 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
What does CLIP know about a red circle? Visual prompt engineering for VLMs
Apr 13, 2023

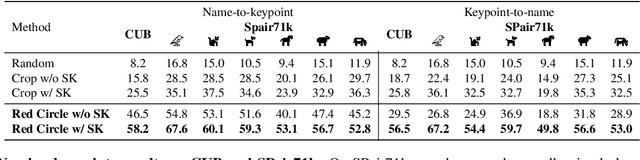
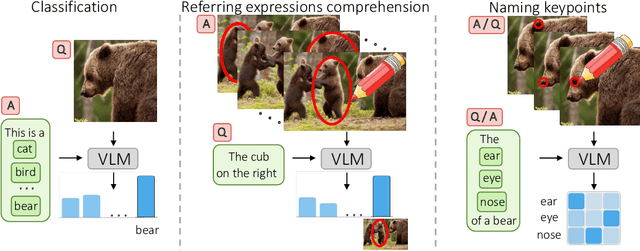

Large-scale Vision-Language Models, such as CLIP, learn powerful image-text representations that have found numerous applications, from zero-shot classification to text-to-image generation. Despite that, their capabilities for solving novel discriminative tasks via prompting fall behind those of large language models, such as GPT-3. Here we explore the idea of visual prompt engineering for solving computer vision tasks beyond classification by editing in image space instead of text. In particular, we discover an emergent ability of CLIP, where, by simply drawing a red circle around an object, we can direct the model's attention to that region, while also maintaining global information. We show the power of this simple approach by achieving state-of-the-art in zero-shot referring expressions comprehension and strong performance in keypoint localization tasks. Finally, we draw attention to some potential ethical concerns of large language-vision models.
Quantifying and Explaining Machine Learning Uncertainty in Predictive Process Monitoring: An Operations Research Perspective
Apr 13, 2023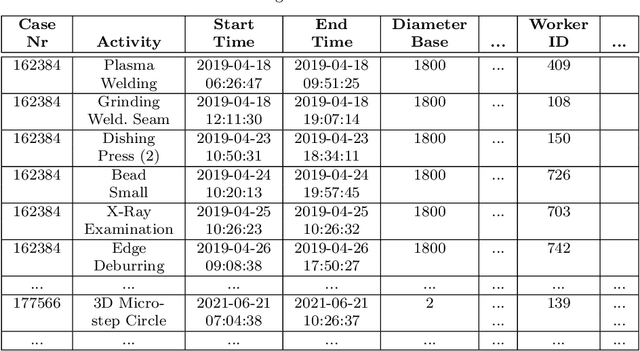
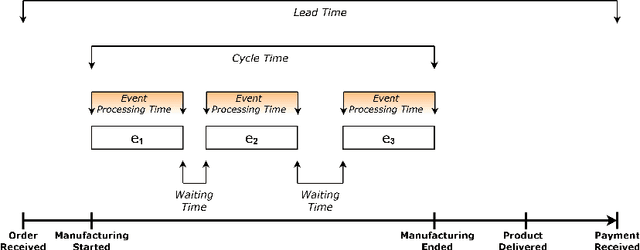
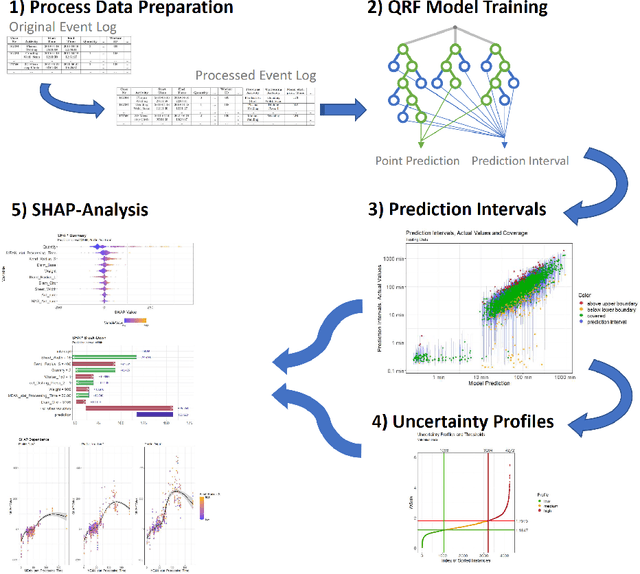
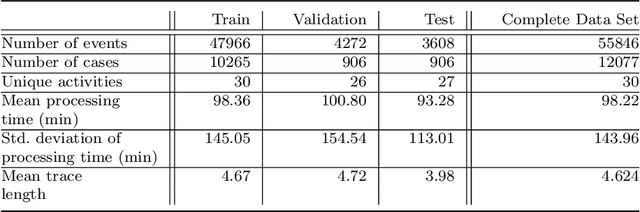
This paper introduces a comprehensive, multi-stage machine learning methodology that effectively integrates information systems and artificial intelligence to enhance decision-making processes within the domain of operations research. The proposed framework adeptly addresses common limitations of existing solutions, such as the neglect of data-driven estimation for vital production parameters, exclusive generation of point forecasts without considering model uncertainty, and lacking explanations regarding the sources of such uncertainty. Our approach employs Quantile Regression Forests for generating interval predictions, alongside both local and global variants of SHapley Additive Explanations for the examined predictive process monitoring problem. The practical applicability of the proposed methodology is substantiated through a real-world production planning case study, emphasizing the potential of prescriptive analytics in refining decision-making procedures. This paper accentuates the imperative of addressing these challenges to fully harness the extensive and rich data resources accessible for well-informed decision-making.
