 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DataChat: Prototyping a Conversational Agent for Dataset Search and Visualization
May 26, 2023
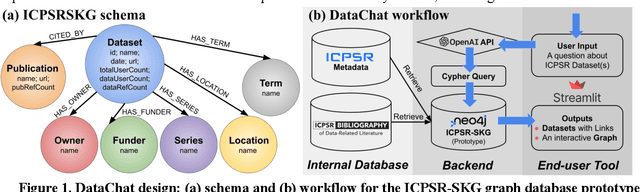
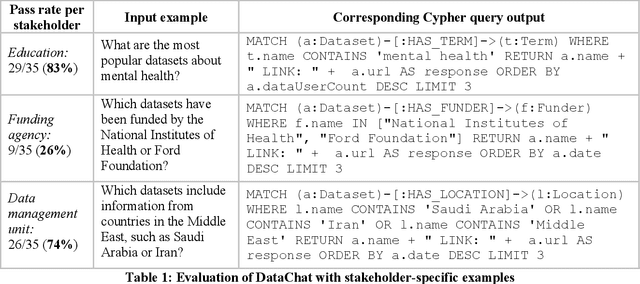
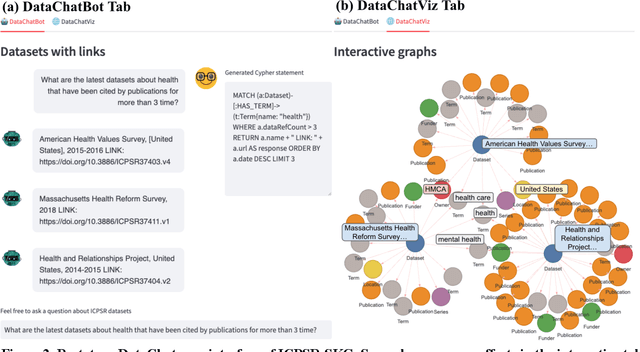
Data users need relevant context and research expertise to effectively search for and identify relevant datasets. Leading data providers, such as the Inter-university Consortium for Political and Social Research (ICPSR), offer standardized metadata and search tools to support data search. Metadata standards emphasize the machine-readability of data and its documentation. There are opportunities to enhance dataset search by improving users' ability to learn about, and make sense of, information about data. Prior research has shown that context and expertise are two main barriers users face in effectively searching for, evaluating, and deciding whether to reuse data. In this paper, we propose a novel chatbot-based search system, DataChat, that leverages a graph database and a large language model to provide novel ways for users to interact with and search for research data. DataChat complements data archives' and institutional repositories' ongoing efforts to curate, preserve, and share research data for reuse by making it easier for users to explore and learn about available research data.
Robustness of Multi-Source MT to Transcription Errors
May 26, 2023
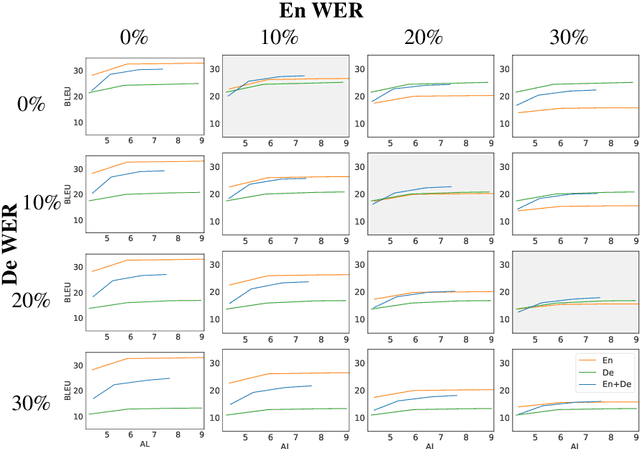

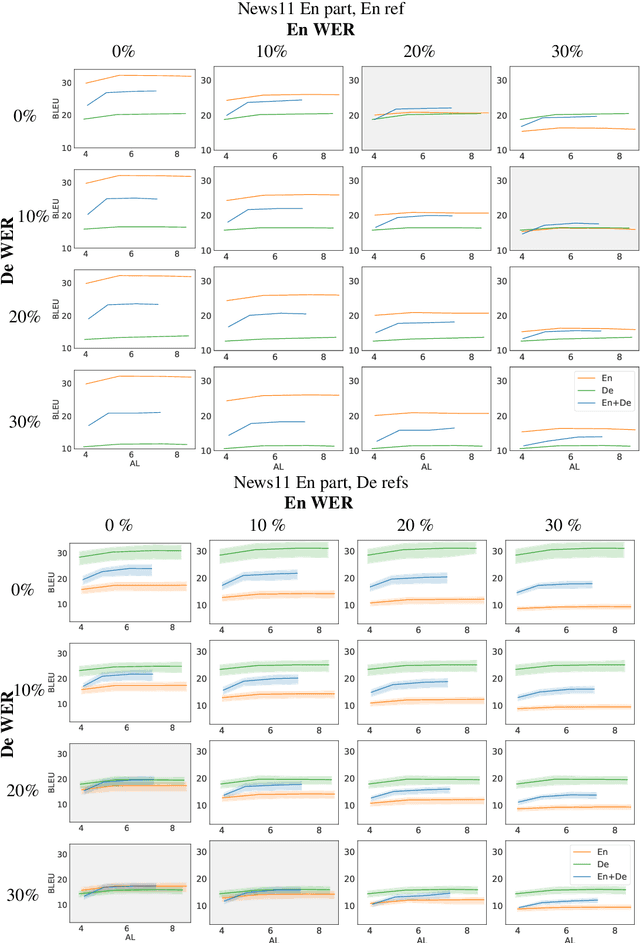
Automatic speech translation is sensitive to speech recognition errors, but in a multilingual scenario, the same content may be available in various languages via simultaneous interpreting, dubbing or subtitling. In this paper, we hypothesize that leveraging multiple sources will improve translation quality if the sources complement one another in terms of correct information they contain. To this end, we first show that on a 