 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodied Intelligence for Sustainable Flight: A Soaring Robot with Active Morphological Control
Aug 27, 2025Achieving both agile maneuverability and high energy efficiency in aerial robots, particularly in dynamic wind environments, remains challenging. Conventional thruster-powered systems offer agility but suffer from high energy consumption, while fixed-wing designs are efficient but lack hovering and maneuvering capabilities. We present Floaty, a shape-changing robot that overcomes these limitations by passively soaring, harnessing wind energy through intelligent morphological control inspired by birds. Floaty's design is optimized for passive stability, and its control policy is derived from an experimentally learned aerodynamic model, enabling precise attitude and position control without active propulsion. Wind tunnel experiments demonstrate Floaty's ability to hover, maneuver, and reject disturbances in vertical airflows up to 10 m/s. Crucially, Floaty achieves this with a specific power consumption of 10 W/kg, an order of magnitude lower than thruster-powered systems. This introduces a paradigm for energy-efficient aerial robotics, leveraging morphological intelligence and control to operate sustainably in challenging wind conditions.
HOIGaze: Gaze Estimation During Hand-Object Interactions in Extended Reality Exploiting Eye-Hand-Head Coordination
Apr 28, 2025We present HOIGaze - a novel learning-based approach for gaze estimation during hand-object interactions (HOI) in extended reality (XR). HOIGaze addresses the challenging HOI setting by building on one key insight: The eye, hand, and head movements are closely coordinated during HOIs and this coordination can be exploited to identify samples that are most useful for gaze estimator training - as such, effectively denoising the training data. This denoising approach is in stark contrast to previous gaze estimation methods that treated all training samples as equal. Specifically, we propose: 1) a novel hierarchical framework that first recognises the hand currently visually attended to and then estimates gaze direction based on the attended hand; 2) a new gaze estimator that uses cross-modal Transformers to fuse head and hand-object features extracted using a convolutional neural network and a spatio-temporal graph convolutional network; and 3) a novel eye-head coordination loss that upgrades training samples belonging to the coordinated eye-head movements. We evaluate HOIGaze on the HOT3D and Aria digital twin (ADT) datasets and show that it significantly outperforms state-of-the-art methods, achieving an average improvement of 15.6% on HOT3D and 6.0% on ADT in mean angular error. To demonstrate the potential of our method, we further report significant performance improvements for the sample downstream task of eye-based activity recognition on ADT. Taken together, our results underline the significant information content available in eye-hand-head coordination and, as such, open up an exciting new direction for learning-based gaze estimation.
HaHeAE: Learning Generalisable Joint Representations of Human Hand and Head Movements in Extended Reality
Oct 21, 2024



Human hand and head movements are the most pervasive input modalities in extended reality (XR) and are significant for a wide range of applications. However, prior works on hand and head modelling in XR only explored a single modality or focused on specific applications. We present HaHeAE - a novel self-supervised method for learning generalisable joint representations of hand and head movements in XR. At the core of our method is an autoencoder (AE) that uses a graph convolutional network-based semantic encoder and a diffusion-based stochastic encoder to learn the joint semantic and stochastic representations of hand-head movements. It also features a diffusion-based decoder to reconstruct the original signals. Through extensive evaluations on three public XR datasets, we show that our method 1) significantly outperforms commonly used self-supervised methods by up to 74.0% in terms of reconstruction quality and is generalisable across users, activities, and XR environments, 2) enables new applications, including interpretable hand-head cluster identification and variable hand-head movement generation, and 3) can serve as an effective feature extractor for downstream tasks. Together, these results demonstrate the effectiveness of our method and underline the potential of self-supervised methods for jointly modelling hand-head behaviours in extended reality.
HOIMotion: Forecasting Human Motion During Human-Object Interactions Using Egocentric 3D Object Bounding Boxes
Jul 02, 2024



We present HOIMotion - a novel approach for human motion forecasting during human-object interactions that integrates information about past body poses and egocentric 3D object bounding boxes. Human motion forecasting is important in many augmented reality applications but most existing methods have only used past body poses to predict future motion. HOIMotion first uses an encoder-residual graph convolutional network (GCN) and multi-layer perceptrons to extract features from body poses and egocentric 3D object bounding boxes, respectively. Our method then fuses pose and object features into a novel pose-object graph and uses a residual-decoder GCN to forecast future body motion. We extensively evaluate our method on the Aria digital twin (ADT) and MoGaze datasets and show that HOIMotion consistently outperforms state-of-the-art methods by a large margin of up to 8.7% on ADT and 7.2% on MoGaze in terms of mean per joint position error. Complementing these evaluations, we report a human study (N=20) that shows that the improvements achieved by our method result in forecasted poses being perceived as both more precise and more realistic than those of existing methods. Taken together, these results reveal the significant information content available in egocentric 3D object bounding boxes for human motion forecasting and the effectiveness of our method in exploiting this information.
GazeMotion: Gaze-guided Human Motion Forecasting
Mar 14, 2024



