 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Contactless Human Activity Recognition using Deep Learning with Flexible and Scalable Software Define Radio
Apr 18, 2023
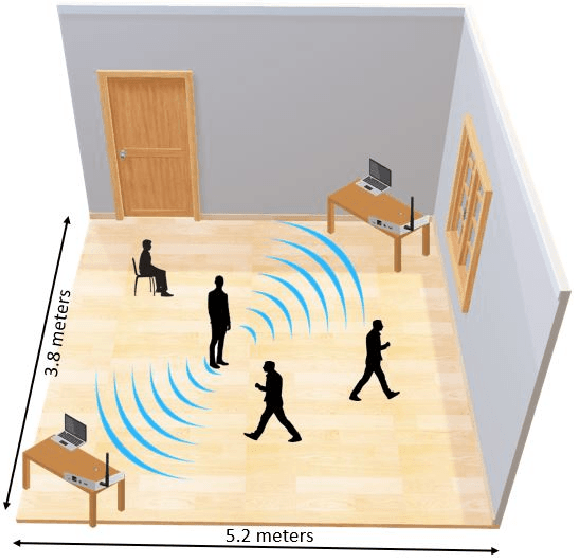

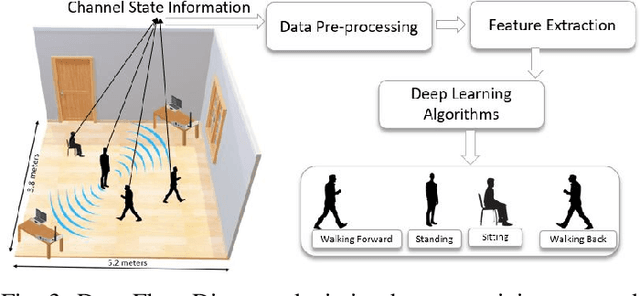
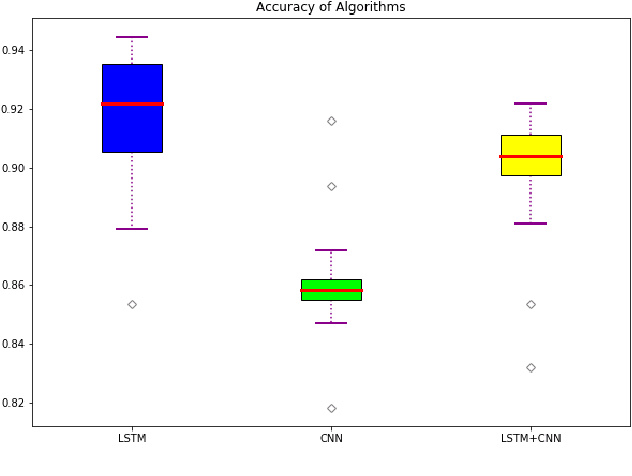
Ambient computing is gaining popularity as a major technological advancement for the future. The modern era has witnessed a surge in the advancement in healthcare systems, with viable radio frequency solutions proposed for remote and unobtrusive human activity recognition (HAR). Specifically, this study investigates the use of Wi-Fi channel state information (CSI) as a novel method of ambient sensing that can be employed as a contactless means of recognizing human activity in indoor environments. These methods avoid additional costly hardware required for vision-based systems, which are privacy-intrusive, by (re)using Wi-Fi CSI for various safety and security applications. During an experiment utilizing universal software-defined radio (USRP) to collect CSI samples, it was observed that a subject engaged in six distinct activities, which included no activity, standing, sitting, and leaning forward, across different areas of the room. Additionally, more CSI samples were collected when the subject walked in two different directions. This study presents a Wi-Fi CSI-based HAR system that assesses and contrasts deep learning approaches, namely convolutional neural network (CNN), long short-term memory (LSTM), and hybrid (LSTM+CNN), employed for accurate activity recognition. The experimental results indicate that LSTM surpasses current models and achieves an average accuracy of 95.3% in multi-activity classification when compared to CNN and hybrid techniques. In the future, research needs to study the significance of resilience in diverse and dynamic environments to identify the activity of multiple users.