CLIP-Lung: Textual Knowledge-Guided Lung Nodule Malignancy Prediction
Apr 17, 2023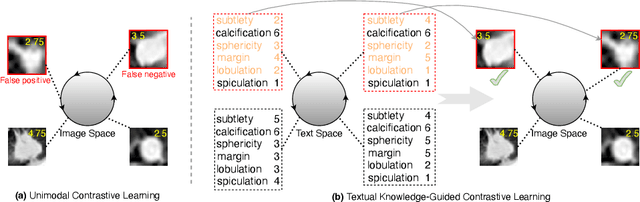
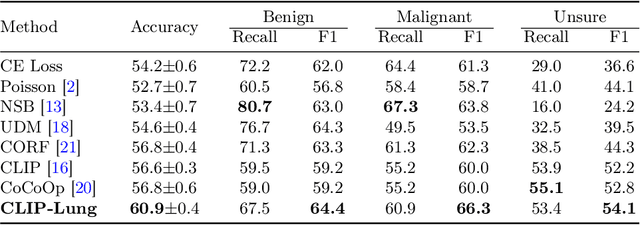


Lung nodule malignancy prediction has been enhanced by advanced deep-learning techniques and effective tricks. Nevertheless, current methods are mainly trained with cross-entropy loss using one-hot categorical labels, which results in difficulty in distinguishing those nodules with closer progression labels. Interestingly, we observe that clinical text information annotated by radiologists provides us with discriminative knowledge to identify challenging samples. Drawing on the capability of the contrastive language-image pre-training (CLIP) model to learn generalized visual representations from text annotations, in this paper, we propose CLIP-Lung, a textual knowledge-guided framework for lung nodule malignancy prediction. First, CLIP-Lung introduces both class and attribute annotations into the training of the lung nodule classifier without any additional overheads in inference. Second, we designed a channel-wise conditional prompt (CCP) module to establish consistent relationships between learnable context prompts and specific feature maps. Third, we align image features with both class and attribute features via contrastive learning, rectifying false positives and false negatives in latent space. The experimental results on the benchmark LIDC-IDRI dataset have demonstrated the superiority of CLIP-Lung, both in classification performance and interpretability of attention maps.
SDVRF: Sparse-to-Dense Voxel Region Fusion for Multi-modal 3D Object Detection
Apr 17, 2023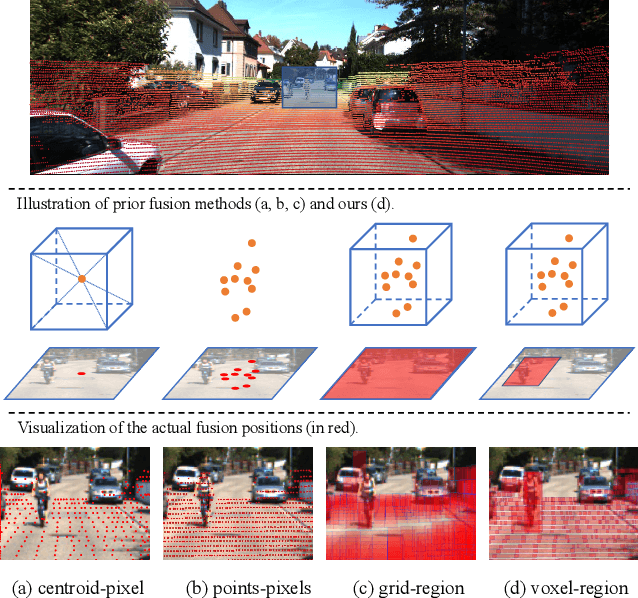
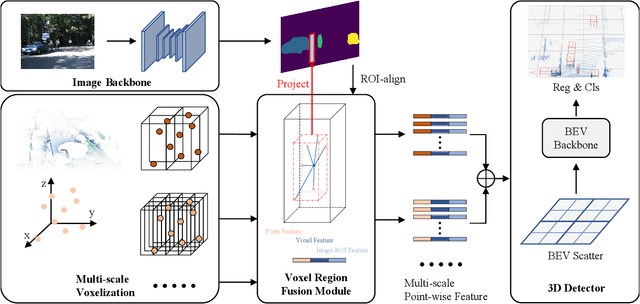
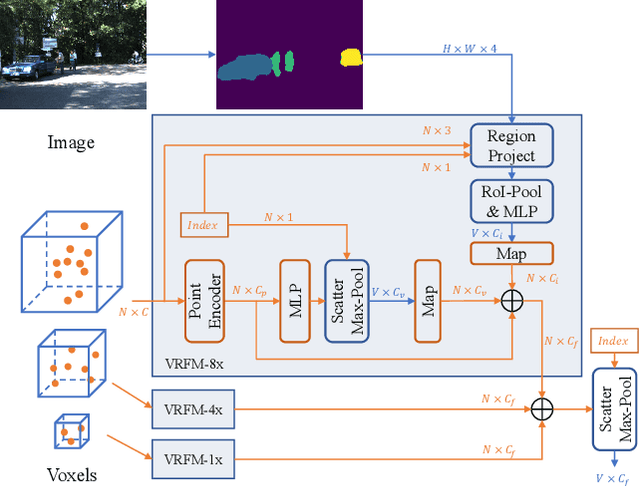

In the perception task of autonomous driving, multi-modal methods have become a trend due to the complementary characteristics of LiDAR point clouds and image data. However, the performance of previous methods is usually limited by the sparsity of the point cloud or the noise problem caused by the misalignment between LiDAR and the camera. To solve these two problems, we present a new concept, Voxel Region (VR), which is obtained by projecting the sparse local point clouds in each voxel dynamically. And we propose a novel fusion method, named Sparse-to-Dense Voxel Region Fusion (SDVRF). Specifically, more pixels of the image feature map inside the VR are gathered to supplement the voxel feature extracted from sparse points and achieve denser fusion. Meanwhile, different from prior methods, which project the size-fixed grids, our strategy of generating dynamic regions achieves better alignment and avoids introducing too much background noise. Furthermore, we propose a multi-scale fusion framework to extract more contextual information and capture the features of objects of different sizes. Experiments on the KITTI dataset show that our method improves the performance of different baselines, especially on classes of small size, including Pedestrian and Cyclist.
