 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Memory-Constrained Algorithms for Convex Optimization via Recursive Cutting-Planes
Jun 16, 2023
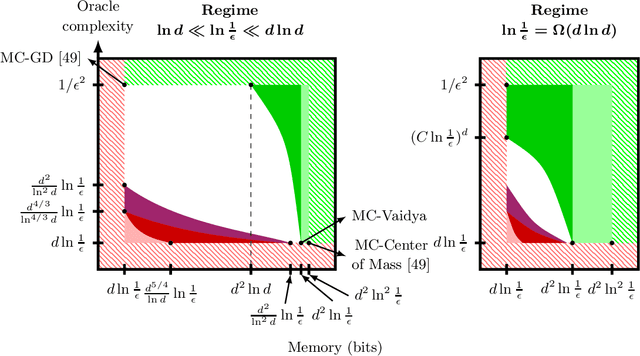
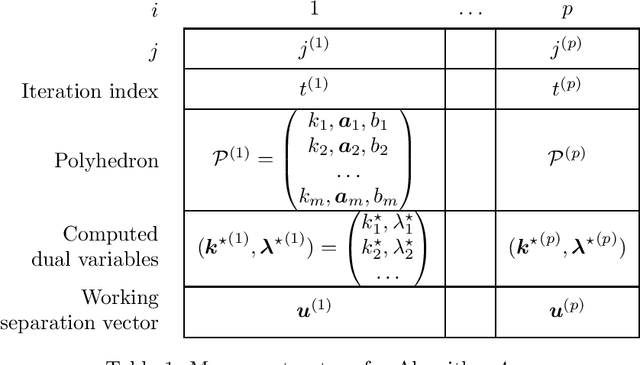
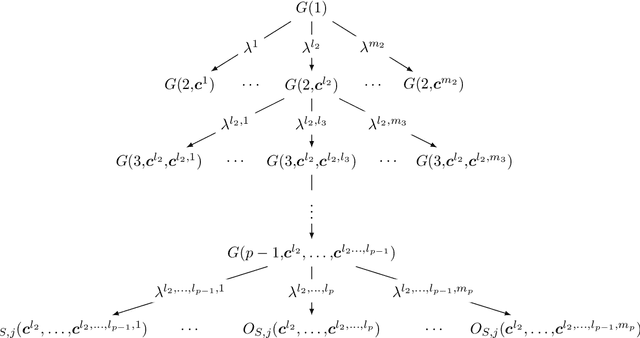

We propose a family of recursive cutting-plane algorithms to solve feasibility problems with constrained memory, which can also be used for first-order convex optimization. Precisely, in order to find a point within a ball of radius $\epsilon$ with a separation oracle in dimension $d$ -- or to minimize $1$-Lipschitz convex functions to accuracy $\epsilon$ over the unit ball -- our algorithms use $\mathcal O(\frac{d^2}{p}\ln \frac{1}{\epsilon})$ bits of memory, and make $\mathcal O((C\frac{d}{p}\ln \frac{1}{\epsilon})^p)$ oracle calls, for some universal constant $C \geq 1$. The family is parametrized by $p\in[d]$ and provides an oracle-complexity/memory trade-off in the sub-polynomial regime $\ln\frac{1}{\epsilon}\gg\ln d$. While several works gave lower-bound trade-offs (impossibility results) -- we explicit here their dependence with $\ln\frac{1}{\epsilon}$, showing that these also hold in any sub-polynomial regime -- to the best of our knowledge this is the first class of algorithms that provides a positive trade-off between gradient descent and cutting-plane methods in any regime with $\epsilon\leq 1/\sqrt d$. The algorithms divide the $d$ variables into $p$ blocks and optimize over blocks sequentially, with approximate separation vectors constructed using a variant of Vaidya's method. In the regime $\epsilon \leq d^{-\Omega(d)}$, our algorithm with $p=d$ achieves the information-theoretic optimal memory usage and improves the oracle-complexity of gradient descent.