10-hour ESIC corpus, the ASR errors in the original English speech and its simultaneous interpreting into German and Czech are mutually independent. We then use two sources, English and German, in a multi-source setting for translation into Czech to establish its robustness to ASR errors. Furthermore, we observe this robustness when translating both noisy sources together in a simultaneous translation setting. Our results show that multi-source neural machine translation has the potential to be useful in a real-time simultaneous translation setting, thereby motivating further investigation in this area.
Multimodal Information Fusion For The Diagnosis Of Diabetic Retinopathy
Mar 20, 2023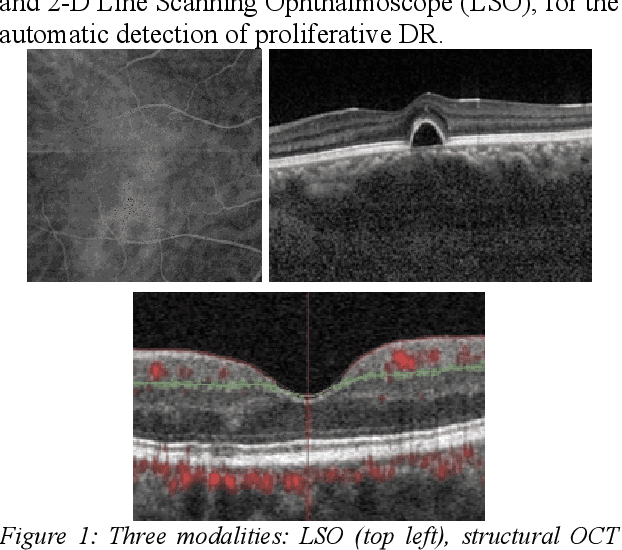

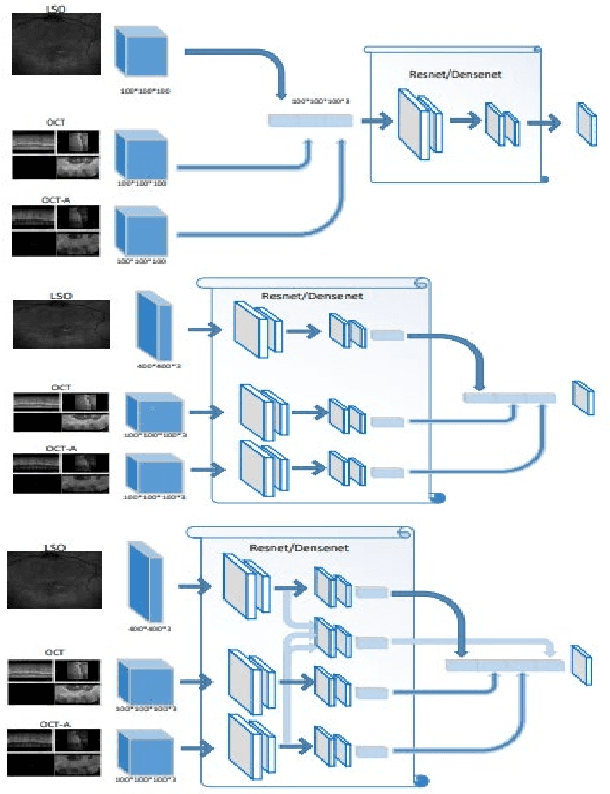
Diabetes is a chronic disease characterized by excess sugar in the blood and affects 422 million people worldwide, including 3.3 million in France. One of the frequent complications of diabetes is diabetic retinopathy (DR): it is the leading cause of blindness in the working population of developed countries. As a result, ophthalmology is on the verge of a revolution in screening, diagnosing, and managing of pathologies. This upheaval is led by the arrival of technologies based on artificial intelligence. The "Evaluation intelligente de la r\'etinopathie diab\'etique" (EviRed) project uses artificial intelligence to answer a medical need: replacing the current classification of diabetic retinopathy which is mainly based on outdated fundus photography and providing an insufficient prediction precision. EviRed exploits modern fundus imaging devices and artificial intelligence to properly integrate the vast amount of data they provide with other available medical data of the patient. The goal is to improve diagnosis and prediction and help ophthalmologists to make better decisions during diabetic retinopathy follow-up. In this study, we investigate the fusion of different modalities acquired simultaneously with a PLEXElite 9000 (Carl Zeiss Meditec Inc. Dublin, California, USA), namely 3-D structural optical coherence tomography (OCT), 3-D OCT angiography (OCTA) and 2-D Line Scanning Ophthalmoscope (LSO), for the automatic detection of proliferative DR.
