 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Catch Me If You Can: Deep Meta-RL for Search-and-Rescue using LoRa UAV Networks
Jun 12, 2023
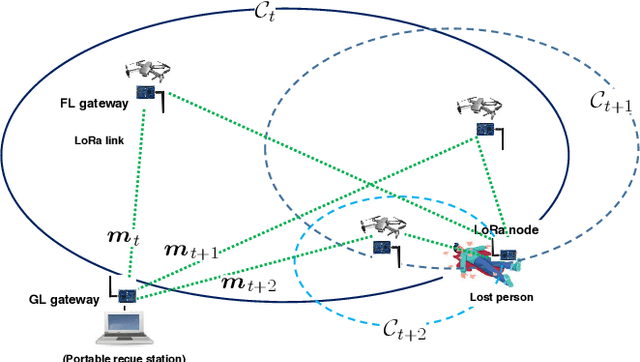
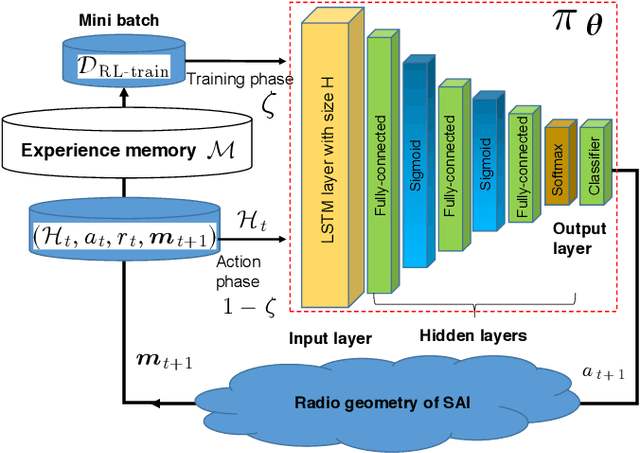
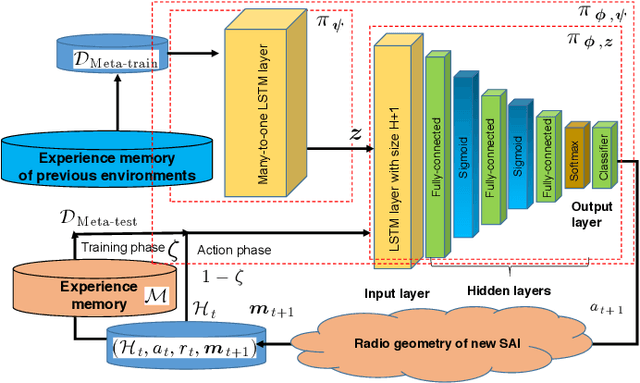

Long range (LoRa) wireless networks have been widely proposed as a efficient wireless access networks for the battery-constrained Internet of Things (IoT) devices. In many practical search-and-rescue (SAR) operations, one challenging problem is finding the location of devices carried by a lost person. However, using a LoRa-based IoT network for SAR operations will have a limited coverage caused by high signal attenuation due to the terrestrial blockages especially in highly remote areas. To overcome this challenge, the use of unmanned aerial vehicles (UAVs) as a flying LoRa gateway to transfer messages from ground LoRa nodes to the ground rescue station can be a promising solution. In this paper, the problem of the flying LoRa (FL) gateway control in the search-and-rescue system using the UAV-assisted LoRa network is modeled as a partially observable Markov decision process. Then, a deep meta-RL-based policy is proposed to control the FL gateway trajectory during SAR operation. For initialization of proposed deep meta-RL-based policy, first, a deep RL-based policy is designed to determine the adaptive FL gateway trajectory in a fixed search environment including a fixed radio geometry. Then, as a general solution, a deep meta-RL framework is used for SAR in any new and unknown environments to integrate the prior FL gateway experience with information collected from the other search environments and rapidly adapt the SAR policy model for SAR operation in a new environment. The proposed UAV-assisted LoRa network is then experimentally designed and implemented. Practical evaluation results show that if the deep meta-RL based control policy is applied instead of the deep RL-based one, the number of SAR time slots decreases from 141 to 50.
