 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Rubric Generation for Improving LLM Judge and Reward Modeling for Open-ended Tasks
Feb 04, 2026Recently, rubrics have been used to guide LLM judges in capturing subjective, nuanced, multi-dimensional human preferences, and have been extended from evaluation to reward signals for reinforcement fine-tuning (RFT). However, rubric generation remains hard to control: rubrics often lack coverage, conflate dimensions, misalign preference direction, and contain redundant or highly correlated criteria, degrading judge accuracy and producing suboptimal rewards during RFT. We propose RRD, a principled framework for rubric refinement built on a recursive decompose-filter cycle. RRD decomposes coarse rubrics into fine-grained, discriminative criteria, expanding coverage while sharpening separation between responses. A complementary filtering mechanism removes misaligned and redundant rubrics, and a correlation-aware weighting scheme prevents over-representing highly correlated criteria, yielding rubric sets that are informative, comprehensive, and non-redundant. Empirically, RRD delivers large, consistent gains across both evaluation and training: it improves preference-judgment accuracy on JudgeBench and PPE for both GPT-4o and Llama3.1-405B judges, achieving top performance in all settings with up to +17.7 points on JudgeBench. When used as the reward source for RFT on WildChat, it yields substantially stronger and more stable learning signals, boosting reward by up to 160% (Qwen3-4B) and 60% (Llama3.1-8B) versus 10-20% for prior rubric baselines, with gains that transfer to HealthBench-Hard and BiGGen Bench. Overall, RRD establishes recursive rubric refinement as a scalable and interpretable foundation for LLM judging and reward modeling in open-ended domains.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Training AI Co-Scientists Using Rubric Rewards
Dec 29, 2025AI co-scientists are emerging as a tool to assist human researchers in achieving their research goals. A crucial feature of these AI co-scientists is the ability to generate a research plan given a set of aims and constraints. The plan may be used by researchers for brainstorming, or may even be implemented after further refinement. However, language models currently struggle to generate research plans that follow all constraints and implicit requirements. In this work, we study how to leverage the vast corpus of existing research papers to train language models that generate better research plans. We build a scalable, diverse training corpus by automatically extracting research goals and goal-specific grading rubrics from papers across several domains. We then train models for research plan generation via reinforcement learning with self-grading. A frozen copy of the initial policy acts as the grader during training, with the rubrics creating a generator-verifier gap that enables improvements without external human supervision. To validate this approach, we conduct a study with human experts for machine learning research goals, spanning 225 hours. The experts prefer plans generated by our finetuned Qwen3-30B-A3B model over the initial model for 70% of research goals, and approve 84% of the automatically extracted goal-specific grading rubrics. To assess generality, we also extend our approach to research goals from medical papers, and new arXiv preprints, evaluating with a jury of frontier models. Our finetuning yields 12-22% relative improvements and significant cross-domain generalization, proving effective even in problem settings like medical research where execution feedback is infeasible. Together, these findings demonstrate the potential of a scalable, automated training recipe as a step towards improving general AI co-scientists.
Balanced Accuracy: The Right Metric for Evaluating LLM Judges -- Explained through Youden's J statistic
Dec 08, 2025



Rigorous evaluation of large language models (LLMs) relies on comparing models by the prevalence of desirable or undesirable behaviors, such as task pass rates or policy violations. These prevalence estimates are produced by a classifier, either an LLM-as-a-judge or human annotators, making the choice of classifier central to trustworthy evaluation. Common metrics used for this choice, such as Accuracy, Precision, and F1, are sensitive to class imbalance and to arbitrary choices of positive class, and can favor judges that distort prevalence estimates. We show that Youden's $J$ statistic is theoretically aligned with choosing the best judge to compare models, and that Balanced Accuracy is an equivalent linear transformation of $J$. Through both analytical arguments and empirical examples and simulations, we demonstrate how selecting judges using Balanced Accuracy leads to better, more robust classifier selection.