Enabling BIM-Driven Robotic Construction Workflows with Closed-Loop Digital Twins
Jun 16, 2023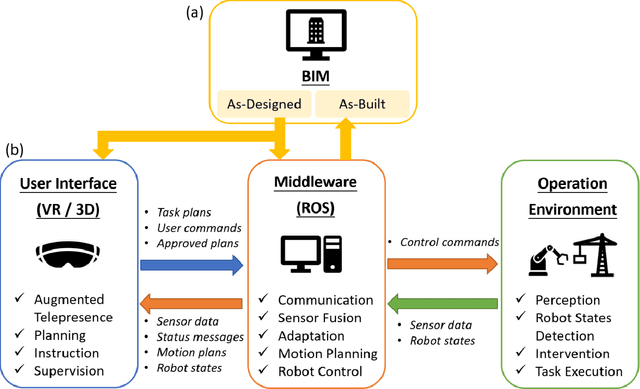
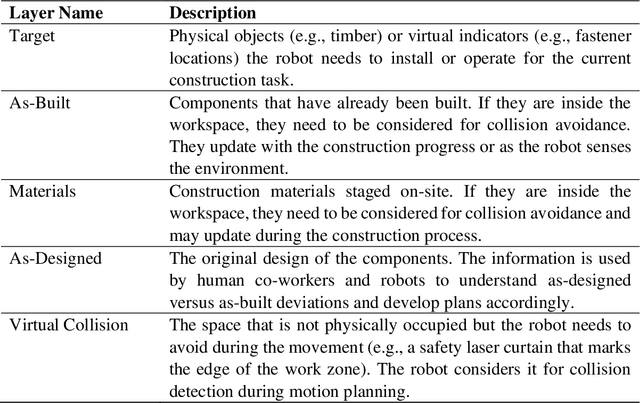
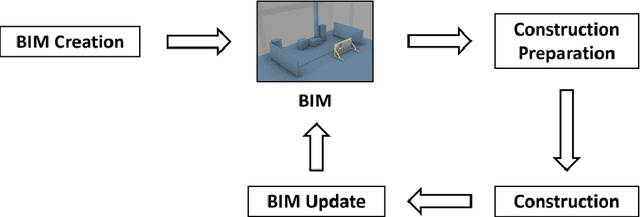

Robots can greatly alleviate physical demands on construction workers while enhancing both the productivity and safety of construction projects. Leveraging a Building Information Model (BIM) offers a natural and promising approach to drive a robotic construction workflow. However, because of uncertainties inherent on construction sites, such as discrepancies between the designed and as-built workpieces, robots cannot solely rely on the BIM to guide field construction work. Human workers are adept at improvising alternative plans with their creativity and experience and thus can assist robots in overcoming uncertainties and performing construction work successfully. This research introduces an interactive closed-loop digital twin system that integrates a BIM into human-robot collaborative construction workflows. The robot is primarily driven by the BIM, but it adaptively adjusts its plan based on actual site conditions while the human co-worker supervises the process. If necessary, the human co-worker intervenes in the robot's plan by changing the task sequence or target position, requesting a new motion plan, or modifying the construction component(s)/material(s) to help the robot navigate uncertainties. To investigate the physical deployment of the system, a drywall installation case study is conducted with an industrial robotic arm in a laboratory. In addition, a block pick-and-place experiment is carried out to evaluate system performance. Integrating the flexibility of human workers and the autonomy and accuracy afforded by the BIM, the system significantly increases the robustness of construction robots in the performance of field construction work.
