 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Recover Triggered States: Protect Model Against Backdoor Attack in Reinforcement Learning
Apr 04, 2023
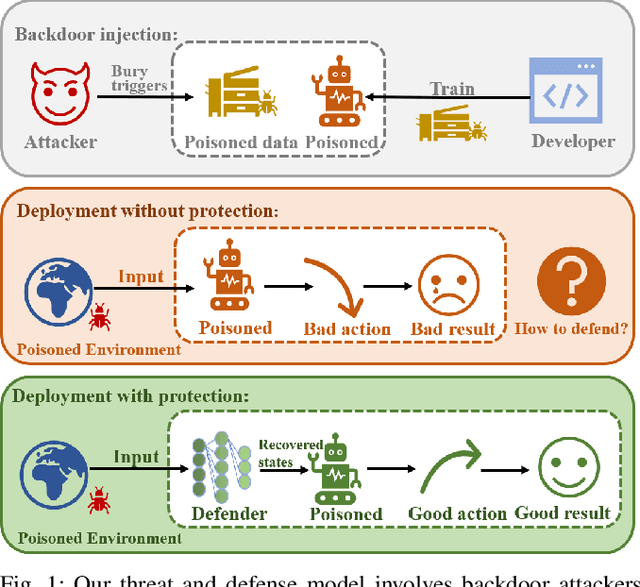
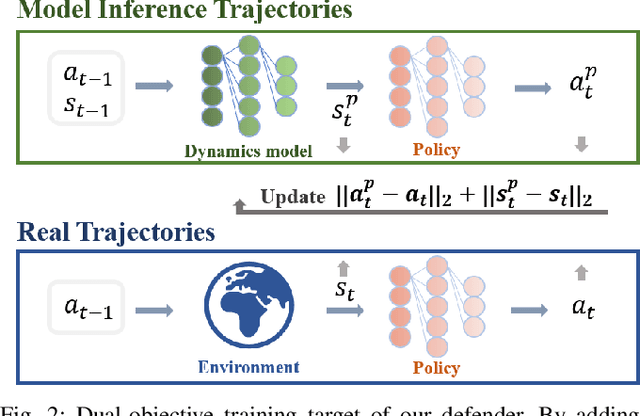
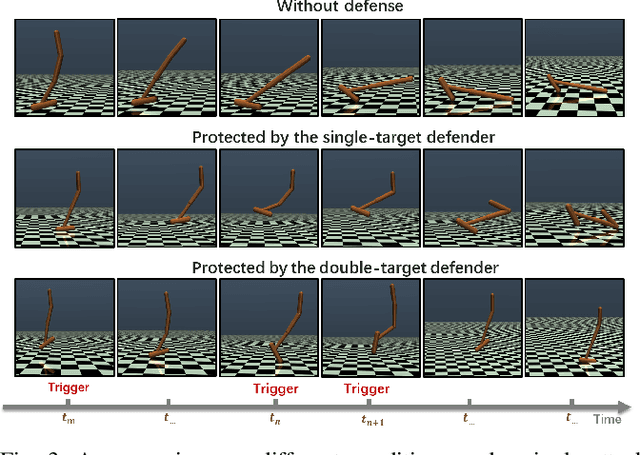
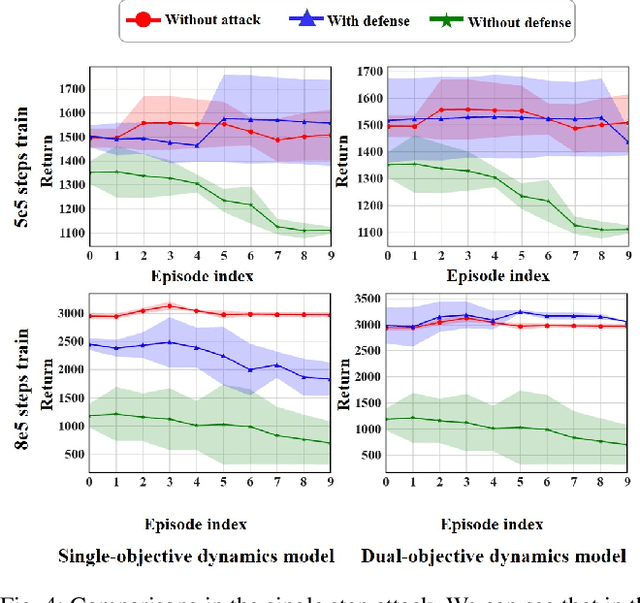
A backdoor attack allows a malicious user to manipulate the environment or corrupt the training data, thus inserting a backdoor into the trained agent. Such attacks compromise the RL system's reliability, leading to potentially catastrophic results in various key fields. In contrast, relatively limited research has investigated effective defenses against backdoor attacks in RL. This paper proposes the Recovery Triggered States (RTS) method, a novel approach that effectively protects the victim agents from backdoor attacks. RTS involves building a surrogate network to approximate the dynamics model. Developers can then recover the environment from the triggered state to a clean state, thereby preventing attackers from activating backdoors hidden in the agent by presenting the trigger. When training the surrogate to predict states, we incorporate agent action information to reduce the discrepancy between the actions taken by the agent on predicted states and the actions taken on real states. RTS is the first approach to defend against backdoor attacks in a single-agent setting. Our results show that using RTS, the cumulative reward only decreased by 1.41% under the backdoor attack.
