 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ICL-D3IE: In-Context Learning with Diverse Demonstrations Updating for Document Information Extraction
Mar 09, 2023
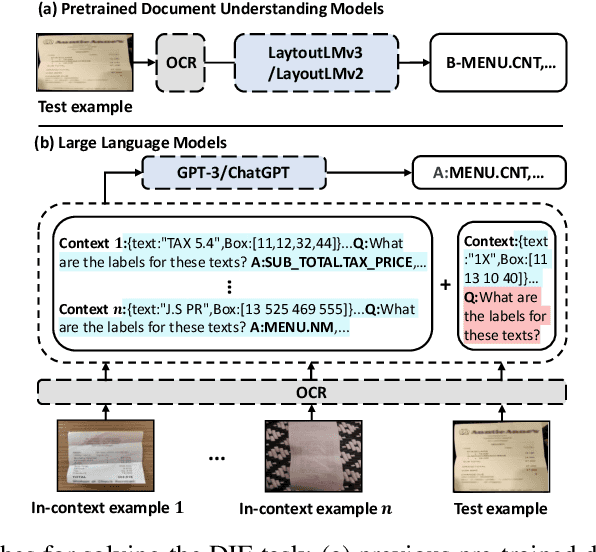
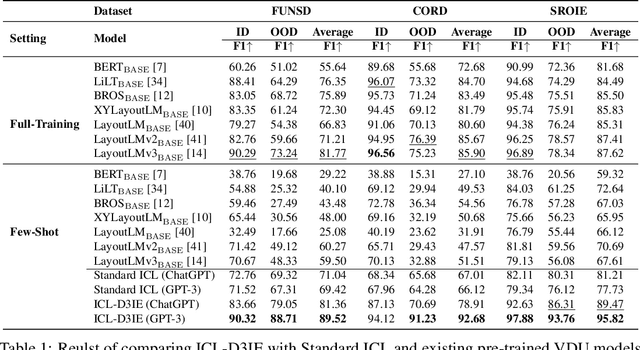
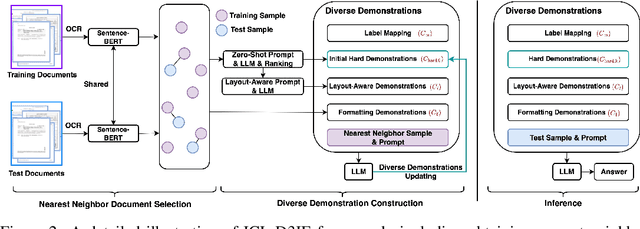
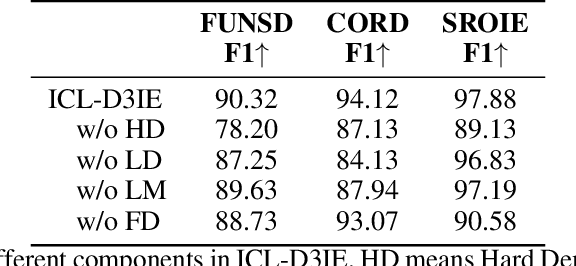
Large language models (LLMs), such as GPT-3 and ChatGPT, have demonstrated remarkable results in various natural language processing (NLP) tasks with in-context learning, which involves inference based on a few demonstration examples. Despite their successes in NLP tasks, no investigation has been conducted to assess the ability of LLMs to perform document information extraction (DIE) using in-context learning. Applying LLMs to DIE poses two challenges: the modality and task gap. To this end, we propose a simple but effective in-context learning framework called ICL-D3IE, which enables LLMs to perform DIE with different types of demonstration examples. Specifically, we extract the most difficult and distinct segments from hard training documents as hard demonstrations for benefiting all test instances. We design demonstrations describing relationships that enable LLMs to understand positional relationships. We introduce formatting demonstrations for easy answer extraction. Additionally, the framework improves diverse demonstrations by updating them iteratively. Our experiments on three widely used benchmark datasets demonstrate that the ICL-D3IE framework enables GPT-3/ChatGPT to achieve superior performance when compared to previous pre-trained methods fine-tuned with full training in both the in-distribution (ID) setting and in the out-of-distribution (OOD) setting.