PEACE: Cross-Platform Hate Speech Detection- A Causality-guided Framework
Jun 15, 2023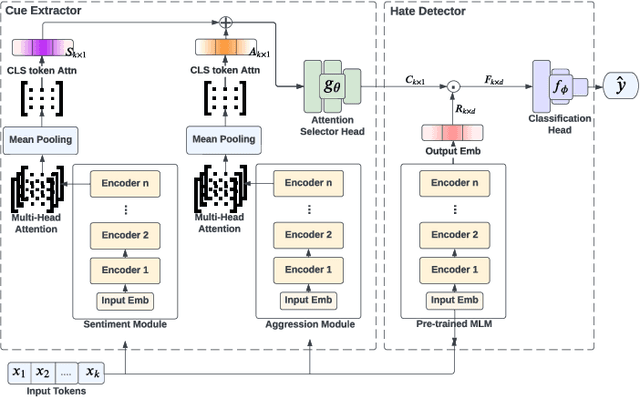
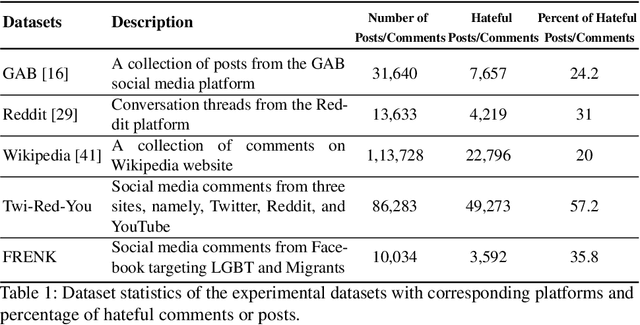
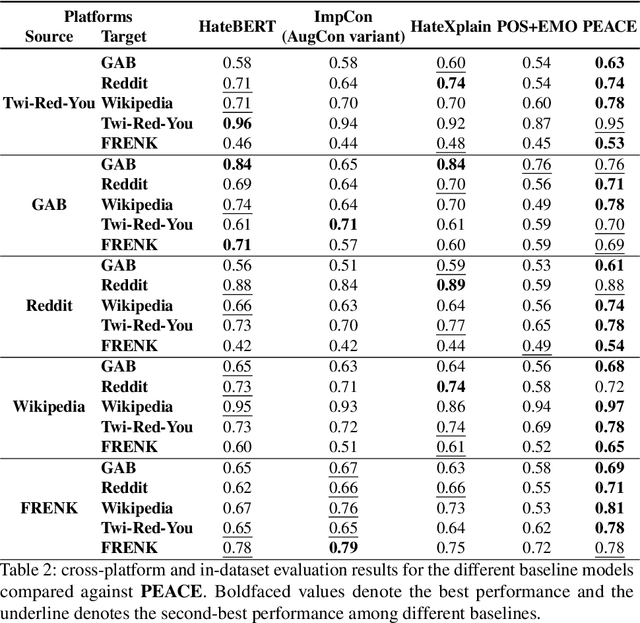
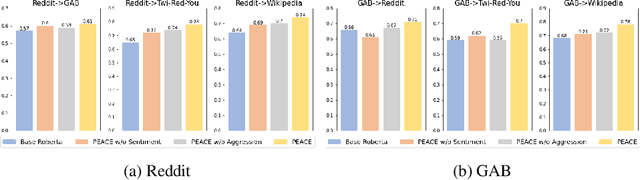
Hate speech detection refers to the task of detecting hateful content that aims at denigrating an individual or a group based on their religion, gender, sexual orientation, or other characteristics. Due to the different policies of the platforms, different groups of people express hate in different ways. Furthermore, due to the lack of labeled data in some platforms it becomes challenging to build hate speech detection models. To this end, we revisit if we can learn a generalizable hate speech detection model for the cross platform setting, where we train the model on the data from one (source) platform and generalize the model across multiple (target) platforms. Existing generalization models rely on linguistic cues or auxiliary information, making them biased towards certain tags or certain kinds of words (e.g., abusive words) on the source platform and thus not applicable to the target platforms. Inspired by social and psychological theories, we endeavor to explore if there exist inherent causal cues that can be leveraged to learn generalizable representations for detecting hate speech across these distribution shifts. To this end, we propose a causality-guided framework, PEACE, that identifies and leverages two intrinsic causal cues omnipresent in hateful content: the overall sentiment and the aggression in the text. We conduct extensive experiments across multiple platforms (representing the distribution shift) showing if causal cues can help cross-platform generalization.
