 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Long-term Microscopic Traffic Simulation with History-Masked Multi-agent Imitation Learning
Jun 10, 2023
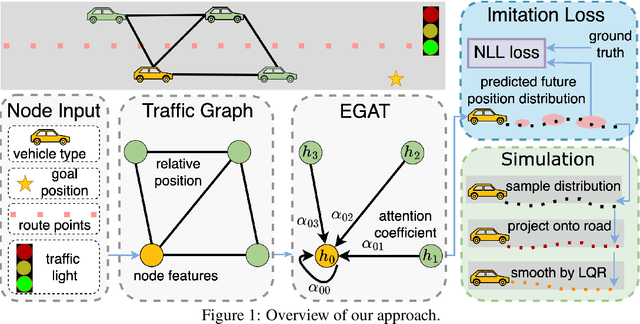
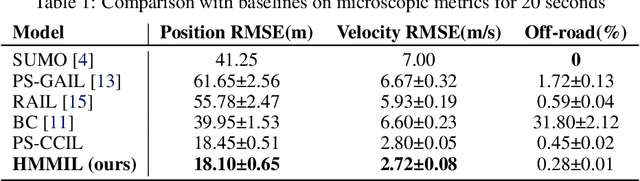
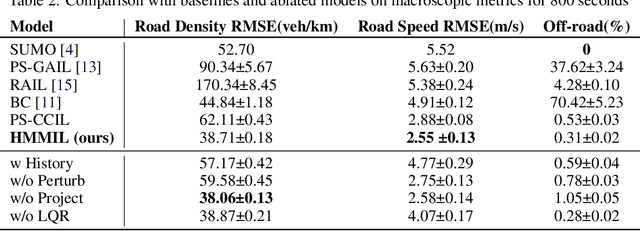
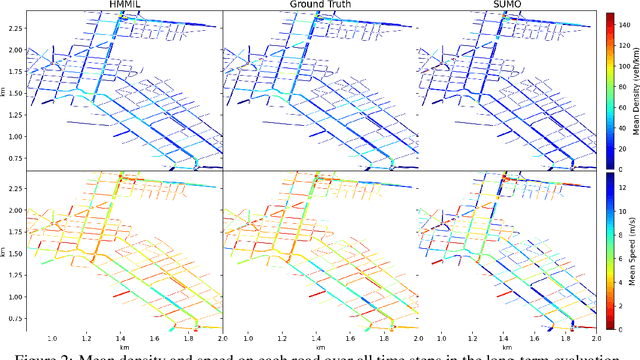
A realistic long-term microscopic traffic simulator is necessary for understanding how microscopic changes affect traffic patterns at a larger scale. Traditional simulators that model human driving behavior with heuristic rules often fail to achieve accurate simulations due to real-world traffic complexity. To overcome this challenge, researchers have turned to neural networks, which are trained through imitation learning from human driver demonstrations. However, existing learning-based microscopic simulators often fail to generate stable long-term simulations due to the \textit{covariate shift} issue. To address this, we propose a history-masked multi-agent imitation learning method that removes all vehicles' historical trajectory information and applies perturbation to their current positions during learning. We apply our approach specifically to the urban traffic simulation problem and evaluate it on the real-world large-scale pNEUMA dataset, achieving better short-term microscopic and long-term macroscopic similarity to real-world data than state-of-the-art baselines.
Semi-supervsied Learning-based Sound Event Detection using Freuqency Dynamic Convolution with Large Kernel Attention for DCASE Challenge 2023 Task 4
Jun 10, 2023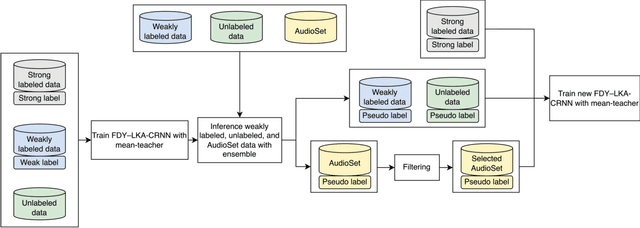
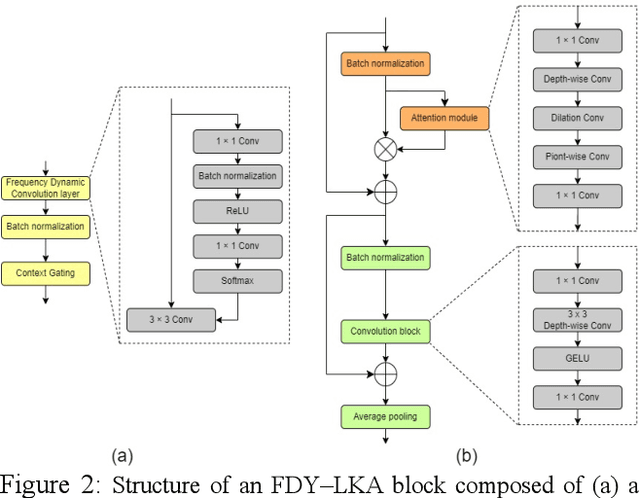

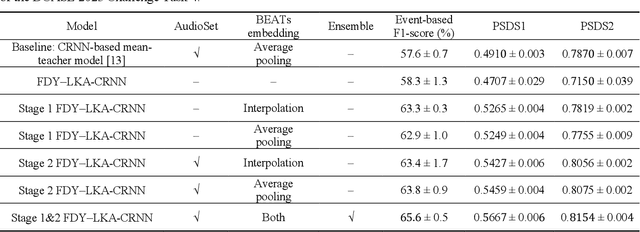
This report proposes a frequency dynamic convolution (FDY) with a large kernel attention (LKA)-convolutional recurrent neural network (CRNN) with a pre-trained bidirectional encoder representation from audio transformers (BEATs) embedding-based sound event detection (SED) model that employs a mean-teacher and pseudo-label approach to address the challenge of limited labeled data for DCASE 2023 Task 4. The proposed FDY with LKA integrates the FDY and LKA module to effectively capture time-frequency patterns, long-term dependencies, and high-level semantic information in