 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Order Fairness: Mitigating LLMs Order Sensitivity through Dual Group Advantage Optimization
May 12, 2026Large Language Models (LLMs) suffer from order bias, where their performance is affected by the arrangement order of input elements. This unfairness limits the model's applications in scenarios such as in-context learning and Retrieval-Augmented Generation (RAG). Recent studies attempt to obtain optimal or suboptimal arrangements based on statistical results or using dataset-based search, but these methods increase inference overhead while leaving the model's inherent order bias unresolved. Other studies mitigate order sensitivity through supervised fine-tuning using augmented training sets with multiple order variants, but often at the cost of accuracy, trapping the model in consistent yet incorrect hallucinations. In this paper, we propose \textbf{D}ual \textbf{G}roup \textbf{A}dvantage \textbf{O}ptimization (\textbf{DGAO}), which aims to improve model accuracy and order stability simultaneously. DGAO calculates and balances intra-group relative accuracy advantage and inter-group relative stability advantage, rewarding the policy model for generating order-stable and correct outputs while penalizing order-sensitive or incorrect responses. This marks the first time reinforcement learning has been used to mitigate LLMs' order sensitivity. We also propose two new metrics, Consistency Rate and Overconfidence Rate, to reveal the pseudo-stability of previous methods and guide more comprehensive evaluation. Extensive experiments demonstrate that DGAO achieves superior order fairness while improving performance on RAG, mathematical reasoning, and classification tasks. Our code is available at: https://github.com/Hyalinesky/DGAO.
SGG-R$^{\rm 3}$: From Next-Token Prediction to End-to-End Unbiased Scene Graph Generation
Mar 12, 2026Scene Graph Generation (SGG) structures visual scenes as graphs of objects and their relations. While Multimodal Large Language Models (MLLMs) have advanced end-to-end SGG, current methods are hindered by both a lack of task-specific structured reasoning and the challenges of sparse, long-tailed relation distributions, resulting in incomplete scene graphs characterized by low recall and biased predictions. To address these issues, we introduce SGG-R$^{\rm 3}$, a structured reasoning framework that integrates task-specific chain-of-thought (CoT)-guided supervised fine-tuning (SFT) and reinforcement learning (RL) with group sequence policy optimization (GSPO), designed to engage in three sequential stages to achieve end-to-end unbiased scene graph generation. During the SFT phase, we propose a relation augmentation strategy by leveraging an MLLM and refined via embedding similarity filtering to alleviate relation sparsity. Subsequently, a stage-aligned reward scheme optimizes the procedural reasoning during RL. Specifically, we propose a novel dual-granularity reward which integrates fine-grained and coarse-grained relation rewards, simultaneously mitigating the long-tail issue via frequency-based adaptive weighting of predicates and improving relation coverage through semantic clustering. Experiments on two benchmarks show that SGG-R$^{\rm 3}$ achieves superior performance compared to existing methods, demonstrating the effectiveness and generalization of the framework.
GuiLoMo: Allocating Expert Number and Rank for LoRA-MoE via Bilevel Optimization with GuidedSelection Vectors
Jun 17, 2025Parameter-efficient fine-tuning (PEFT) methods, particularly Low-Rank Adaptation (LoRA), offer an efficient way to adapt large language models with reduced computational costs. However, their performance is limited by the small number of trainable parameters. Recent work combines LoRA with the Mixture-of-Experts (MoE), i.e., LoRA-MoE, to enhance capacity, but two limitations remain in hindering the full exploitation of its potential: 1) the influence of downstream tasks when assigning expert numbers, and 2) the uniform rank assignment across all LoRA experts, which restricts representational diversity. To mitigate these gaps, we propose GuiLoMo, a fine-grained layer-wise expert numbers and ranks allocation strategy with GuidedSelection Vectors (GSVs). GSVs are learned via a prior bilevel optimization process to capture both model- and task-specific needs, and are then used to allocate optimal expert numbers and ranks. Experiments on three backbone models across diverse benchmarks show that GuiLoMo consistently achieves superior or comparable performance to all baselines. Further analysis offers key insights into how expert numbers and ranks vary across layers and tasks, highlighting the benefits of adaptive expert configuration. Our code is available at https://github.com/Liar406/Gui-LoMo.git.
Qwen Look Again: Guiding Vision-Language Reasoning Models to Re-attention Visual Information
May 29, 2025



