 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Imprecise Label Learning: A Unified Framework for Learning with Various Imprecise Label Configurations
May 23, 2023
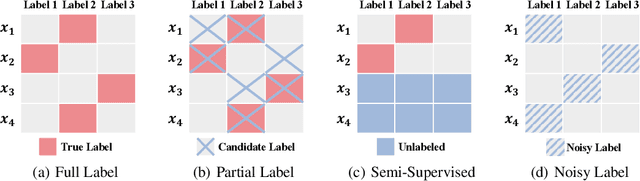
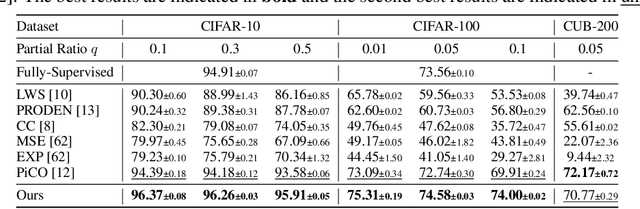

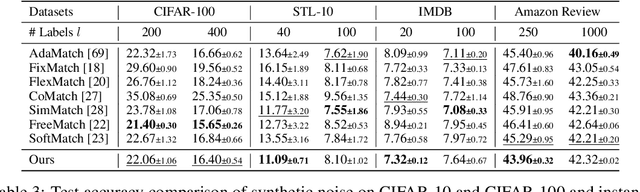
In this paper, we introduce the imprecise label learning (ILL) framework, a unified approach to handle various imprecise label configurations, which are commonplace challenges in machine learning tasks. ILL leverages an expectation-maximization (EM) algorithm for the maximum likelihood estimation (MLE) of the imprecise label information, treating the precise labels as latent variables. Compared to previous versatile methods attempting to infer correct labels from the imprecise label information, our ILL framework considers all possible labeling imposed by the imprecise label information, allowing a unified solution to deal with any imprecise labels. With comprehensive experimental results, we demonstrate that ILL can seamlessly adapt to various situations, including partial label learning, semi-supervised learning, noisy label learning, and a mixture of these settings. Notably, our simple method surpasses the existing techniques for handling imprecise labels, marking the first unified framework with robust and effective performance across various imprecise labels. We believe that our approach has the potential to significantly enhance the performance of machine learning models on tasks where obtaining precise labels is expensive and complicated. We hope our work will inspire further research on this topic with an open-source codebase release.
ManiTweet: A New Benchmark for Identifying Manipulation of News on Social Media
May 23, 2023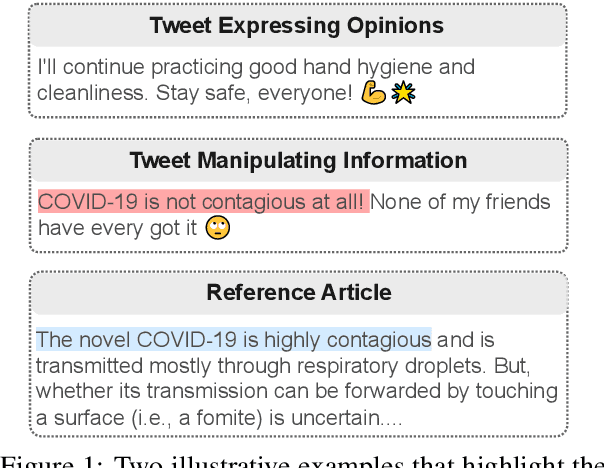
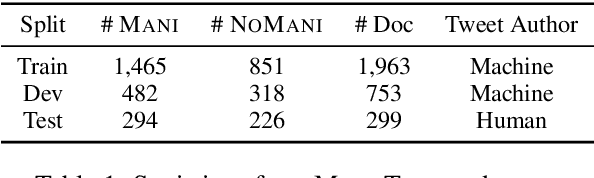

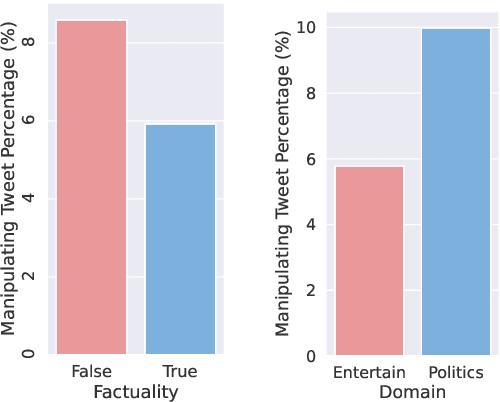
Considerable advancements have been made to tackle the misrepresentation of information derived from reference articles in the domains of fact-checking and faithful summarization. However, an unaddressed aspect remains - the identification of social media posts that manipulate information within associated news articles. This task presents a significant challenge, primarily due to the prevalence of personal opinions in such posts. We present a novel task, identifying manipulation of news on social