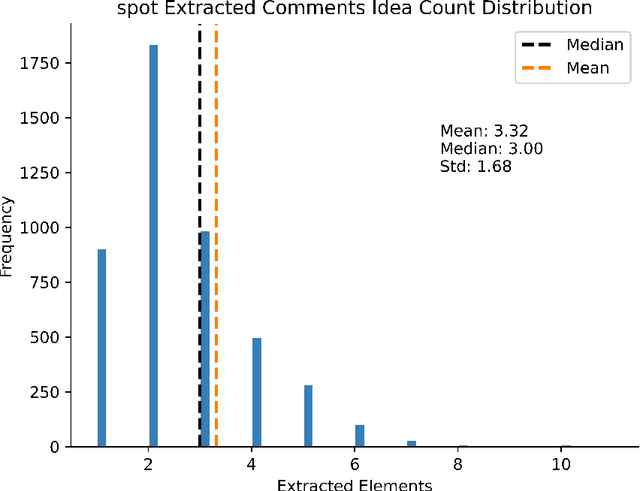

Feedback is a critical aspect of improvement. Unfortunately, when there is a lot of feedback from multiple sources, it can be difficult to distill the information into actionable insights. Consider student evaluations of teaching (SETs), which are important sources of feedback for educators. They can give instructors insights into what worked during a semester. A collection of SETs can also be useful to administrators as signals for courses or entire programs. However, on a large scale as in high-enrollment courses or administrative records over several years, the volume of SETs can render them difficult to analyze. In this paper, we discuss a novel method for analyzing SETs using natural language processing (NLP) and large language models (LLMs). We demonstrate the method by applying it to a corpus of 5,000 SETs from a large public university. We show that the method can be used to extract, embed, cluster, and summarize the SETs to identify the themes they express. More generally, this work illustrates how to use the combination of NLP techniques and LLMs to generate a codebook for SETs. We conclude by discussing the implications of this method for analyzing SETs and other types of student writing in teaching and research settings.
BEVCar: Camera-Radar Fusion for BEV Map and Object Segmentation
Mar 18, 2024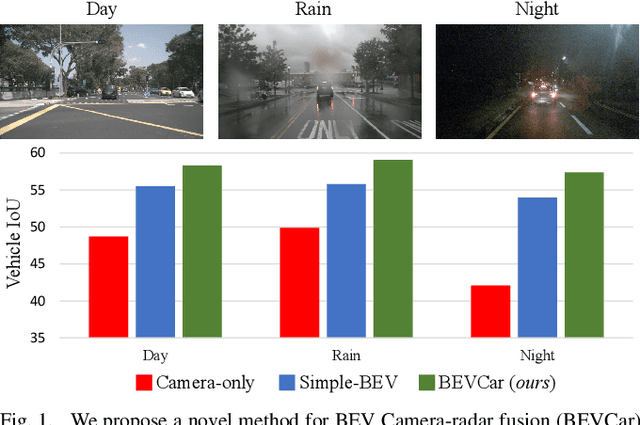
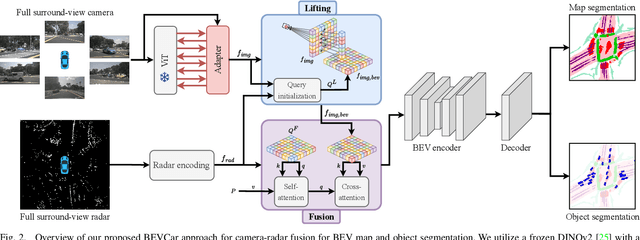
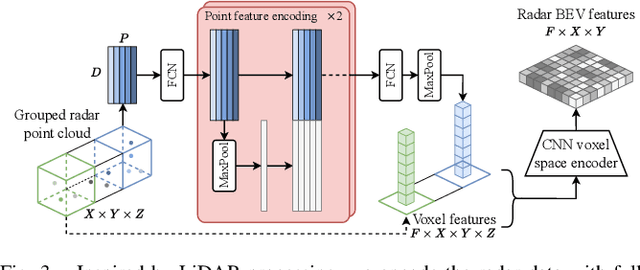
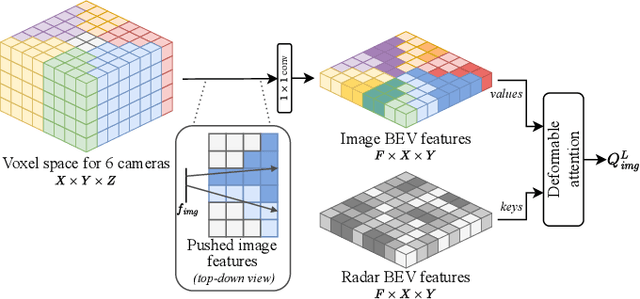
Semantic scene segmentation from a bird's-eye-view (BEV) perspective plays a crucial role in facilitating planning and decision-making for mobile robots. Although recent vision-only methods have demonstrated notable advancements in performance, they often struggle under adverse illumination conditions such as rain or nighttime. While active sensors offer a solution to this challenge, the prohibitively high cost of LiDARs remains a limiting factor. Fusing camera data with automotive