Robustness Benchmark of Road User Trajectory Prediction Models for Automated Driving
Apr 04, 2023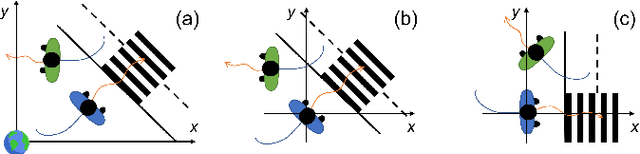
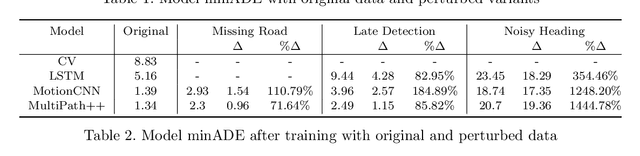
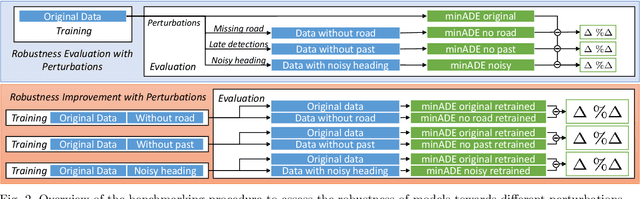

Accurate and robust trajectory predictions of road users are needed to enable safe automated driving. To do this, machine learning models are often used, which can show erratic behavior when presented with previously unseen inputs. In this work, two environment-aware models (MotionCNN and MultiPath++) and two common baselines (Constant Velocity and an LSTM) are benchmarked for robustness against various perturbations that simulate functional insufficiencies observed during model deployment in a vehicle: unavailability of road information, late detections, and noise. Results show significant performance degradation under the presence of these perturbations, with errors increasing up to +1444.8\% in commonly used trajectory prediction evaluation metrics. Training the models with similar perturbations effectively reduces performance degradation, with error increases of up to +87.5\%. We argue that despite being an effective mitigation strategy, data augmentation through perturbations during training does not guarantee robustness towards unforeseen perturbations, since identification of all possible on-road complications is unfeasible. Furthermore, degrading the inputs sometimes leads to more accurate predictions, suggesting that the models are unable to learn the true relationships between the different elements in the data.
