 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SACHA: Soft Actor-Critic with Heuristic-Based Attention for Partially Observable Multi-Agent Path Finding
Jul 05, 2023
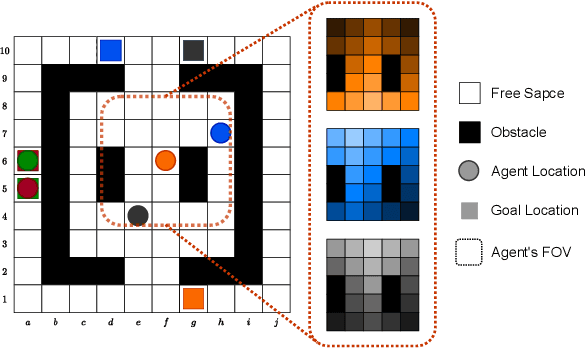
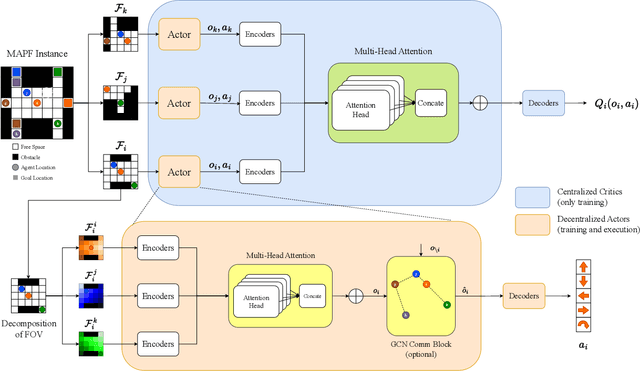
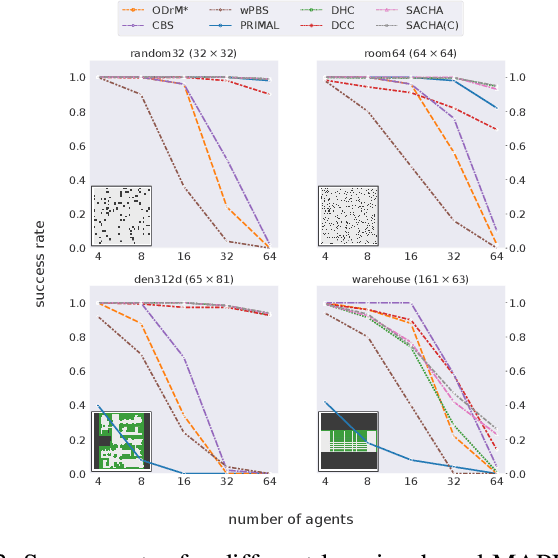

Multi-Agent Path Finding (MAPF) is a crucial component for many large-scale robotic systems, where agents must plan their collision-free paths to their given goal positions. Recently, multi-agent reinforcement learning has been introduced to solve the partially observable variant of MAPF by learning a decentralized single-agent policy in a centralized fashion based on each agent's partial observation. However, existing learning-based methods are ineffective in achieving complex multi-agent cooperation, especially in congested environments, due to the non-stationarity of this setting. To tackle this challenge, we propose a multi-agent actor-critic method called Soft Actor-Critic with Heuristic-Based Attention (SACHA), which employs novel heuristic-based attention mechanisms for both the actors and critics to encourage cooperation among agents. SACHA learns a neural network for each agent to selectively pay attention to the shortest path heuristic guidance from multiple agents within its field of view, thereby allowing for more scalable learning of cooperation. SACHA also extends the existing multi-agent actor-critic framework by introducing a novel critic centered on each agent to approximate $Q$-values. Compared to existing methods that use a fully observable critic, our agent-centered multi-agent actor-critic method results in more impartial credit assignment and better generalizability of the learned policy to MAPF instances with varying numbers of agents and types of environments. We also implement SACHA(C), which embeds a communication module in the agent's policy network to enable information exchange among agents. We evaluate both SACHA and SACHA(C) on a variety of MAPF instances and demonstrate decent improvements over several state-of-the-art learning-based MAPF methods with respect to success rate and solution quality.