We present GazeMotion, a novel method for human motion forecasting that combines information on past human poses with human eye gaze. Inspired by evidence from behavioural sciences showing that human eye and body movements are closely coordinated, GazeMotion first predicts future eye gaze from past gaze, then fuses predicted future gaze and past poses into a gaze-pose graph, and finally uses a residual graph convolutional network to forecast body motion. We extensively evaluate our method on the MoGaze, ADT, and GIMO benchmark datasets and show that it outperforms state-of-the-art methods by up to 7.4% improvement in mean per joint position error. Using head direction as a proxy to gaze, our method still achieves an average improvement of 5.5%. We finally report an online user study showing that our method also outperforms prior methods in terms of perceived realism. These results show the significant information content available in eye gaze for human motion forecasting as well as the effectiveness of our method in exploiting this information.
Generating Realistic Arm Movements in Reinforcement Learning: A Quantitative Comparison of Reward Terms and Task Requirements
Feb 21, 2024



The mimicking of human-like arm movement characteristics involves the consideration of three factors during control policy synthesis: (a) chosen task requirements, (b) inclusion of noise during movement execution and (c) chosen optimality principles. Previous studies showed that when considering these factors (a-c) individually, it is possible to synthesize arm movements that either kinematically match the experimental data or reproduce the stereotypical triphasic muscle activation pattern. However, to date no quantitative comparison has been made on how realistic the arm movement generated by each factor is; as well as whether a partial or total combination of all factors results in arm movements with human-like kinematic characteristics and a triphasic muscle pattern. To investigate this, we used reinforcement learning to learn a control policy for a musculoskeletal arm model, aiming to discern which combination of factors (a-c) results in realistic arm movements according to four frequently reported stereotypical characteristics. Our findings indicate that incorporating velocity and acceleration requirements into the reaching task, employing reward terms that encourage minimization of mechanical work, hand jerk, and control effort, along with the inclusion of noise during movement, leads to the emergence of realistic human arm movements in reinforcement learning. We expect that the gained insights will help in the future to better predict desired arm movements and corrective forces in wearable assistive devices.
GazeMoDiff: Gaze-guided Diffusion Model for Stochastic Human Motion Prediction
Dec 19, 2023



Human motion prediction is important for virtual reality (VR) applications, e.g., for realistic avatar animation. Existing methods have synthesised body motion only from observed past motion, despite the fact that human gaze is known to correlate strongly with body movements and is readily available in recent VR headsets. We present GazeMoDiff -- a novel gaze-guided denoising diffusion model to generate stochastic human motions. Our method first uses a graph attention network to learn the spatio-temporal correlations between eye gaze and human movements and to fuse them into cross-modal gaze-motion features. These cross-modal features are injected into a noise prediction network via a cross-attention mechanism and progressively denoised to generate realistic human full-body motions. Experimental results on the MoGaze and GIMO datasets demonstrate that our method outperforms the state-of-the-art methods by a large margin in terms of average displacement error (15.03% on MoGaze and 9.20% on GIMO). We further conducted an online user study to compare our method with state-of-the-art methods and the responses from 23 participants validate that the motions generated by our method are more realistic than those from other methods. Taken together, our work makes a first important step towards gaze-guided stochastic human motion prediction and guides future work on this important topic in VR research.
Pose2Gaze: Generating Realistic Human Gaze Behaviour from Full-body Poses using an Eye-body Coordination Model
Dec 19, 2023