media, which aims to detect manipulation in social media posts and identify manipulated or inserted information. To study this task, we have proposed a data collection schema and curated a dataset called ManiTweet, consisting of 3.6K pairs of tweets and corresponding articles. Our analysis demonstrates that this task is highly challenging, with large language models (LLMs) yielding unsatisfactory performance. Additionally, we have developed a simple yet effective basic model that outperforms LLMs significantly on the ManiTweet dataset. Finally, we have conducted an exploratory analysis of human-written tweets, unveiling intriguing connections between manipulation and the domain and factuality of news articles, as well as revealing that manipulated sentences are more likely to encapsulate the main story or consequences of a news outlet.
Improving Language Models via Plug-and-Play Retrieval Feedback
May 23, 2023
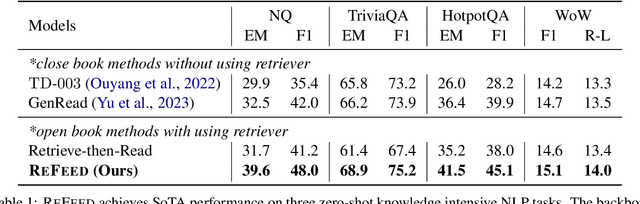

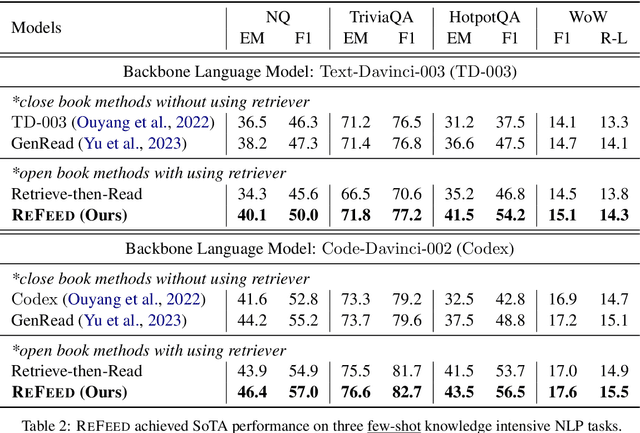
Large language models (LLMs) exhibit remarkable performance across various NLP tasks. However, they often generate incorrect or hallucinated information, which hinders their practical applicability in real-world scenarios. Human feedback has been shown to effectively enhance the factuality and quality of generated content, addressing some of these limitations. However, this approach is resource-intensive, involving manual input and supervision, which can be time-consuming and expensive. Moreover, it cannot be provided during inference, further limiting its practical utility in dynamic and interactive applications. In this paper, we introduce ReFeed, a novel pipeline designed to enhance LLMs by providing automatic retrieval feedback in a plug-and-play framework without the need for expensive fine-tuning. ReFeed first generates initial outputs, then utilizes a retrieval model to acquire relevant information from large document collections, and finally incorporates the retrieved information into the in-context demonstration for output refinement, thereby addressing the limitations of LLMs in a more efficient and cost-effective manner. Experiments on four knowledge-intensive benchmark datasets demonstrate our proposed ReFeed could improve over +6.0% under zero-shot setting and +2.5% under few-shot setting, compared to baselines without using retrieval feedback.