Jointprop: Joint Semi-supervised Learning for Entity and Relation Extraction with Heterogeneous Graph-based Propagation
May 25, 2023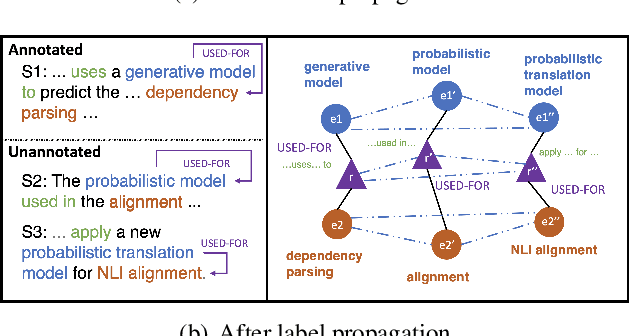

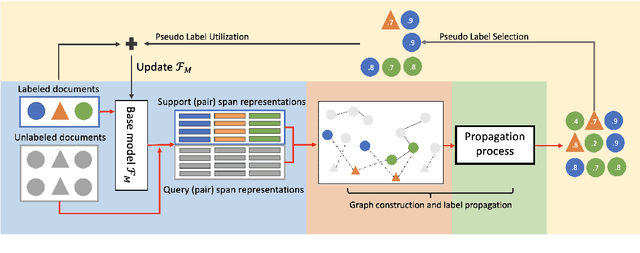
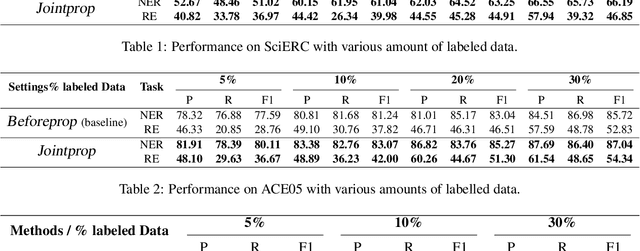
Semi-supervised learning has been an important approach to address challenges in extracting entities and relations from limited data. However, current semi-supervised works handle the two tasks (i.e., Named Entity Recognition and Relation Extraction) separately and ignore the cross-correlation of entity and relation instances as well as the existence of similar instances across unlabeled data. To alleviate the issues, we propose Jointprop, a Heterogeneous Graph-based Propagation framework for joint semi-supervised entity and relation extraction, which captures the global structure information between individual tasks and exploits interactions within unlabeled data. Specifically, we construct a unified span-based heterogeneous graph from entity and relation candidates and propagate class labels based on confidence scores. We then employ a propagation learning scheme to leverage the affinities between labelled and unlabeled samples. Experiments on benchmark datasets show that our framework outperforms the state-of-the-art semi-supervised approaches on NER and RE tasks. We show that the joint semi-supervised learning of the two tasks benefits from their codependency and validates the importance of utilizing the shared information between unlabeled data.
AssistGPT: A General Multi-modal Assistant that can Plan, Execute, Inspect, and Learn
Jun 14, 2023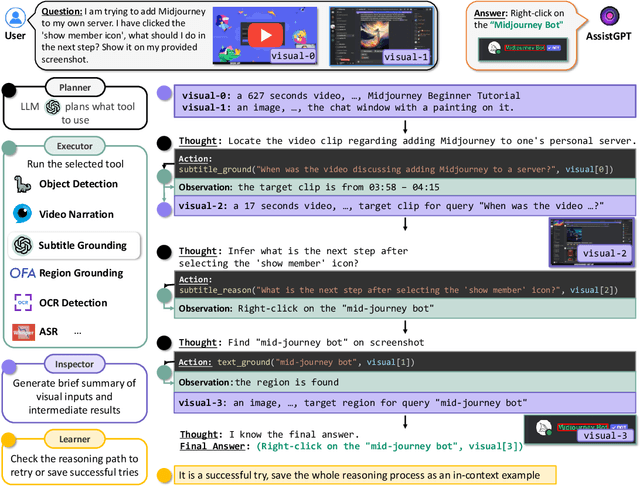


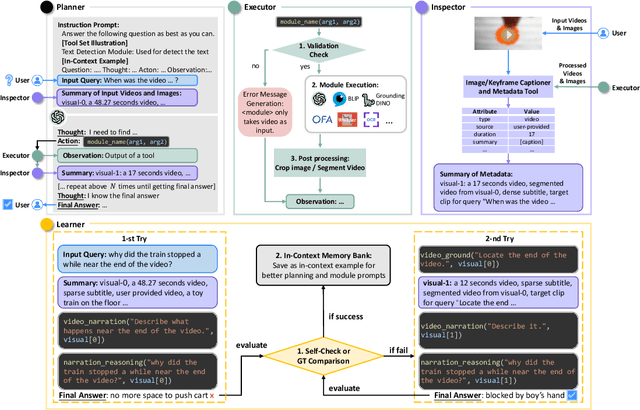
Recent research on Large Language Models (LLMs) has led to remarkable advancements in general NLP AI assistants. Some studies have further explored the use of LLMs for planning and invoking models or APIs to address more general multi-modal user queries. Despite this progress, complex visual-based tasks still remain challenging