EXACT: Extensive Attack for Split Learning
May 25, 2023



Privacy-Preserving machine learning (PPML) can help us train and deploy models that utilize private information. In particular, on-device Machine Learning allows us to completely avoid sharing information with a third-party server during inference. However, on-device models are typically less accurate when compared to the server counterparts due to the fact that (1) they typically only rely on a small set of on-device features and (2) they need to be small enough to run efficiently on end-user devices. Split Learning (SL) is a promising approach that can overcome these limitations. In SL, a large machine learning model is divided into two parts, with the bigger part residing on the server-side and a smaller part executing on-device, aiming to incorporate the private features. However, end-to-end training of such models requires exchanging gradients at the cut layer, which might encode private features or labels. In this paper, we provide insights into potential privacy risks associated with SL and introduce a novel attack method, EXACT, to reconstruct private information. Furthermore, we also investigate the effectiveness of various mitigation strategies. Our results indicate that the gradients significantly improve the attacker's effectiveness in all three datasets reaching almost 100% reconstruction accuracy for some features. However, a small amount of differential privacy (DP) is quite effective in mitigating this risk without causing significant training degradation.
FEL: High Capacity Learning for Recommendation and Ranking via Federated Ensemble Learning
Jun 07, 2022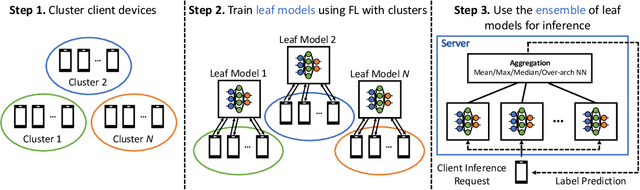
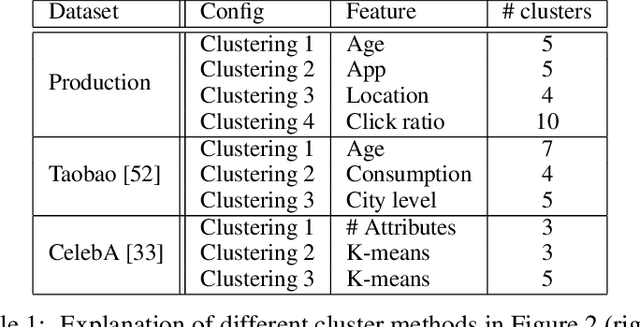
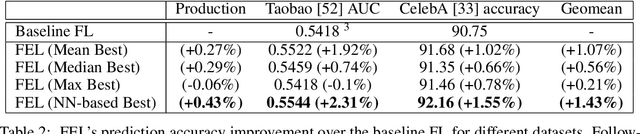
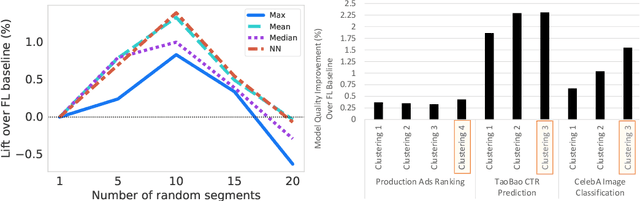
Federated learning (FL) has emerged as an effective approach to address consumer privacy needs. FL has been successfully applied to certain machine learning tasks, such as training smart keyboard models and keyword spotting. Despite FL's initial success, many important deep learning use cases, such as ranking and recommendation tasks, have been limited from on-device learning. One of the key challenges faced by practical FL adoption for DL-based ranking and recommendation is the prohibitive resource requirements that cannot be satisfied by modern mobile systems. We propose Federated Ensemble Learning (FEL) as a solution to tackle the large memory requirement of deep learning ranking and recommendation tasks. FEL enables large-scale ranking and recommendation model training on-device by simultaneously training multiple model versions on disjoint clusters of client devices. FEL integrates the trained sub-models via an over-arch layer into an ensemble model that is hosted on the server. Our experiments demonstrate that FEL leads to 0.43-2.31% model quality improvement over traditional on-device federated learning - a significant improvement for ranking and recommendation system use cases.