Cross or Wait? Predicting Pedestrian Interaction Outcomes at Unsignalized Crossings
Apr 17, 2023

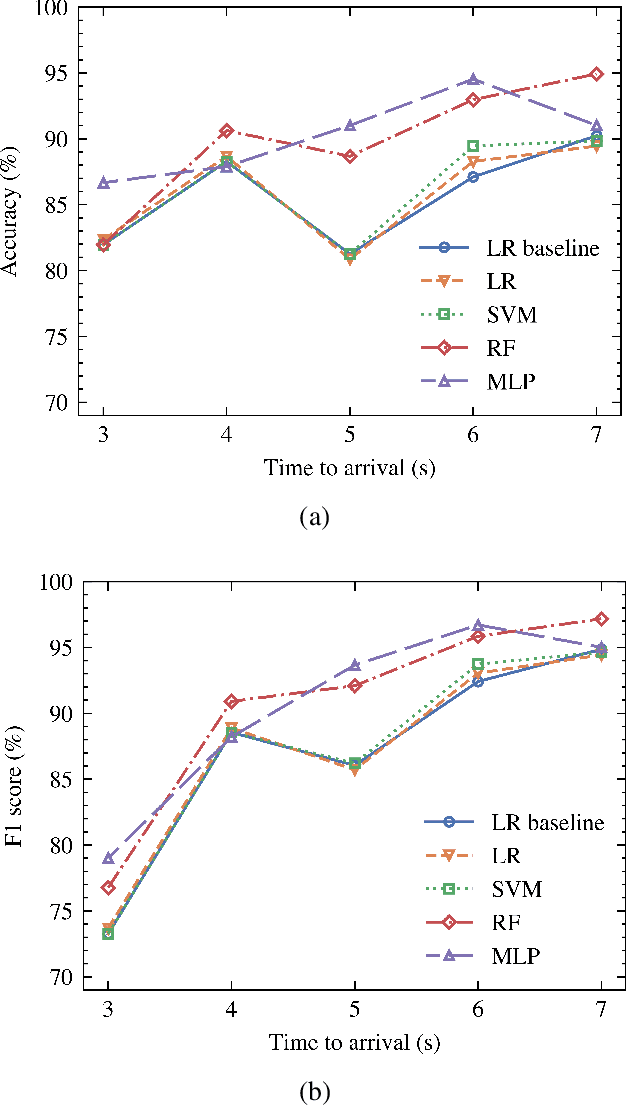
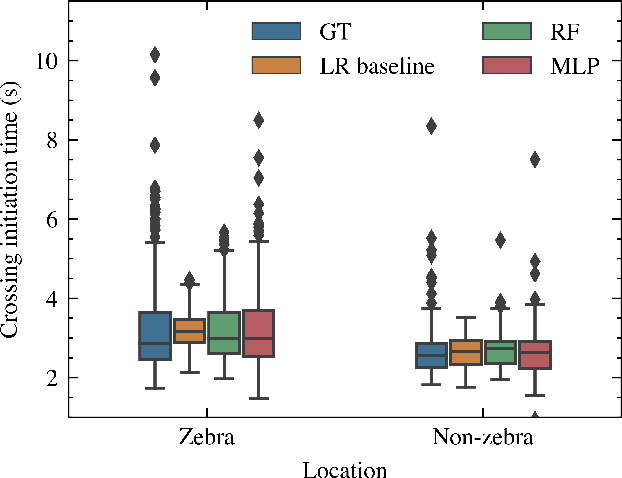
Predicting pedestrian behavior when interacting with vehicles is one of the most critical challenges in the field of automated driving. Pedestrian crossing behavior is influenced by various interaction factors, including time to arrival, pedestrian waiting time, the presence of zebra crossing, and the properties and personality traits of both pedestrians and drivers. However, these factors have not been fully explored for use in predicting interaction outcomes. In this paper, we use machine learning to predict pedestrian crossing behavior including pedestrian crossing decision, crossing initiation time (CIT), and crossing duration (CD) when interacting with vehicles at unsignalized crossings. Distributed simulator data are utilized for predicting and analyzing the interaction factors. Compared with the logistic regression baseline model, our proposed neural network model improves the prediction accuracy and F1 score by 4.46% and 3.23%, respectively. Our model also reduces the root mean squared error (RMSE) for CIT and CD by 21.56% and 30.14% compared with the linear regression model. Additionally, we have analyzed the importance of interaction factors, and present the results of models using fewer factors. This provides information for model selection in different scenarios with limited input features.