audio signals. The proposed FDY with LKA-CRNN with a BEATs embedding network is initially trained on the entire DCASE 2023 Task 4 dataset using the mean-teacher approach, generating pseudo-labels for weakly labeled, unlabeled, and the AudioSet. Subsequently, the proposed SED model is retrained using the same pseudo-label approach. A subset of these models is selected for submission, demonstrating superior F1-scores and polyphonic SED score performance on the DCASE 2023 Challenge Task 4 validation dataset.
Low-Light Image Enhancement with Wavelet-based Diffusion Models
Jun 01, 2023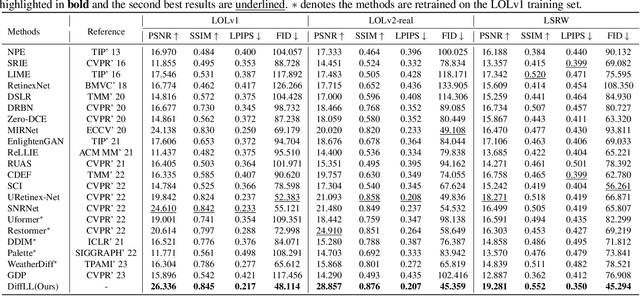
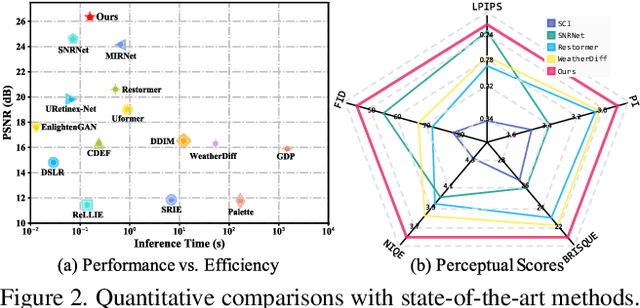
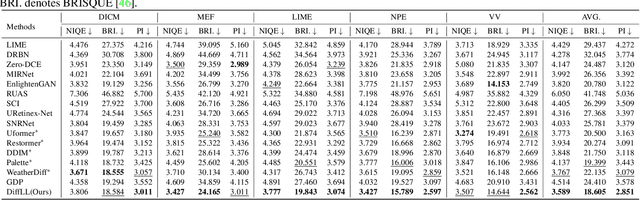
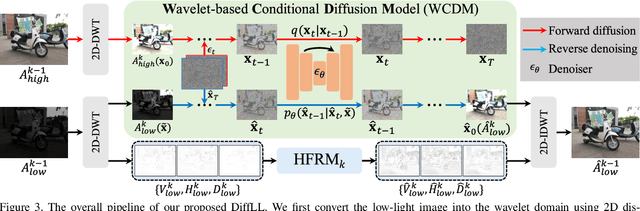
Diffusion models have achieved promising results in image restoration tasks, yet suffer from time-consuming, excessive computational resource consumption, and unstable restoration. To address these issues, we propose a robust and efficient Diffusion-based Low-Light image enhancement approach, dubbed DiffLL. Specifically, we present a wavelet-based conditional diffusion model (WCDM) that leverages the generative power of diffusion models to produce results with satisfactory perceptual fidelity. Additionally, it also takes advantage of the strengths of wavelet transformation to greatly accelerate inference and reduce computational resource usage without sacrificing information. To avoid chaotic content and diversity, we perform both forward diffusion and reverse denoising in the training phase of WCDM, enabling the model to achieve stable denoising and reduce randomness during inference. Moreover, we further design a high-frequency restoration module (HFRM) that utilizes the vertical and horizontal details of the image to complement the diagonal information for better fine-grained restoration. Extensive experiments on publicly available real-world benchmarks demonstrate that our method outperforms the existing state-of-the-art methods both quantitatively and visually, and it achieves remarkable improvements in efficiency compared to previous diffusion-based methods. In addition, we empirically show that the application for low-light face detection also reveals the latent practical values of our method.