An Architecture for Deploying Reinforcement Learning in Industrial Environments
Jun 02, 2023Industry 4.0 is driven by demands like shorter time-to-market, mass customization of products, and batch size one production. Reinforcement Learning (RL), a machine learning paradigm shown to possess a great potential in improving and surpassing human level performance in numerous complex tasks, allows coping with the mentioned demands. In this paper, we present an OPC UA based Operational Technology (OT)-aware RL architecture, which extends the standard RL setting, combining it with the setting of digital twins. Moreover, we define an OPC UA information model allowing for a generalized plug-and-play like approach for exchanging the RL agent used. In conclusion, we demonstrate and evaluate the architecture, by creating a proof of concept. By means of solving a toy example, we show that this architecture can be used to determine the optimal policy using a real control system.
* This preprint has not undergone peer review or any post-submission improvements or corrections. The Version of Record of this contribution is published in Computer Aided Systems Theory - EUROCAST 2022 and is available online at https://doi.org/10.1007/978-3-031-25312-6_67
DistilXLSR: A Light Weight Cross-Lingual Speech Representation Model
Jun 02, 2023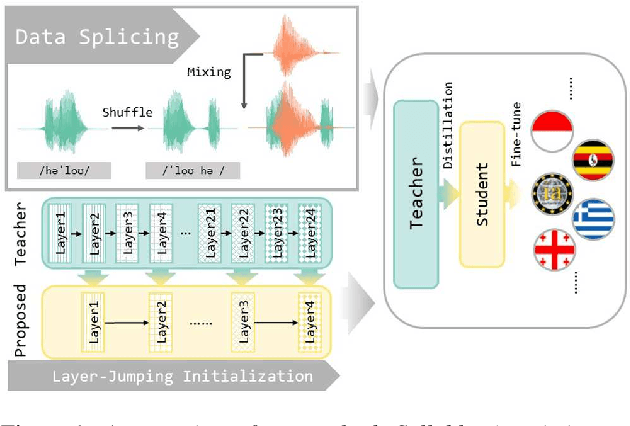
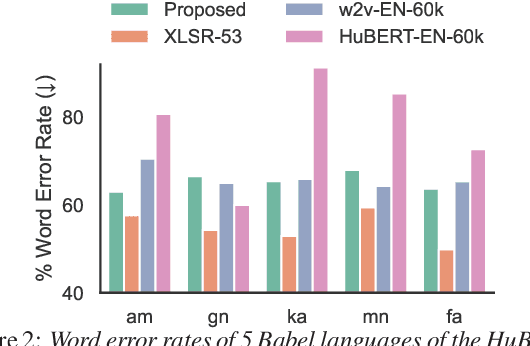
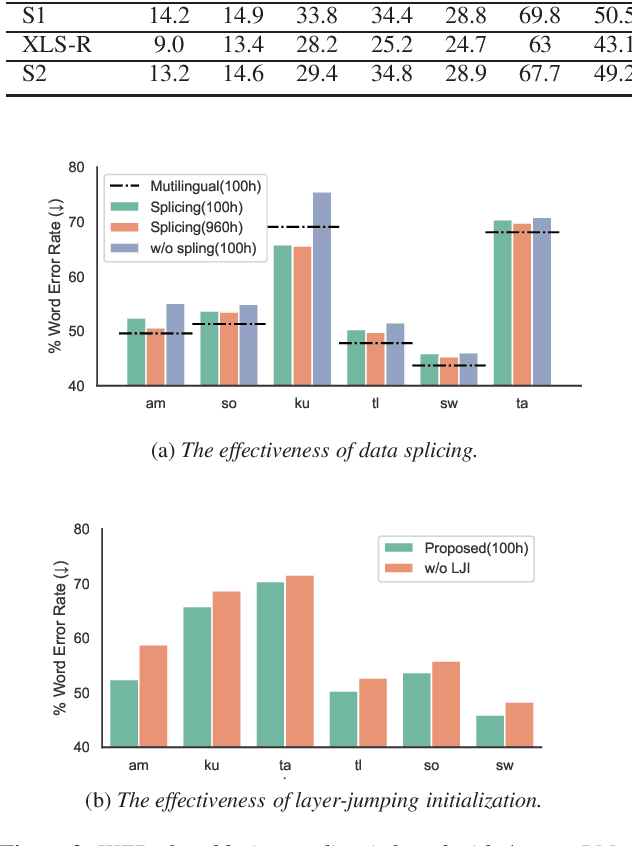
Multilingual self-supervised speech representation models have greatly enhanced the speech recognition performance for low-resource languages, and the compression of these huge models has also become a crucial prerequisite for their industrial application. In this paper, we propose DistilXLSR, a distilled cross-lingual speech representation model. By