Interleaving Pre-Trained Language Models and Large Language Models for Zero-Shot NL2SQL Generation
Jun 15, 2023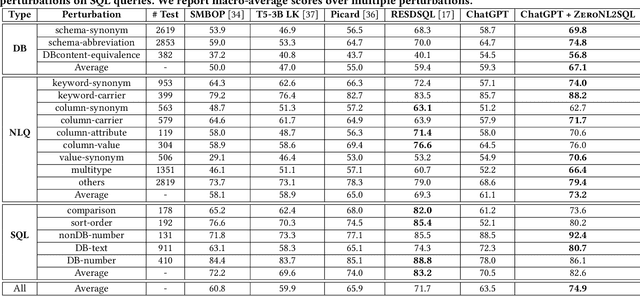
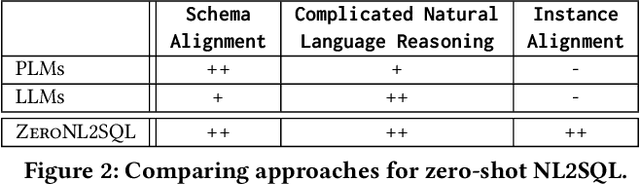

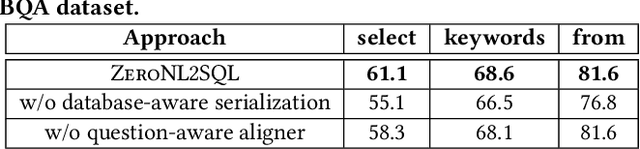
Zero-shot NL2SQL is crucial in achieving natural language to SQL that is adaptive to new environments (e.g., new databases, new linguistic phenomena or SQL structures) with zero annotated NL2SQL samples from such environments. Existing approaches either fine-tune pre-trained language models (PLMs) based on annotated data or use prompts to guide fixed large language models (LLMs) such as ChatGPT. PLMs can perform well in schema alignment but struggle to achieve complex reasoning, while LLMs is superior in complex reasoning tasks but cannot achieve precise schema alignment. In this paper, we propose a ZeroNL2SQL framework that combines the complementary advantages of PLMs and LLMs for supporting zero-shot NL2SQL. ZeroNL2SQL first uses PLMs to generate an SQL sketch via schema alignment, then uses LLMs to fill the missing information via complex reasoning. Moreover, in order to better align the generated SQL queries with values in the given database instances, we design a predicate calibration method to guide the LLM in completing the SQL sketches based on the database instances and select the optimal SQL query via an execution-based strategy. Comprehensive experiments show that ZeroNL2SQL can achieve the best zero-shot NL2SQL performance on real-world benchmarks. Specifically, ZeroNL2SQL outperforms the state-of-the-art PLM-based methods by 3.2% to 13% and exceeds LLM-based methods by 10% to 20% on execution accuracy.
Predictive Maneuver Planning with Deep Reinforcement Learning (PMP-DRL) for comfortable and safe autonomous driving
Jun 15, 2023
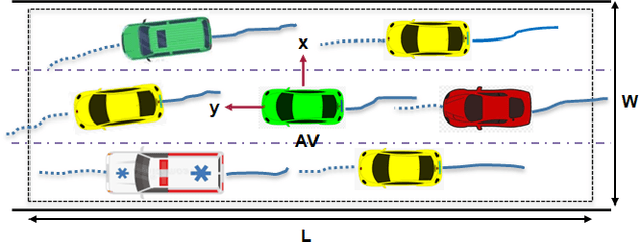
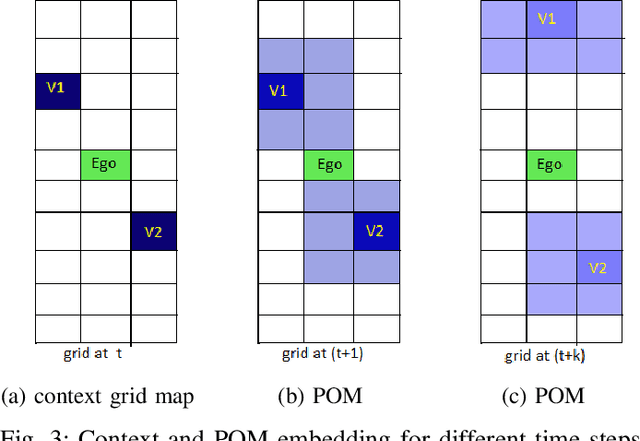
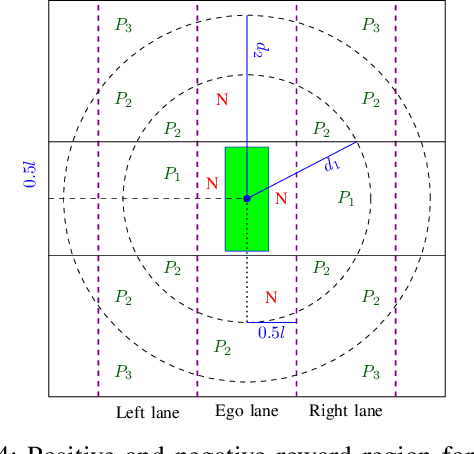
This paper presents a Predictive Maneuver Planning with Deep Reinforcement Learning (PMP-DRL) model for maneuver planning. Traditional rule-based maneuver planning approaches often have to improve their abilities to handle the variabilities of real-world driving scenarios. By learning from its experience, a Reinforcement Learning (RL)-based driving agent can adapt to changing driving conditions and improve its performance over time. Our proposed approach combines a predictive model and an RL agent to plan for comfortable and safe maneuvers. The predictive model is trained using historical driving data to predict the future positions of other surrounding vehicles. The surrounding vehicles' past and predicted future positions are embedded in context-aware grid maps. At the same time, the RL agent learns to make maneuvers based on this spatio-temporal context information. Performance evaluation of PMP-DRL has been carried out using simulated environments generated from publicly available NGSIM US101 and I80 datasets. The training sequence shows the continuous improvement in the driving experiences. It shows that proposed PMP-DRL can learn the trade-off between safety and comfortability. The decisions generated by the recent imitation learning-based model are compared with the proposed PMP-DRL for unseen scenarios. The results clearly show that PMP-DRL can handle complex real-world scenarios and make better comfortable and safe maneuver decisions than rule-based and imitative models.