Joint Event Extraction via Structural Semantic Matching
Jun 06, 2023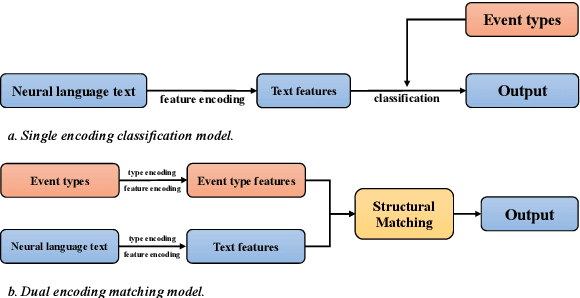
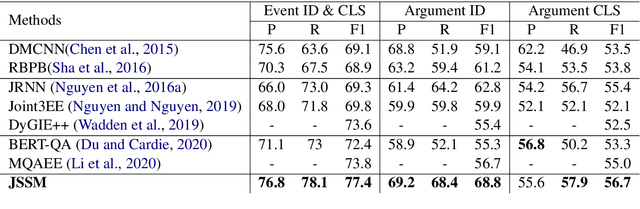
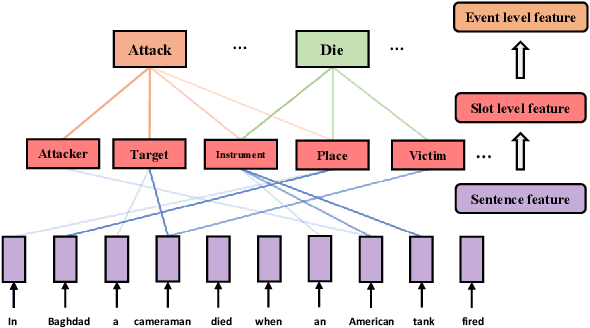
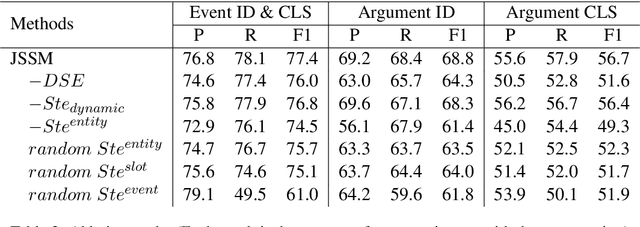
Event Extraction (EE) is one of the essential tasks in information extraction, which aims to detect event mentions from text and find the corresponding argument roles. The EE task can be abstracted as a process of matching the semantic definitions and argument structures of event types with the target text. This paper encodes the semantic features of event types and makes structural matching with target text. Specifically, Semantic Type Embedding (STE) and Dynamic Structure Encoder (DSE) modules are proposed. Also, the Joint Structural Semantic Matching (JSSM) model is built to jointly perform event detection and argument extraction tasks through a bidirectional attention layer. The experimental results on the ACE2005 dataset indicate that our model achieves a significant performance improvement
Cyclic Learning: Bridging Image-level Labels and Nuclei Instance Segmentation
Jun 05, 2023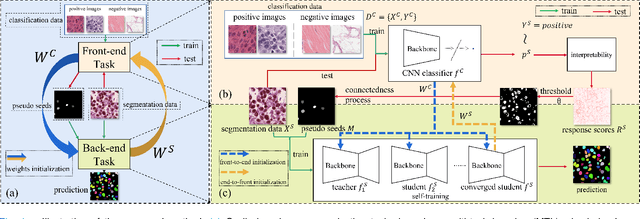



Nuclei instance segmentation on histopathology images is of great clinical value for disease analysis. Generally, fully-supervised algorithms for this task require pixel-wise manual annotations, which is especially time-consuming and laborious for the high nuclei density. To alleviate the annotation burden, we seek to solve the problem through image-level weakly supervised learning, which is underexplored for nuclei instance segmentation. Compared with most existing methods using other weak annotations (scribble, point, etc.) for nuclei instance segmentation, our method is more labor-saving. The obstacle to using image-level annotations in nuclei instance segmentation is the lack of adequate location information, leading to severe nuclei omission or overlaps. In this paper, we propose a novel image-level weakly supervised method, called cyclic learning, to solve this problem. Cyclic learning comprises a front-end classification task and a back-end semi-supervised instance segmentation task to benefit from multi-task learning (MTL). We utilize a deep learning classifier with interpretability as the front-end to convert image-level labels to sets of high-confidence pseudo masks and establish a semi-supervised architecture as the back-end to conduct nuclei instance segmentation under the supervision of these pseudo masks. Most importantly, cyclic learning is designed to circularly share knowledge between the front-end classifier and the back-end semi-supervised part, which allows the whole system to fully extract the underlying information from image-level labels and converge to a better optimum. Experiments on three datasets demonstrate the good generality of our method, which outperforms other image-level weakly supervised methods for nuclei instance segmentation, and achieves comparable performance to fully-supervised methods.
