 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Functional Memorization in Code Language Models
Jun 11, 2026Large language models (LLMs) are increasingly used to generate code at scale. Meanwhile, prior work has investigated whether training data may be recoverable from model outputs, by auditing the textual overlap between training examples and model generations. Code, however, can be functionally equivalent while textually dissimilar. In this work, we study functional memorization: extraction of functional logic beyond what verbatim metrics detect. We construct a counterfactual setup for Olmo-3-32B, comparing a midtrained model (exposed to target code) against a pretrained reference (not exposed). We prompt both models with Python function signatures and measure both textual and functional similarity (i.e., LLM-as-a-judge, execution-based). Our results show clear evidence of functional memorization, highlighting the need for auditing metrics that go beyond textual overlap.
Observational Auditing of Label Privacy
Nov 18, 2025Differential privacy (DP) auditing is essential for evaluating privacy guarantees in machine learning systems. Existing auditing methods, however, pose a significant challenge for large-scale systems since they require modifying the training dataset -- for instance, by injecting out-of-distribution canaries or removing samples from training. Such interventions on the training data pipeline are resource-intensive and involve considerable engineering overhead. We introduce a novel observational auditing framework that leverages the inherent randomness of data distributions, enabling privacy evaluation without altering the original dataset. Our approach extends privacy auditing beyond traditional membership inference to protected attributes, with labels as a special case, addressing a key gap in existing techniques. We provide theoretical foundations for our method and perform experiments on Criteo and CIFAR-10 datasets that demonstrate its effectiveness in auditing label privacy guarantees. This work opens new avenues for practical privacy auditing in large-scale production environments.
Auditing $f$-Differential Privacy in One Run
Oct 29, 2024



Empirical auditing has emerged as a means of catching some of the flaws in the implementation of privacy-preserving algorithms. Existing auditing mechanisms, however, are either computationally inefficient requiring multiple runs of the machine learning algorithms or suboptimal in calculating an empirical privacy. In this work, we present a tight and efficient auditing procedure and analysis that can effectively assess the privacy of mechanisms. Our approach is efficient; similar to the recent work of Steinke, Nasr, and Jagielski (2023), our auditing procedure leverages the randomness of examples in the input dataset and requires only a single run of the target mechanism. And it is more accurate; we provide a novel analysis that enables us to achieve tight empirical privacy estimates by using the hypothesized $f$-DP curve of the mechanism, which provides a more accurate measure of privacy than the traditional $\epsilon,\delta$ differential privacy parameters. We use our auditing procure and analysis to obtain empirical privacy, demonstrating that our auditing procedure delivers tighter privacy estimates.
Noisy Neighbors: Efficient membership inference attacks against LLMs
Jun 24, 2024


The potential of transformer-based LLMs risks being hindered by privacy concerns due to their reliance on extensive datasets, possibly including sensitive information. Regulatory measures like GDPR and CCPA call for using robust auditing tools to address potential privacy issues, with Membership Inference Attacks (MIA) being the primary method for assessing LLMs' privacy risks. Differently from traditional MIA approaches, often requiring computationally intensive training of additional models, this paper introduces an efficient methodology that generates \textit{noisy neighbors} for a target sample by adding stochastic noise in the embedding space, requiring operating the target model in inference mode only. Our findings demonstrate that this approach closely matches the effectiveness of employing shadow models, showing its usability in practical privacy auditing scenarios.
ReMasker: Imputing Tabular Data with Masked Autoencoding
Sep 25, 2023



We present ReMasker, a new method of imputing missing values in tabular data by extending the masked autoencoding framework. Compared with prior work, ReMasker is both simple -- besides the missing values (i.e., naturally masked), we randomly ``re-mask'' another set of values, optimize the autoencoder by reconstructing this re-masked set, and apply the trained model to predict the missing values; and effective -- with extensive evaluation on benchmark datasets, we show that ReMasker performs on par with or outperforms state-of-the-art methods in terms of both imputation fidelity and utility under various missingness settings, while its performance advantage often increases with the ratio of missing data. We further explore theoretical justification for its effectiveness, showing that ReMasker tends to learn missingness-invariant representations of tabular data. Our findings indicate that masked modeling represents a promising direction for further research on tabular data imputation. The code is publicly available.
Federated Linear Contextual Bandits with User-level Differential Privacy
Jun 09, 2023