radars poses a more inexpensive alternative but has received less attention in prior research. In this work, we aim to advance this promising avenue by introducing BEVCar, a novel approach for joint BEV object and map segmentation. The core novelty of our approach lies in first learning a point-based encoding of raw radar data, which is then leveraged to efficiently initialize the lifting of image features into the BEV space. We perform extensive experiments on the nuScenes dataset and demonstrate that BEVCar outperforms the current state of the art. Moreover, we show that incorporating radar information significantly enhances robustness in challenging environmental conditions and improves segmentation performance for distant objects. To foster future research, we provide the weather split of the nuScenes dataset used in our experiments, along with our code and trained models at http://bevcar.cs.uni-freiburg.de.
ShapeFormer: Shape Prior Visible-to-Amodal Transformer-based Amodal Instance Segmentation
Mar 18, 2024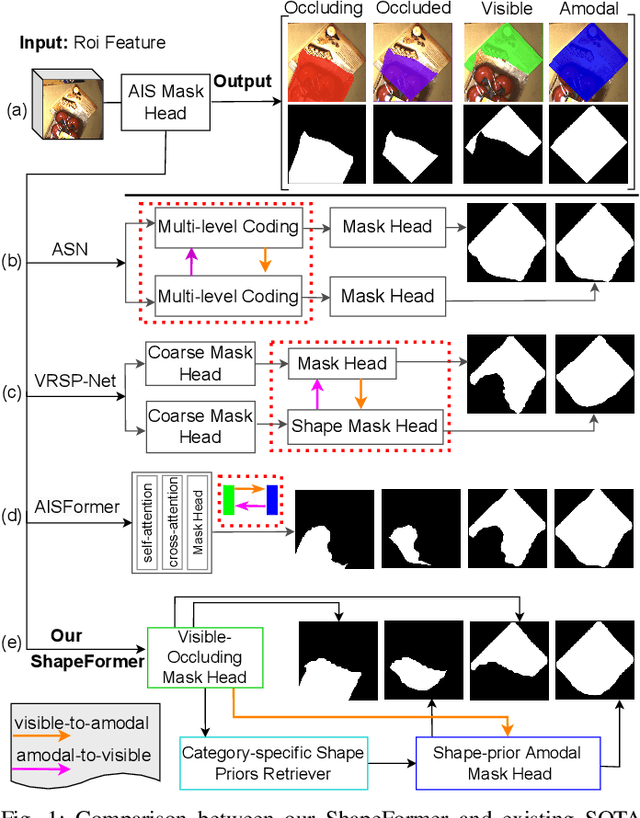
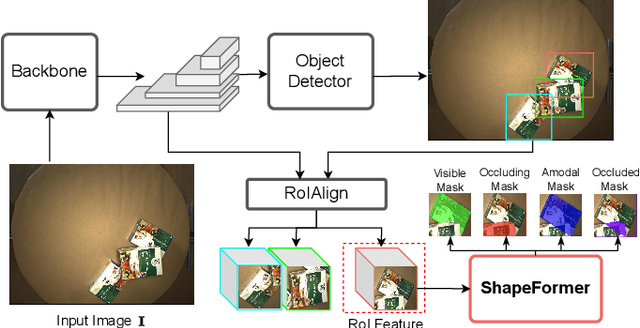
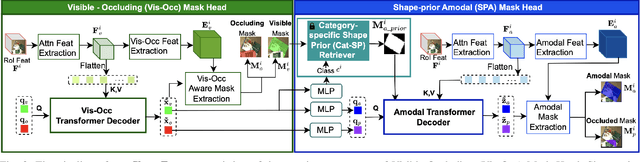
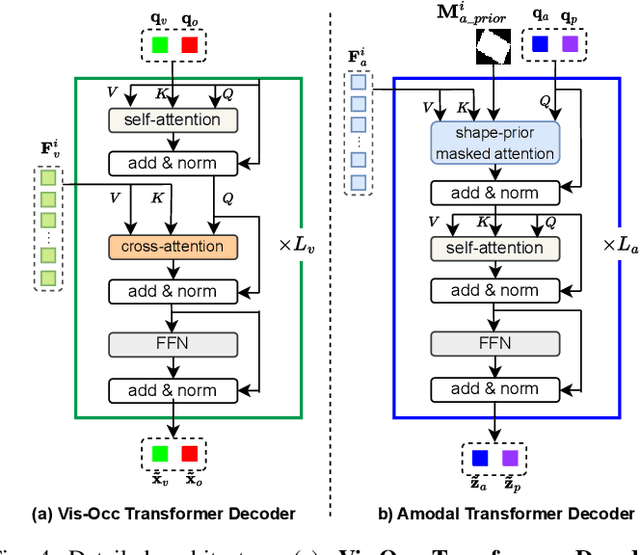
Amodal Instance Segmentation (AIS) presents a challenging task as it involves predicting both visible and occluded parts of objects within images. Existing AIS methods rely on a bidirectional approach, encompassing both the transition from amodal features to visible features (amodal-to-visible) and from visible features to amodal features (visible-to-amodal). Our observation shows that the utilization of amodal features through the amodal-to-visible can confuse the visible features due to the extra information of occluded/hidden segments not presented in visible display. Consequently, this compromised quality of visible features during the subsequent visible-to-amodal transition. To tackle this issue, we introduce ShapeFormer, a decoupled Transformer-based model with a visible-to-amodal transition. It facilitates