Social Cue Analysis using Transfer Entropy
Mar 06, 2023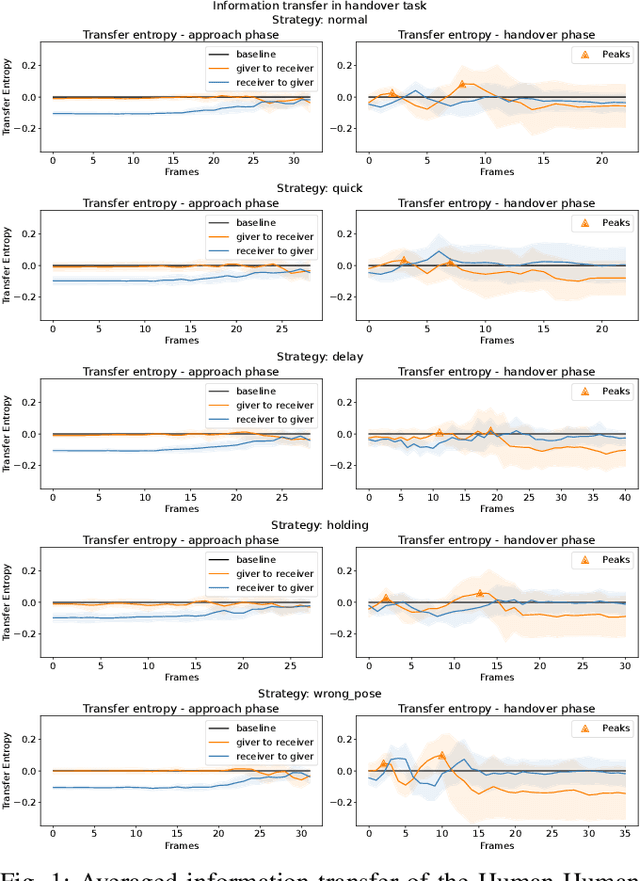
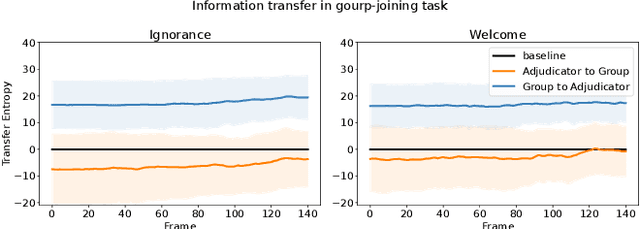
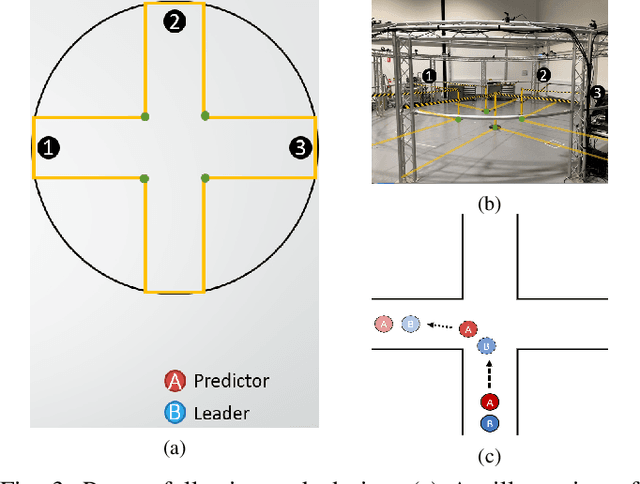
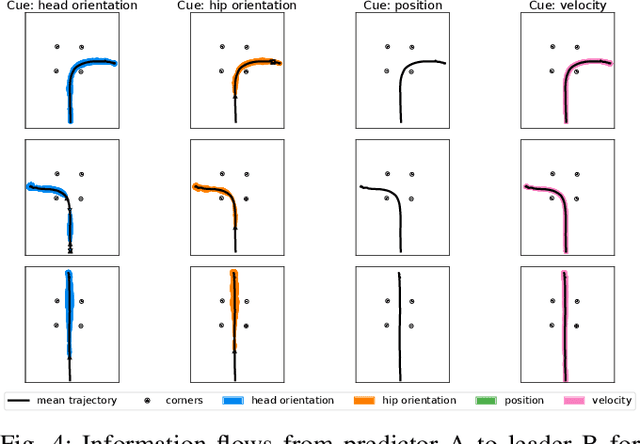
Robots that work close to humans need to understand and use social cues to act in a socially acceptable manner. Social cues are a form of communication (i.e., information flow) between people. In this paper, a framework is introduced to detect and analyse social cues and information transfer directionality using an information-theoretic measure, namely, transfer entropy. We demonstrate the framework in three settings involving social interactions between humans: object-handover, group-joining and person-following. Results show that transfer entropy can identify information flows between agents, when and where they occur, and their relative strength. For instance, in a person-following scenario, we find that head orientation of a predictor is particularly informative, and the different times and locations that this is used to convey information to a leader influences their behaviour. Potential applications of the framework include information flow or social cue analysis for interactive robot design, or socially-aware robot planning.