Visual Prompt Based Personalized Federated Learning
Mar 15, 2023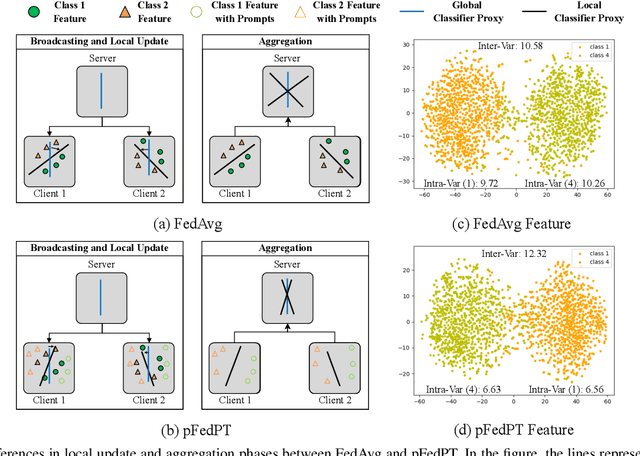
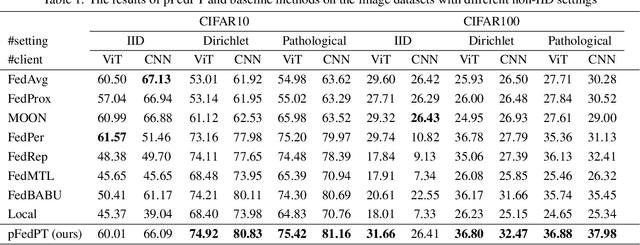
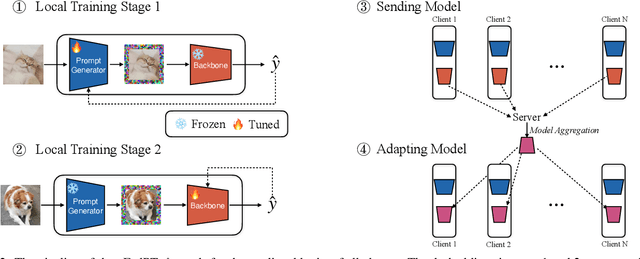
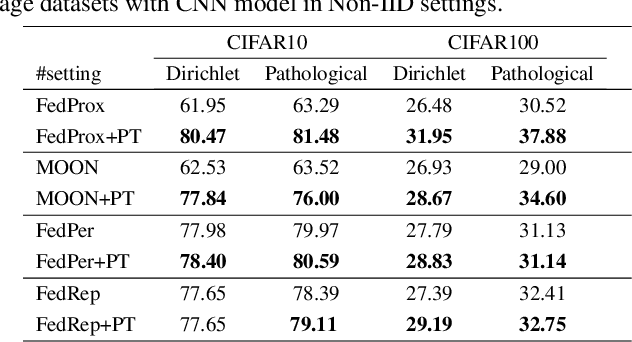
As a popular paradigm of distributed learning, personalized federated learning (PFL) allows personalized models to improve generalization ability and robustness by utilizing knowledge from all distributed clients. Most existing PFL algorithms tackle personalization in a model-centric way, such as personalized layer partition, model regularization, and model interpolation, which all fail to take into account the data characteristics of distributed clients. In this paper, we propose a novel PFL framework for image classification tasks, dubbed pFedPT, that leverages personalized visual prompts to implicitly represent local data distribution information of clients and provides that information to the aggregation model to help with classification tasks. Specifically, in each round of pFedPT training, each client generates a local personalized prompt related to local data distribution. Then, the local model is trained on the input composed of raw data and a visual prompt to learn the distribution information contained in the prompt. During model testing, the aggregated model obtains prior knowledge of the data distributions based on the prompts, which can be seen as an adaptive fine-tuning of the aggregation model to improve model performances on different clients. Furthermore, the visual prompt can be added as an orthogonal method to implement personalization on the client for existing FL methods to boost their performance. Experiments on the CIFAR10 and CIFAR100 datasets show that pFedPT outperforms several state-of-the-art (SOTA) PFL algorithms by a large margin in various settings.