Noisy-label Learning with Sample Selection based on Noise Rate Estimate
May 31, 2023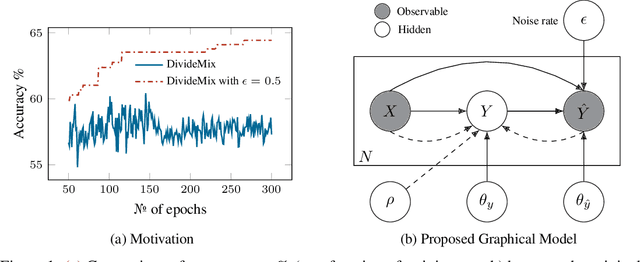
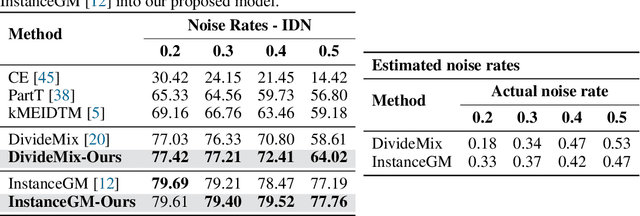
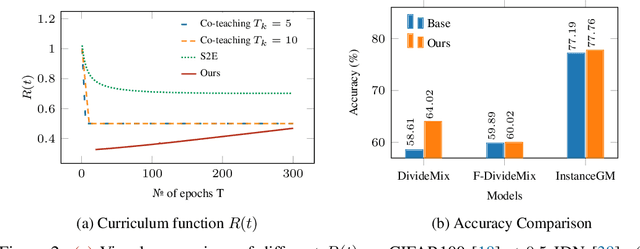
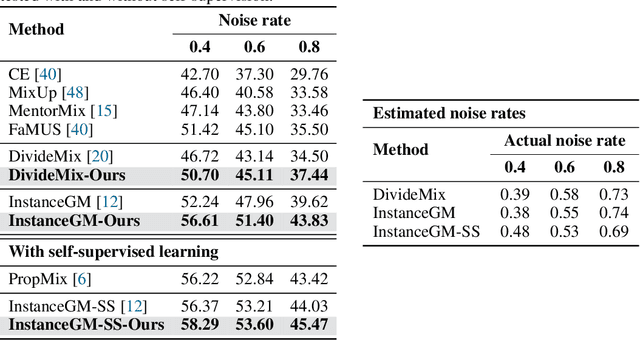
Noisy-labels are challenging for deep learning due to the high capacity of the deep models that can overfit noisy-label training samples. Arguably the most realistic and coincidentally challenging type of label noise is the instance-dependent noise (IDN), where the labelling errors are caused by the ambivalent information present in the images. The most successful label noise learning techniques to address IDN problems usually contain a noisy-label sample selection stage to separate clean and noisy-label samples during training. Such sample selection depends on a criterion, such as loss or gradient, and on a curriculum to define the proportion of training samples to be classified as clean at each training epoch. Even though the estimated noise rate from the training set appears to be a natural signal to be used in the definition of this curriculum, previous approaches generally rely on arbitrary thresholds or pre-defined selection functions to the best of our knowledge. This paper addresses this research gap by proposing a new noisy-label learning graphical model that can easily accommodate state-of-the-art (SOTA) noisy-label learning methods and provide them with a reliable noise rate estimate to be used in a new sample selection curriculum. We show empirically that our model integrated with many SOTA methods can improve their results in many IDN benchmarks, including synthetic and real-world datasets.