Loop Closure Detection Based on Object-level Spatial Layout and Semantic Consistency
Apr 14, 2023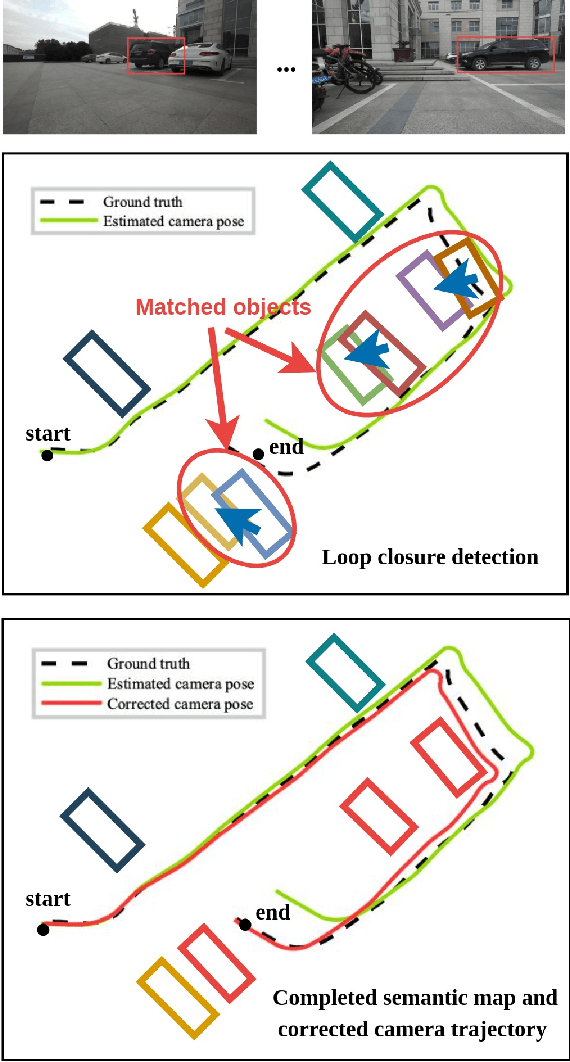
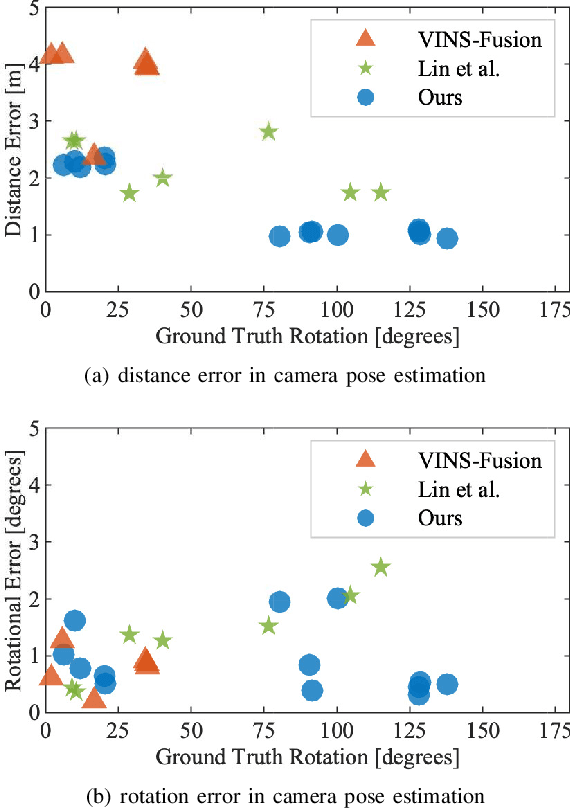
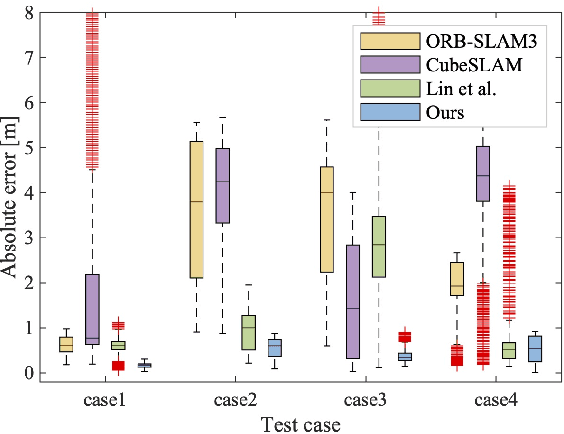
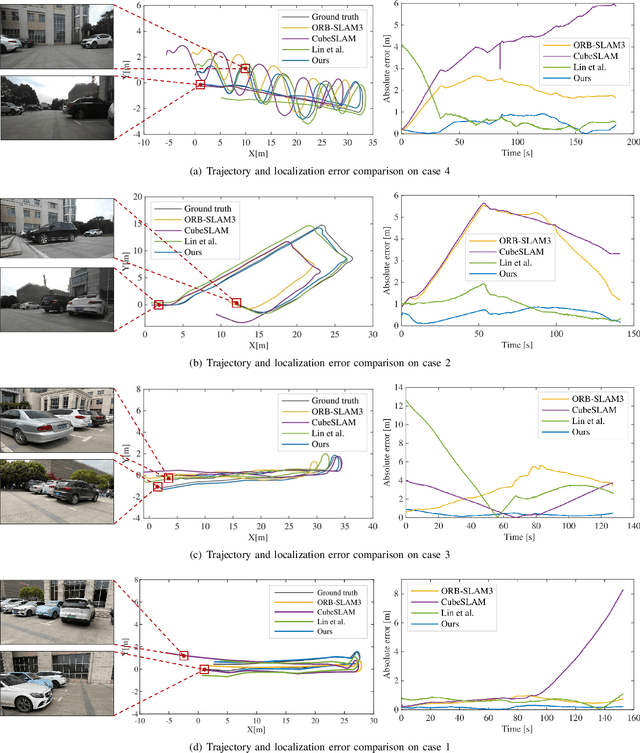
Visual simultaneous localization and mapping (SLAM) systems face challenges in detecting loop closure under the circumstance of large viewpoint changes. In this paper, we present an object-based loop closure detection method based on the spatial layout and semanic consistency of the 3D scene graph. Firstly, we propose an object-level data association approach based on the semantic information from semantic labels, intersection over union (IoU), object color, and object embedding. Subsequently, multi-view bundle adjustment with the associated objects is utilized to jointly optimize the poses of objects and cameras. We represent the refined objects as a 3D spatial graph with semantics and topology. Then, we propose a graph matching approach to select correspondence objects based on the structure layout and semantic property similarity of vertices' neighbors. Finally, we jointly optimize camera trajectories and object poses in an object-level pose graph optimization, which results in a globally consistent map. Experimental results demonstrate that our proposed data association approach can construct more accurate 3D semantic maps, and our loop closure method is more robust than point-based and object-based methods in circumstances with large viewpoint changes.