randomly shuffling the phonemes of existing speech, we reduce the linguistic information and distill cross-lingual models using only English data. We also design a layer-jumping initialization method to fully leverage the teacher's pre-trained weights. Experiments on 2 kinds of teacher models and 15 low-resource languages show that our method can reduce the parameters by 50% while maintaining cross-lingual representation ability. Our method is proven to be generalizable to various languages/teacher models and has the potential to improve the cross-lingual performance of the English pre-trained models.
Enhance Temporal Relations in Audio Captioning with Sound Event Detection
Jun 02, 2023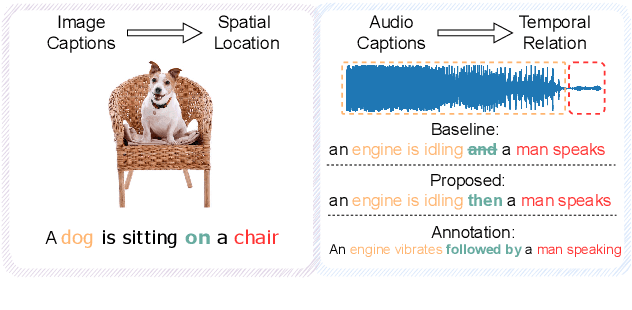

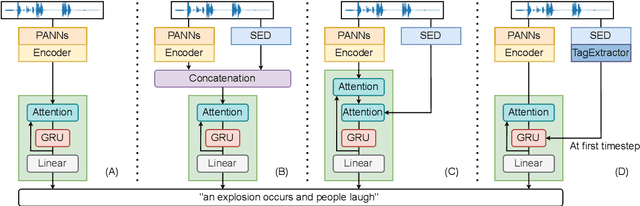
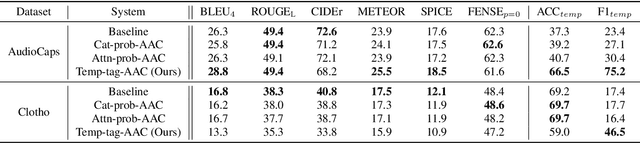
Automated audio captioning aims at generating natural language descriptions for given audio clips, not only detecting and classifying sounds, but also summarizing the relationships between audio events. Recent research advances in audio captioning have introduced additional guidance to improve the accuracy of audio events in generated sentences. However, temporal relations between audio events have received little attention while revealing complex relations is a key component in summarizing audio content. Therefore, this paper aims to better capture temporal relationships in caption generation with sound event detection (SED), a task that locates events' timestamps. We investigate the best approach to integrate temporal information in a captioning model and propose a temporal tag system to transform the timestamps into comprehensible relations. Results evaluated by the proposed temporal metrics suggest that great improvement is achieved in terms of temporal relation generation.