Best of Both Worlds: Hybrid SNN-ANN Architecture for Event-based Optical Flow Estimation
Jun 05, 2023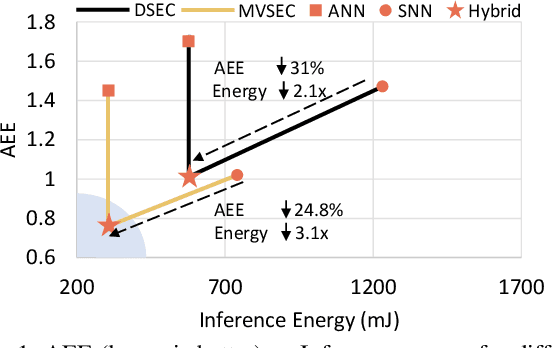
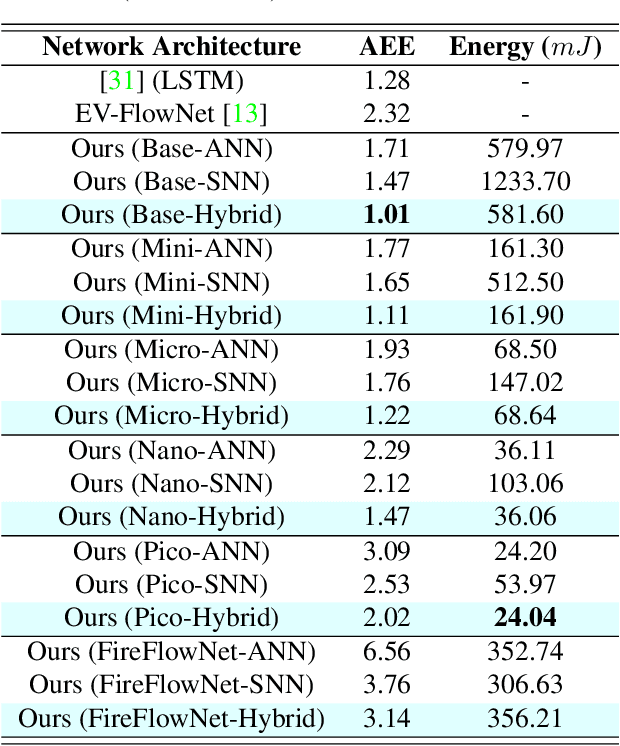
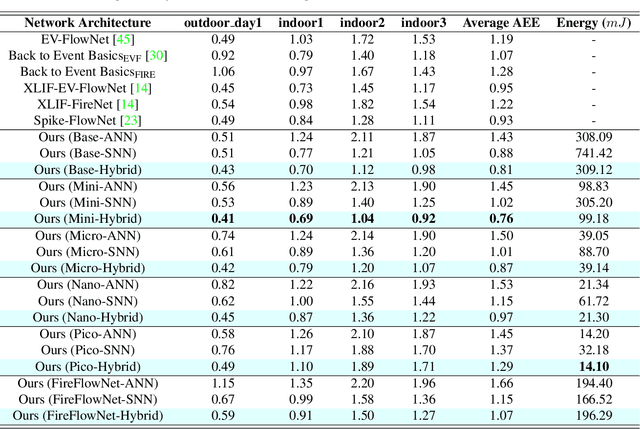
Event-based cameras offer a low-power alternative to frame-based cameras for capturing high-speed motion and high dynamic range scenes. They provide asynchronous streams of sparse events. Spiking Neural Networks (SNNs) with their asynchronous event-driven compute, show great potential for extracting the spatio-temporal features from these event streams. In contrast, the standard Analog Neural Networks (ANNs1) fail to process event data effectively. However, training SNNs is difficult due to additional trainable parameters (thresholds and leaks), vanishing spikes at deeper layers, non-differentiable binary activation function etc. Moreover, an additional data structure "membrane potential" responsible for keeping track of temporal information, must be fetched and updated at every timestep in SNNs. To overcome these, we propose a novel SNN-ANN hybrid architecture that combines the strengths of both. Specifically, we leverage the asynchronous compute capabilities of SNN layers to effectively extract the input temporal information. While the ANN layers offer trouble-free training and implementation on standard machine learning hardware such as GPUs. We provide extensive experimental analysis for assigning each layer to be spiking or analog in nature, leading to a network configuration optimized for performance and ease of training. We evaluate our hybrid architectures for optical flow estimation using event-data on DSEC-flow and Mutli-Vehicle Stereo Event-Camera (MVSEC) datasets. The results indicate that our configured hybrid architectures outperform the state-of-the-art ANN-only, SNN-only and past hybrid architectures both in terms of accuracy and efficiency. Specifically, our hybrid architecture exhibit a 31% and 24.8% lower average endpoint error (AEE) at 2.1x and 3.1x lower energy, compared to an SNN-only architecture on DSEC and MVSEC datasets, respectively.