Learning Semantic-Aware Knowledge Guidance for Low-Light Image Enhancement
Apr 14, 2023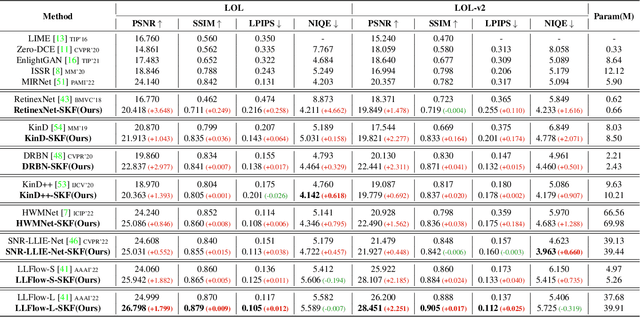
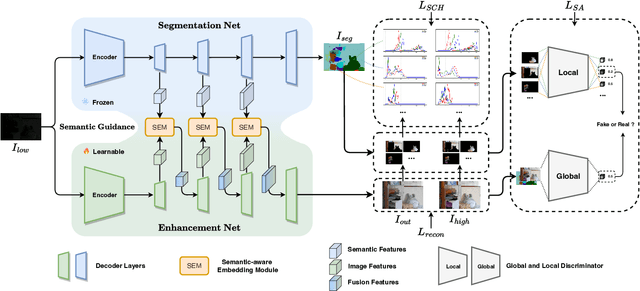
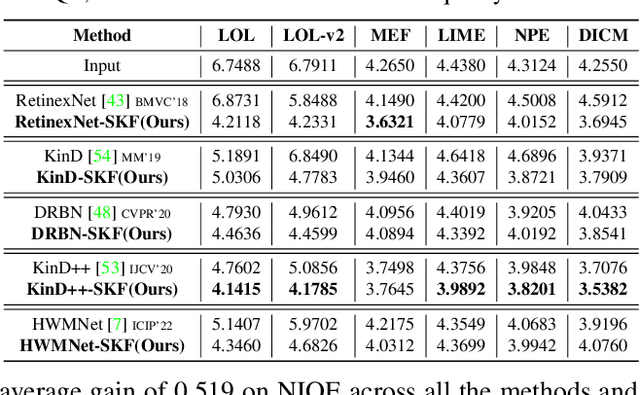
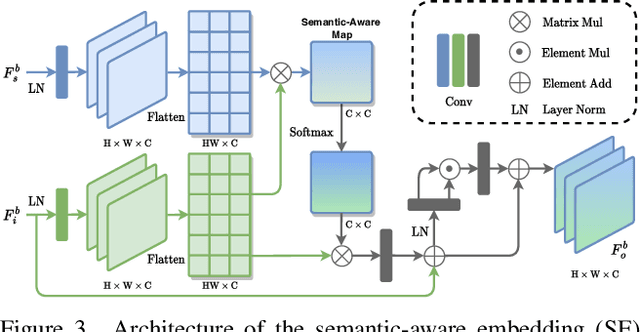
Low-light image enhancement (LLIE) investigates how to improve illumination and produce normal-light images. The majority of existing methods improve low-light images via a global and uniform manner, without taking into account the semantic information of different regions. Without semantic priors, a network may easily deviate from a region's original color. To address this issue, we propose a novel semantic-aware knowledge-guided framework (SKF) that can assist a low-light enhancement model in learning rich and diverse priors encapsulated in a semantic segmentation model. We concentrate on incorporating semantic knowledge from three key aspects: a semantic-aware embedding module that wisely integrates semantic priors in feature representation space, a semantic-guided color histogram loss that preserves color consistency of various instances, and a semantic-guided adversarial loss that produces more natural textures by semantic priors. Our SKF is appealing in acting as a general framework in LLIE task. Extensive experiments show that models equipped with the SKF significantly outperform the baselines on multiple datasets and our SKF generalizes to different models and scenes well. The code is available at Semantic-Aware-Low-Light-Image-Enhancement.