Language Knowledge-Assisted Representation Learning for Skeleton-Based Action Recognition
May 21, 2023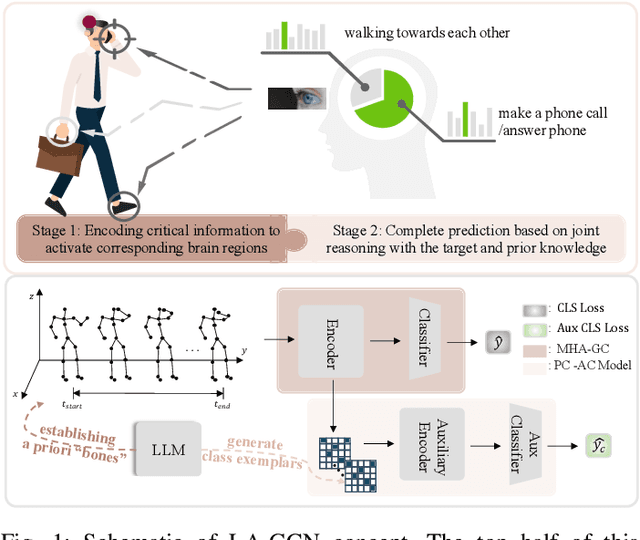
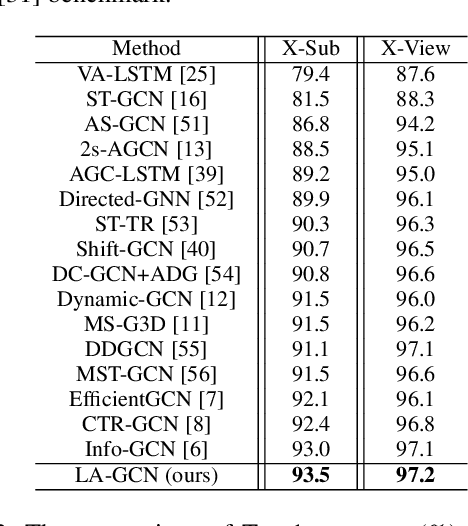
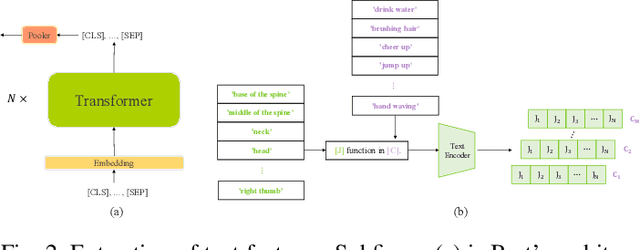

How humans understand and recognize the actions of others is a complex neuroscientific problem that involves a combination of cognitive mechanisms and neural networks. Research has shown that humans have brain areas that recognize actions that process top-down attentional information, such as the temporoparietal association area. Also, humans have brain regions dedicated to understanding the minds of others and analyzing their intentions, such as the medial prefrontal cortex of the temporal lobe. Skeleton-based action recognition creates mappings for the complex connections between the human skeleton movement patterns and behaviors. Although existing studies encoded meaningful node relationships and synthesized action representations for classification with good results, few of them considered incorporating a priori knowledge to aid potential representation learning for better performance. LA-GCN proposes a graph convolution network using large-scale language models (LLM) knowledge assistance. First, the LLM knowledge is mapped into a priori global relationship (GPR) topology and a priori category relationship (CPR) topology between nodes. The GPR guides the generation of new "bone" representations, aiming to emphasize essential node information from the data level. The CPR mapping simulates category prior knowledge in human brain regions, encoded by the PC-AC module and used to add additional supervision-forcing the model to learn class-distinguishable features. In addition, to improve information transfer efficiency in topology modeling, we propose multi-hop attention graph convolution. It aggregates each node's k-order neighbor simultaneously to speed up model convergence. LA-GCN reaches state-of-the-art on NTU RGB+D, NTU RGB+D 120, and NW-UCLA datasets.