Leveraging Multi-stream Information Fusion for Trajectory Prediction in Low-illumination Scenarios: A Multi-channel Graph Convolutional Approach
Nov 18, 2022Trajectory prediction is a fundamental problem and challenge for autonomous vehicles. Early works mainly focused on designing complicated architectures for deep-learning-based prediction models in normal-illumination environments, which fail in dealing with low-light conditions. This paper proposes a novel approach for trajectory prediction in low-illumination scenarios by leveraging multi-stream information fusion, which flexibly integrates image, optical flow, and object trajectory information. The image channel employs Convolutional Neural Network (CNN) and Long Short-term Memory (LSTM) networks to extract temporal information from the camera. The optical flow channel is applied to capture the pattern of relative motion between adjacent camera frames and modelled by Spatial-Temporal Graph Convolutional Network (ST-GCN). The trajectory channel is used to recognize high-level interactions between vehicles. Finally, information from all the three channels is effectively fused in the prediction module to generate future trajectories of surrounding vehicles in low-illumination conditions. The proposed multi-channel graph convolutional approach is validated on HEV-I and newly generated Dark-HEV-I, egocentric vision datasets that primarily focus on urban intersection scenarios. The results demonstrate that our method outperforms the baselines, in standard and low-illumination scenarios. Additionally, our approach is generic and applicable to scenarios with different types of perception data. The source code of the proposed approach is available at https://github.com/TommyGong08/MSIF}{https://github.com/TommyGong08/MSIF.
CASP-Net: Rethinking Video Saliency Prediction from an Audio-VisualConsistency Perceptual Perspective
Mar 11, 2023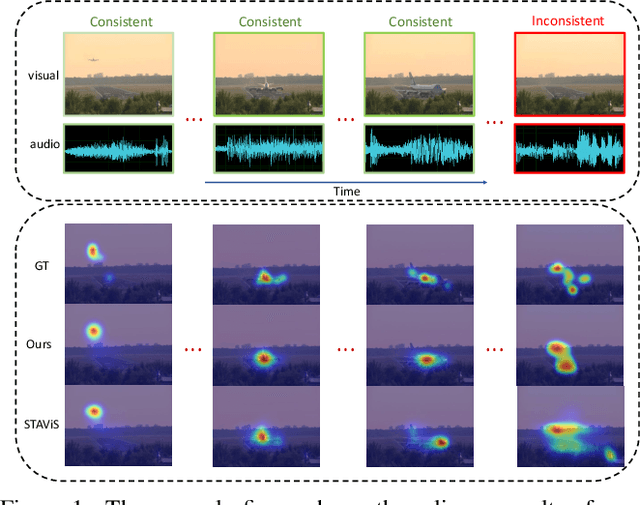
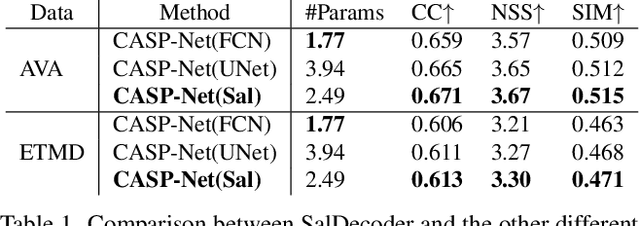
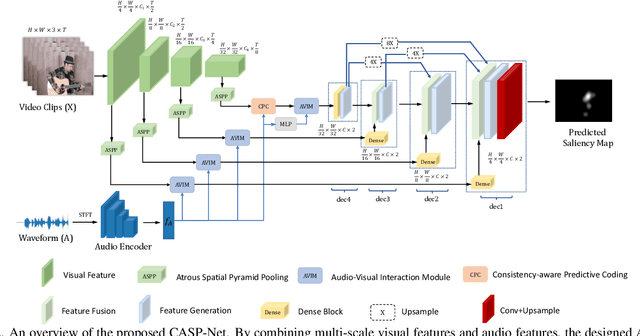
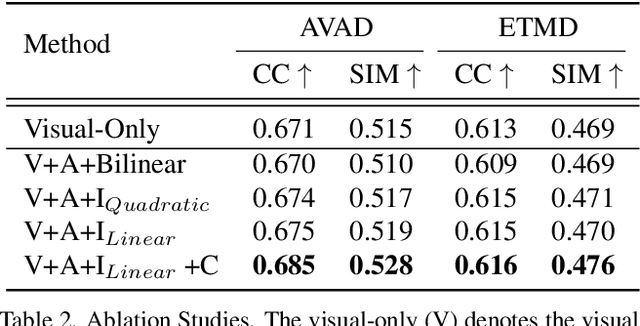
Incorporating the audio stream enables Video Saliency Prediction (VSP) to imitate the selective attention mechanism of human brain. By focusing on the benefits of joint auditory and visual information, most VSP methods are capable of exploiting semantic correlation between vision and audio modalities but ignoring the negative effects due to the temporal inconsistency of audio-visual intrinsics. Inspired by the biological inconsistency-correction within multi-sensory information, in this study, a consistency-aware audio-visual saliency prediction network (CASP-Net) is proposed, which takes a comprehensive consideration of the audio-visual semantic interaction and consistent perception. In addition a two-stream encoder for elegant association between video frames and corresponding sound source, a novel consistency-aware predictive coding is also designed to improve the consistency within audio and visual representations iteratively. To further aggregate the multi-scale audio-visual information, a saliency decoder is introduced for the final saliency map generation. Substantial experiments demonstrate that the proposed CASP-Net outperforms the other state-of-the-art methods on six challenging audio-visual eye-tracking datasets. For a demo of our system please see our project webpage.