due to the diverse nature of visual tasks. This diversity is reflected in two aspects: 1) Reasoning paths. For many real-life applications, it is hard to accurately decompose a query simply by examining the query itself. Planning based on the specific visual content and the results of each step is usually required. 2) Flexible inputs and intermediate results. Input forms could be flexible for in-the-wild cases, and involves not only a single image or video but a mixture of videos and images, e.g., a user-view image with some reference videos. Besides, a complex reasoning process will also generate diverse multimodal intermediate results, e.g., video narrations, segmented video clips, etc. To address such general cases, we propose a multi-modal AI assistant, AssistGPT, with an interleaved code and language reasoning approach called Plan, Execute, Inspect, and Learn (PEIL) to integrate LLMs with various tools. Specifically, the Planner is capable of using natural language to plan which tool in Executor should do next based on the current reasoning progress. Inspector is an efficient memory manager to assist the Planner to feed proper visual information into a specific tool. Finally, since the entire reasoning process is complex and flexible, a Learner is designed to enable the model to autonomously explore and discover the optimal solution. We conducted experiments on A-OKVQA and NExT-QA benchmarks, achieving state-of-the-art results. Moreover, showcases demonstrate the ability of our system to handle questions far more complex than those found in the benchmarks.
Joining the Conversation: Towards Language Acquisition for Ad Hoc Team Play
May 20, 2023In this paper, we propose and consider the problem of cooperative language acquisition as a particular form of the ad hoc team play problem. We then present a probabilistic model for inferring a speaker's intentions and a listener's semantics from observing communications between a team of language-users. This model builds on the assumptions that speakers