Smart at what cost? Characterising Mobile Deep Neural Networks in the wild
Sep 28, 2021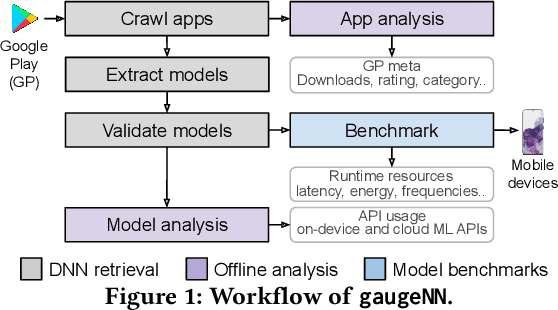
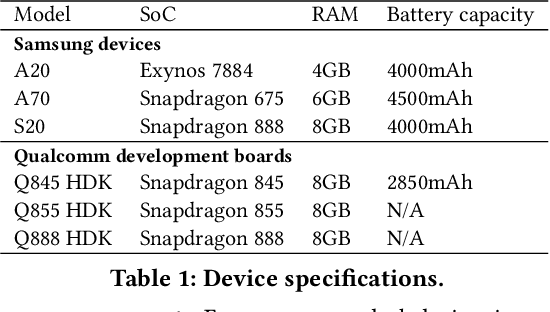
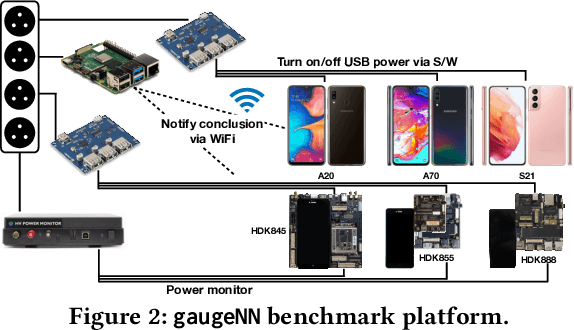
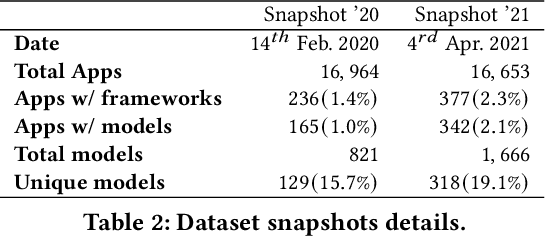
With smartphones' omnipresence in people's pockets, Machine Learning (ML) on mobile is gaining traction as devices become more powerful. With applications ranging from visual filters to voice assistants, intelligence on mobile comes in many forms and facets. However, Deep Neural Network (DNN) inference remains a compute intensive workload, with devices struggling to support intelligence at the cost of responsiveness.On the one hand, there is significant research on reducing model runtime requirements and supporting deployment on embedded devices. On the other hand, the strive to maximise the accuracy of a task is supported by deeper and wider neural networks, making mobile deployment of state-of-the-art DNNs a moving target. In this paper, we perform the first holistic study of DNN usage in the wild in an attempt to track deployed models and match how these run on widely deployed devices. To this end, we analyse over 16k of the most popular apps in the Google Play Store to characterise their DNN usage and performance across devices of different capabilities, both across tiers and generations. Simultaneously, we measure the models' energy footprint, as a core cost dimension of any mobile deployment. To streamline the process, we have developed gaugeNN, a tool that automates the deployment, measurement and analysis of DNNs on devices, with support for different frameworks and platforms. Results from our experience study paint the landscape of deep learning deployments on smartphones and indicate their popularity across app developers. Furthermore, our study shows the gap between bespoke techniques and real-world deployments and the need for optimised deployment of deep learning models in a highly dynamic and heterogeneous ecosystem.
How to Reach Real-Time AI on Consumer Devices? Solutions for Programmable and Custom Architectures
Jun 21, 2021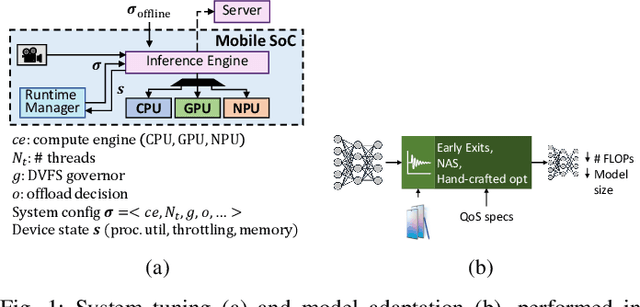
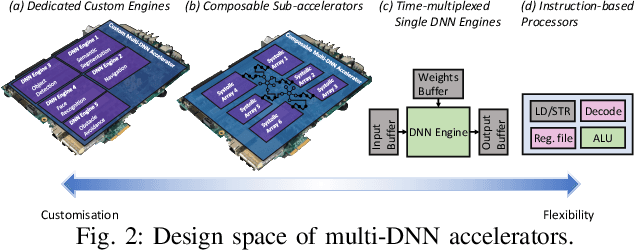
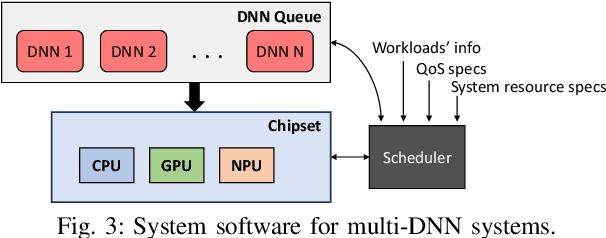
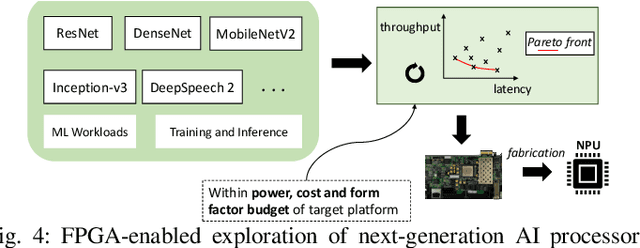
The unprecedented performance of deep neural networks (DNNs) has led to large strides in various Artificial Intelligence (AI) inference tasks, such as object and speech recognition. Nevertheless, deploying such AI models across commodity devices faces significant challenges: large computational cost, multiple performance objectives, hardware heterogeneity and a common need for high accuracy, together pose critical problems to the deployment of