Improving Generalization in Task-oriented Dialogues with Workflows and Action Plans
Jun 02, 2023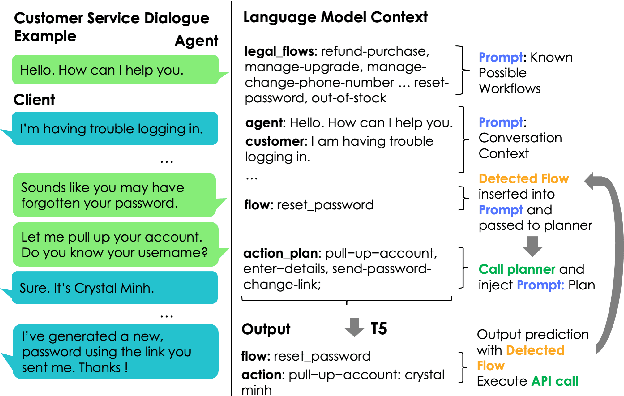

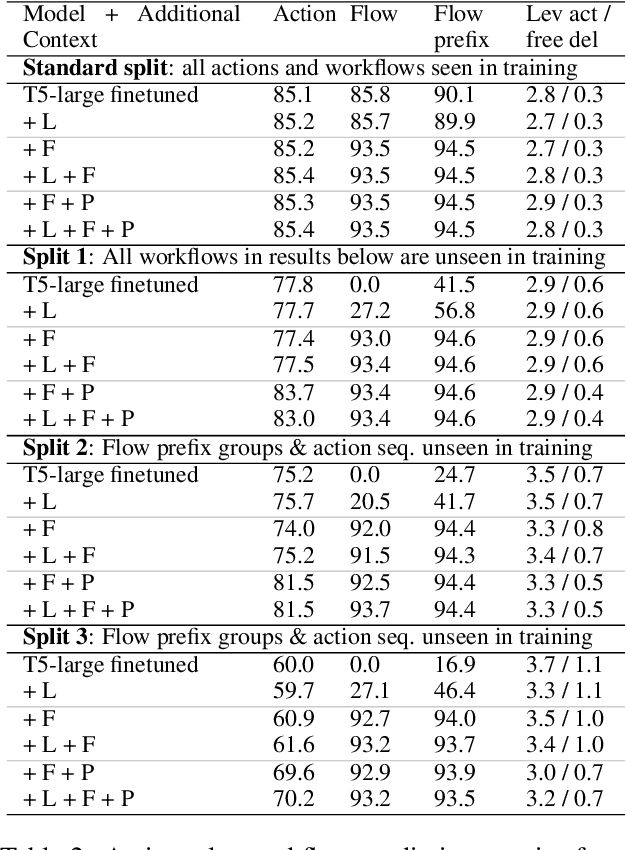
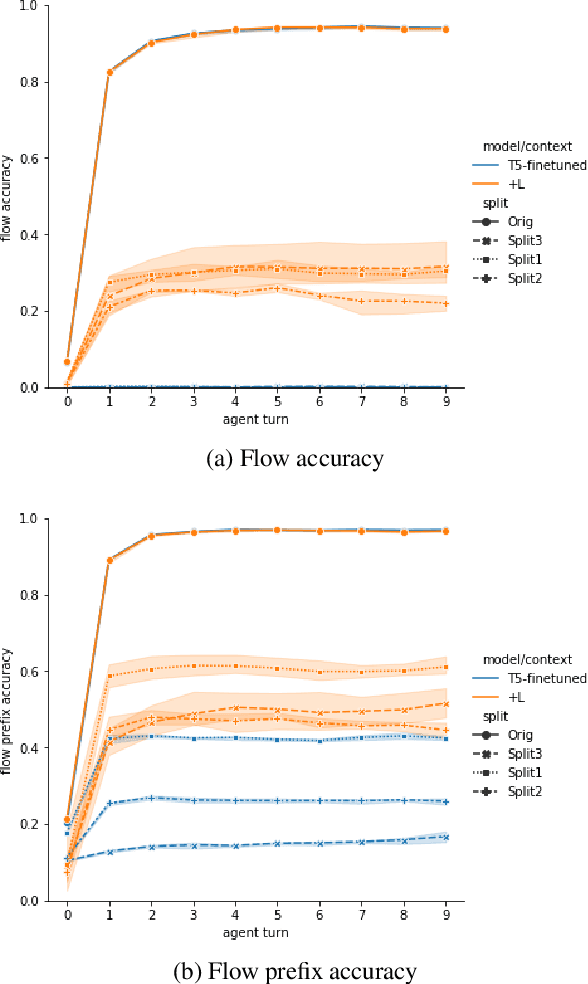
Task-oriented dialogue is difficult in part because it involves understanding user intent, collecting information from the user, executing API calls, and generating helpful and fluent responses. However, for complex tasks one must also correctly do all of these things over multiple steps, and in a specific order. While large pre-trained language models can be fine-tuned end-to-end to create multi-step task-oriented dialogue agents that generate fluent text, our experiments confirm that this approach alone cannot reliably perform new multi-step tasks that are unseen during training. To address these limitations, we augment the dialogue contexts given to \textmd{text2text} transformers with known \textit{valid workflow names} and \textit{action plans}. Action plans consist of sequences of actions required to accomplish a task, and are encoded as simple sequences of keywords (e.g. verify-identity, pull-up-account, reset-password, etc.). We perform extensive experiments on the Action-Based Conversations Dataset (ABCD) with T5-small, base and large models, and show that such models: a) are able to more readily generalize to unseen workflows by following the provided plan, and b) are able to generalize to executing unseen actions if they are provided in the plan. In contrast, models are unable to fully accomplish new multi-step tasks when they are not provided action plan information, even when given new valid workflow names.