Prompt-Tuning Decision Transformer with Preference Ranking
May 16, 2023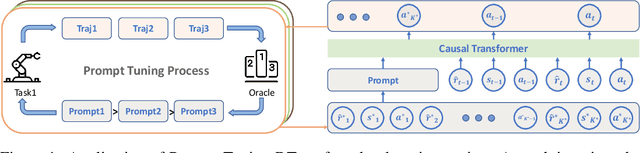
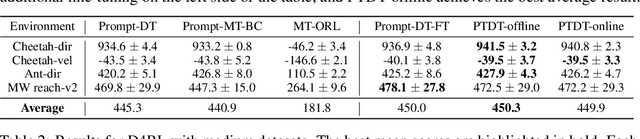

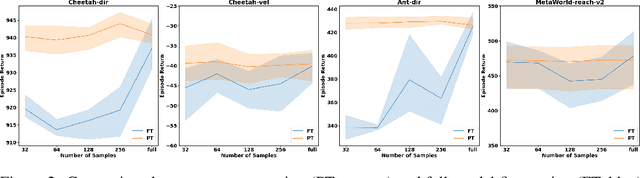
Prompt-tuning has emerged as a promising method for adapting pre-trained models to downstream tasks or aligning with human preferences. Prompt learning is widely used in NLP but has limited applicability to RL due to the complex physical meaning and environment-specific information contained within RL prompts. These factors require supervised learning to imitate the demonstrations and may result in a loss of meaning after learning. Additionally, directly extending prompt-tuning approaches to RL is challenging because RL prompts guide agent behavior based on environmental modeling and analysis, rather than filling in missing information, making it unlikely that adjustments to the prompt format for downstream tasks, as in NLP, can yield significant improvements. In this work, we propose the Prompt-Tuning DT algorithm to address these challenges by using trajectory segments as prompts to guide RL agents in acquiring environmental information and optimizing prompts via black-box tuning to enhance their ability to contain more relevant information, thereby enabling agents to make better decisions. Our approach involves randomly sampling a Gaussian distribution to fine-tune the elements of the prompt trajectory and using preference ranking function to find the optimization direction, thereby providing more informative prompts and guiding the agent towards specific preferences in the target environment. Extensive experiments show that with only 0.03% of the parameters learned, Prompt-Tuning DT achieves comparable or even better performance than full-model fine-tuning in low-data scenarios. Our work contributes to the advancement of prompt-tuning approaches in RL, providing a promising direction for optimizing large RL agents for specific preference tasks.
Instructive Feature Enhancement for Dichotomous Medical Image Segmentation
Jun 06, 2023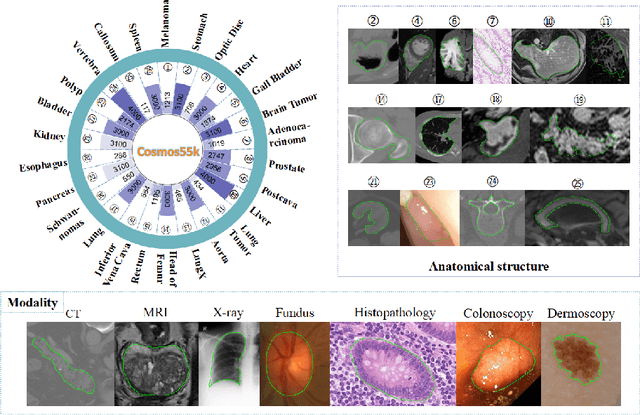
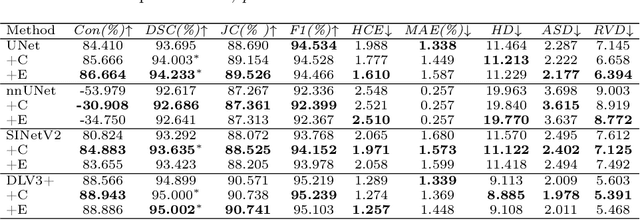
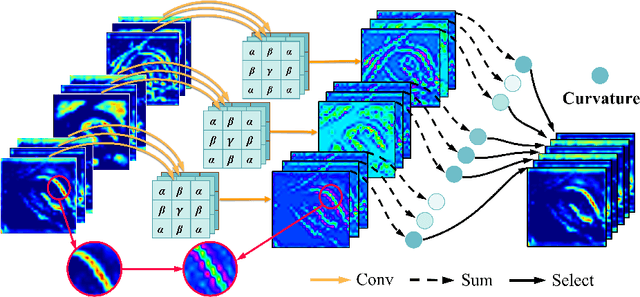
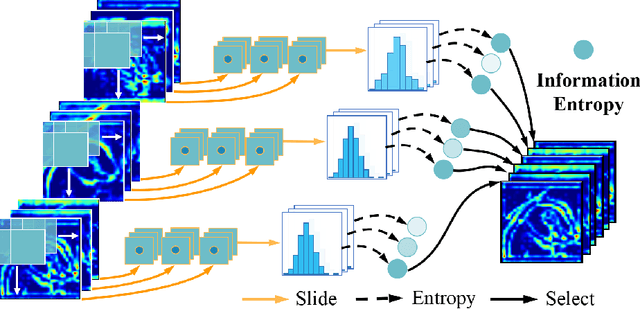