DNNs across the various embedded and mobile devices in the wild. As such, we have yet to witness the mainstream usage of state-of-the-art deep learning algorithms across consumer devices. In this paper, we provide preliminary answers to this potentially game-changing question by presenting an array of design techniques for efficient AI systems. We start by examining the major roadblocks when targeting both programmable processors and custom accelerators. Then, we present diverse methods for achieving real-time performance following a cross-stack approach. These span model-, system- and hardware-level techniques, and their combination. Our findings provide illustrative examples of AI systems that do not overburden mobile hardware, while also indicating how they can improve inference accuracy. Moreover, we showcase how custom ASIC- and FPGA-based accelerators can be an enabling factor for next-generation AI applications, such as multi-DNN systems. Collectively, these results highlight the critical need for further exploration as to how the various cross-stack solutions can be best combined in order to bring the latest advances in deep learning close to users, in a robust and efficient manner.
DynO: Dynamic Onloading of Deep Neural Networks from Cloud to Device
Apr 20, 2021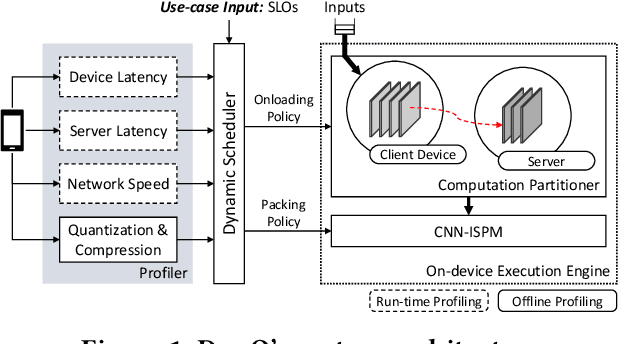

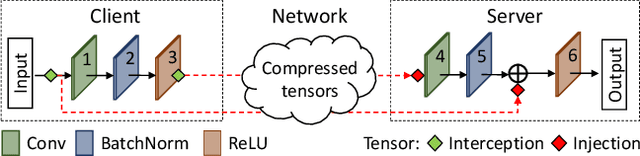
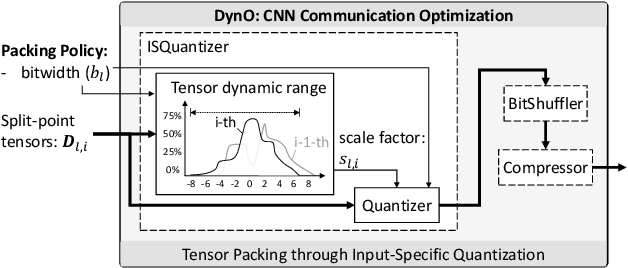
Recently, there has been an explosive growth of mobile and embedded applications using convolutional neural networks(CNNs). To alleviate their excessive computational demands, developers have traditionally resorted to cloud offloading, inducing high infrastructure costs and a strong dependence on networking conditions. On the other end, the emergence of powerful SoCs is gradually enabling on-device execution. Nonetheless, low- and mid-tier platforms still struggle to run state-of-the-art CNNs sufficiently. In this paper, we present DynO, a distributed inference framework that combines the best of both worlds to address several challenges, such as device heterogeneity, varying bandwidth and multi-objective requirements. Key components that enable this are its novel CNN-specific data packing method, which exploits the variability of precision needs in different parts of the CNN when onloading computation, and its novel scheduler that jointly tunes the partition point and transferred data precision at run time to adapt inference to its execution environment. Quantitative evaluation shows that DynO outperforms the current state-of-the-art, improving throughput by over an order of magnitude over device-only execution and up to 7.9x over competing CNN offloading systems, with up to 60x less data transferred.