EXACT: Extensive Attack for Split Learning
May 25, 2023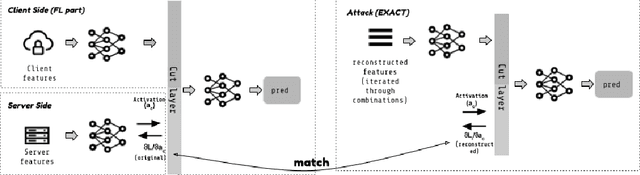

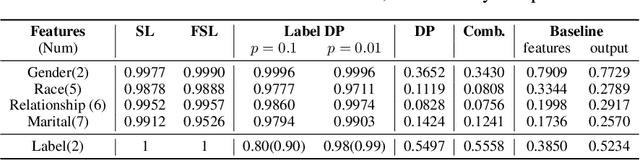
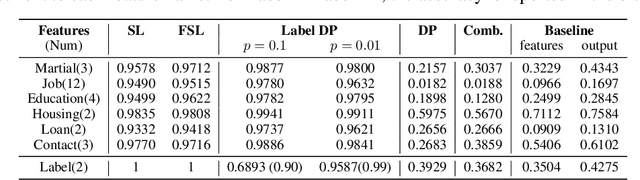
Privacy-Preserving machine learning (PPML) can help us train and deploy models that utilize private information. In particular, on-device Machine Learning allows us to completely avoid sharing information with a third-party server during inference. However, on-device models are typically less accurate when compared to the server counterparts due to the fact that (1) they typically only rely on a small set of on-device features and (2) they need to be small enough to run efficiently on end-user devices. Split Learning (SL) is a promising approach that can overcome these limitations. In SL, a large machine learning model is divided into two parts, with the bigger part residing on the server-side and a smaller part executing on-device, aiming to incorporate the private features. However, end-to-end training of such models requires exchanging gradients at the cut layer, which might encode private features or labels. In this paper, we provide insights into potential privacy risks associated with SL and introduce a novel attack method, EXACT, to reconstruct private information. Furthermore, we also investigate the effectiveness of various mitigation strategies. Our results indicate that the gradients significantly improve the attacker's effectiveness in all three datasets reaching almost 100% reconstruction accuracy for some features. However, a small amount of differential privacy (DP) is quite effective in mitigating this risk without causing significant training degradation.
$\textit{WHAT}$, $\textit{WHEN}$, and $\textit{HOW}$ to Ground: Designing User Persona-Aware Conversational Agents for Engaging Dialogue
Jun 06, 2023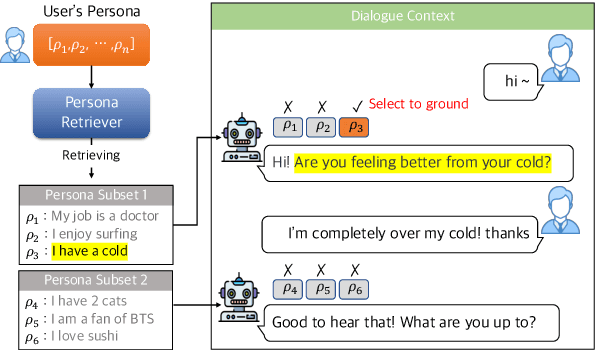

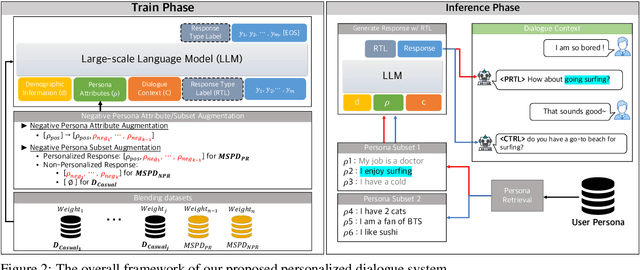
This paper presents a method for building a personalized open-domain dialogue system to address the $\textit{WWH}$ ($\textit{WHAT}$, $\textit{WHEN}$, and $\textit{HOW}$) problem for natural response generation in a commercial setting, where personalized dialogue responses are heavily interleaved with casual response turns. The proposed approach involves weighted dataset blending, negative persona information augmentation methods, and the design of personalized conversation datasets to address the challenges of $\textit{WWH}$ in personalized, open-domain dialogue systems. Our work effectively balances dialogue fluency and tendency to ground, while also introducing a response-type label to improve the controllability and explainability of the grounded responses. The combination of these methods leads to more fluent conversations, as evidenced by subjective human evaluations as well as objective evaluations.