Memory Efficient Diffusion Probabilistic Models via Patch-based Generation
Apr 14, 2023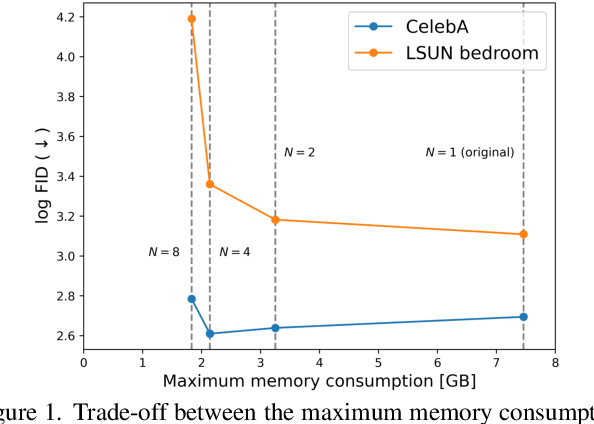
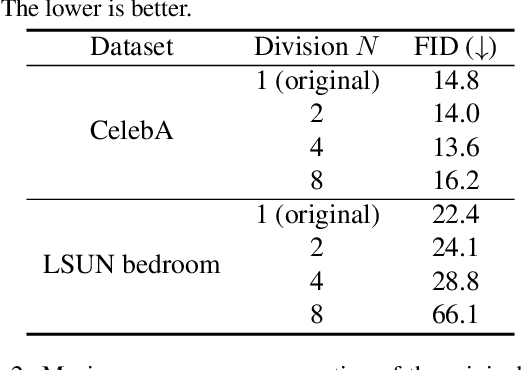
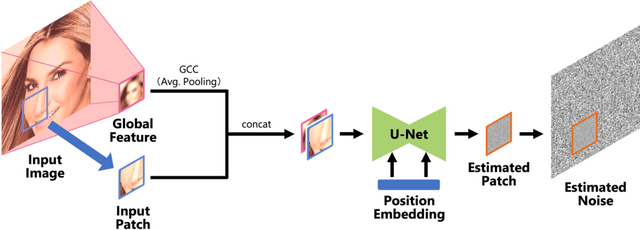

Diffusion probabilistic models have been successful in generating high-quality and diverse images. However, traditional models, whose input and output are high-resolution images, suffer from excessive memory requirements, making them less practical for edge devices. Previous approaches for generative adversarial networks proposed a patch-based method that uses positional encoding and global content information. Nevertheless, designing a patch-based approach for diffusion probabilistic models is non-trivial. In this paper, we resent a diffusion probabilistic model that generates images on a patch-by-patch basis. We propose two conditioning methods for a patch-based generation. First, we propose position-wise conditioning using one-hot representation to ensure patches are in proper positions. Second, we propose Global Content Conditioning (GCC) to ensure patches have coherent content when concatenated together. We evaluate our model qualitatively and quantitatively on CelebA and LSUN bedroom datasets and demonstrate a moderate trade-off between maximum memory consumption and generated image quality. Specifically, when an entire image is divided into 2 x 2 patches, our proposed approach can reduce the maximum memory consumption by half while maintaining comparable image quality.
Phantom Embeddings: Using Embedding Space for Model Regularization in Deep Neural Networks
Apr 14, 2023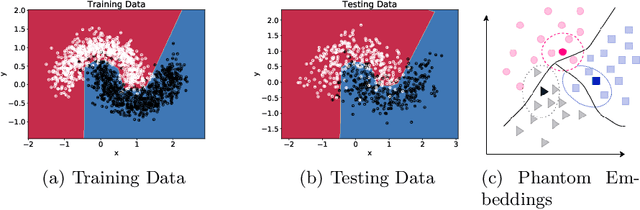
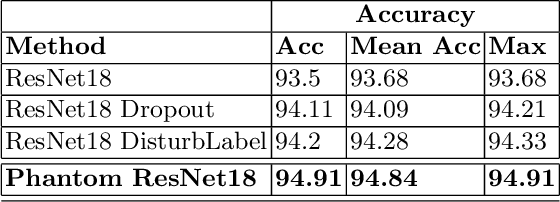
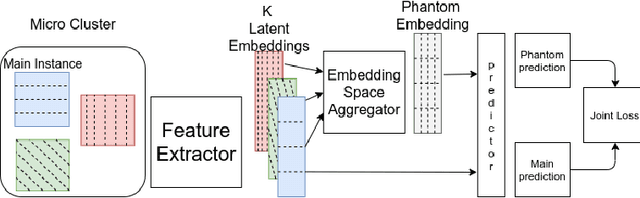
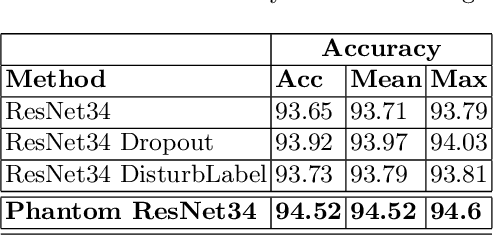
The strength of machine learning models stems from their ability to learn complex function approximations from data; however, this strength also makes training deep neural networks challenging. Notably, the complex models tend to memorize the training data, which results in poor regularization performance on test data. The regularization techniques such as L1, L2, dropout, etc. are proposed to reduce the overfitting effect; however, they bring in additional hyperparameters tuning complexity. These methods also fall short when the inter-class similarity is high due to the underlying data distribution, leading to a less accurate model. In this paper, we present a novel approach to regularize the models by leveraging the information-rich latent embeddings and their high intra-class correlation. We create phantom embeddings from a subset of homogenous samples and use these phantom embeddings to decrease the inter-class similarity of instances in their latent embedding space. The resulting models generalize better as a combination of their embedding and regularize them without requiring an expensive hyperparameter search. We evaluate our method on two popular and challenging image classification datasets (CIFAR and FashionMNIST) and show how our approach outperforms the standard baselines while displaying better training behavior.