the explicit relationship between output segmentations and avoids the need for amodal-to-visible transitions. ShapeFormer comprises three key modules: (i) Visible-Occluding Mask Head for predicting visible segmentation with occlusion awareness, (ii) Shape-Prior Amodal Mask Head for predicting amodal and occluded masks, and (iii) Category-Specific Shape Prior Retriever aims to provide shape prior knowledge. Comprehensive experiments and extensive ablation studies across various AIS benchmarks demonstrate the effectiveness of our ShapeFormer. The code is available at: https://github.com/UARK-AICV/ShapeFormer
OUCopula: Bi-Channel Multi-Label Copula-Enhanced Adapter-Based CNN for Myopia Screening Based on OU-UWF Images
Mar 18, 2024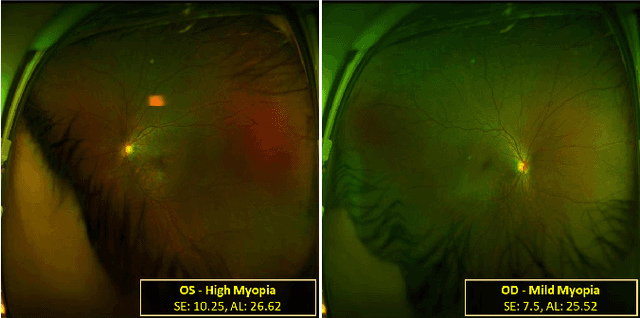
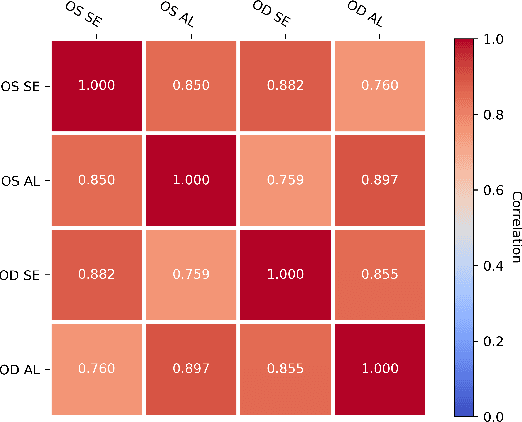
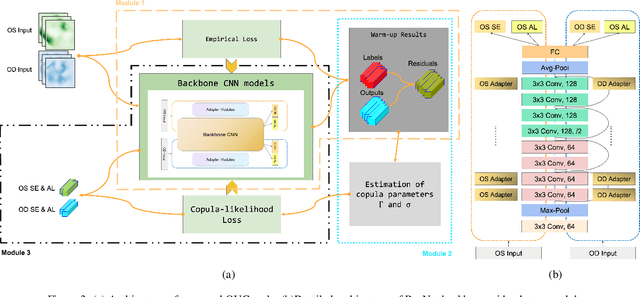
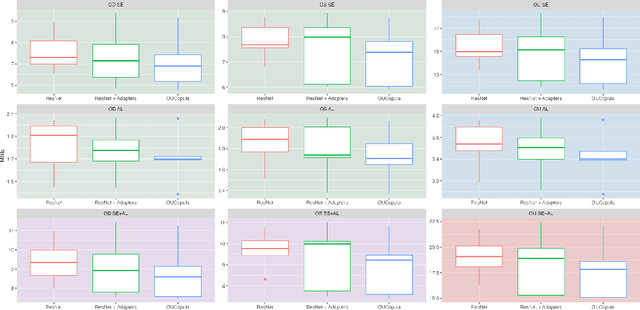
Myopia screening using cutting-edge ultra-widefield (UWF) fundus imaging is potentially significant for ophthalmic outcomes. Current multidisciplinary research between ophthalmology and deep learning (DL) concentrates primarily on disease classification and diagnosis using single-eye images, largely ignoring joint modeling and prediction for Oculus Uterque (OU, both eyes). Inspired by the complex relationships between OU and the high correlation between the (continuous) outcome labels (Spherical Equivalent and Axial Length), we propose a framework of copula-enhanced adapter convolutional neural network (CNN) learning with OU UWF fundus images (OUCopula) for joint prediction of multiple clinical scores. We design a novel bi-channel multi-label CNN that can (1) take bi-channel image inputs subject to both high correlation and heterogeneity (by sharing the same backbone network and employing adapters to parameterize the channel-wise discrepancy), and (2) incorporate correlation information between continuous output labels (using a copula). Solid experiments show that OUCopula achieves satisfactory performance