The Effect of News Article Quality on Ad Consumption
May 31, 2023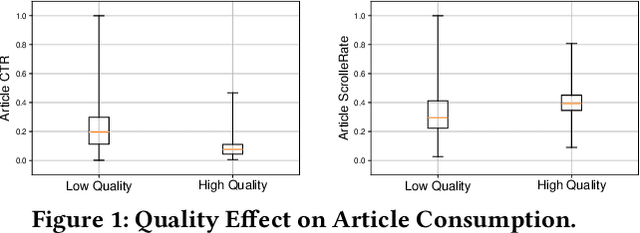
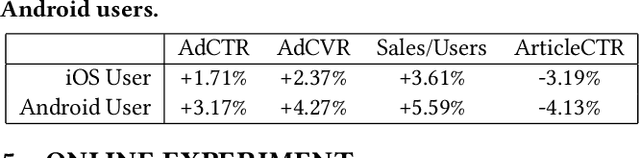
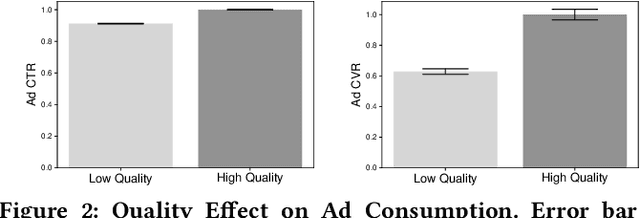
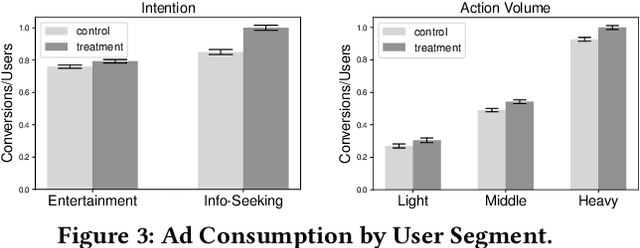
Practical news feed platforms generate a hybrid list of news articles and advertising items (e.g., products, services, or information) and many platforms optimize the position of news articles and advertisements independently. However, they should be arranged with careful consideration of each other, as we show in this study, since user behaviors toward advertisements are significantly affected by the news articles. This paper investigates the effect of news articles on users' ad consumption and shows the dependency between news and ad effectiveness. We conducted a service log analysis and showed that sessions with high-quality news article exposure had more ad consumption than those with low-quality news article exposure. Based on this result, we hypothesized that exposure to high-quality articles will lead to a high ad consumption rate. Thus, we conducted million-scale A/B testing to investigate the effect of high-quality articles on ad consumption, in which we prioritized high-quality articles in the ranking for the treatment group. The A/B test showed that the treatment group's ad consumption, such as the number of clicks, conversions, and sales, increased significantly while the number of article clicks decreased. We also found that users who prefer a social or economic topic had more ad consumption by stratified analysis. These insights regarding news articles and advertisements will help optimize news and ad effectiveness in rankings considering their mutual influence.