CP$^3$: Channel Pruning Plug-in for Point-based Networks
Mar 23, 2023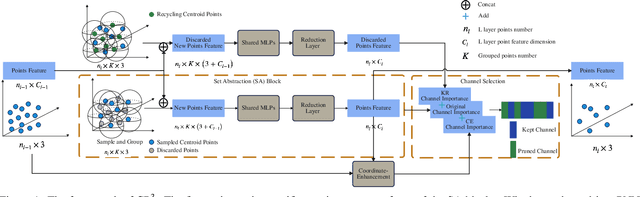
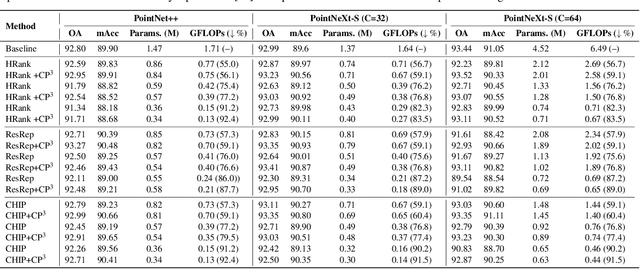
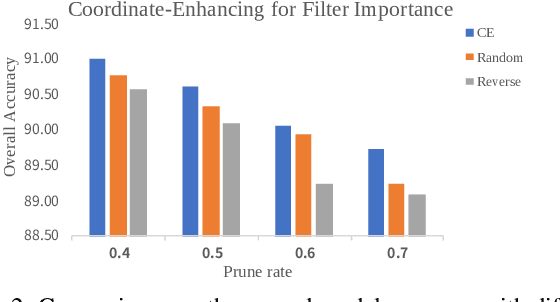
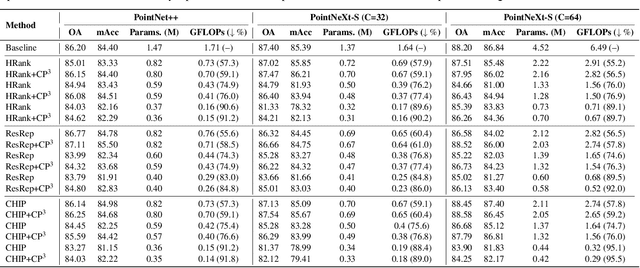
Channel pruning can effectively reduce both computational cost and memory footprint of the original network while keeping a comparable accuracy performance. Though great success has been achieved in channel pruning for 2D image-based convolutional networks (CNNs), existing works seldom extend the channel pruning methods to 3D point-based neural networks (PNNs). Directly implementing the 2D CNN channel pruning methods to PNNs undermine the performance of PNNs because of the different representations of 2D images and 3D point clouds as well as the network architecture disparity. In this paper, we proposed CP$^3$, which is a Channel Pruning Plug-in for Point-based network. CP$^3$ is elaborately designed to leverage the characteristics of point clouds and PNNs in order to enable 2D channel pruning methods for PNNs. Specifically, it presents a coordinate-enhanced channel importance metric to reflect the correlation between dimensional information and individual channel features, and it recycles the discarded points in PNN's sampling process and reconsiders their potentially-exclusive information to enhance the robustness of channel pruning. Experiments on various PNN architectures show that CP$^3$ constantly improves state-of-the-art 2D CNN pruning approaches on different point cloud tasks. For instance, our compressed PointNeXt-S on ScanObjectNN achieves an accuracy of 88.52% with a pruning rate of 57.8%, outperforming the baseline pruning methods with an accuracy gain of 1.94%.