Deep neural networks have been widely applied in dichotomous medical image segmentation (DMIS) of many anatomical structures in several modalities, achieving promising performance. However, existing networks tend to struggle with task-specific, heavy and complex designs to improve accuracy. They made little instructions to which feature channels would be more beneficial for segmentation, and that may be why the performance and universality of these segmentation models are hindered. In this study, we propose an instructive feature enhancement approach, namely IFE, to adaptively select feature channels with rich texture cues and strong discriminability to enhance raw features based on local curvature or global information entropy criteria. Being plug-and-play and applicable for diverse DMIS tasks, IFE encourages the model to focus on texture-rich features which are especially important for the ambiguous and challenging boundary identification, simultaneously achieving simplicity, universality, and certain interpretability. To evaluate the proposed IFE, we constructed the first large-scale DMIS dataset Cosmos55k, which contains 55,023 images from 7 modalities and 26 anatomical structures. Extensive experiments show that IFE can improve the performance of classic segmentation networks across different anatomies and modalities with only slight modifications. Code is available at https://github.com/yezi-66/IFE
Machine Unlearning: A Survey
Jun 06, 2023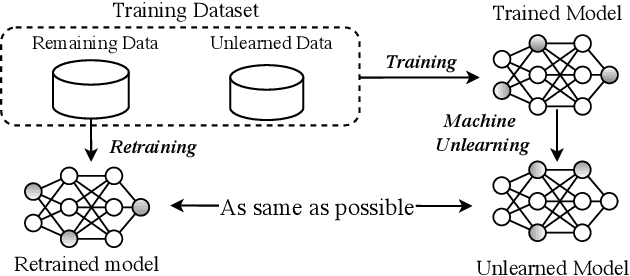
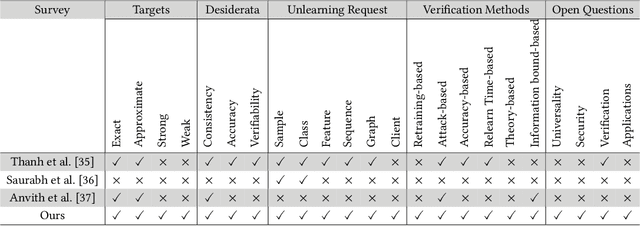
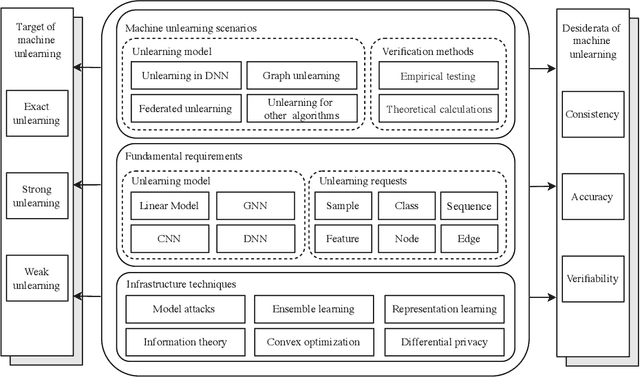
Machine learning has attracted widespread attention and evolved into an enabling technology for a wide range of highly successful applications, such as intelligent computer vision, speech recognition, medical diagnosis, and more. Yet a special need has arisen where, due to privacy, usability, and/or the right to be forgotten, information about some specific samples needs to be removed from a model, called machine unlearning. This emerging technology has drawn significant interest from both academics and industry due to its innovation and practicality. At the same time, this ambitious problem has led to numerous research efforts aimed at confronting its challenges. To the best of our knowledge, no study has analyzed this complex topic or compared the feasibility of existing unlearning solutions in different kinds of scenarios. Accordingly, with this survey, we aim to capture the key concepts of unlearning techniques. The existing solutions are classified and summarized based on their characteristics within an up-to-date and comprehensive review of each category's advantages and limitations. The survey concludes by highlighting some of the outstanding issues with unlearning techniques, along with some feasible directions for new research opportunities.