Balancing Unobserved Confounding with a Few Unbiased Ratings in Debiased Recommendations
Apr 17, 2023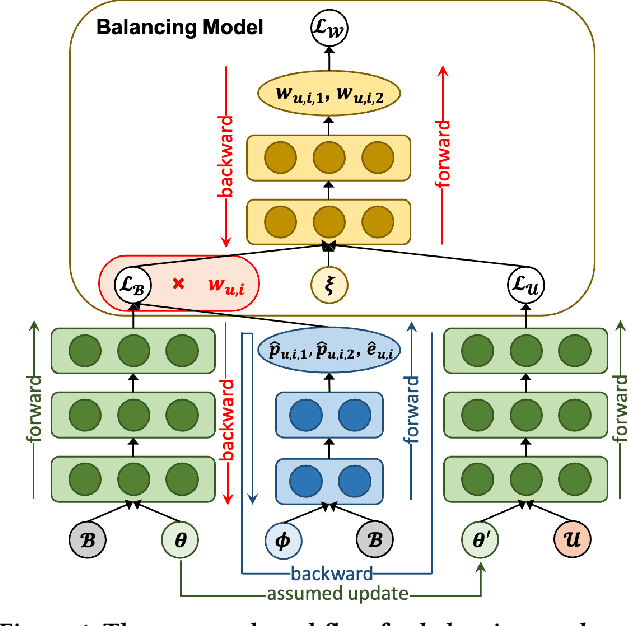
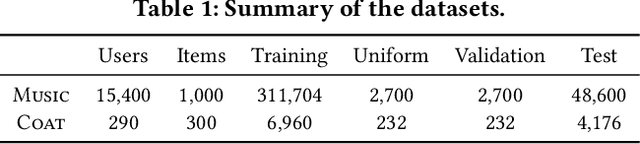
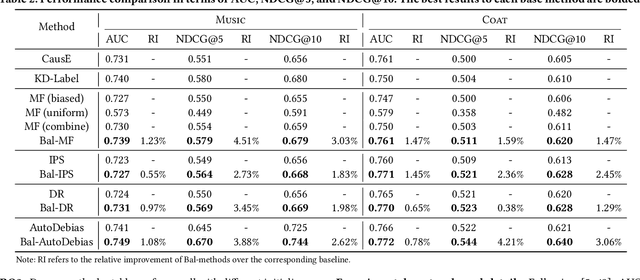
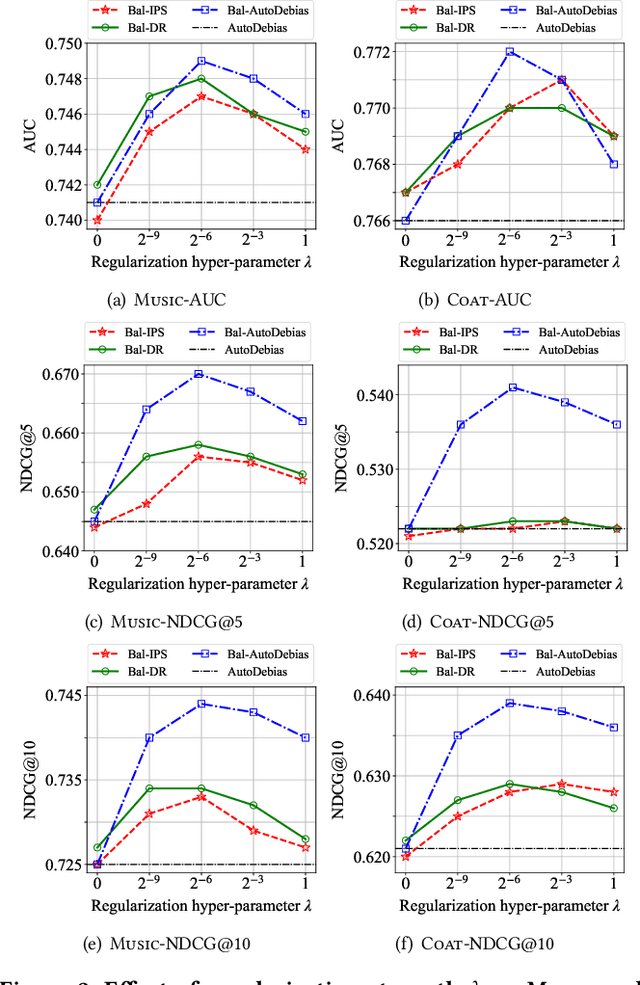
Recommender systems are seen as an effective tool to address information overload, but it is widely known that the presence of various biases makes direct training on large-scale observational data result in sub-optimal prediction performance. In contrast, unbiased ratings obtained from randomized controlled trials or A/B tests are considered to be the golden standard, but are costly and small in scale in reality. To exploit both types of data, recent works proposed to use unbiased ratings to correct the parameters of the propensity or imputation models trained on the biased dataset. However, the existing methods fail to obtain accurate predictions in the presence of unobserved confounding or model misspecification. In this paper, we propose a theoretically guaranteed model-agnostic balancing approach that can be applied to any existing debiasing method with the aim of combating unobserved confounding and model misspecification. The proposed approach makes full use of unbiased data by alternatively correcting model parameters learned with biased data, and adaptively learning balance coefficients of biased samples for further debiasing. Extensive real-world experiments are conducted along with the deployment of our proposal on four representative debiasing methods to demonstrate the effectiveness.