are engaged in positive signalling and listeners are exhibiting positive listening, which is to say the messages convey hidden information from the listener, that then causes them to change their behaviour. Further, it accounts for potential sub-optimality in the speaker's ability to convey the right information (according to the given task). Finally, we discuss further work for testing and developing this framework.
Hi-ResNet: A High-Resolution Remote Sensing Network for Semantic Segmentation
May 23, 2023
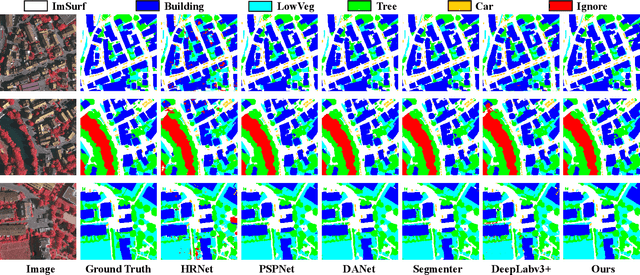
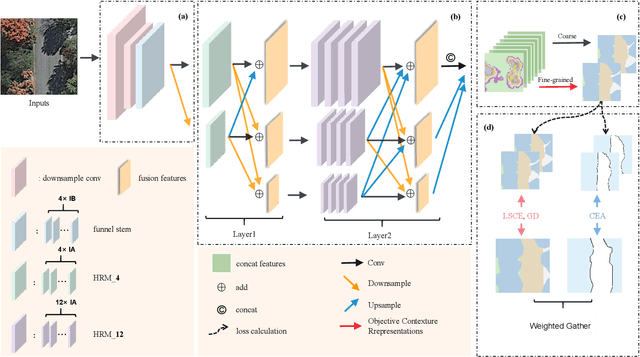
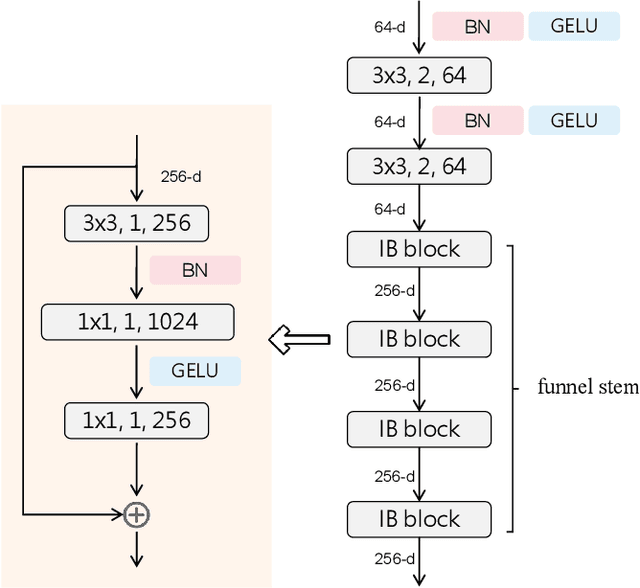
High-resolution remote sensing (HRS) semantic segmentation extracts key objects from high-resolution coverage areas. However, objects of the same category within HRS images generally show significant differences in scale and shape across diverse geographical environments, making it difficult to fit the data distribution. Additionally, a complex background environment causes similar appearances of objects of different categories, which precipitates a substantial number of objects into misclassification as background. These issues make existing learning algorithms sub-optimal. In this work, we solve the above-mentioned problems by proposing a High-resolution remote sensing network (Hi-ResNet) with efficient network structure designs, which consists of a funnel module, a multi-branch module with stacks of information aggregation (IA) blocks, and a feature refinement module, sequentially, and Class-agnostic Edge Aware (CEA) loss. Specifically, we propose a funnel module to downsample, which reduces the computational cost, and extract high-resolution semantic information from the initial input image. Secondly, we downsample the processed feature images into multi-resolution branches incrementally to capture image features at different scales and apply IA blocks, which capture key latent information by leveraging attention mechanisms, for effective feature aggregation, distinguishing