This paper studies federated linear contextual bandits under the notion of user-level differential privacy (DP). We first introduce a unified federated bandits framework that can accommodate various definitions of DP in the sequential decision-making setting. We then formally introduce user-level central DP (CDP) and local DP (LDP) in the federated bandits framework, and investigate the fundamental trade-offs between the learning regrets and the corresponding DP guarantees in a federated linear contextual bandits model. For CDP, we propose a federated algorithm termed as $\texttt{ROBIN}$ and show that it is near-optimal in terms of the number of clients $M$ and the privacy budget $\varepsilon$ by deriving nearly-matching upper and lower regret bounds when user-level DP is satisfied. For LDP, we obtain several lower bounds, indicating that learning under user-level $(\varepsilon,\delta)$-LDP must suffer a regret blow-up factor at least $\min\{1/\varepsilon,M\}$ or $\min\{1/\sqrt{\varepsilon},\sqrt{M}\}$ under different conditions.
EXACT: Extensive Attack for Split Learning
May 25, 2023



Privacy-Preserving machine learning (PPML) can help us train and deploy models that utilize private information. In particular, on-device Machine Learning allows us to completely avoid sharing information with a third-party server during inference. However, on-device models are typically less accurate when compared to the server counterparts due to the fact that (1) they typically only rely on a small set of on-device features and (2) they need to be small enough to run efficiently on end-user devices. Split Learning (SL) is a promising approach that can overcome these limitations. In SL, a large machine learning model is divided into two parts, with the bigger part residing on the server-side and a smaller part executing on-device, aiming to incorporate the private features. However, end-to-end training of such models requires exchanging gradients at the cut layer, which might encode private features or labels. In this paper, we provide insights into potential privacy risks associated with SL and introduce a novel attack method, EXACT, to reconstruct private information. Furthermore, we also investigate the effectiveness of various mitigation strategies. Our results indicate that the gradients significantly improve the attacker's effectiveness in all three datasets reaching almost 100% reconstruction accuracy for some features. However, a small amount of differential privacy (DP) is quite effective in mitigating this risk without causing significant training degradation.
FEL: High Capacity Learning for Recommendation and Ranking via Federated Ensemble Learning
Jun 07, 2022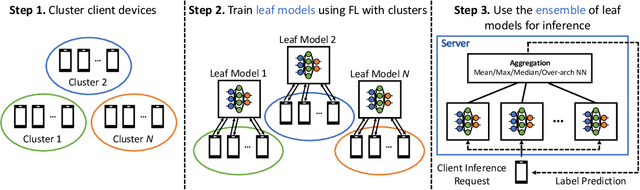
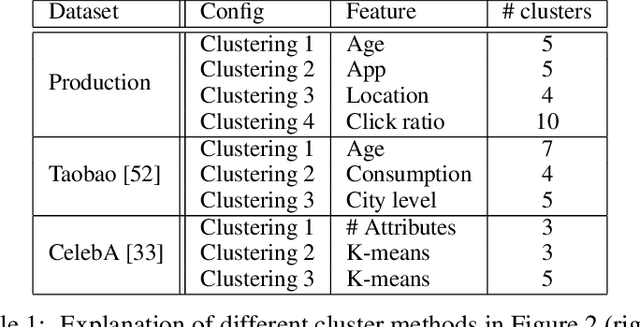
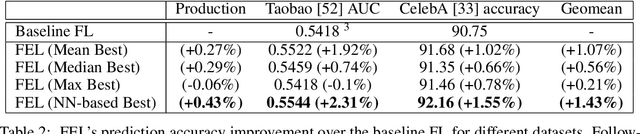
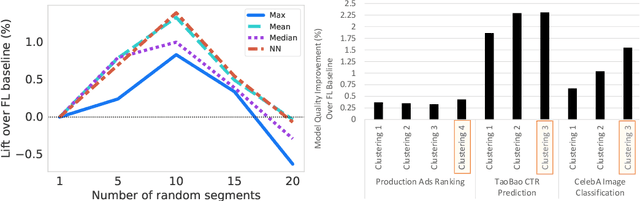
Federated learning (FL) has emerged as an effective approach to address consumer privacy needs. FL has been successfully applied to certain machine learning tasks, such as training smart keyboard models and keyword spotting. Despite FL's initial success, many important deep learning use cases, such as ranking and recommendation tasks, have been limited from on-device learning. One of the key challenges faced by practical FL adoption for DL-based ranking and recommendation is the prohibitive resource requirements that cannot be satisfied by modern mobile systems. We propose Federated Ensemble Learning (FEL) as a solution to tackle the large memory requirement of deep learning ranking and recommendation tasks. FEL enables large-scale ranking and recommendation model training on-device by simultaneously training multiple model versions on disjoint clusters of client devices. FEL integrates the trained sub-models via an over-arch layer into an ensemble model that is hosted on the server. Our experiments demonstrate that FEL leads to 0.43-2.31% model quality improvement over traditional on-device federated learning - a significant improvement for ranking and recommendation system use cases.
Towards Fair Federated Recommendation Learning: Characterizing the Inter-Dependence of System and Data Heterogeneity
May 30, 2022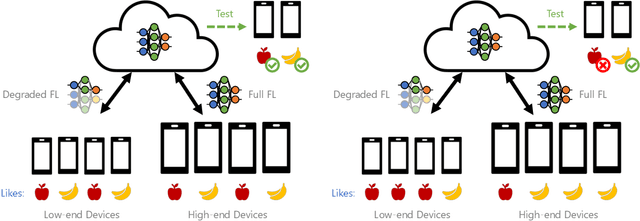
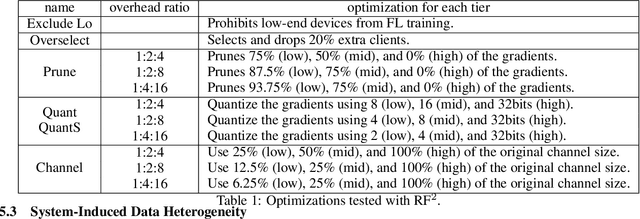
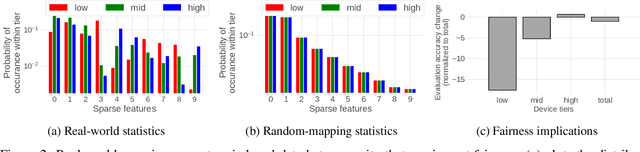
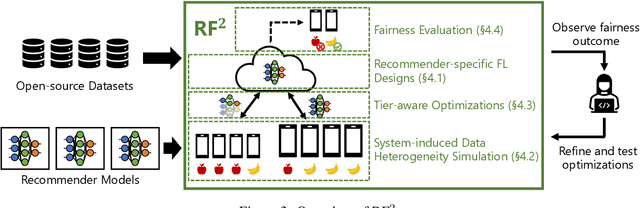
Federated learning (FL) is an effective mechanism for data privacy in recommender systems by running machine learning model training on-device. While prior FL optimizations tackled the data and system heterogeneity challenges faced by FL, they assume the two are independent of each other. This fundamental assumption is not reflective of real-world, large-scale recommender systems -- data and system heterogeneity are tightly intertwined. This paper takes a data-driven approach to show the inter-dependence of data and system heterogeneity in real-world data and quantifies its impact on the overall model quality and fairness. We design a framework, RF^2, to model the inter-dependence and evaluate its impact on state-of-the-art model optimization techniques for federated recommendation tasks. We demonstrate that the impact on fairness can be severe under realistic heterogeneity scenarios, by up to 15.8--41x compared to a simple setup assumed in most (if not all) prior work. It means when realistic system-induced data heterogeneity is not properly modeled, the fairness impact of an optimization can be downplayed by up to 41x. The result shows that modeling realistic system-induced data heterogeneity is essential to achieving fair federated recommendation learning. We plan to open-source RF^2 to enable future design and evaluation of FL innovations.
Differentially Private Query Release Through Adaptive Projection
Mar 11, 2021
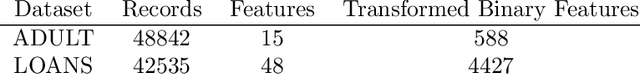