Exploiting Mechanics-Based Priors for Lateral Displacement Estimation in Ultrasound Elastography
May 31, 2023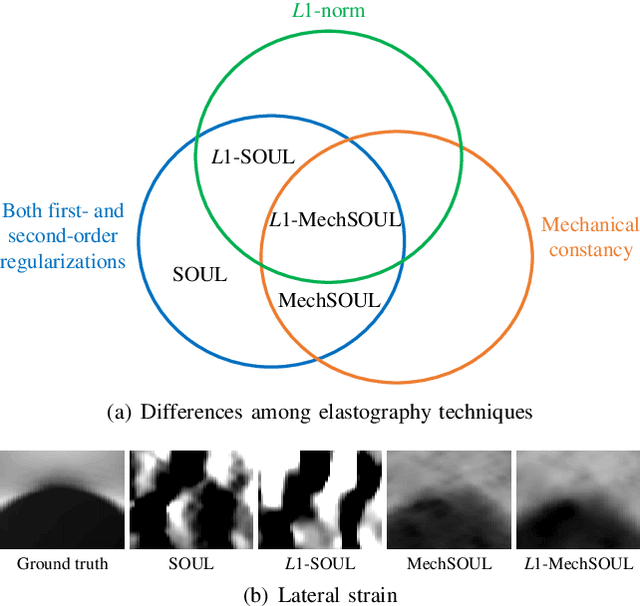
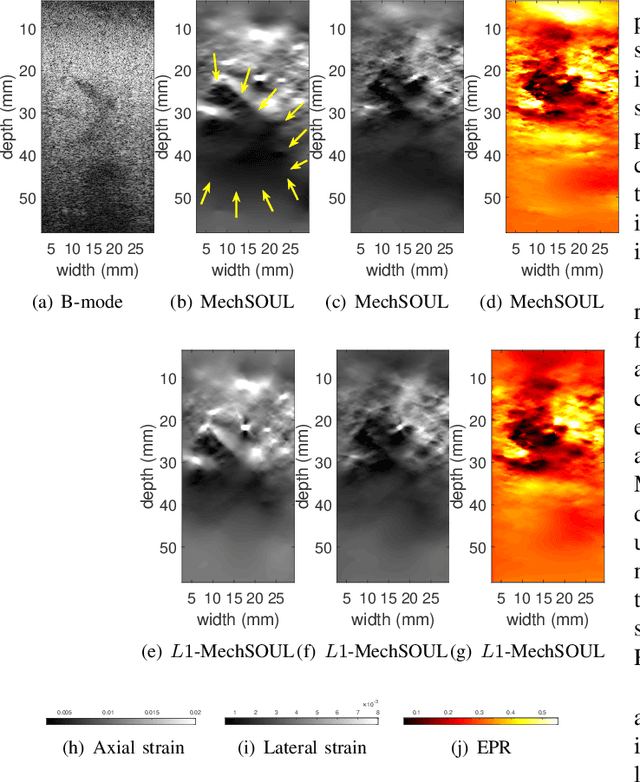


Tracking the displacement between the pre- and post-deformed radio-frequency (RF) frames is a pivotal step of ultrasound elastography, which depicts tissue mechanical properties to identify pathologies. Due to ultrasound's poor ability to capture information pertaining to the lateral direction, the existing displacement estimation techniques fail to generate an accurate lateral displacement or strain map. The attempts made in the literature to mitigate this well-known issue suffer from one of the following limitations: 1) Sampling size is substantially increased, rendering the method computationally and memory expensive. 2) The lateral displacement estimation entirely depends on the axial one, ignoring data fidelity and creating large errors. This paper proposes exploiting the effective Poisson's ratio (EPR)-based mechanical correspondence between the axial and lateral strains along with the RF data fidelity and displacement continuity to improve the lateral displacement and strain estimation accuracies. We call our techniques MechSOUL (Mechanically-constrained Second-Order Ultrasound eLastography) and L1-MechSOUL (L1-norm-based MechSOUL), which optimize L2- and L1-norm-based penalty functions, respectively. Extensive validation experiments with simulated, phantom, and in vivo datasets demonstrate that MechSOUL and L1-MechSOUL's lateral strain and EPR estimation abilities are substantially superior to those of the recently-published elastography techniques. We have published the MATLAB codes of MechSOUL and L1-MechSOUL at http://code.sonography.ai.