Inference time scaling drives extended reasoning to enhance the performance of Vision-Language Models (VLMs), thus forming powerful Vision-Language Reasoning Models (VLRMs). However, long reasoning dilutes visual tokens, causing visual information to receive less attention and may trigger hallucinations. Although introducing text-only reflection processes shows promise in language models, we demonstrate that it is insufficient to suppress hallucinations in VLMs. To address this issue, we introduce Qwen-LookAgain (Qwen-LA), a novel VLRM designed to mitigate hallucinations by incorporating a vision-text reflection process that guides the model to re-attention visual information during reasoning. We first propose a reinforcement learning method Balanced Reflective Policy Optimization (BRPO), which guides the model to decide when to generate vision-text reflection on its own and balance the number and length of reflections. Then, we formally prove that VLRMs lose attention to visual tokens as reasoning progresses, and demonstrate that supplementing visual information during reflection enhances visual attention. Therefore, during training and inference, Visual Token COPY and Visual Token ROUTE are introduced to force the model to re-attention visual information at the visual level, addressing the limitations of text-only reflection. Experiments on multiple visual QA datasets and hallucination metrics indicate that Qwen-LA achieves leading accuracy performance while reducing hallucinations. Our code is available at: https://github.com/Liar406/Look_Again.
GMM-Based Comprehensive Feature Extraction and Relative Distance Preservation For Few-Shot Cross-Modal Retrieval
May 19, 2025Few-shot cross-modal retrieval focuses on learning cross-modal representations with limited training samples, enabling the model to handle unseen classes during inference. Unlike traditional cross-modal retrieval tasks, which assume that both training and testing data share the same class distribution, few-shot retrieval involves data with sparse representations across modalities. Existing methods often fail to adequately model the multi-peak distribution of few-shot cross-modal data, resulting in two main biases in the latent semantic space: intra-modal bias, where sparse samples fail to capture intra-class diversity, and inter-modal bias, where misalignments between image and text distributions exacerbate the semantic gap. These biases hinder retrieval accuracy. To address these issues, we propose a novel method, GCRDP, for few-shot cross-modal retrieval. This approach effectively captures the complex multi-peak distribution of data using a Gaussian Mixture Model (GMM) and incorporates a multi-positive sample contrastive learning mechanism for comprehensive feature modeling. Additionally, we introduce a new strategy for cross-modal semantic alignment, which constrains the relative distances between image and text feature distributions, thereby improving the accuracy of cross-modal representations. We validate our approach through extensive experiments on four benchmark datasets, demonstrating superior performance over six state-of-the-art methods.
CLEAR-KGQA: Clarification-Enhanced Ambiguity Resolution for Knowledge Graph Question Answering
Apr 13, 2025This study addresses the challenge of ambiguity in knowledge graph question answering (KGQA). While recent KGQA systems have made significant progress, particularly with the integration of large language models (LLMs), they typically assume user queries are unambiguous, which is an assumption that rarely holds in real-world applications. To address these limitations, we propose a novel framework that dynamically handles both entity ambiguity (e.g., distinguishing between entities with similar names) and intent ambiguity (e.g., clarifying different interpretations of user queries) through interactive clarification. Our approach employs a Bayesian inference mechanism to quantify query ambiguity and guide LLMs in determining when and how to request clarification from users within a multi-turn dialogue framework. We further develop a two-agent interaction framework where an LLM-based user simulator enables iterative refinement of logical forms through simulated user feedback. Experimental results on the WebQSP and CWQ dataset demonstrate that our method significantly improves performance by effectively resolving semantic ambiguities. Additionally, we contribute a refined dataset of disambiguated queries, derived from interaction histories, to facilitate future research in this direction.
GraphBC: Improving LLMs for Better Graph Data Processing
Jan 24, 2025



The success of Large Language Models (LLMs) in various domains has led researchers to apply them to graph-related problems by converting graph data into natural language text. However, unlike graph data, natural language inherently has sequential order. We observe that when the order of nodes or edges in the natural language description of a graph is shuffled, despite describing the same graph, model performance fluctuates between high performance and random guessing. Additionally, due to the limited input context length of LLMs, current methods typically randomly sample neighbors of target nodes as representatives of their neighborhood, which may not always be effective for accurate reasoning. To address these gaps, we introduce GraphBC. This novel model framework features an Order Selector Module to ensure proper serialization order of the graph and a Subgraph Sampling Module to sample subgraphs with better structure for better reasoning. Furthermore, we propose Graph CoT obtained through distillation, and enhance LLM's reasoning and zero-shot learning capabilities for graph tasks through instruction tuning. Experiments on multiple datasets for node classification and graph question-answering demonstrate that GraphBC improves LLMs' performance and generalization ability on graph tasks.
Domaino1s: Guiding LLM Reasoning for Explainable Answers in High-Stakes Domains
Jan 24, 2025