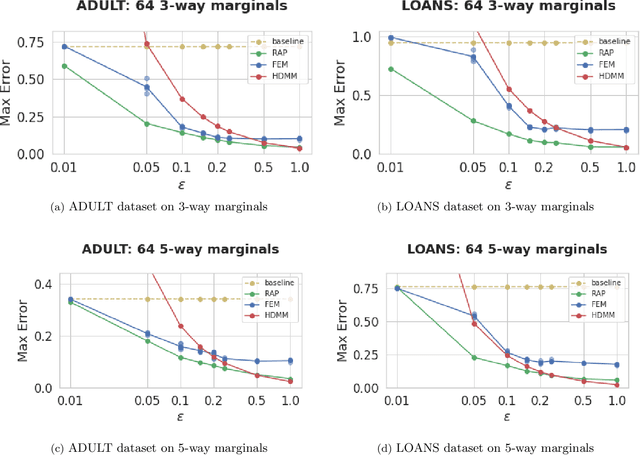
We propose, implement, and evaluate a new algorithm for releasing answers to very large numbers of statistical queries like $k$-way marginals, subject to differential privacy. Our algorithm makes adaptive use of a continuous relaxation of the Projection Mechanism, which answers queries on the private dataset using simple perturbation, and then attempts to find the synthetic dataset that most closely matches the noisy answers. We use a continuous relaxation of the synthetic dataset domain which makes the projection loss differentiable, and allows us to use efficient ML optimization techniques and tooling. Rather than answering all queries up front, we make judicious use of our privacy budget by iteratively and adaptively finding queries for which our (relaxed) synthetic data has high error, and then repeating the projection. We perform extensive experimental evaluations across a range of parameters and datasets, and find that our method outperforms existing algorithms in many cases, especially when the privacy budget is small or the query class is large.