Improving Adversarial Robustness with Hypersphere Embedding and Angular-based Regularizations
Mar 15, 2023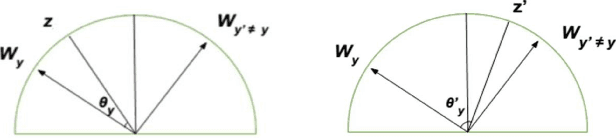



Adversarial training (AT) methods have been found to be effective against adversarial attacks on deep neural networks. Many variants of AT have been proposed to improve its performance. Pang et al. [1] have recently shown that incorporating hypersphere embedding (HE) into the existing AT procedures enhances robustness. We observe that the existing AT procedures are not designed for the HE framework, and thus fail to adequately learn the angular discriminative information available in the HE framework. In this paper, we propose integrating HE into AT with regularization terms that exploit the rich angular information available in the HE framework. Specifically, our method, termed angular-AT, adds regularization terms to AT that explicitly enforce weight-feature compactness and inter-class separation; all expressed in terms of angular features. Experimental results show that angular-AT further improves adversarial robustness.
HCGMNET: A Hierarchical Change Guiding Map Network For Change Detection
Mar 13, 2023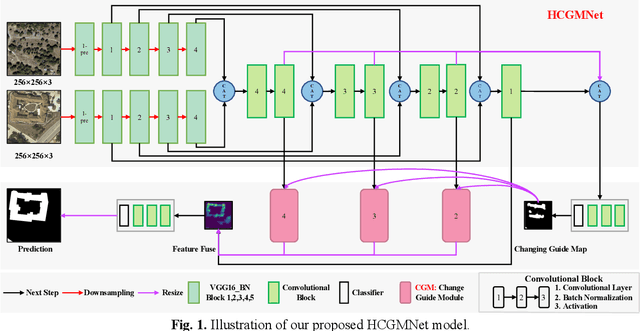
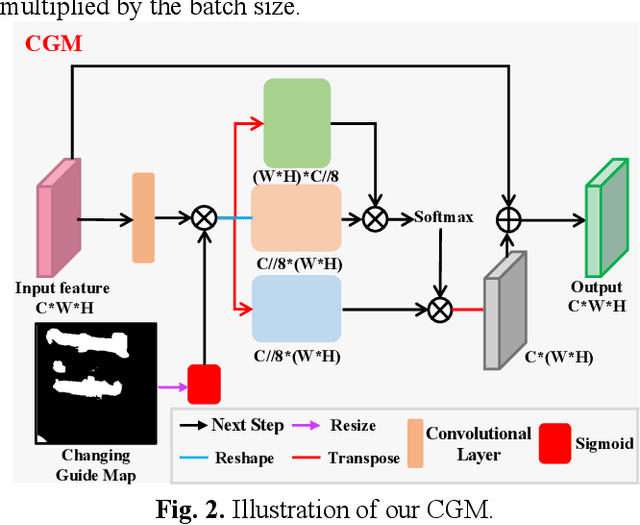

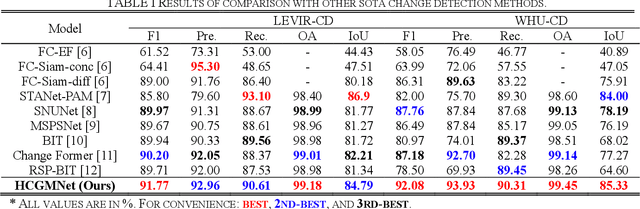
Very-high-resolution (VHR) remote sensing (RS) image change detection (CD) has been a challenging task for its very rich spatial information and sample imbalance problem. In this paper, we have proposed a hierarchical change guiding map network (HCGMNet) for change detection. The model uses hierarchical convolution operations to extract multiscale features, continuously merges multi-scale features layer by layer to improve the expression of global and local information, and guides the model to gradually refine edge features and comprehensive performance by a change guide module (CGM), which is a self-attention with changing guide map. Extensive experiments on two CD datasets show that the proposed HCGMNet architecture achieves better CD performance than existing state-of-the-art (SOTA) CD methods.