A Dual-scale Lead-seperated Transformer With Lead-orthogonal Attention And Meta-information For Ecg Classification
Nov 23, 2022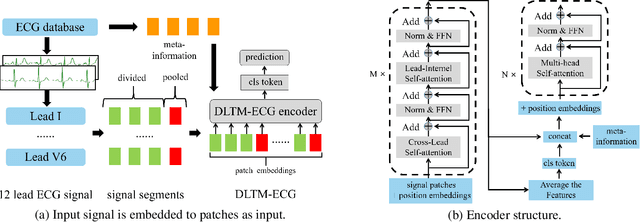
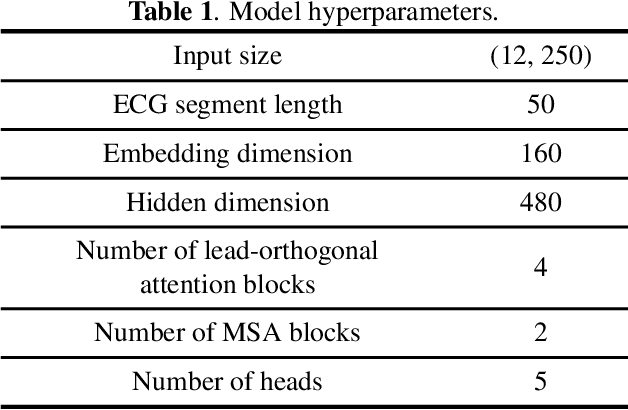
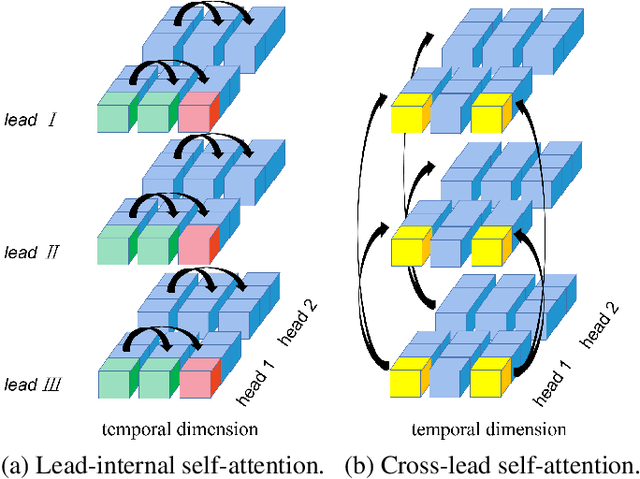

Auxiliary diagnosis of cardiac electrophysiological status can be obtained through the analysis of 12-lead electrocardiograms (ECGs). This work proposes a dual-scale lead-separated transformer with lead-orthogonal attention and meta-information (DLTM-ECG) as a novel approach to address this challenge. ECG segments of each lead are interpreted as independent patches, and together with the reduced dimension signal, they form a dual-scale representation. As a method to reduce interference from segments with low correlation, two group attention mechanisms perform both lead-internal and cross-lead attention. Our method allows for the addition of previously discarded meta-information, further improving the utilization of clinical information. Experimental results show that our DLTM-ECG yields significantly better classification scores than other transformer-based models,matching or performing better than state-of-the-art (SOTA) deep learning methods on two benchmark datasets. Our work has the potential for similar multichannel bioelectrical signal processing and physiological multimodal tasks.