PFNs4BO: In-Context Learning for Bayesian Optimization
Jun 09, 2023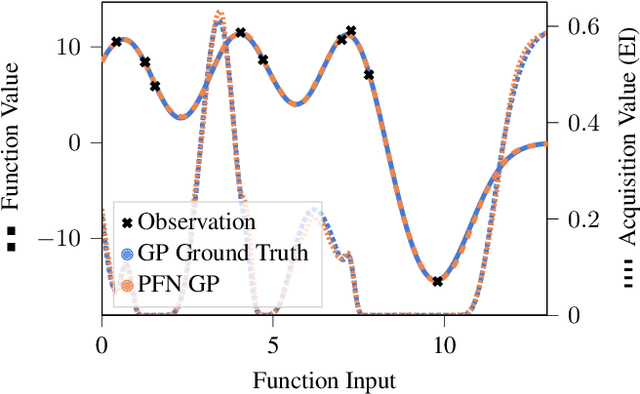
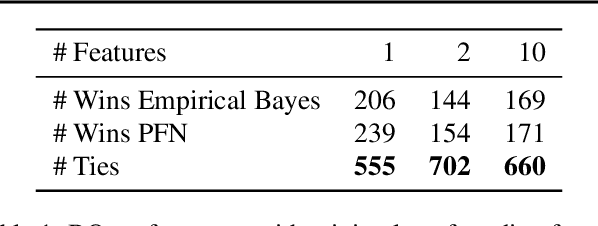
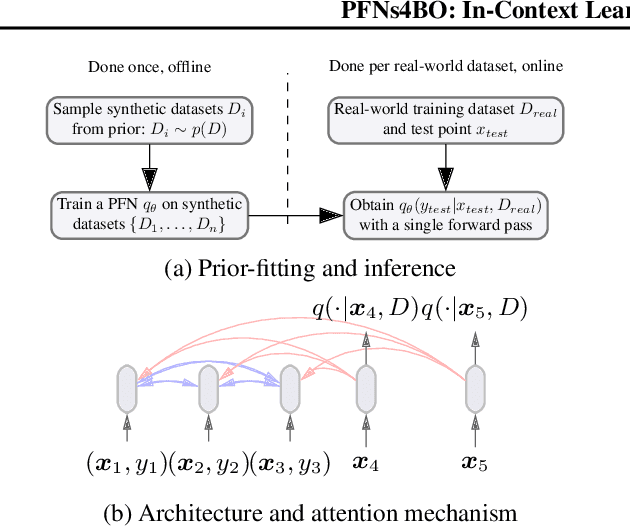
In this paper, we use Prior-data Fitted Networks (PFNs) as a flexible surrogate for Bayesian Optimization (BO). PFNs are neural processes that are trained to approximate the posterior predictive distribution (PPD) through in-context learning on any prior distribution that can be efficiently sampled from. We describe how this flexibility can be exploited for surrogate modeling in BO. We use PFNs to mimic a naive Gaussian process (GP), an advanced GP, and a Bayesian Neural Network (BNN). In addition, we show how to incorporate further information into the prior, such as allowing hints about the position of optima (user priors), ignoring irrelevant dimensions, and performing non-myopic BO by learning the acquisition function. The flexibility underlying these extensions opens up vast possibilities for using PFNs for BO. We demonstrate the usefulness of PFNs for BO in a large-scale evaluation on artificial GP samples and three different hyperparameter optimization testbeds: HPO-B, Bayesmark, and PD1. We publish code alongside trained models at https://github.com/automl/PFNs4BO.