A Multi-Level, Multi-Scale Visual Analytics Approach to Assessment of Multifidelity HPC Systems
Jun 15, 2023
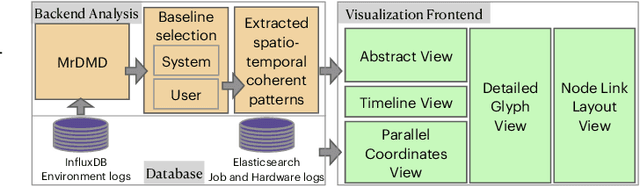
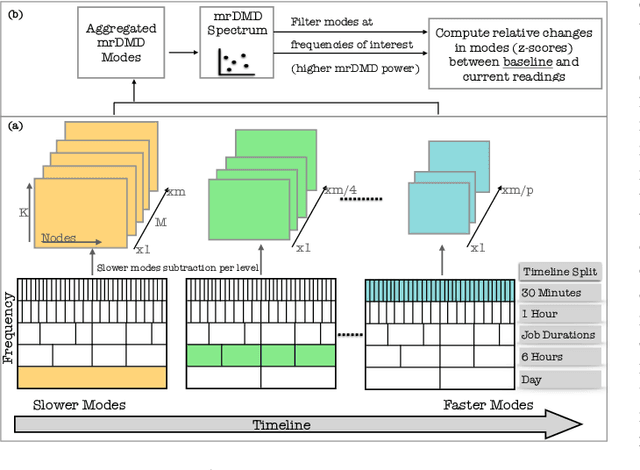
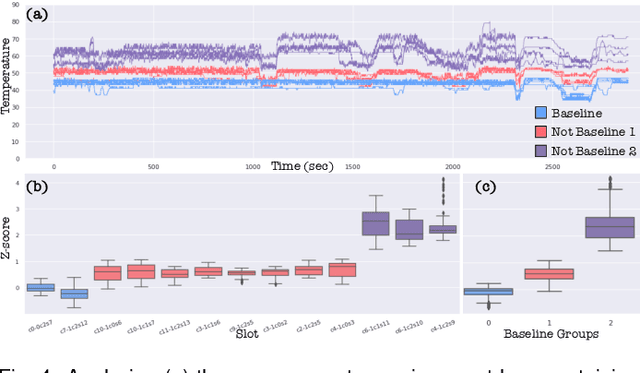
The ability to monitor and interpret of hardware system events and behaviors are crucial to improving the robustness and reliability of these systems, especially in a supercomputing facility. The growing complexity and scale of these systems demand an increase in monitoring data collected at multiple fidelity levels and varying temporal resolutions. In this work, we aim to build a holistic analytical system that helps make sense of such massive data, mainly the hardware logs, job logs, and environment logs collected from disparate subsystems and components of a supercomputer system. This end-to-end log analysis system, coupled with visual analytics support, allows users to glean and promptly extract supercomputer usage and error patterns at varying temporal and spatial resolutions. We use multiresolution dynamic mode decomposition (mrDMD), a technique that depicts high-dimensional data as correlated spatial-temporal variations patterns or modes, to extract variation patterns isolated at specified frequencies. Our improvements to the mrDMD algorithm help promptly reveal useful information in the massive environment log dataset, which is then associated with the processed hardware and job log datasets using our visual analytics system. Furthermore, our system can identify the usage and error patterns filtered at user, project, and subcomponent levels. We exemplify the effectiveness of our approach with two use scenarios with the Cray XC40 supercomputer.