image features of the same class with variant scales and shapes. Finally, our feature refinement module integrate the CEA loss function, which disambiguates inter-class objects with similar shapes and increases the data distribution distance for correct predictions. With effective pre-training strategies, we demonstrated the superiority of Hi-ResNet over state-of-the-art methods on three HRS segmentation benchmarks.
Efficient Multi-Task Scene Analysis with RGB-D Transformers
Jun 08, 2023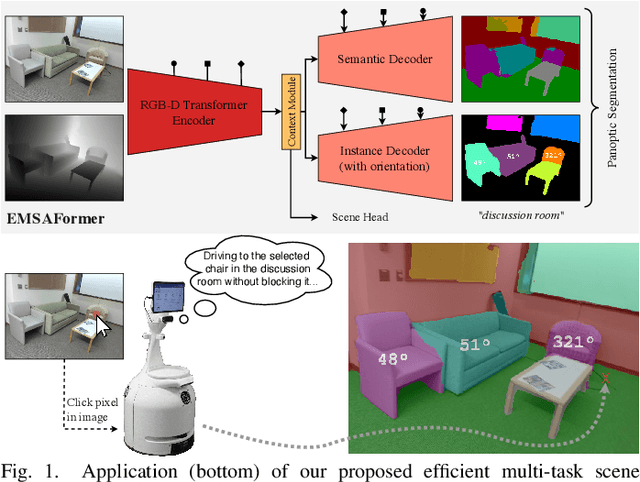
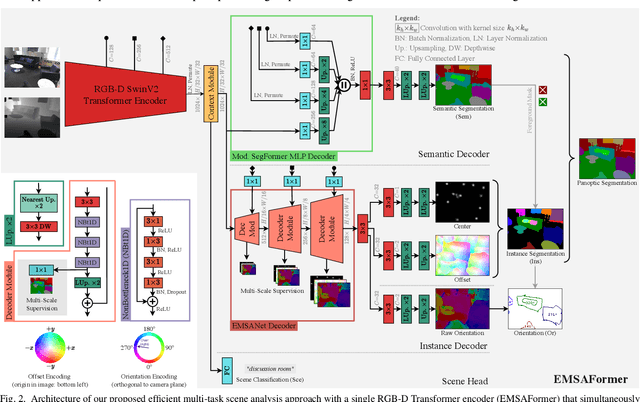
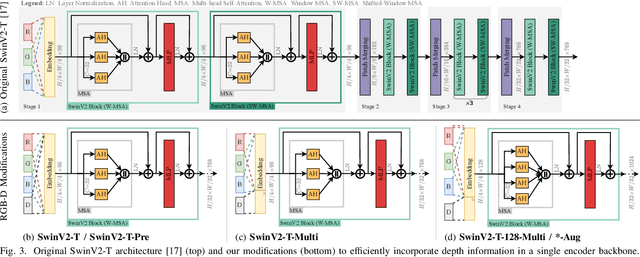
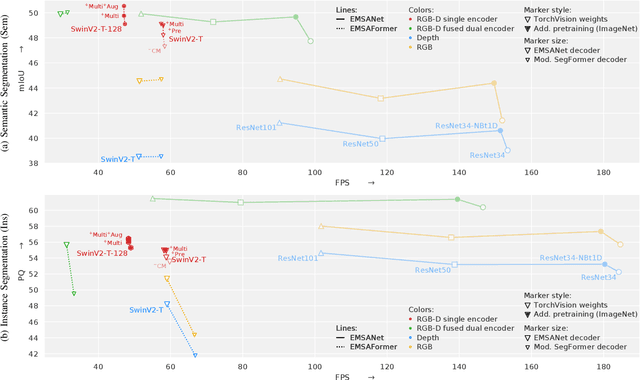
Scene analysis is essential for enabling autonomous systems, such as mobile robots, to operate in real-world environments. However, obtaining a comprehensive understanding of the scene requires solving multiple tasks, such as panoptic segmentation, instance orientation estimation, and scene classification. Solving these tasks given limited computing and battery capabilities on mobile platforms is challenging. To address this challenge, we introduce an efficient multi-task scene analysis approach, called EMSAFormer, that uses an RGB-D Transformer-based encoder to simultaneously perform the aforementioned tasks. Our approach builds upon the previously published EMSANet. However, we show that the dual CNN-based encoder of EMSANet can be replaced with a single Transformer-based encoder. To achieve this, we investigate how information from both RGB and depth data can be effectively incorporated in a single encoder. To accelerate inference on robotic hardware, we provide a custom NVIDIA TensorRT extension enabling highly optimization for our EMSAFormer approach. Through extensive experiments on the commonly used indoor datasets NYUv2, SUNRGB-D, and ScanNet, we show that our approach achieves state-of-the-art performance while still enabling inference with up to 39.1 FPS on an NVIDIA Jetson AGX Orin 32 GB.
SparseTrack: Multi-Object Tracking by Performing Scene Decomposition based on Pseudo-Depth