Challenges and Opportunities for the Design of Smart Speakers
Jun 09, 2023

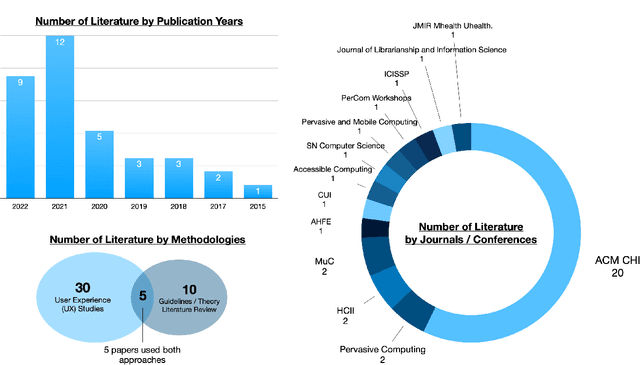
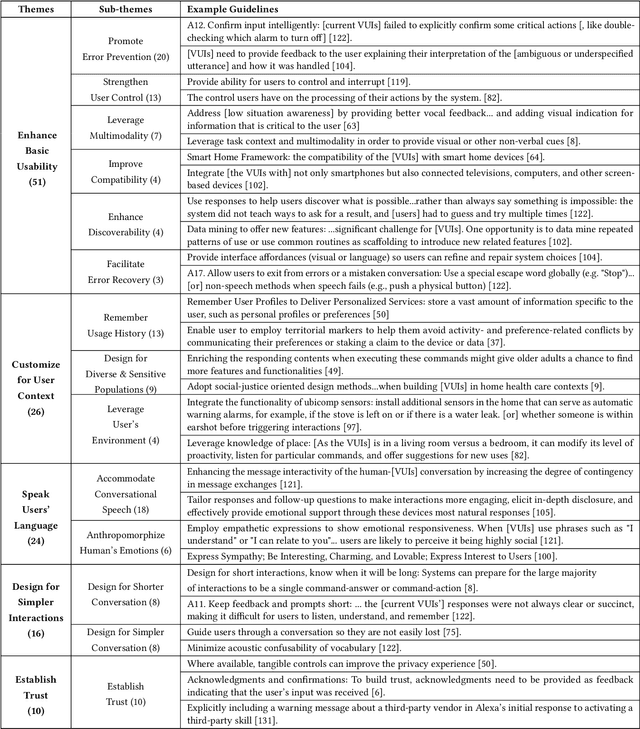
Advances in voice technology and voice user interfaces (VUIs) -- such as Alexa, Siri, and Google Home -- have opened up the potential for many new types of interaction. However, despite the potential of these devices reflected by the growing market and body of VUI research, there is a lingering sense that the technology is still underused. In this paper, we conducted a systematic literature review of 35 papers to identify and synthesize 127 VUI design guidelines into five themes. Additionally, we conducted semi-structured interviews with 15 smart speaker users to understand their use and non-use of the technology. From the interviews, we distill four design challenges that contribute the most to non-use. Based on their (non-)use, we identify four opportunity spaces for designers to explore such as focusing on information support while multitasking (cooking, driving, childcare, etc), incorporating users' mental models for smart speakers, and integrating calm design principles.