Perceptual Kalman Filters: Online State Estimation under a Perfect Perceptual-Quality Constraint
Jun 04, 2023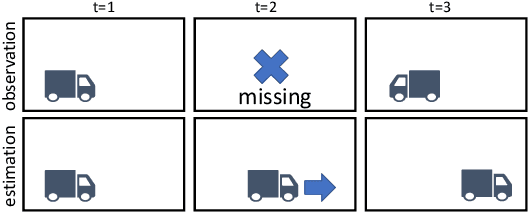
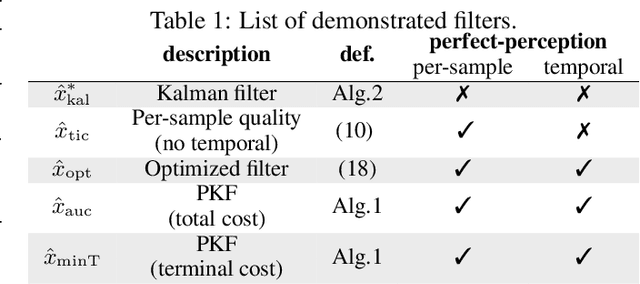
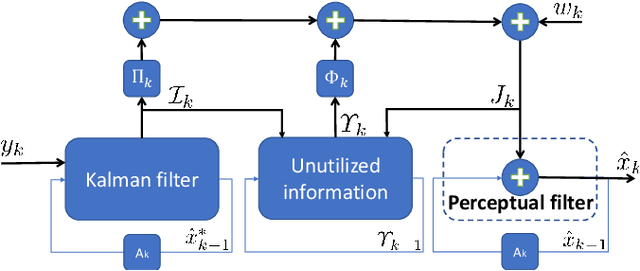
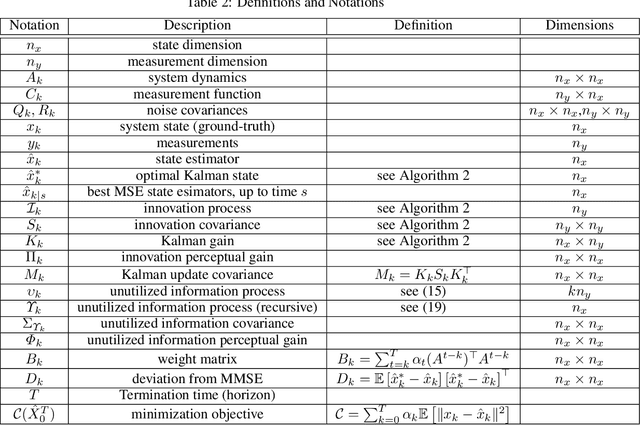
Many practical settings call for the reconstruction of temporal signals from corrupted or missing data. Classic examples include decoding, tracking, signal enhancement and denoising. Since the reconstructed signals are ultimately viewed by humans, it is desirable to achieve reconstructions that are pleasing to human perception. Mathematically, perfect perceptual-quality is achieved when the distribution of restored signals is the same as that of natural signals, a requirement which has been heavily researched in static estimation settings (i.e. when a whole signal is processed at once). Here, we study the problem of optimal causal filtering under a perfect perceptual-quality constraint, which is a task of fundamentally different nature. Specifically, we analyze a Gaussian Markov signal observed through a linear noisy transformation. In the absence of perceptual constraints, the Kalman filter is known to be optimal in the MSE sense for this setting. Here, we show that adding the perfect perceptual quality constraint (i.e. the requirement of temporal consistency), introduces a fundamental dilemma whereby the filter may have to "knowingly" ignore new information revealed by the observations in order to conform to its past decisions. This often comes at the cost of a significant increase in the MSE (beyond that encountered in static settings). Our analysis goes beyond the classic innovation process of the Kalman filter, and introduces the novel concept of an unutilized information process. Using this tool, we present a recursive formula for perceptual filters, and demonstrate the qualitative effects of perfect perceptual-quality estimation on a video reconstruction problem.