Jun 08, 2023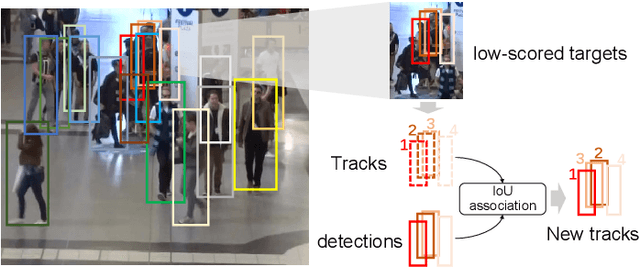
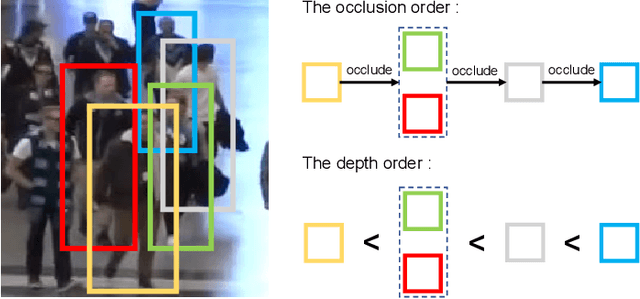
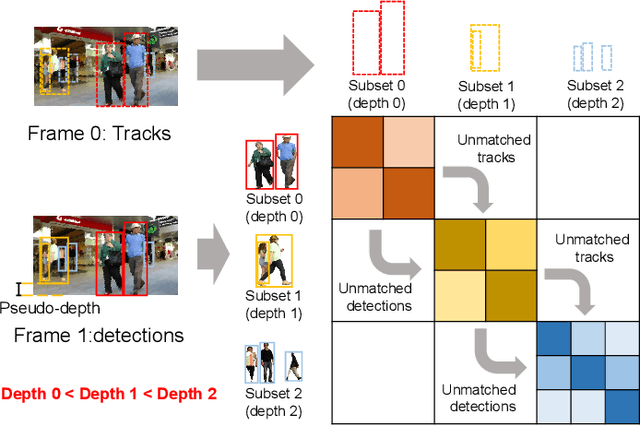
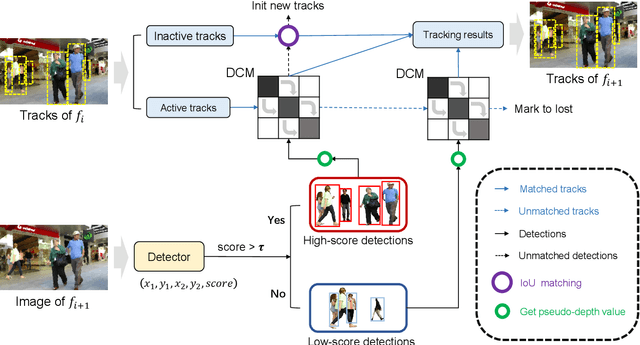
Exploring robust and efficient association methods has always been an important issue in multiple-object tracking (MOT). Although existing tracking methods have achieved impressive performance, congestion and frequent occlusions still pose challenging problems in multi-object tracking. We reveal that performing sparse decomposition on dense scenes is a crucial step to enhance the performance of associating occluded targets. To this end, we propose a pseudo-depth estimation method for obtaining the relative depth of targets from 2D images. Secondly, we design a depth cascading matching (DCM) algorithm, which can use the obtained depth information to convert a dense target set into multiple sparse target subsets and perform data association on these sparse target subsets in order from near to far. By integrating the pseudo-depth method and the DCM strategy into the data association process, we propose a new tracker, called SparseTrack. SparseTrack provides a new perspective for solving the challenging crowded scene MOT problem. Only using IoU matching, SparseTrack achieves comparable performance with the state-of-the-art (SOTA) methods on the MOT17 and MOT20 benchmarks. Code and models are publicly available at \url{https://github.com/hustvl/SparseTrack}.
Interpretable Medical Diagnostics with Structured Data Extraction by Large Language Models
Jun 08, 2023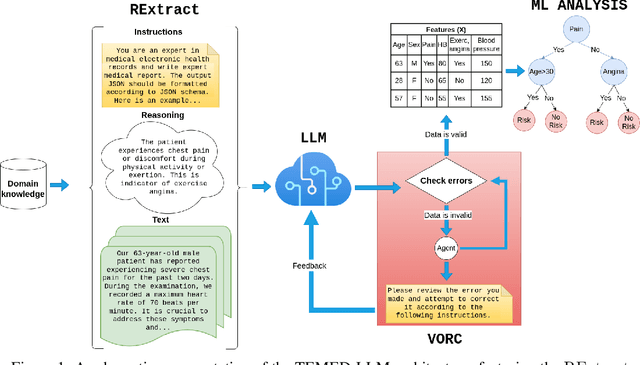
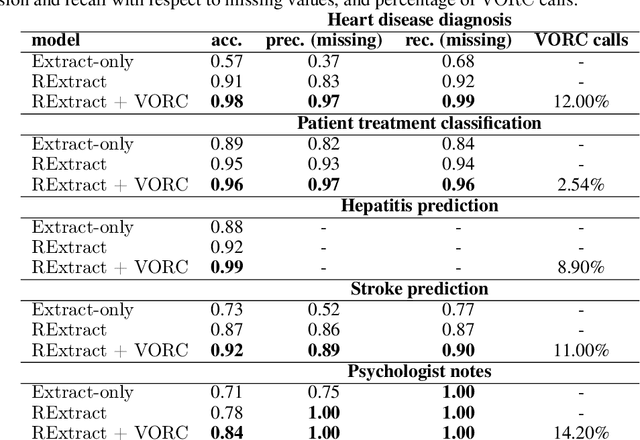
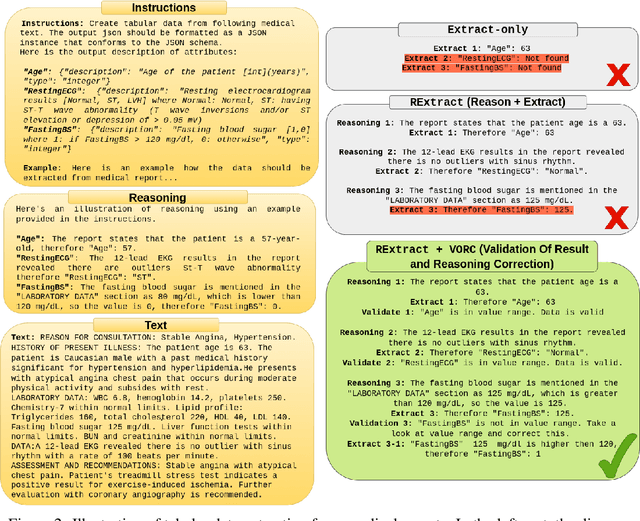
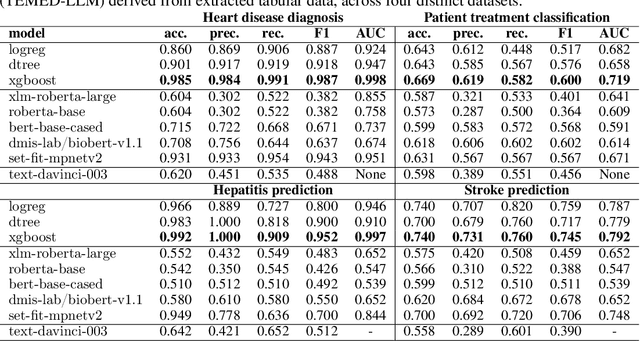