FjORD: Fair and Accurate Federated Learning under heterogeneous targets with Ordered Dropout
Mar 01, 2021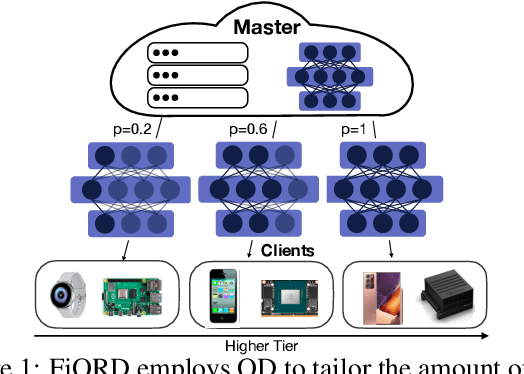
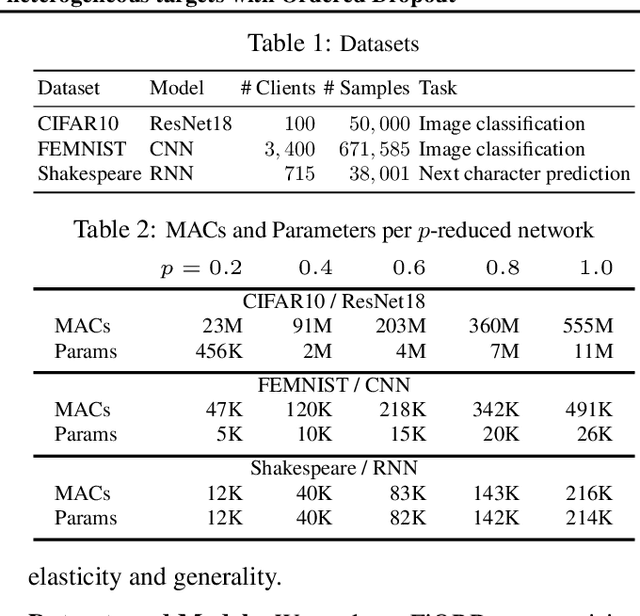
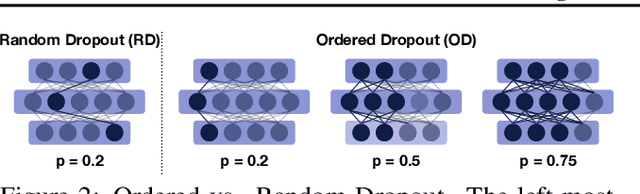
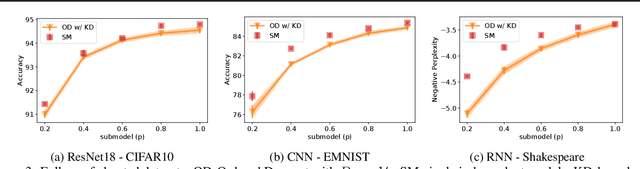
Federated Learning (FL) has been gaining significant traction across different ML tasks, ranging from vision to keyboard predictions. In large-scale deployments, client heterogeneity is a fact, and constitutes a primary problem for fairness, training performance and accuracy. Although significant efforts have been made into tackling statistical data heterogeneity, the diversity in the processing capabilities and network bandwidth of clients, termed as system heterogeneity, has remained largely unexplored. Current solutions either disregard a large portion of available devices or set a uniform limit on the model's capacity, restricted by the least capable participants. In this work, we introduce Ordered Dropout, a mechanism that achieves an ordered, nested representation of knowledge in Neural Networks and enables the extraction of lower footprint submodels without the need of retraining. We further show that for linear maps our Ordered Dropout is equivalent to SVD. We employ this technique, along with a self-distillation methodology, in the realm of FL in a framework called FjORD. FjORD alleviates the problem of client system heterogeneity by tailoring the model width to the client's capabilities. Extensive evaluation on both CNNs and RNNs across diverse modalities shows that FjORD consistently leads to significant performance gains over state-of-the-art baselines, while maintaining its nested structure.