ForkNet: Simultaneous Time and Time-Frequency Domain Modeling for Speech Enhancement
May 15, 2023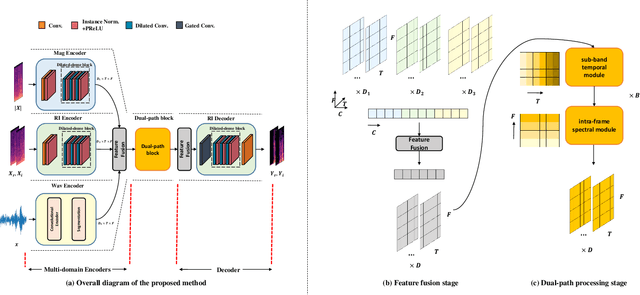

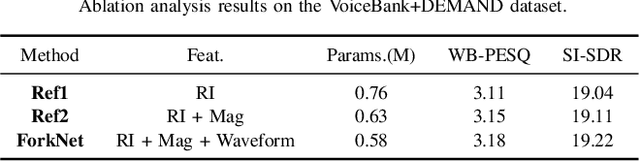
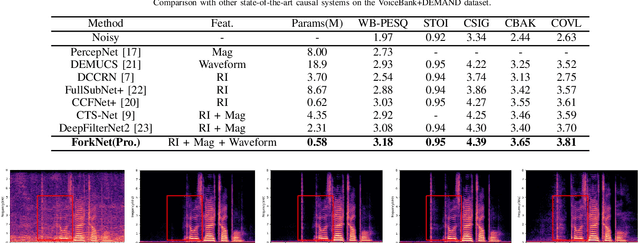
Previous research in speech enhancement has mostly focused on modeling time or time-frequency domain information alone, with little consideration given to the potential benefits of simultaneously modeling both domains. Since these domains contain complementary information, combining them may improve the performance of the model. In this letter, we propose a new approach to simultaneously model time and time-frequency domain information in a single model. We begin with the DPT-FSNet (causal version) model as a baseline and modify the encoder structure by replacing the original encoder with three separate encoders, each dedicated to modeling time-domain, real-imaginary, and magnitude information, respectively. Additionally, we introduce a feature fusion module both before and after the dual-path processing blocks to better leverage information from the different domains. The outcomes of our experiments reveal that the proposed approach achieves superior performance compared to existing state-of-the-art causal models, while preserving a relatively compact model size and low computational complexity.
Disentangled Variational Autoencoder for Emotion Recognition in Conversations
May 23, 2023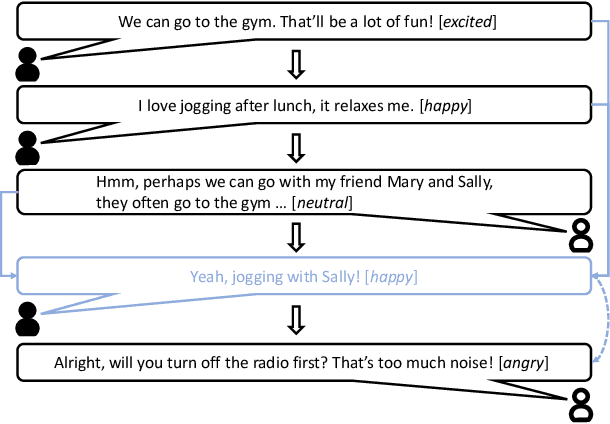

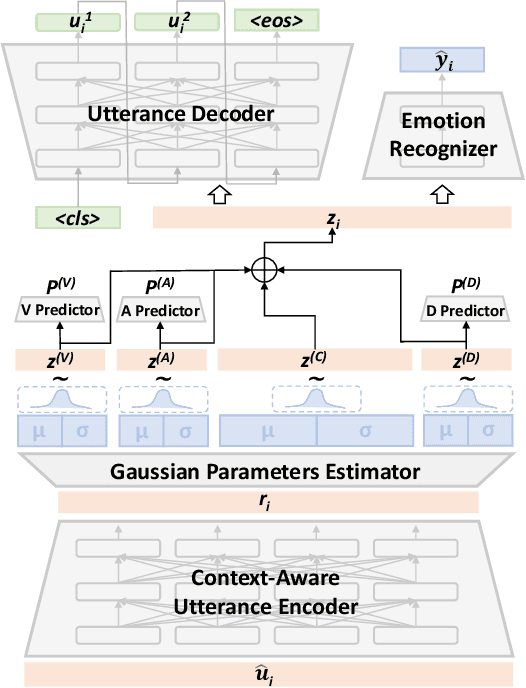
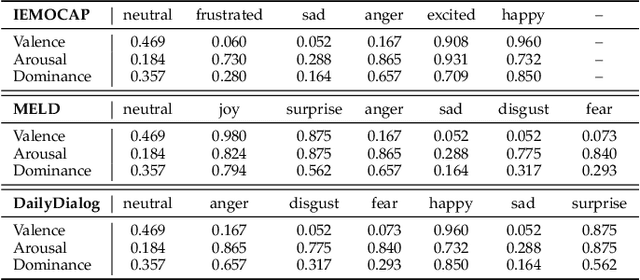
In Emotion Recognition in Conversations (ERC), the emotions of target utterances are closely dependent on their context. Therefore, existing works train the model to generate the response of the target utterance, which aims to recognise emotions leveraging contextual information. However, adjacent response generation ignores long-range dependencies and provides limited affective information in many cases. In addition, most ERC models learn a unified distributed representation for each utterance, which lacks interpretability and robustness. To address these issues, we propose a VAD-disentangled Variational AutoEncoder (VAD-VAE), which