Understanding the Benefits of Image Augmentations
Jun 09, 2023Image Augmentations are widely used to reduce overfitting in neural networks. However, the explainability of their benefits largely remains a mystery. We study which layers of residual neural networks (ResNets) are most affected by augmentations using Centered Kernel Alignment (CKA). We do so by analyzing models of varying widths and depths, as well as whether their weights are initialized randomly or through transfer learning. We find that the pattern of how the layers are affected depends on the model's depth, and that networks trained with augmentation that use information from two images affect the learned weights significantly more than augmentations that operate on a single image. Deeper layers of ResNets initialized with ImageNet-1K weights and fine-tuned receive more impact from the augmentations than early layers. Understanding the effects of image augmentations on CNNs will have a variety of applications, such as determining how far back one needs to fine-tune a network and which layers should be frozen when implementing layer freezing algorithms.
WePaMaDM-Outlier Detection: Weighted Outlier Detection using Pattern Approaches for Mass Data Mining
Jun 09, 2023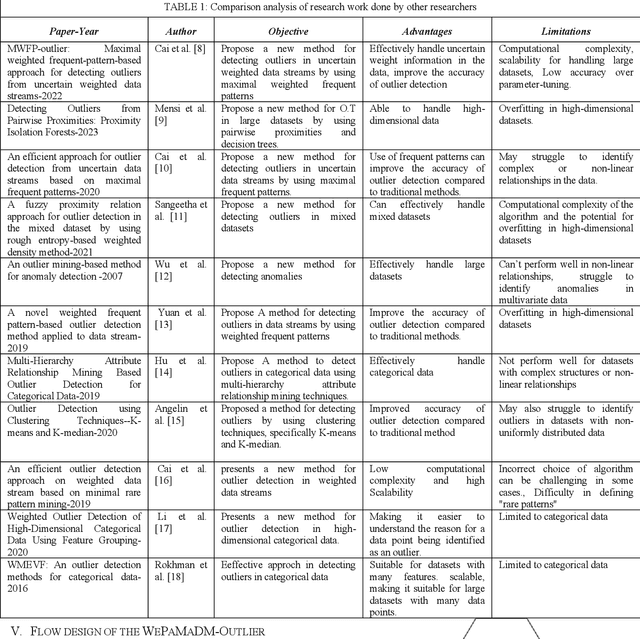
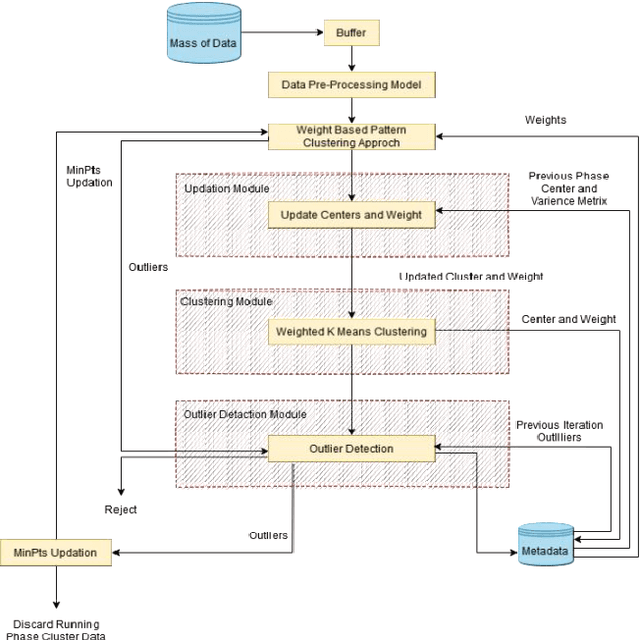
Weighted Outlier Detection is a method for identifying unusual or anomalous data points in a dataset, which can be caused by various factors like human error, fraud, or equipment malfunctions. Detecting outliers can reveal vital information about system faults, fraudulent activities, and patterns in the data, assisting experts in addressing the root causes of these anomalies. However,creating a model of normal data patterns to identify outliers can be challenging due to the nature of input data, labeled data availability, and specific requirements of the problem. This article proposed the WePaMaDM-Outlier Detection with distinct mass data mining domain, demonstrating that such techniques are domain-dependent and usually developed for specific problem formulations. Nevertheless, similar domains can adapt solutions with modifications. This work also investigates the significance of data modeling in outlier detection techniques in surveillance, fault detection, and trend analysis, also referred to as novelty detection, a semisupervised task where the algorithm learns to recognize abnormality while being taught the normal class.
