 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoliDubber: Holistic Video Dubbing for Complex Acoustic Scenes via Text-Guided Audio Synthesis
Jun 08, 2026Video dubbing is a cornerstone of multimedia content creation, aiming to synthesize synchronized acoustic sequences for visual streams. While Text-to-Speech (TTS) and Text-to-Audio (TTA) generation have each achieved remarkable progress, existing dubbing systems remain confined to isolated speech synthesis without incorporating sound effects and ambient audio, forcing practitioners to rely on fragmented workflows and laborious manual post-mixing. To address this limitation, we present HoliDubber, a holistic video dubbing framework that moves beyond speech-only generation by enabling the joint synthesis of speech and sound effects from a single text prompt. Specifically, HoliDubber adopts a patch-based autoregressive diffusion transformer architecture, where a causal language model autoregressively models aggregated patch embeddings to capture global temporal structure, and a Diffusion Transformer decoder generates high-fidelity continuous tokens within each patch, following a divide-and-conquer strategy. To achieve cross-modal alignment, visual features are encoded into patch-level representations and fused with audio patches via cross-attention, enabling the model to ground speech generation in the speaker's visual articulation dynamics. In addition, we introduce HoliDub-Bench, a benchmark curated from established datasets with synchronized video-text-audio triplets designed for holistic dubbing evaluation. Extensive experiments demonstrate that HoliDubber significantly outperforms existing methods across multiple benchmarks in speech quality, synchronization, and speaker similarity. Furthermore, results on HoliDub-Bench validate the effectiveness of joint speech-and-sound generation, establishing a new paradigm for holistic video dubbing in complex acoustic scenes. \footnote{The demo page of the project is https://holidubber.github.io}
JoyVoice: Long-Context Conditioning for Anthropomorphic Multi-Speaker Conversational Synthesis
Dec 22, 2025Large speech generation models are evolving from single-speaker, short sentence synthesis to multi-speaker, long conversation geneartion. Current long-form speech generation models are predominately constrained to dyadic, turn-based interactions. To address this, we introduce JoyVoice, a novel anthropomorphic foundation model designed for flexible, boundary-free synthesis of up to eight speakers. Unlike conventional cascaded systems, JoyVoice employs a unified E2E-Transformer-DiT architecture that utilizes autoregressive hidden representations directly for diffusion inputs, enabling holistic end-to-end optimization. We further propose a MM-Tokenizer operating at a low bitrate of 12.5 Hz, which integrates multitask semantic and MMSE losses to effectively model both semantic and acoustic information. Additionally, the model incorporates robust text front-end processing via large-scale data perturbation. Experiments show that JoyVoice achieves state-of-the-art results in multilingual generation (Chinese, English, Japanese, Korean) and zero-shot voice cloning. JoyVoice achieves top-tier results on both the Seed-TTS-Eval Benchmark and multi-speaker long-form conversational voice cloning tasks, demonstrating superior audio quality and generalization. It achieves significant improvements in prosodic continuity for long-form speech, rhythm richness in multi-speaker conversations, paralinguistic naturalness, besides superior intelligibility. We encourage readers to listen to the demo at https://jea-speech.github.io/JoyVoice
ForkNet: Simultaneous Time and Time-Frequency Domain Modeling for Speech Enhancement
May 15, 2023Previous research in speech enhancement has mostly focused on modeling time or time-frequency domain information alone, with little consideration given to the potential benefits of simultaneously modeling both domains. Since these domains contain complementary information, combining them may improve the performance of the model. In this letter, we propose a new approach to simultaneously model time and time-frequency domain information in a single model. We begin with the DPT-FSNet (causal version) model as a baseline and modify the encoder structure by replacing the original encoder with three separate encoders, each dedicated to modeling time-domain, real-imaginary, and magnitude information, respectively. Additionally, we introduce a feature fusion module both before and after the dual-path processing blocks to better leverage information from the different domains. The outcomes of our experiments reveal that the proposed approach achieves superior performance compared to existing state-of-the-art causal models, while preserving a relatively compact model size and low computational complexity.
THLNet: two-stage heterogeneous lightweight network for monaural speech enhancement
Jan 19, 2023



In this paper, we propose a two-stage heterogeneous lightweight network for monaural speech enhancement. Specifically, we design a novel two-stage framework consisting of a coarse-grained full-band mask estimation stage and a fine-grained low-frequency refinement stage. Instead of using a hand-designed real-valued filter, we use a novel learnable complex-valued rectangular bandwidth (LCRB) filter bank as an extractor of compact features. Furthermore, considering the respective characteristics of the proposed two-stage task, we used a heterogeneous structure, i.e., a U-shaped subnetwork as the backbone of CoarseNet and a single-scale subnetwork as the backbone of FineNet. We conducted experiments on the VoiceBank + DEMAND and DNS datasets to evaluate the proposed approach. The experimental results show that the proposed method outperforms the current state-of-the-art methods, while maintaining relatively small model size and low computational complexity.
DPT-FSNet:Dual-path Transformer Based Full-band and Sub-band Fusion Network for Speech Enhancement
Apr 27, 2021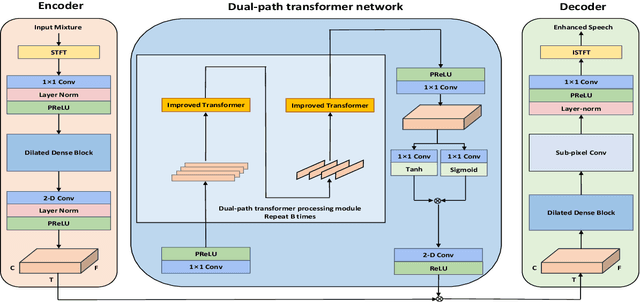
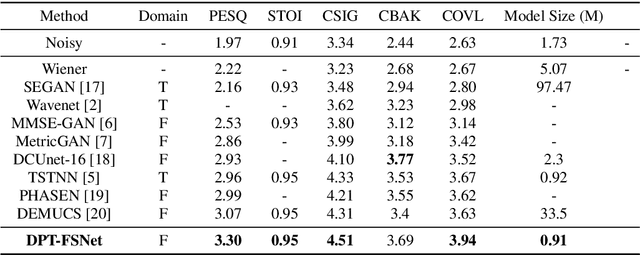

Recently, dual-path networks have achieved promising performance due to their ability to model local and global features of the input sequence. However, previous studies are based on simple time-domain features and do not fully investigate the impact of the input features of the dual-path network on the enhancement performance. In this paper, we propose a dual-path transformer-based full-band and sub-band fusion network (DPT-FSNet) for speech enhancement in the frequency domain. The intra and inter parts of the dual-path transformer network in our model can be seen as sub-band and full-band modeling respectively, which have stronger interpretability as well as more information compared to the features utilized by the time-domain transformer. We conducted experiments on the Voice Bank + DEMAND dataset to evaluate the proposed method. Experimental results show that the proposed method outperforms the current state-of-the-arts in terms of PESQ, STOI, CSIG, COVL. (The PESQ, STOI, CSIG, and COVL scores on the Voice Bank + DEMAND dataset were 3.30, 0.95, 4.51, and 3.94, respectively).