Tabular data is often hidden in text, particularly in medical diagnostic reports. Traditional machine learning (ML) models designed to work with tabular data, cannot effectively process information in such form. On the other hand, large language models (LLMs) which excel at textual tasks, are probably not the best tool for modeling tabular data. Therefore, we propose a novel, simple, and effective methodology for extracting structured tabular data from textual medical reports, called TEMED-LLM. Drawing upon the reasoning capabilities of LLMs, TEMED-LLM goes beyond traditional extraction techniques, accurately inferring tabular features, even when their names are not explicitly mentioned in the text. This is achieved by combining domain-specific reasoning guidelines with a proposed data validation and reasoning correction feedback loop. By applying interpretable ML models such as decision trees and logistic regression over the extracted and validated data, we obtain end-to-end interpretable predictions. We demonstrate that our approach significantly outperforms state-of-the-art text classification models in medical diagnostics. Given its predictive performance, simplicity, and interpretability, TEMED-LLM underscores the potential of leveraging LLMs to improve the performance and trustworthiness of ML models in medical applications.
Posterior Collapse in Linear Conditional and Hierarchical Variational Autoencoders
Jun 08, 2023
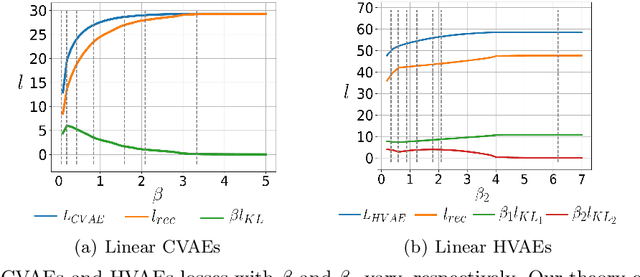
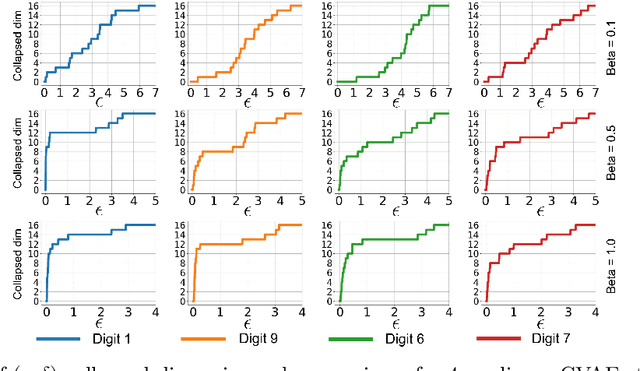
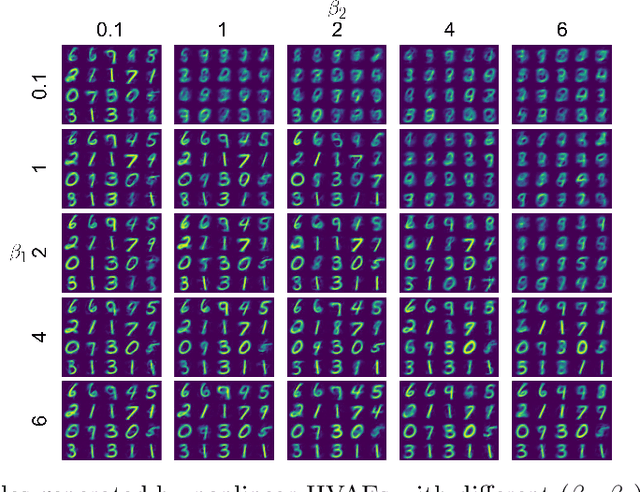
The posterior collapse phenomenon in variational autoencoders (VAEs), where the variational posterior distribution closely matches the prior distribution, can hinder the quality of the learned latent variables. As a consequence of posterior collapse, the latent variables extracted by the encoder in VAEs preserve less information from the input data and thus fail to produce meaningful representations as input to the reconstruction process in the decoder. While this phenomenon has been an actively addressed topic related to VAEs performance, the theory for posterior collapse remains underdeveloped, especially beyond the standard VAEs. In this work, we advance the theoretical understanding of posterior collapse to two important and prevalent yet