Learning Model-Free Robust Precoding for Cooperative Multibeam Satellite Communications
Mar 13, 2023
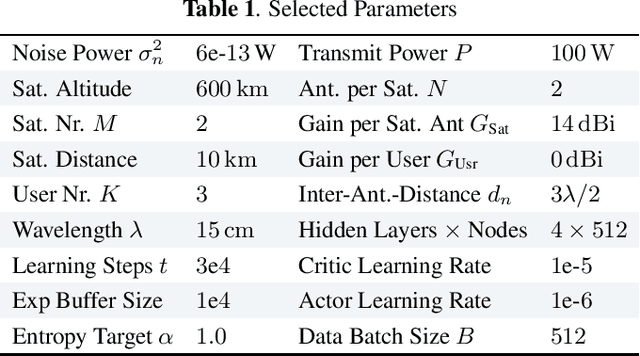
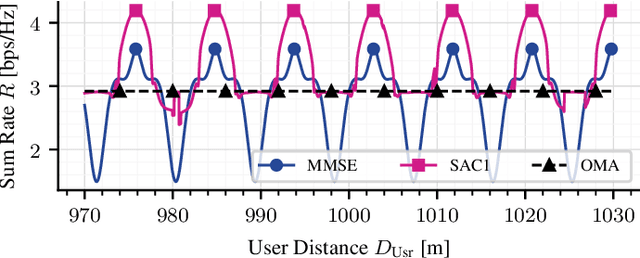
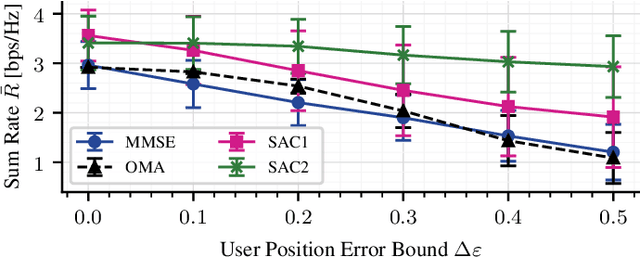
Direct Low Earth Orbit satellite-to-handheld links are expected to be part of a new era in satellite communications. Space-Division Multiple Access precoding is a technique that reduces interference among satellite beams, therefore increasing spectral efficiency by allowing cooperating satellites to reuse frequency. Over the past decades, optimal precoding solutions with perfect channel state information have been proposed for several scenarios, whereas robust precoding with only imperfect channel state information has been mostly studied for simplified models. In particular, for Low Earth Orbit satellite applications such simplified models might not be accurate. In this paper, we use the function approximation capabilities of the Soft Actor-Critic deep Reinforcement Learning algorithm to learn robust precoding with no knowledge of the system imperfections.