first introduces a target utterance reconstruction task based on Variational Autoencoder, then disentangles three affect representations Valence-Arousal-Dominance (VAD) from the latent space. We also enhance the disentangled representations by introducing VAD supervision signals from a sentiment lexicon and minimising the mutual information between VAD distributions. Experiments show that VAD-VAE outperforms the state-of-the-art model on two datasets. Further analysis proves the effectiveness of each proposed module and the quality of disentangled VAD representations. The code is available at https://github.com/SteveKGYang/VAD-VAE.
RaSP: Relation-aware Semantic Prior for Weakly Supervised Incremental Segmentation
May 31, 2023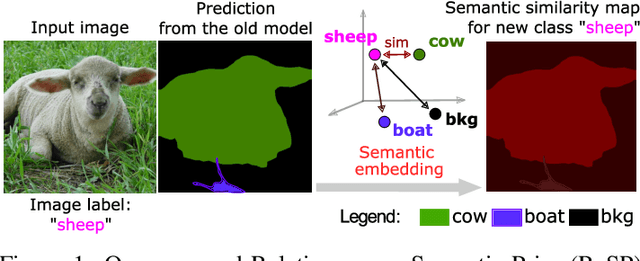
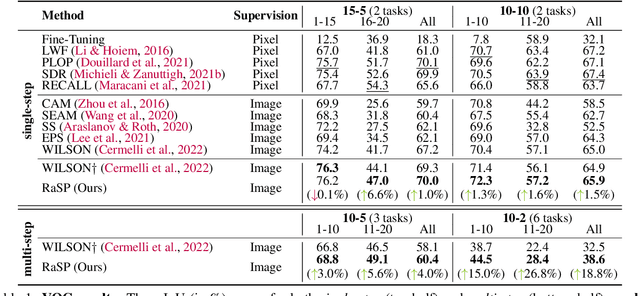
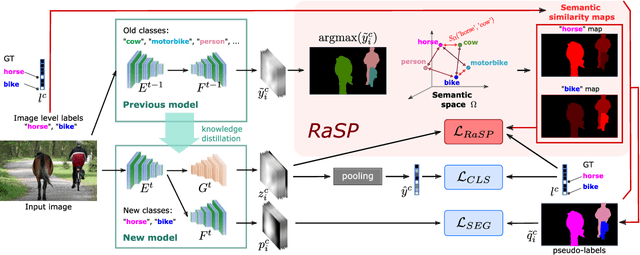
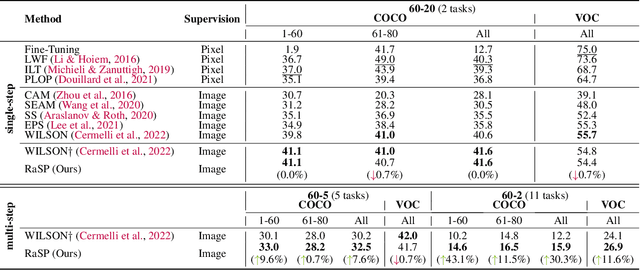
Class-incremental semantic image segmentation assumes multiple model updates, each enriching the model to segment new categories. This is typically carried out by providing expensive pixel-level annotations to the training algorithm for all new objects, limiting the adoption of such methods in practical applications. Approaches that solely require image-level labels offer an attractive alternative, yet, such coarse annotations lack precise information about the location and boundary of the new objects. In this paper we argue that, since classes represent not just indices but semantic entities, the conceptual relationships between them can provide valuable information that should be leveraged. We propose a weakly supervised approach that exploits such semantic relations to transfer objectness prior from the previously learned classes into the new ones, complementing the supervisory signal from image-level labels. We validate our approach on a number of continual learning tasks, and show how even a simple pairwise interaction between classes can significantly improve the segmentation mask quality of both old and new classes. We show these conclusions still hold for longer and, hence, more realistic sequences of tasks and for a challenging few-shot scenario.