* Accepted Paper in WWW'23
Universal Adversarial Backdoor Attacks to Fool Vertical Federated Learning in Cloud-Edge Collaboration
Apr 22, 2023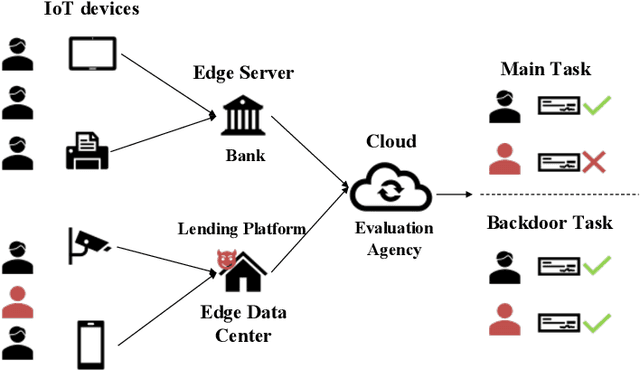
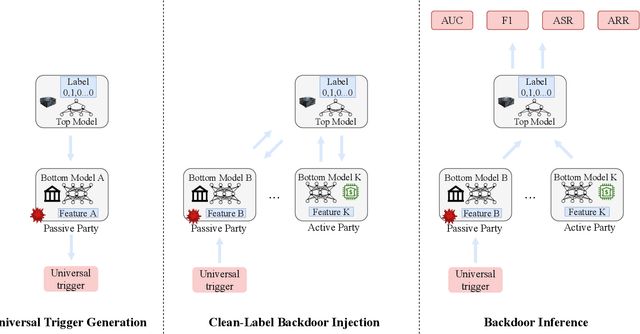
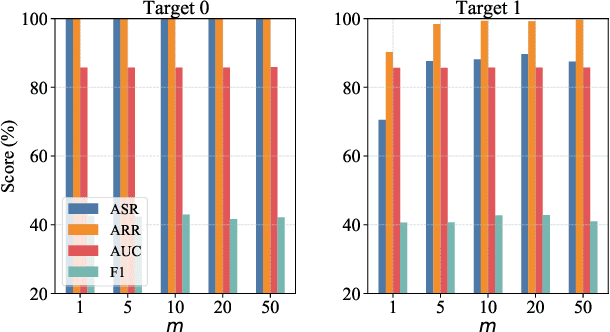
Vertical federated learning (VFL) is a cloud-edge collaboration paradigm that enables edge nodes, comprising resource-constrained Internet of Things (IoT) devices, to cooperatively train artificial intelligence (AI) models while retaining their data locally. This paradigm facilitates improved privacy and security for edges and IoT devices, making VFL an essential component of Artificial Intelligence of Things (AIoT) systems. Nevertheless, the partitioned structure of VFL can be exploited by adversaries to inject a backdoor, enabling them to manipulate the VFL predictions. In this paper, we aim to investigate the vulnerability of VFL in the context of binary classification tasks. To this end, we define a threat model for backdoor attacks in VFL and introduce a universal adversarial backdoor (UAB) attack to poison the predictions of VFL. The UAB attack, consisting of universal trigger generation and clean-label backdoor injection, is incorporated during the VFL training at specific iterations. This is achieved by alternately optimizing the universal trigger and model parameters of VFL sub-problems. Our work distinguishes itself from existing studies on designing backdoor attacks for VFL, as those require the knowledge of auxiliary information not accessible within the split VFL architecture. In contrast, our approach does not necessitate any additional data to execute the attack. On the LendingClub and Zhongyuan datasets, our approach surpasses existing state-of-the-art methods, achieving up to 100\% backdoor task performance while maintaining the main task performance. Our results in this paper make a major advance to revealing the hidden backdoor risks of VFL, hence paving the way for the future development of secure AIoT.
3D-IntPhys: Towards More Generalized 3D-grounded Visual Intuitive Physics under Challenging Scenes
Apr 22, 2023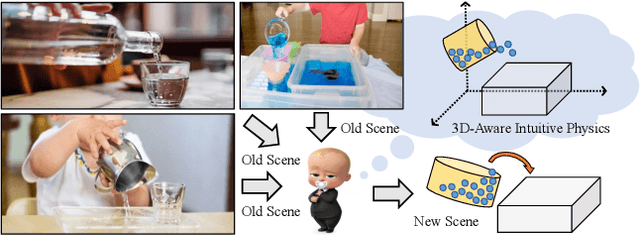
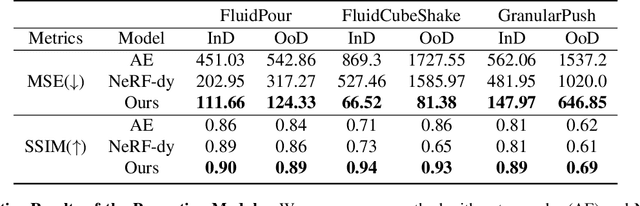
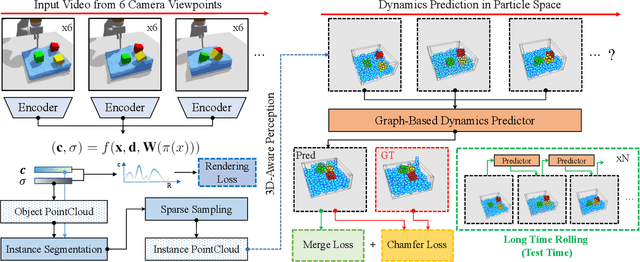
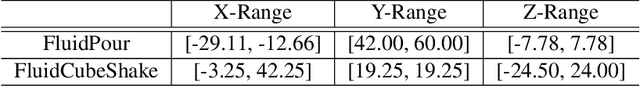
Given a visual scene, humans have strong intuitions about how a scene can evolve over time under given actions. The intuition, often termed visual intuitive physics, is a critical ability that allows us to make effective plans to manipulate the scene to achieve desired outcomes without relying on extensive trial and error. In this paper, we present a framework capable of learning 3D-grounded visual intuitive physics models from videos of complex scenes with fluids. Our method is composed of a conditional Neural Radiance Field (NeRF)-style visual frontend and a 3D point-based dynamics prediction backend, using which we can impose strong relational and structural inductive bias to capture the structure of the underlying environment. Unlike existing intuitive point-based dynamics works that rely on the supervision of dense point trajectory from simulators, we relax the requirements and only assume access to multi-view RGB images and (imperfect) instance masks acquired using color prior. This enables the proposed model to handle scenarios where accurate point estimation and tracking are hard or impossible. We generate datasets including three challenging scenarios involving fluid, granular materials, and rigid objects in the simulation. The datasets do not include any dense particle information so most previous 3D-based intuitive physics pipelines can barely deal with that. We show our model can make long-horizon future predictions by learning from raw images and significantly outperforms models that do not employ an explicit 3D representation space. We also show that once trained, our model can achieve strong generalization in complex scenarios under extrapolate settings.