Application of an ontology for model cards to generate computable artifacts for linking machine learning information from biomedical research
Mar 21, 2023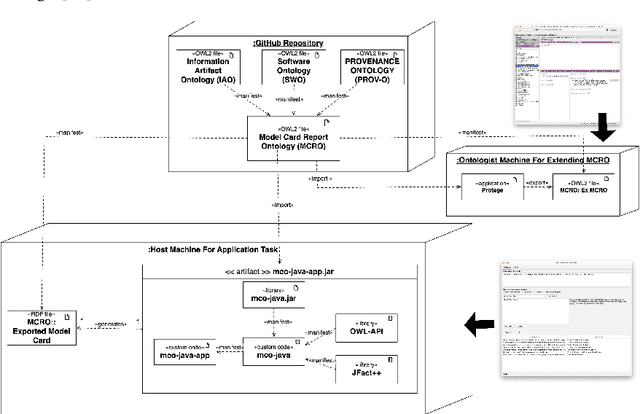
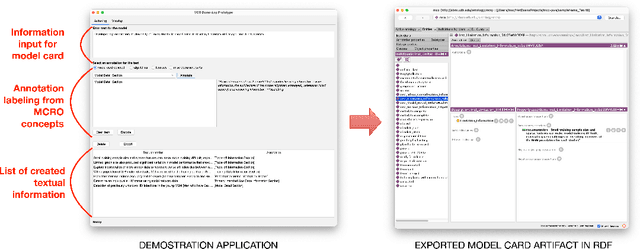
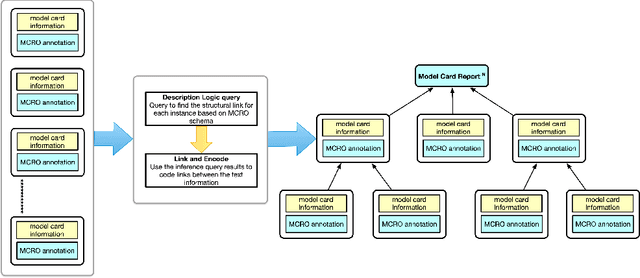
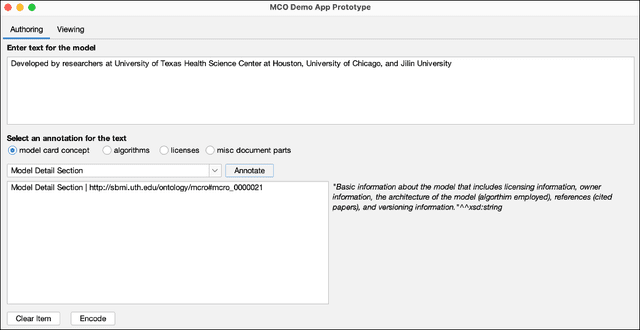
Model card reports provide a transparent description of machine learning models which includes information about their evaluation, limitations, intended use, etc. Federal health agencies have expressed an interest in model cards report for research studies using machine-learning based AI. Previously, we have developed an ontology model for model card reports to structure and formalize these reports. In this paper, we demonstrate a Java-based library (OWL API, FaCT++) that leverages our ontology to publish computable model card reports. We discuss future directions and other use cases that highlight applicability and feasibility of ontology-driven systems to support FAIR challenges.