Large Language Models (LLMs) are widely applied to downstream domains. However, current LLMs for high-stakes domain tasks, such as financial investment and legal QA, typically generate brief answers without reasoning processes and explanations. This limits users' confidence in making decisions based on their responses. While original CoT shows promise, it lacks self-correction mechanisms during reasoning. This work introduces Domain$o1$s, which enhances LLMs' reasoning capabilities on domain tasks through supervised fine-tuning and tree search. We construct CoT-stock-2k and CoT-legal-2k datasets for fine-tuning models that activate domain-specific reasoning steps based on their judgment. Additionally, we propose Selective Tree Exploration to spontaneously explore solution spaces and sample optimal reasoning paths to improve performance. We also introduce PROOF-Score, a new metric for evaluating domain models' explainability, complementing traditional accuracy metrics with richer assessment dimensions. Extensive experiments on stock investment recommendation and legal reasoning QA tasks demonstrate Domaino1s's leading performance and explainability. Our code is available at https://anonymous.4open.science/r/Domaino1s-006F/.
Mitigating Hallucinations on Object Attributes using Multiview Images and Negative Instructions
Jan 17, 2025
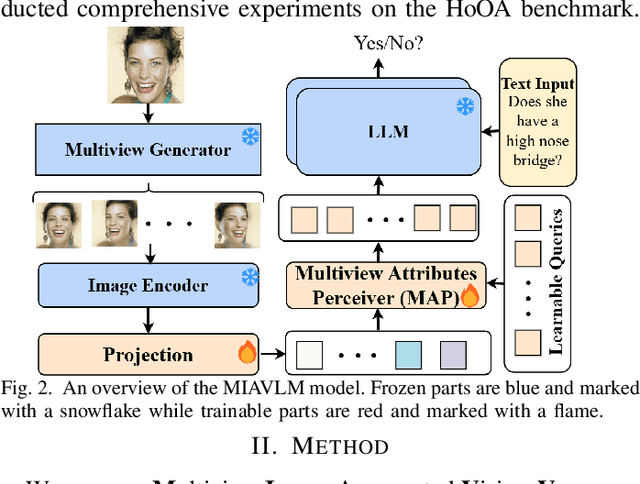


Current popular Large Vision-Language Models (LVLMs) are suffering from Hallucinations on Object Attributes (HoOA), leading to incorrect determination of fine-grained attributes in the input images. Leveraging significant advancements in 3D generation from a single image, this paper proposes a novel method to mitigate HoOA in LVLMs. This method utilizes multiview images sampled from generated 3D representations as visual prompts for LVLMs, thereby providing more visual information from other viewpoints. Furthermore, we observe the input order of multiple multiview images significantly affects the performance of LVLMs. Consequently, we have devised Multiview Image Augmented VLM (MIAVLM), incorporating a Multiview Attributes Perceiver (MAP) submodule capable of simultaneously eliminating the influence of input image order and aligning visual information from multiview images with Large Language Models (LLMs). Besides, we designed and employed negative instructions to mitigate LVLMs' bias towards ``Yes" responses. Comprehensive experiments demonstrate the effectiveness of our method.
Adaptive Spatiotemporal Augmentation for Improving Dynamic Graph Learning
Jan 17, 2025



Dynamic graph augmentation is used to improve the performance of dynamic GNNs. Most methods assume temporal locality, meaning that recent edges are more influential than earlier edges. However, for temporal changes in edges caused by random noise, overemphasizing recent edges while neglecting earlier ones may lead to the model capturing noise. To address this issue, we propose STAA (SpatioTemporal Activity-Aware Random Walk Diffusion). STAA identifies nodes likely to have noisy edges in spatiotemporal dimensions. Spatially, it analyzes critical topological positions through graph wavelet coefficients. Temporally, it analyzes edge evolution through graph wavelet coefficient change rates. Then, random walks are used to reduce the weights of noisy edges, deriving a diffusion matrix containing spatiotemporal information as an augmented adjacency matrix for dynamic GNN learning. Experiments on multiple datasets show that STAA outperforms other dynamic graph augmentation methods in node classification and link prediction tasks.