Towards Carbon-Neutral Edge Computing: Greening Edge AI by Harnessing Spot and Future Carbon Markets
Apr 22, 2023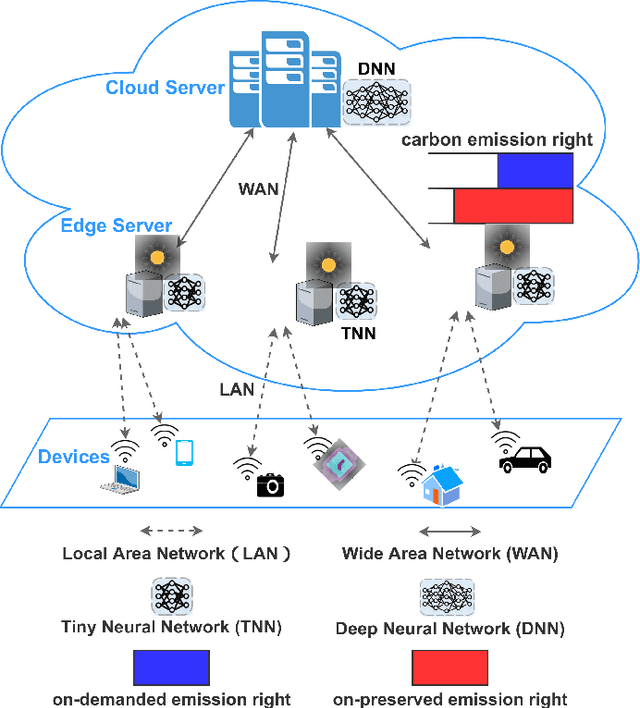
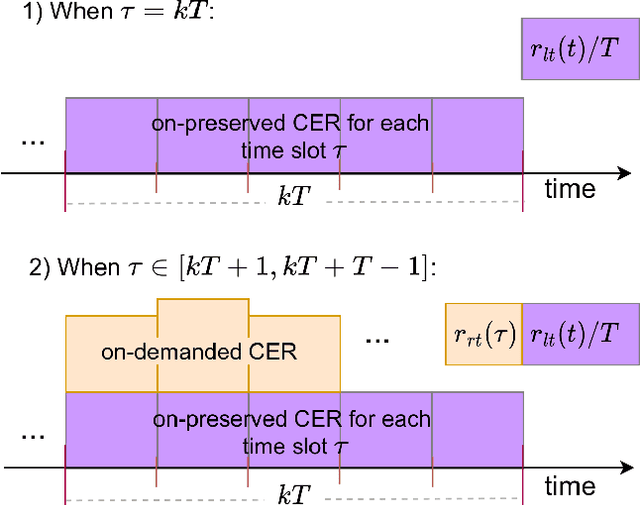
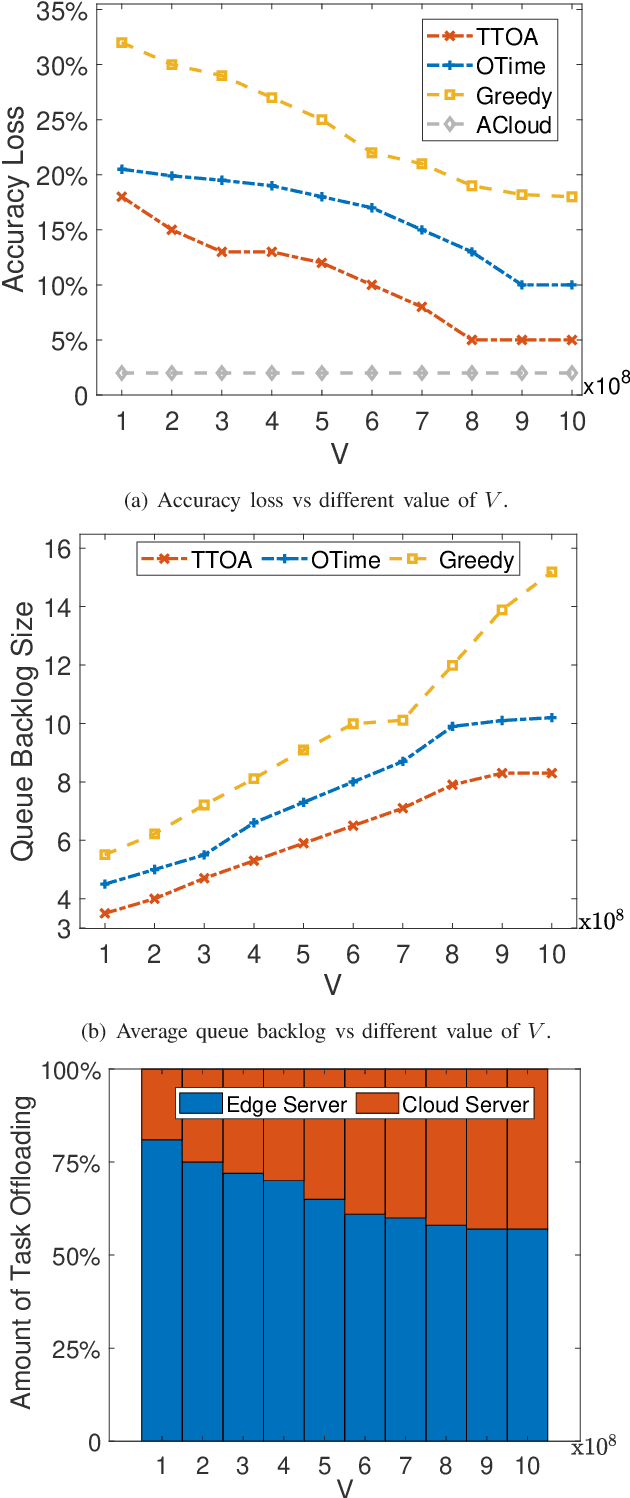
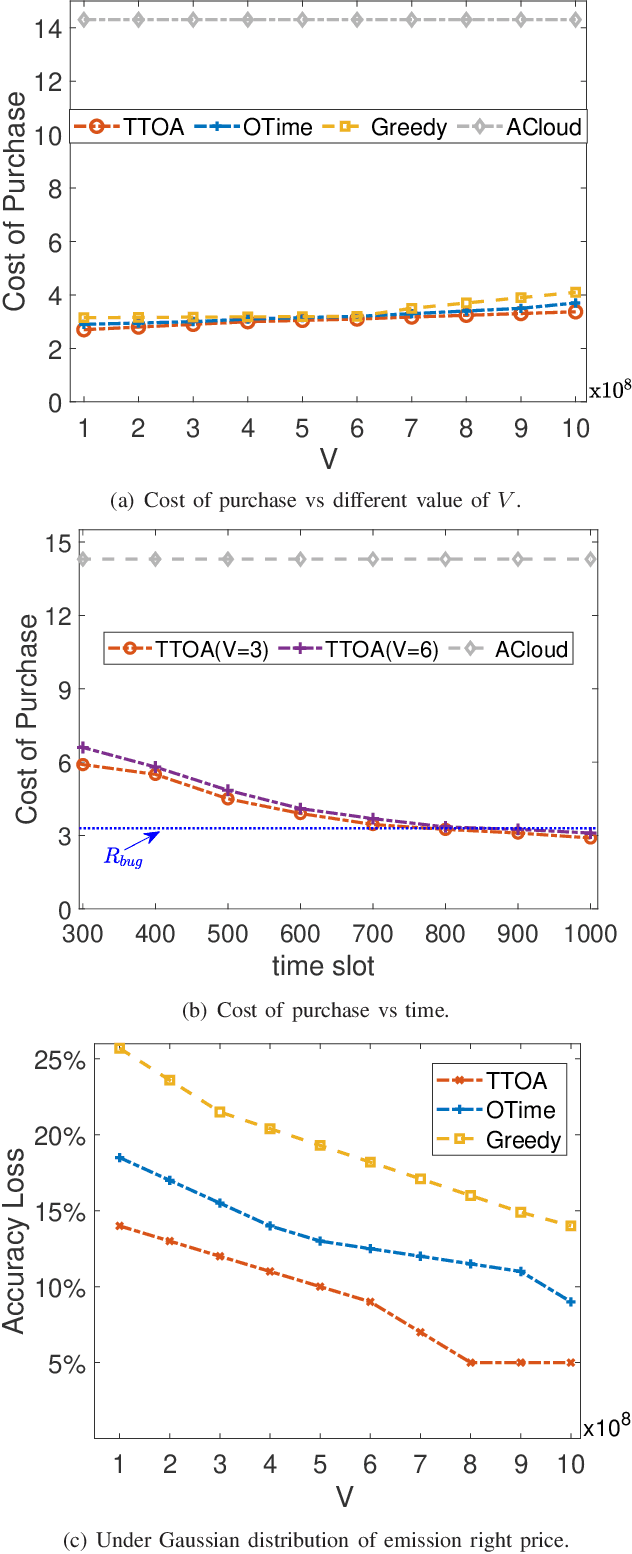
Provisioning dynamic machine learning (ML) inference as a service for artificial intelligence (AI) applications of edge devices faces many challenges, including the trade-off among accuracy loss, carbon emission, and unknown future costs. Besides, many governments are launching carbon emission rights (CER) for operators to reduce carbon emissions further to reverse climate change. Facing these challenges, to achieve carbon-aware ML task offloading under limited carbon emission rights thus to achieve green edge AI, we establish a joint ML task offloading and CER purchasing problem, intending to minimize the accuracy loss under the long-term time-averaged cost budget of purchasing the required CER. However, considering the uncertainty of the resource prices, the CER purchasing prices, the carbon intensity of sites, and ML tasks' arrivals, it is hard to decide the optimal policy online over a long-running period time. To overcome this difficulty, we leverage the two-timescale Lyapunov optimization technique, of which the $T$-slot drift-plus-penalty methodology inspires us to propose an online algorithm that purchases CER in multiple timescales (on-preserved in carbon future market and on-demanded in the carbon spot market) and makes decisions about where to offload ML tasks. Considering the NP-hardness of the $T$-slot problems, we further propose the resource-restricted randomized dependent rounding algorithm to help to gain the near-optimal solution with no help of any future information. Our theoretical analysis and extensive simulation results driven by the real carbon intensity trace show the superior performance of the proposed algorithms.