Online Estimation of Self-Body Deflection With Various Sensor Data Based on Directional Statistics
Jun 06, 2023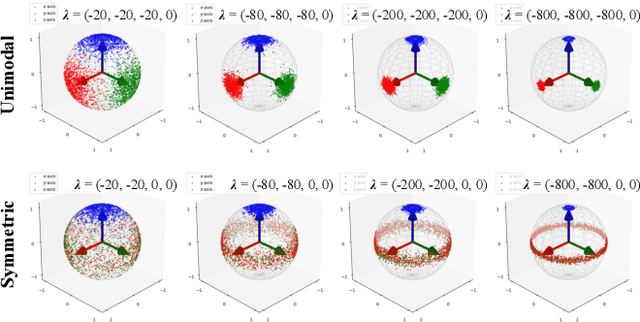
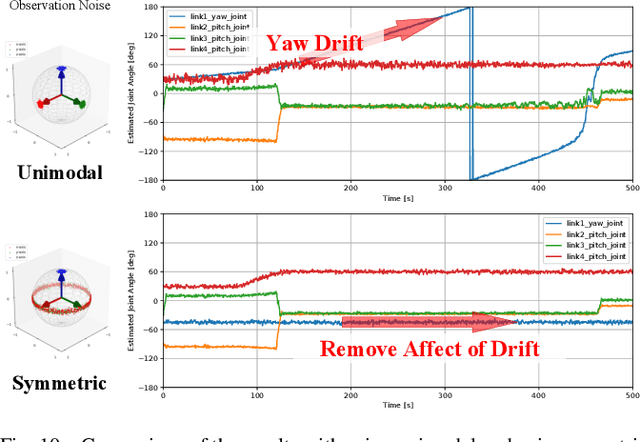
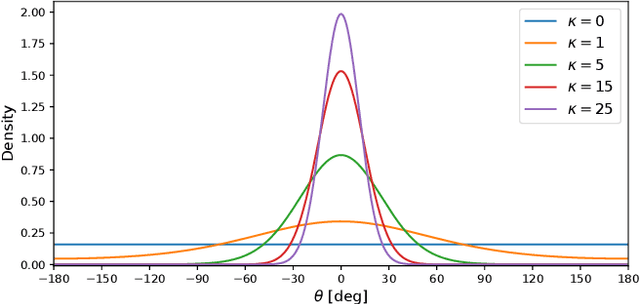
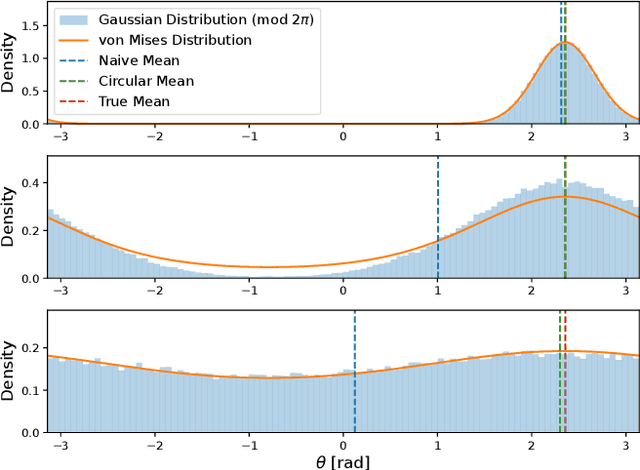
In this paper, we propose a method for online estimation of the robot's posture. Our method uses von Mises and Bingham distributions as probability distributions of joint angles and 3D orientation, which are used in directional statistics. We constructed a particle filter using these distributions and configured a system to estimate the robot's posture from various sensor information (e.g., joint encoders, IMU sensors, and cameras). Furthermore, unlike tangent space approximations, these distributions can handle global features and represent sensor characteristics as observation noises. As an application, we show that the yaw drift of a 6-axis IMU sensor can be represented probabilistically to prevent adverse effects on attitude estimation. For the estimation, we used an approximate model that assumes the actual robot posture can be reproduced by correcting the joint angles of a rigid body model. In the experiment part, we tested the estimator's effectiveness by examining that the joint angles generated with the approximate model can be estimated using the link pose of the same model. We then applied the estimator to the actual robot and confirmed that the gripper position could be estimated, thereby verifying the validity of the approximate model in our situation.