Learning the Right Layers: a Data-Driven Layer-Aggregation Strategy for Semi-Supervised Learning on Multilayer Graphs
May 31, 2023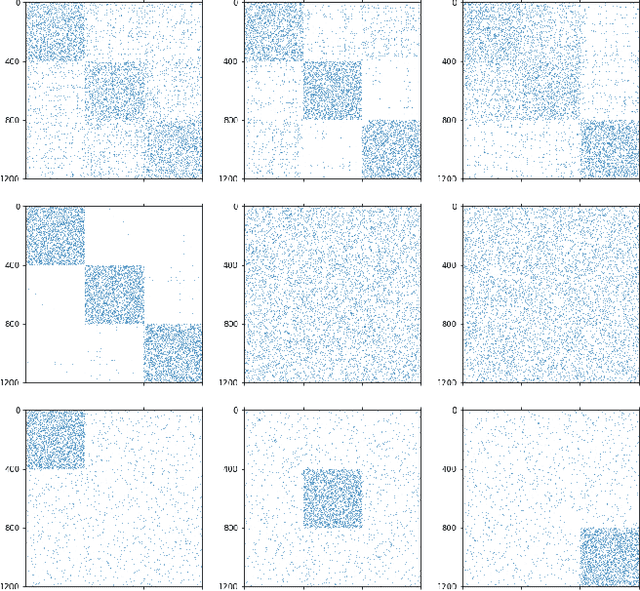
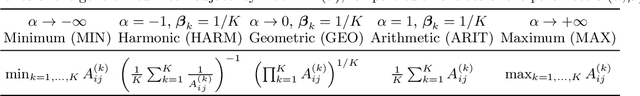
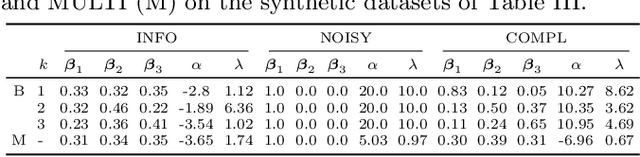
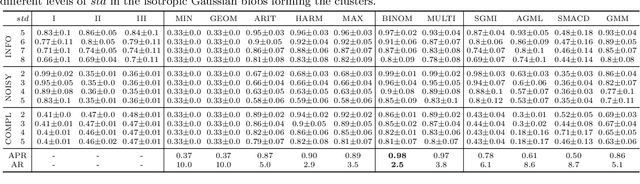
Clustering (or community detection) on multilayer graphs poses several additional complications with respect to standard graphs as different layers may be characterized by different structures and types of information. One of the major challenges is to establish the extent to which each layer contributes to the cluster assignment in order to effectively take advantage of the multilayer structure and improve upon the classification obtained using the individual layers or their union. However, making an informed a-priori assessment about the clustering information content of the layers can be very complicated. In this work, we assume a semi-supervised learning setting, where the class of a small percentage of nodes is initially provided, and we propose a parameter-free Laplacian-regularized model that learns an optimal nonlinear combination of the different layers from the available input labels. The learning algorithm is based on a Frank-Wolfe optimization scheme with inexact gradient, combined with a modified Label Propagation iteration. We provide a detailed convergence analysis of the algorithm and extensive experiments on synthetic and real-world datasets, showing that the proposed method compares favourably with a variety of baselines and outperforms each individual layer when used in isolation.