Investigating Catastrophic Overfitting in Fast Adversarial Training: A Self-fitting Perspective
Feb 23, 2023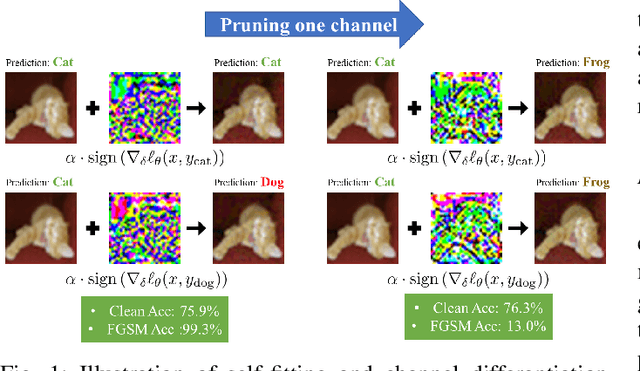
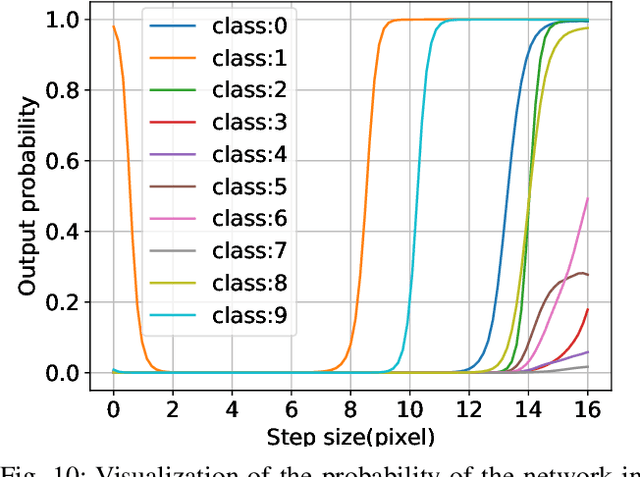
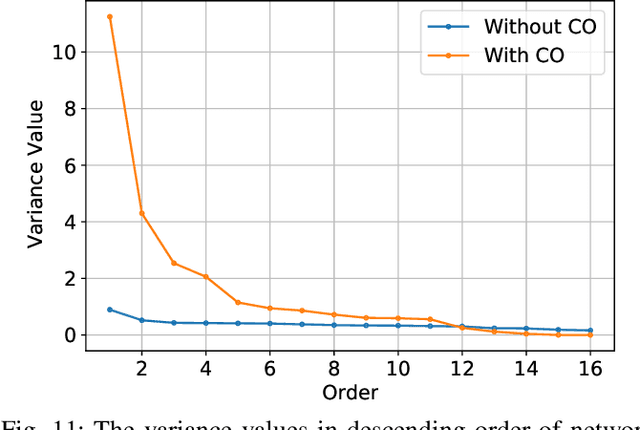
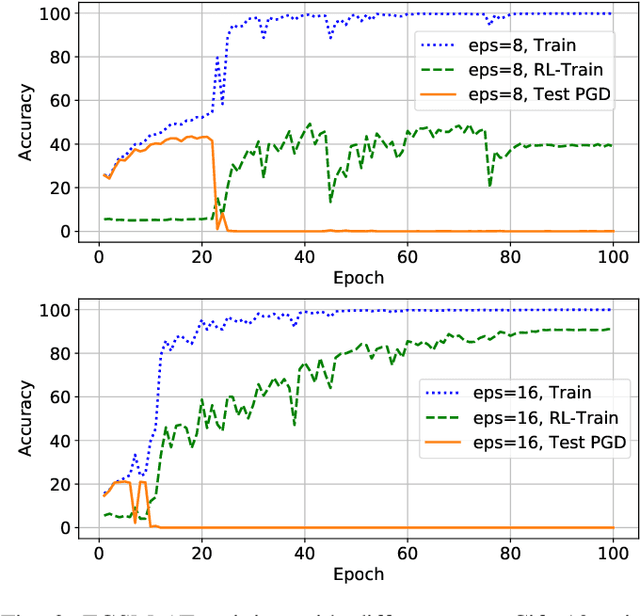
Although fast adversarial training provides an efficient approach for building robust networks, it may suffer from a serious problem known as catastrophic overfitting (CO), where the multi-step robust accuracy suddenly collapses to zero. In this paper, we for the first time decouple the FGSM examples into data-information and self-information, which reveals an interesting phenomenon called "self-fitting". Self-fitting, i.e., DNNs learn the self-information embedded in single-step perturbations, naturally leads to the occurrence of CO. When self-fitting occurs, the network experiences an obvious "channel differentiation" phenomenon that some convolution channels accounting for recognizing self-information become dominant, while others for data-information are suppressed. In this way, the network learns to only recognize images with sufficient self-information and loses generalization ability to other types of data. Based on self-fitting, we provide new insight into the existing methods to mitigate CO and extend CO to multi-step adversarial training. Our findings reveal a self-learning mechanism in adversarial training and open up new perspectives for suppressing different kinds of information to mitigate CO.