in myopia score prediction compared to backbone models. Moreover, OUCopula can far exceed the performance of models constructed for single-eye inputs. Importantly, our study also hints at the potential extension of the bi-channel model to a multi-channel paradigm and the generalizability of OUCopula across various backbone CNNs.
GeoWizard: Unleashing the Diffusion Priors for 3D Geometry Estimation from a Single Image
Mar 18, 2024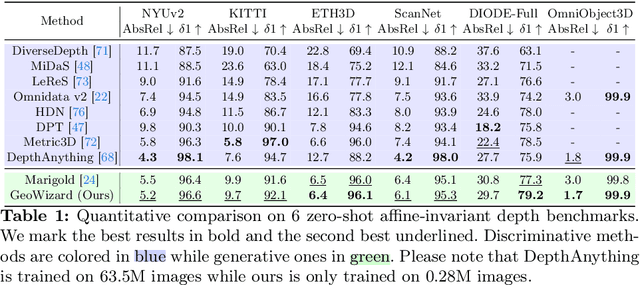
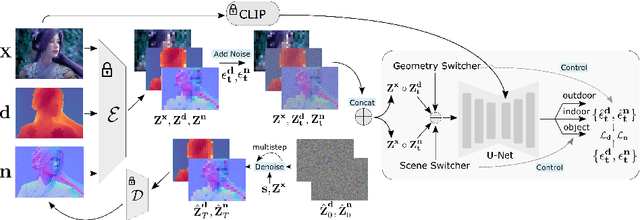

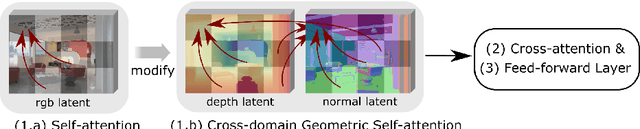
We introduce GeoWizard, a new generative foundation model designed for estimating geometric attributes, e.g., depth and normals, from single images. While significant research has already been conducted in this area, the progress has been substantially limited by the low diversity and poor quality of publicly available datasets. As a result, the prior works either are constrained to limited scenarios or suffer from the inability to capture geometric details. In this paper, we demonstrate that generative models, as opposed to traditional discriminative models (e.g., CNNs and Transformers), can effectively address the inherently ill-posed problem. We further show that leveraging diffusion priors can markedly improve generalization, detail preservation, and efficiency in resource usage. Specifically, we extend the original stable diffusion model to jointly predict depth and normal, allowing mutual information exchange and high consistency between the two representations. More importantly, we propose a simple yet effective strategy to segregate the complex data distribution of various scenes into distinct sub-distributions. This strategy enables our model to recognize different scene layouts, capturing 3D geometry with remarkable fidelity. GeoWizard sets new benchmarks for zero-shot depth and normal prediction, significantly enhancing many downstream applications such as 3D reconstruction, 2D content creation, and novel viewpoint synthesis.