Resolving Interference When Merging Models
Jun 02, 2023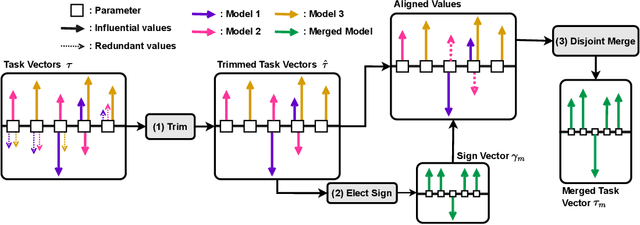
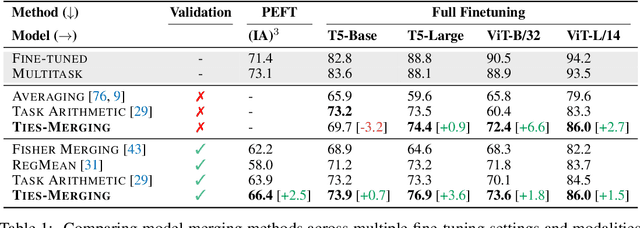
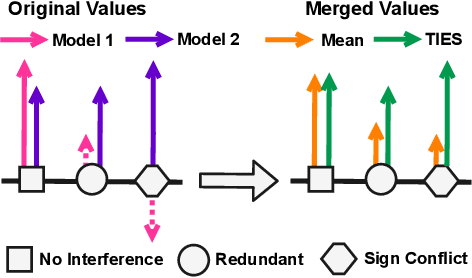
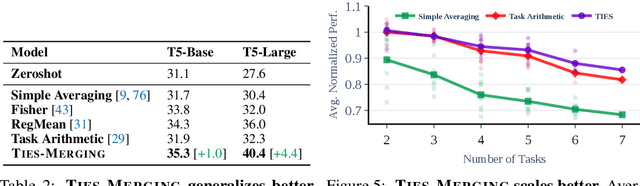
Transfer learning - i.e., further fine-tuning a pre-trained model on a downstream task - can confer significant advantages, including improved downstream performance, faster convergence, and better sample efficiency. These advantages have led to a proliferation of task-specific fine-tuned models, which typically can only perform a single task and do not benefit from one another. Recently, model merging techniques have emerged as a solution to combine multiple task-specific models into a single multitask model without performing additional training. However, existing merging methods often ignore the interference between parameters of different models, resulting in large performance drops when merging multiple models. In this paper, we demonstrate that prior merging techniques inadvertently lose valuable information due to two major sources of interference: (a) interference due to redundant parameter values and (b) disagreement on the sign of a given parameter's values across models. To address this, we propose our method, TrIm, Elect Sign & Merge (TIES-Merging), which introduces three novel steps when merging models: (1) resetting parameters that only changed a small amount during fine-tuning, (2) resolving sign conflicts, and (3) merging only the parameters that are in alignment with the final agreed-upon sign. We find that TIES-Merging outperforms several existing methods in diverse settings covering a range of modalities, domains, number of tasks, model sizes, architectures, and fine-tuning settings. We further analyze the impact of different types of interference on model parameters, highlight the importance of resolving sign interference. Our code is available at https://github.com/prateeky2806/ties-merging
Towards Source-free Domain Adaptive Semantic Segmentation via Importance-aware and Prototype-contrast Learning
Jun 02, 2023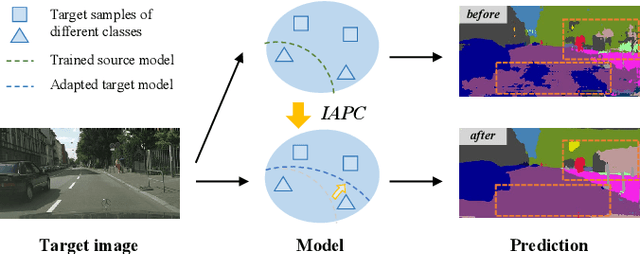
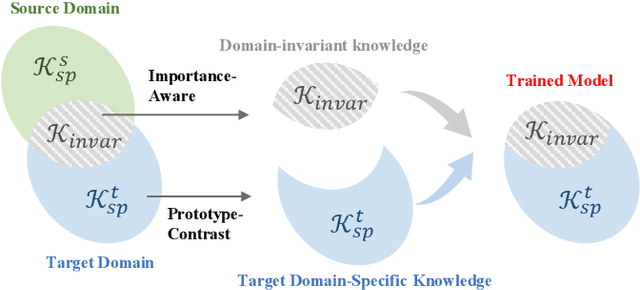
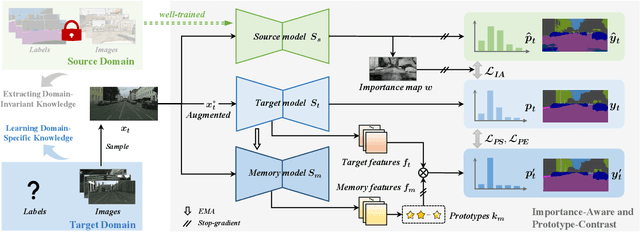
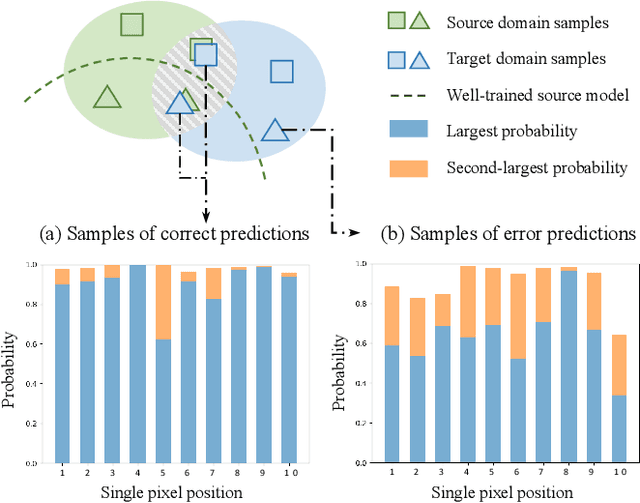
Domain adaptive semantic segmentation enables robust pixel-wise understanding in real-world driving scenes. Source-free domain adaptation, as a more practical technique, addresses the concerns of data privacy and storage limitations in typical unsupervised domain adaptation methods. It utilizes a well-trained source model and unlabeled target data to achieve adaptation in the target domain. However, in the absence of source data and target labels, current solutions cannot sufficiently reduce the impact of domain shift and fully leverage the information from the target data. In this paper, we propose an end-to-end