Augmentation-aware Self-supervised Learning with Guided Projector
May 31, 2023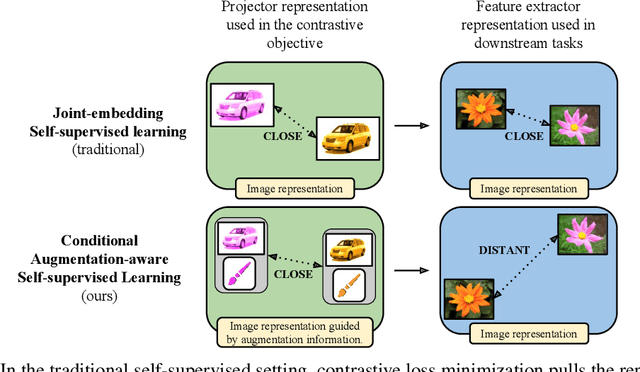
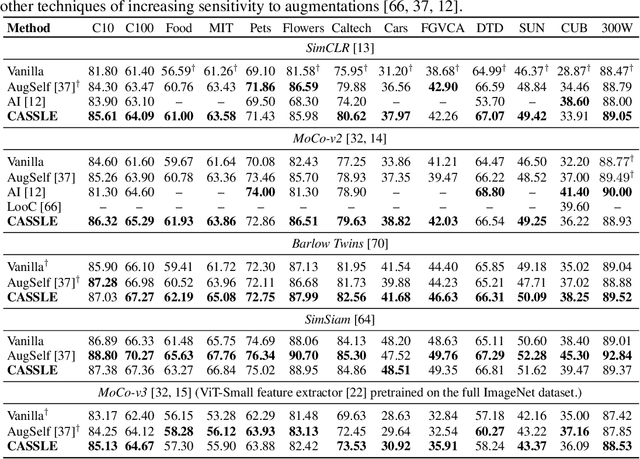
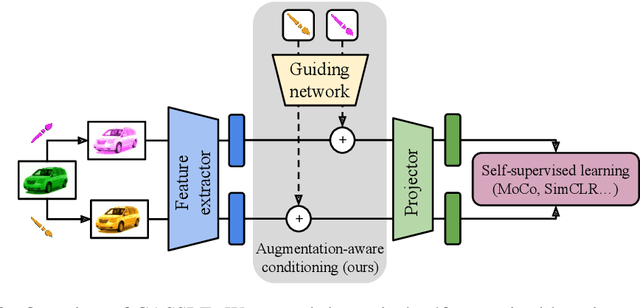

Self-supervised learning (SSL) is a powerful technique for learning robust representations from unlabeled data. By learning to remain invariant to applied data augmentations, methods such as SimCLR and MoCo are able to reach quality on par with supervised approaches. However, this invariance may be harmful to solving some downstream tasks which depend on traits affected by augmentations used during pretraining, such as color. In this paper, we propose to foster sensitivity to such characteristics in the representation space by modifying the projector network, a common component of self-supervised architectures. Specifically, we supplement the projector with information about augmentations applied to images. In order for the projector to take advantage of this auxiliary guidance when solving the SSL task, the feature extractor learns to preserve the augmentation information in its representations. Our approach, coined Conditional Augmentation-aware Selfsupervised Learning (CASSLE), is directly applicable to typical joint-embedding SSL methods regardless of their objective functions. Moreover, it does not require major changes in the network architecture or prior knowledge of downstream tasks. In addition to an analysis of sensitivity towards different data augmentations, we conduct a series of experiments, which show that CASSLE improves over various SSL methods, reaching state-of-the-art performance in multiple downstream tasks.