Exploring Diffusion Models for Unsupervised Video Anomaly Detection
Apr 12, 2023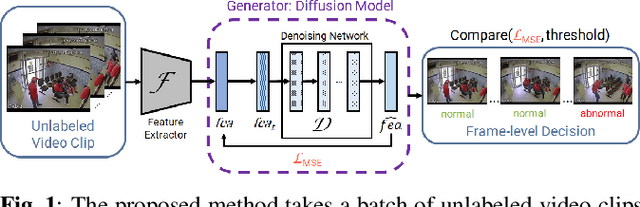

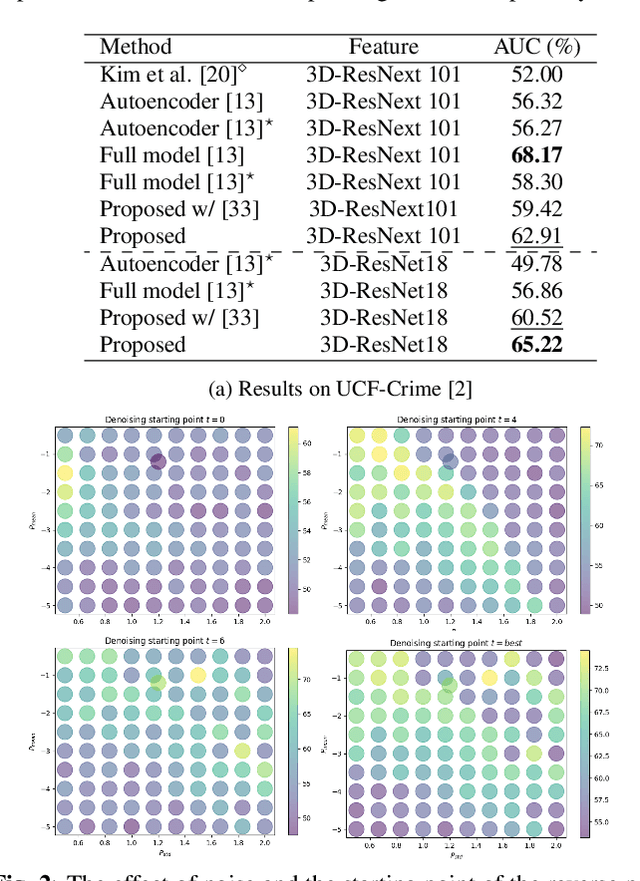
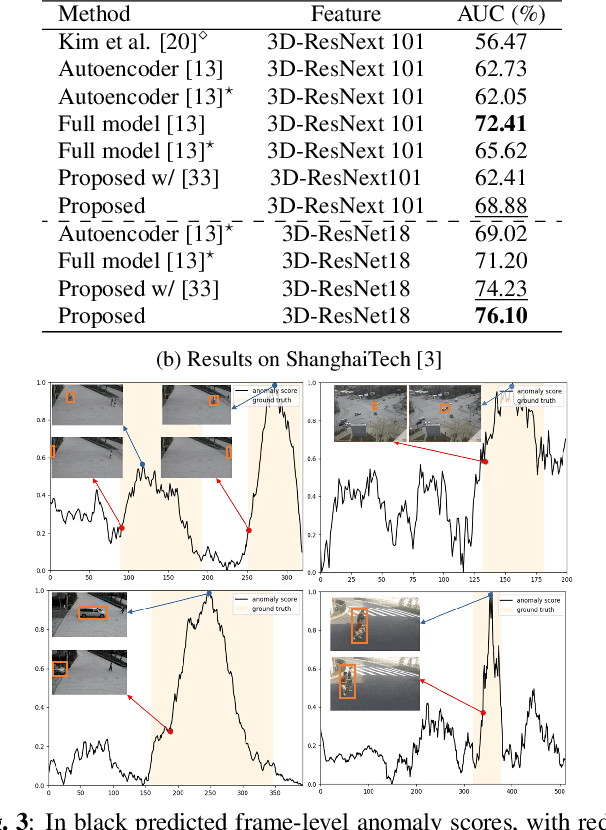
This paper investigates the performance of diffusion models for video anomaly detection (VAD) within the most challenging but also the most operational scenario in which the data annotations are not used. As being sparse, diverse, contextual, and often ambiguous, detecting abnormal events precisely is a very ambitious task. To this end, we rely only on the information-rich spatio-temporal data, and the reconstruction power of the diffusion models such that a high reconstruction error is utilized to decide the abnormality. Experiments performed on two large-scale video anomaly detection datasets demonstrate the consistent improvement of the proposed method over the state-of-the-art generative models while in some cases our method achieves better scores than the more complex models. This is the first study using a diffusion model and examining its parameters' influence to present guidance for VAD in surveillance scenarios.