DDT: A Diffusion-Driven Transformer-based Framework for Human Mesh Recovery from a Video
Mar 29, 2023

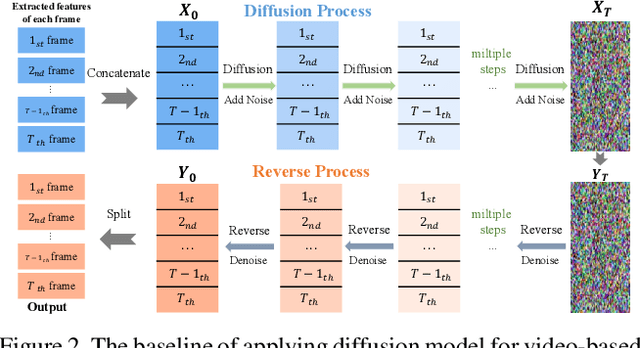
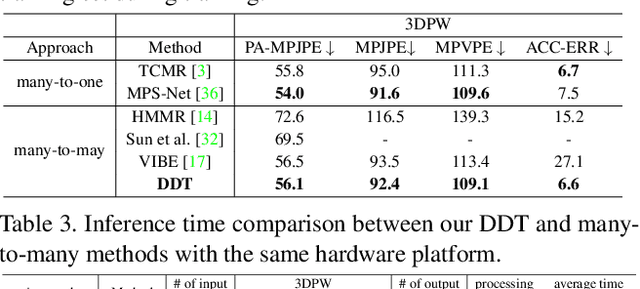
Human mesh recovery (HMR) provides rich human body information for various real-world applications such as gaming, human-computer interaction, and virtual reality. Compared to single image-based methods, video-based methods can utilize temporal information to further improve performance by incorporating human body motion priors. However, many-to-many approaches such as VIBE suffer from motion smoothness and temporal inconsistency. While many-to-one approaches such as TCMR and MPS-Net rely on the future frames, which is non-causal and time inefficient during inference. To address these challenges, a novel Diffusion-Driven Transformer-based framework (DDT) for video-based HMR is presented. DDT is designed to decode specific motion patterns from the input sequence, enhancing motion smoothness and temporal consistency. As a many-to-many approach, the decoder of our DDT outputs the human mesh of all the frames, making DDT more viable for real-world applications where time efficiency is crucial and a causal model is desired. Extensive experiments are conducted on the widely used datasets (Human3.6M, MPI-INF-3DHP, and 3DPW), which demonstrated the effectiveness and efficiency of our DDT.
Ideal Abstractions for Decision-Focused Learning
Mar 29, 2023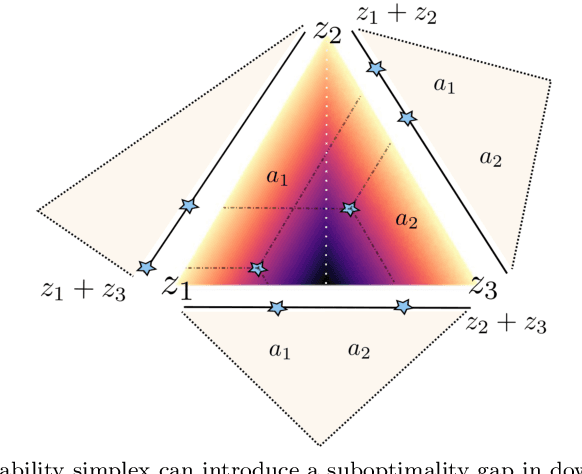
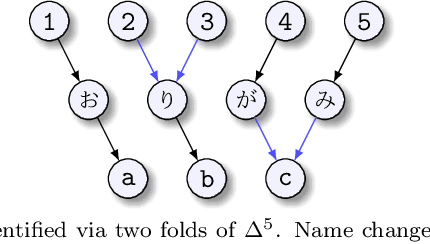
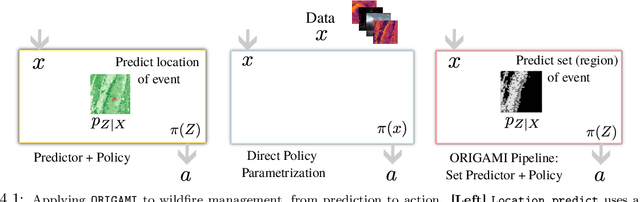
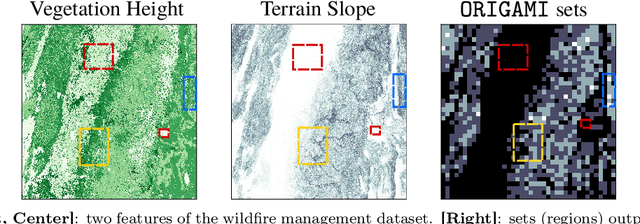
We present a methodology for formulating simplifying abstractions in machine learning systems by identifying and harnessing the utility structure of decisions. Machine learning tasks commonly involve high-dimensional output spaces (e.g., predictions for every pixel in an image or node in a graph), even though a coarser output would often suffice for downstream decision-making (e.g., regions of an image instead of pixels). Developers often hand-engineer abstractions of the output space, but numerous abstractions are possible and it is unclear how the choice of output space for a model impacts its usefulness in downstream decision-making. We propose a method that configures the output space automatically in order to minimize the loss of decision-relevant information. Taking a geometric perspective, we formulate a step of the algorithm as a projection of the probability simplex, termed fold, that minimizes the total loss of decision-related information in the H-entropy sense. Crucially, learning in the abstracted outcome space requires less data, leading to a net improvement in decision quality. We demonstrate the method in two domains: data acquisition for deep neural network training and a closed-loop wildfire management task.