Revisiting Neural Retrieval on Accelerators
Jun 06, 2023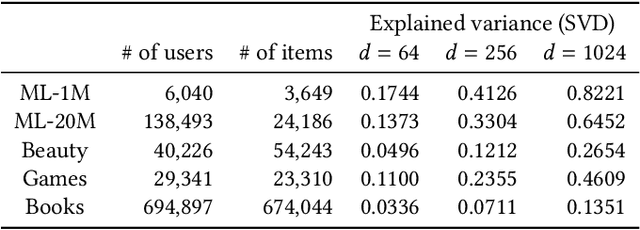
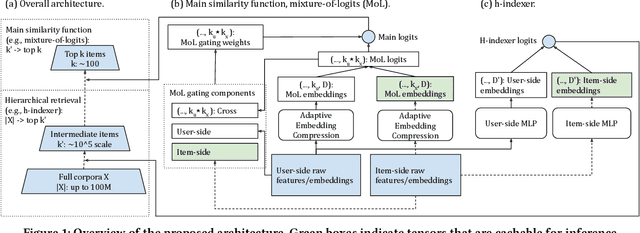
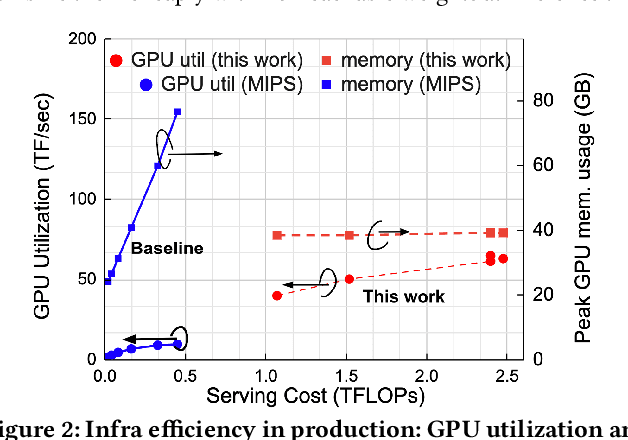

Retrieval finds a small number of relevant candidates from a large corpus for information retrieval and recommendation applications. A key component of retrieval is to model (user, item) similarity, which is commonly represented as the dot product of two learned embeddings. This formulation permits efficient inference, commonly known as Maximum Inner Product Search (MIPS). Despite its popularity, dot products cannot capture complex user-item interactions, which are multifaceted and likely high rank. We hence examine non-dot-product retrieval settings on accelerators, and propose \textit{mixture of logits} (MoL), which models (user, item) similarity as an adaptive composition of elementary similarity functions. This new formulation is expressive, capable of modeling high rank (user, item) interactions, and further generalizes to the long tail. When combined with a hierarchical retrieval strategy, \textit{h-indexer}, we are able to scale up MoL to 100M corpus on a single GPU with latency comparable to MIPS baselines. On public datasets, our approach leads to uplifts of up to 77.3\% in hit rate (HR). Experiments on a large recommendation surface at Meta showed strong metric gains and reduced popularity bias, validating the proposed approach's performance and improved generalization.