less studied classes of VAEs: conditional VAEs and hierarchical VAEs. Specifically, via a non-trivial theoretical analysis of linear conditional VAEs and hierarchical VAEs with two levels of latent, we prove that the cause of posterior collapses in these models includes the correlation between the input and output of the conditional VAEs and the effect of learnable encoder variance in the hierarchical VAEs. We empirically validate our theoretical findings for linear conditional and hierarchical VAEs and demonstrate that these results are also predictive for non-linear cases.
IFaceUV: Intuitive Motion Facial Image Generation by Identity Preservation via UV map
Jun 08, 2023
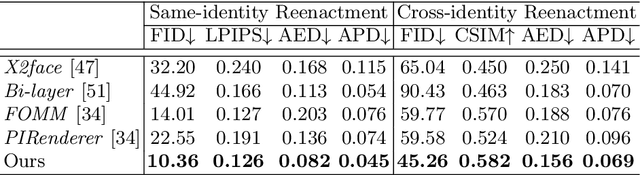
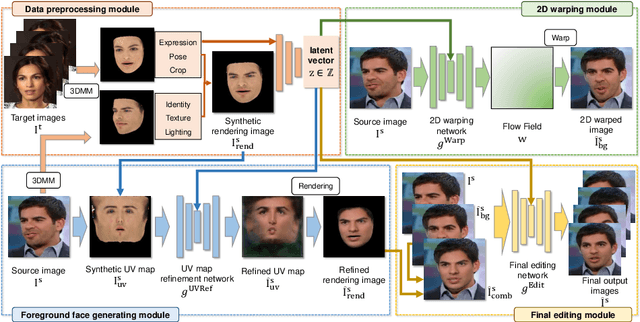
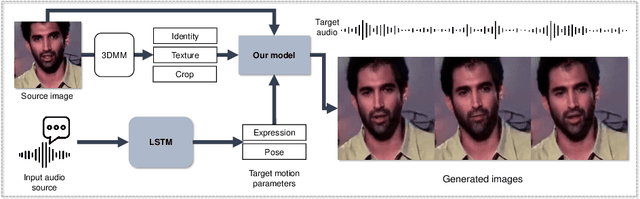
Reenacting facial images is an important task that can find numerous applications. We proposed IFaceUV, a fully differentiable pipeline that properly combines 2D and 3D information to conduct the facial reenactment task. The three-dimensional morphable face models (3DMMs) and corresponding UV maps are utilized to intuitively control facial motions and textures, respectively. Two-dimensional techniques based on 2D image warping is further required to compensate for missing components of the 3DMMs such as backgrounds, ear, hair and etc. In our pipeline, we first extract 3DMM parameters and corresponding UV maps from source and target images. Then, initial UV maps are refined by the UV map refinement network and it is rendered to the image with the motion manipulated 3DMM parameters. In parallel, we warp the source image according to the 2D flow field obtained from the 2D warping network. Rendered and warped images are combined in the final editing network to generate the final reenactment image. Additionally, we tested our model for the audio-driven facial reenactment task. Extensive qualitative and quantitative experiments illustrate the remarkable performance of our method compared to other state-of-the-art methods.