Deep Reinforcement Learning for Distributed Dynamic Coordinated Beamforming in Massive MIMO Cellular Networks
Mar 24, 2023
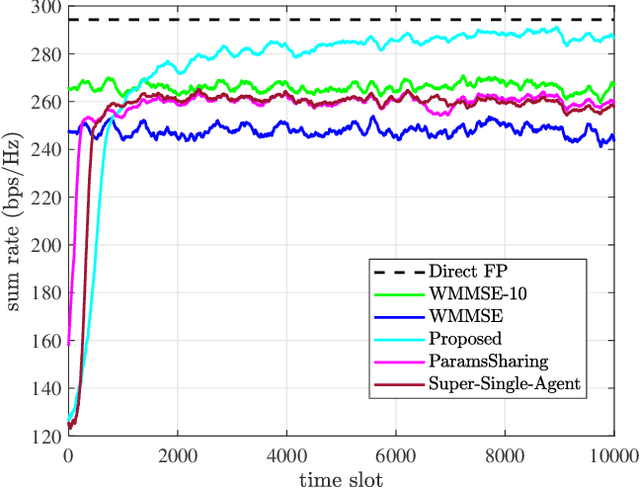
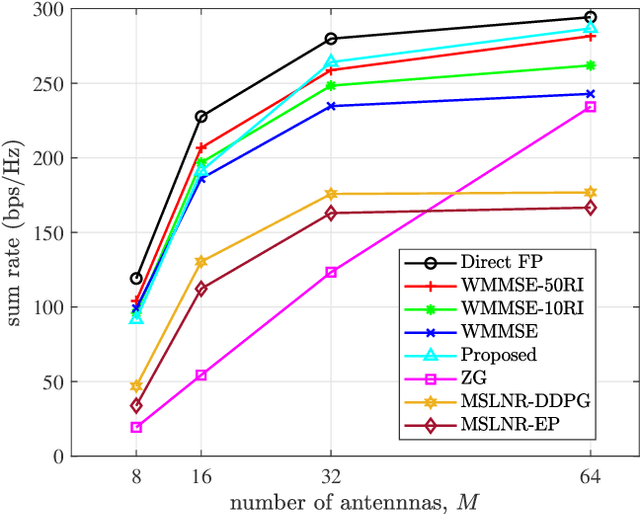
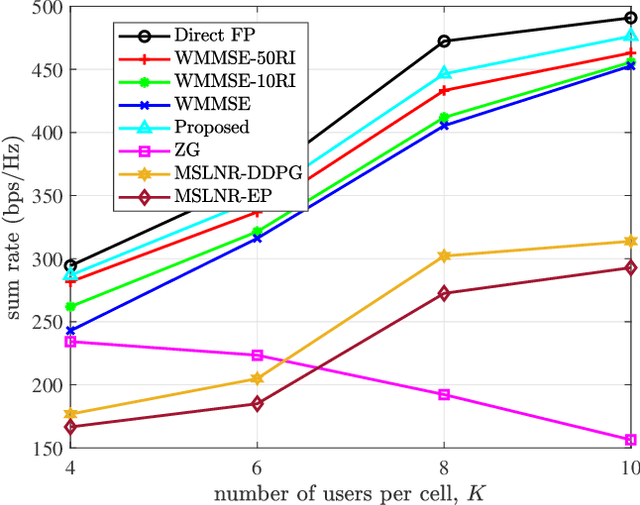
To accommodate the explosive wireless traffics, massive multiple-input multiple-output (MIMO) is regarded as one of the key enabling technologies for next-generation communication systems. In massive MIMO cellular networks, coordinated beamforming (CBF), which jointly designs the beamformers of multiple base stations (BSs), is an efficient method to enhance the network performance. In this paper, we investigate the sum rate maximization problem in a massive MIMO mobile cellular network, where in each cell a multi-antenna BS serves multiple mobile users simultaneously via downlink beamforming. Although existing optimization-based CBF algorithms can provide near-optimal solutions, they require realtime and global channel state information (CSI), in addition to their high computation complexity. It is almost impossible to apply them in practical wireless networks, especially highly dynamic mobile cellular networks. Motivated by this, we propose a deep reinforcement learning based distributed dynamic coordinated beamforming (DDCBF) framework, which enables each BS to determine the beamformers with only local CSI and some historical information from other BSs.Besides, the beamformers can be calculated with a considerably lower computational complexity by exploiting neural networks and expert knowledge, i.e., a solution structure observed from the iterative procedure of the weighted minimum mean square error (WMMSE) algorithm. Moreover, we provide extensive numerical simulations to validate the effectiveness of the proposed DRL-based approach. With lower computational complexity and less required information, the results show that the proposed approach can achieve comparable performance to the centralized iterative optimization algorithms.