source-free domain adaptation semantic segmentation method via Importance-Aware and Prototype-Contrast (IAPC) learning. The proposed IAPC framework effectively extracts domain-invariant knowledge from the well-trained source model and learns domain-specific knowledge from the unlabeled target domain. Specifically, considering the problem of domain shift in the prediction of the target domain by the source model, we put forward an importance-aware mechanism for the biased target prediction probability distribution to extract domain-invariant knowledge from the source model. We further introduce a prototype-contrast strategy, which includes a prototype-symmetric cross-entropy loss and a prototype-enhanced cross-entropy loss, to learn target intra-domain knowledge without relying on labels. A comprehensive variety of experiments on two domain adaptive semantic segmentation benchmarks demonstrates that the proposed end-to-end IAPC solution outperforms existing state-of-the-art methods. Code will be made publicly available at https://github.com/yihong-97/Source-free_IAPC.
Incorporating Structured Representations into Pretrained Vision & Language Models Using Scene Graphs
May 10, 2023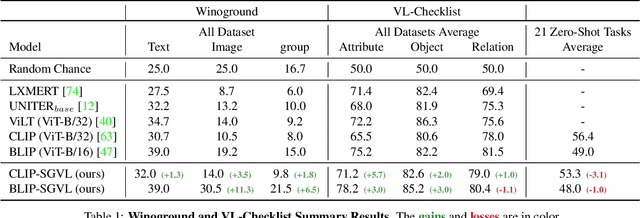
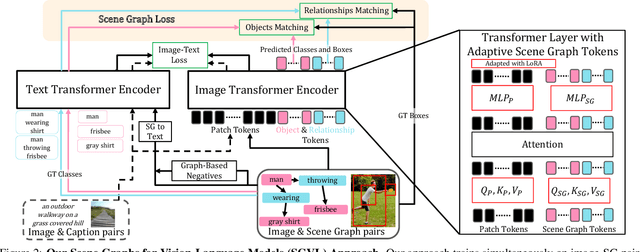
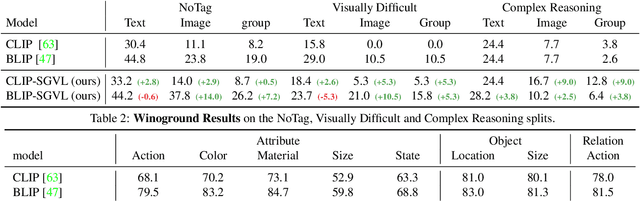

Vision and Language (VL) models have demonstrated remarkable zero-shot performance in a variety of tasks. However, recent studies have shown that even the best VL models struggle to capture aspects of scene understanding, such as object attributes, relationships, and action states. In contrast, obtaining structured annotations, e.g., scene graphs (SGs) that could improve these models is time-consuming, costly, and tedious, and thus cannot be used on a large scale. Here we ask, can small datasets containing SG annotations provide sufficient information for enhancing structured understanding of VL models? We show that it is indeed possible to improve VL models using such data by utilizing a specialized model architecture and a new training paradigm. Our approach captures structure-related information for both the visual and textual encoders by directly supervising both components when learning from SG labels. We use scene graph supervision to generate fine-grained captions based on various graph augmentations highlighting different compositional aspects of the scene, and to predict SG information using an open vocabulary approach by adding special ``Adaptive SG tokens'' to the visual encoder. Moreover, we design a new adaptation technique tailored specifically to the SG tokens that allows better learning of the graph prediction task while still maintaining zero-shot capabilities. Our model shows strong performance improvements on the Winoground and VL-checklist datasets with only a mild degradation in zero-shot performance.