While generating realistic body movements, e.g., for avatars in virtual reality, is widely studied in computer vision and graphics, the generation of eye movements that exhibit realistic coordination with the body remains under-explored. We first report a comprehensive analysis of the coordination of human eye and full-body movements during everyday activities based on data from the MoGaze and GIMO datasets. We show that eye gaze has strong correlations with head directions and also full-body motions and there exists a noticeable time delay between body and eye movements. Inspired by the analyses, we then present Pose2Gaze -- a novel eye-body coordination model that first uses a convolutional neural network and a spatio-temporal graph convolutional neural network to extract features from head directions and full-body poses respectively and then applies a convolutional neural network to generate realistic eye movements. We compare our method with state-of-the-art methods that predict eye gaze only from head movements for three different generation tasks and demonstrate that Pose2Gaze significantly outperforms these baselines on both datasets with an average improvement of 26.4% and 21.6% in mean angular error, respectively. Our findings underline the significant potential of cross-modal human gaze behaviour analysis and modelling.
Natural and Robust Walking using Reinforcement Learning without Demonstrations in High-Dimensional Musculoskeletal Models
Sep 07, 2023



Humans excel at robust bipedal walking in complex natural environments. In each step, they adequately tune the interaction of biomechanical muscle dynamics and neuronal signals to be robust against uncertainties in ground conditions. However, it is still not fully understood how the nervous system resolves the musculoskeletal redundancy to solve the multi-objective control problem considering stability, robustness, and energy efficiency. In computer simulations, energy minimization has been shown to be a successful optimization target, reproducing natural walking with trajectory optimization or reflex-based control methods. However, these methods focus on particular motions at a time and the resulting controllers are limited when compensating for perturbations. In robotics, reinforcement learning~(RL) methods recently achieved highly stable (and efficient) locomotion on quadruped systems, but the generation of human-like walking with bipedal biomechanical models has required extensive use of expert data sets. This strong reliance on demonstrations often results in brittle policies and limits the application to new behaviors, especially considering the potential variety of movements for high-dimensional musculoskeletal models in 3D. Achieving natural locomotion with RL without sacrificing its incredible robustness might pave the way for a novel approach to studying human walking in complex natural environments. Videos: https://sites.google.com/view/naturalwalkingrl
Learning with Muscles: Benefits for Data-Efficiency and Robustness in Anthropomorphic Tasks
Jul 08, 2022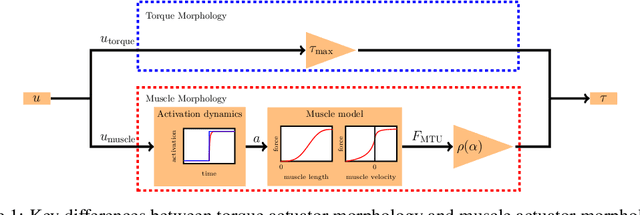
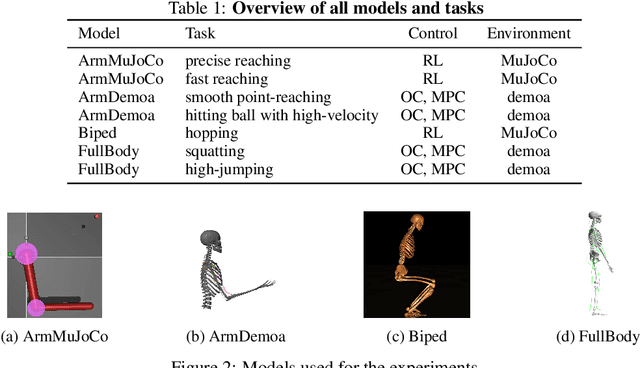

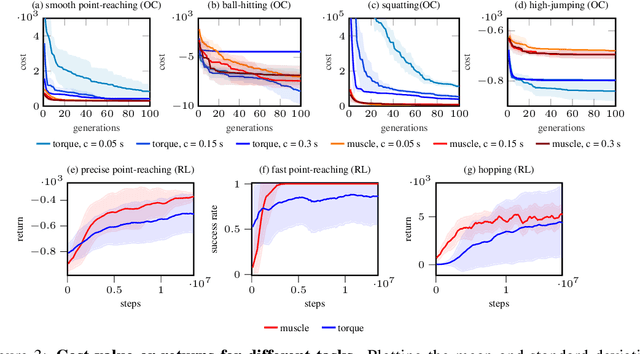
Humans are able to outperform robots in terms of robustness, versatility, and learning of new tasks in a wide variety of movements. We hypothesize that highly nonlinear muscle dynamics play a large role in providing inherent stability, which is favorable to learning. While recent advances have been made in applying modern learning techniques to muscle-actuated systems both in simulation as well as in robotics, so far, no detailed analysis has been performed to show the benefits of muscles in this setting. Our study closes this gap by investigating core robotics challenges and comparing the performance of different actuator morphologies in terms of data-efficiency, hyperparameter sensitivity, and robustness.