LM-VC: Zero-shot Voice Conversion via Speech Generation based on Language Models
Jun 18, 2023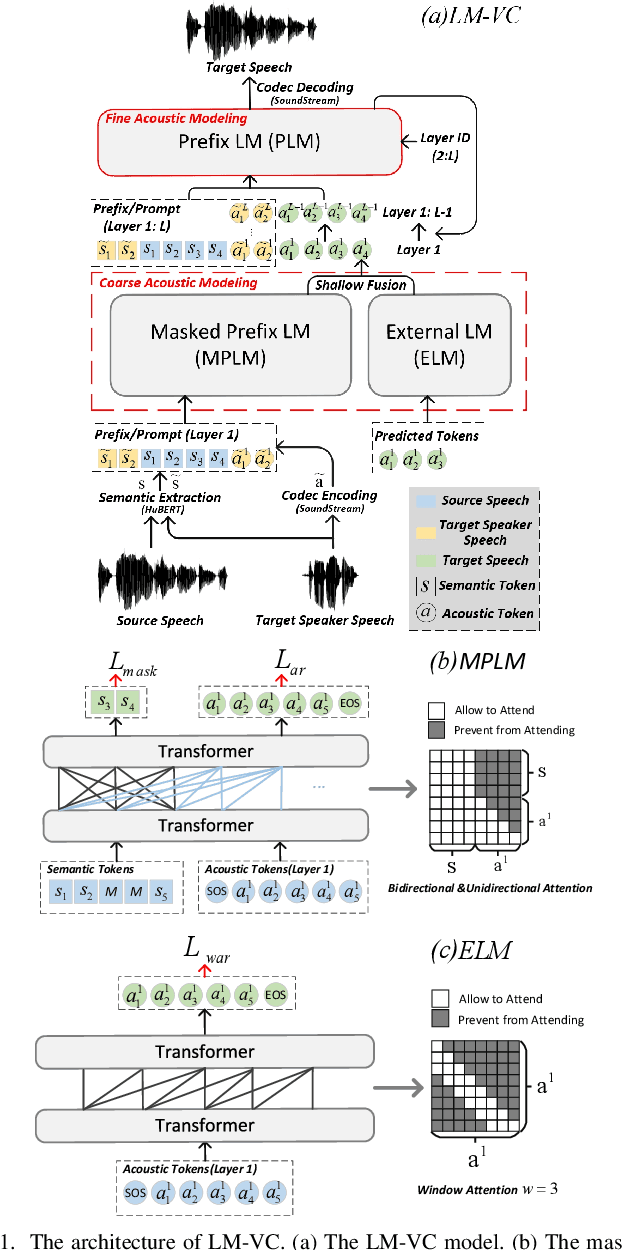
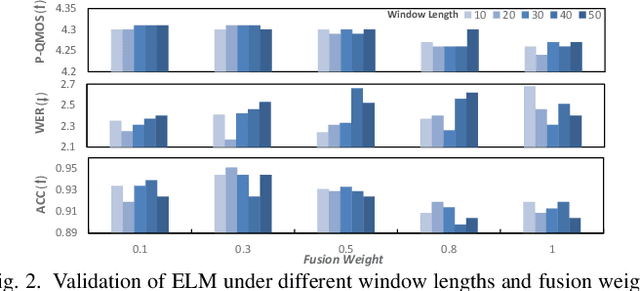
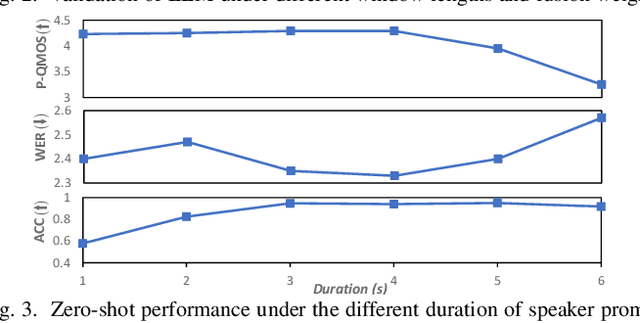
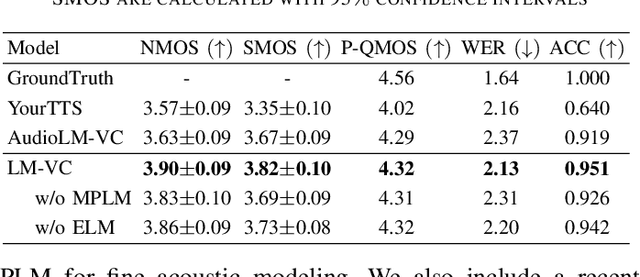
Language model (LM) based audio generation frameworks, e.g., AudioLM, have recently achieved new state-of-the-art performance in zero-shot audio generation. In this paper, we explore the feasibility of LMs for zero-shot voice conversion. An intuitive approach is to follow AudioLM - Tokenizing speech into semantic and acoustic tokens respectively by HuBERT and SoundStream, and converting source semantic tokens to target acoustic tokens conditioned on acoustic tokens of the target speaker. However, such an approach encounters several issues: 1) the linguistic content contained in semantic tokens may get dispersed during multi-layer modeling while the lengthy speech input in the voice conversion task makes contextual learning even harder; 2) the semantic tokens still contain speaker-related information, which may be leaked to the target speech, lowering the target speaker similarity; 3) the generation diversity in the sampling of the LM can lead to unexpected outcomes during inference, leading to unnatural pronunciation and speech quality degradation. To mitigate these problems, we propose LM-VC, a two-stage language modeling approach that generates coarse acoustic tokens for recovering the source linguistic content and target speaker's timbre, and then reconstructs the fine for acoustic details as converted speech. Specifically, to enhance content preservation and facilitates better disentanglement, a masked prefix LM with a mask prediction strategy is used for coarse acoustic modeling. This model is encouraged to recover the masked content from the surrounding context and generate target speech based on the target speaker's utterance and corrupted semantic tokens. Besides, to further alleviate the sampling error in the generation, an external LM, which employs window attention to capture the local acoustic relations, is introduced to participate in the coarse acoustic modeling.