Continual Learning for Abdominal Multi-Organ and Tumor Segmentation
Jun 01, 2023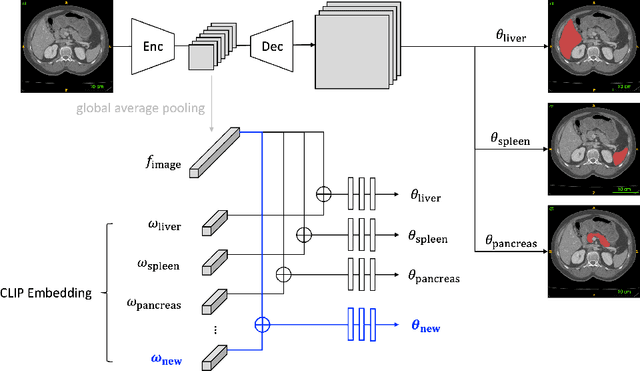

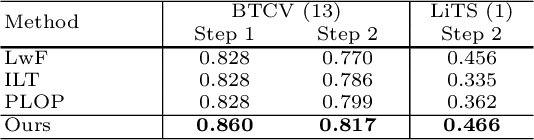
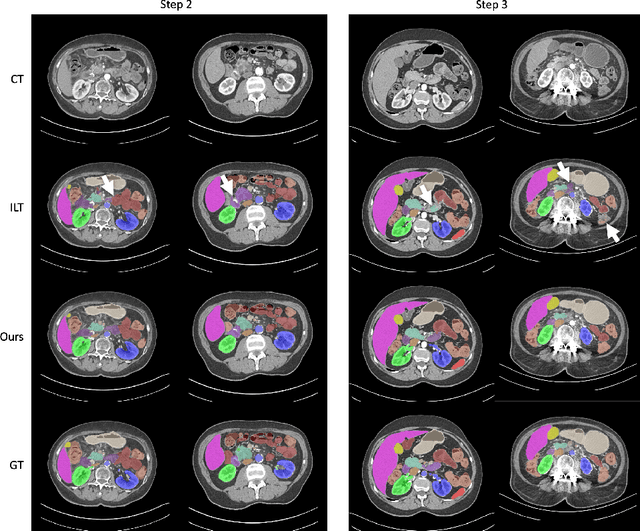
The ability to dynamically extend a model to new data and classes is critical for multiple organ and tumor segmentation. However, due to privacy regulations, accessing previous data and annotations can be problematic in the medical domain. This poses a significant barrier to preserving the high segmentation accuracy of the old classes when learning from new classes because of the catastrophic forgetting problem. In this paper, we first empirically demonstrate that simply using high-quality pseudo labels can fairly mitigate this problem in the setting of organ segmentation. Furthermore, we put forward an innovative architecture designed specifically for continuous organ and tumor segmentation, which incurs minimal computational overhead. Our proposed design involves replacing the conventional output layer with a suite of lightweight, class-specific heads, thereby offering the flexibility to accommodate newly emerging classes. These heads enable independent predictions for newly introduced and previously learned classes, effectively minimizing the impact of new classes on old ones during the course of continual learning. We further propose incorporating Contrastive Language-Image Pretraining (CLIP) embeddings into the organ-specific heads. These embeddings encapsulate the semantic information of each class, informed by extensive image-text co-training. The proposed method is evaluated on both in-house and public abdominal CT datasets under organ and tumor segmentation tasks. Empirical results suggest that the proposed design improves the segmentation performance of a baseline neural network on newly-introduced and previously-learned classes along the learning trajectory.