ReMask: A Robust Information-Masking Approach for Domain Counterfactual Generation
May 04, 2023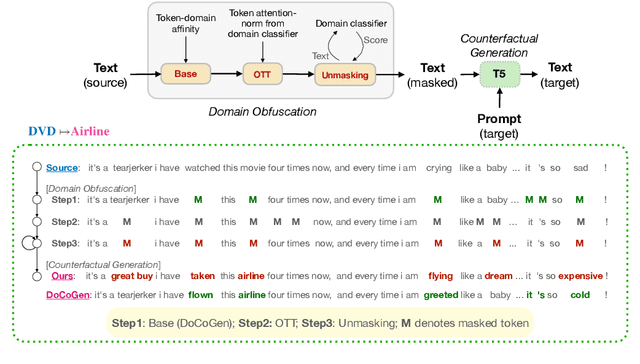


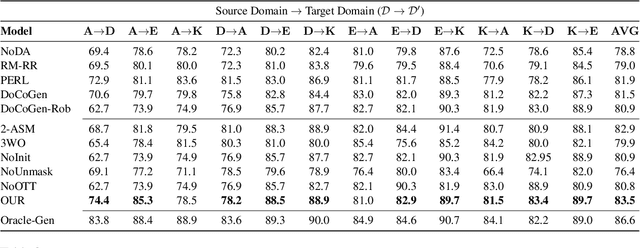
Domain shift is a big challenge in NLP, thus, many approaches resort to learning domain-invariant features to mitigate the inference phase domain shift. Such methods, however, fail to leverage the domain-specific nuances relevant to the task at hand. To avoid such drawbacks, domain counterfactual generation aims to transform a text from the source domain to a given target domain. However, due to the limited availability of data, such frequency-based methods often miss and lead to some valid and spurious domain-token associations. Hence, we employ a three-step domain obfuscation approach that involves frequency and attention norm-based masking, to mask domain-specific cues, and unmasking to regain the domain generic context. Our experiments empirically show that the counterfactual samples sourced from our masked text lead to improved domain transfer on 10 out of 12 domain sentiment classification settings, with an average of 2% accuracy improvement over the state-of-the-art for unsupervised domain adaptation (UDA). Further, our model outperforms the state-of-the-art by achieving 1.4% average accuracy improvement in the adversarial domain adaptation (ADA) setting. Moreover, our model also shows its domain adaptation efficacy on a large multi-domain intent classification dataset where it attains state-of-the-art results. We release the codes publicly at \url{https://github.com/declare-lab/remask}.
FormNetV2: Multimodal Graph Contrastive Learning for Form Document Information Extraction
May 04, 2023
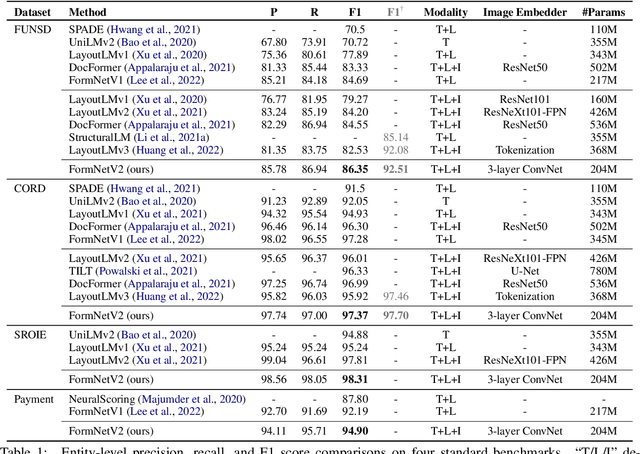
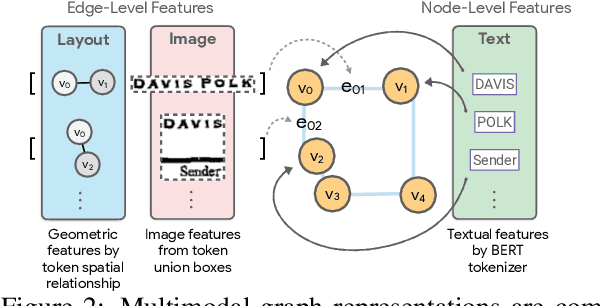
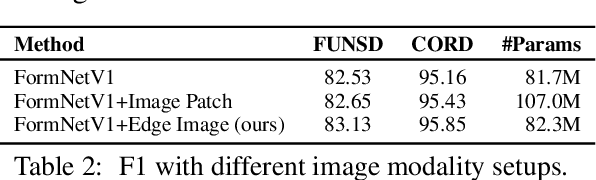
The recent advent of self-supervised pre-training techniques has led to a surge in the use of multimodal learning in form document understanding. However, existing approaches that extend the mask language modeling to other modalities require careful multi-task tuning, complex reconstruction target designs, or additional pre-training data. In FormNetV2, we introduce a centralized multimodal graph contrastive learning strategy to unify self-supervised pre-training for all modalities in one loss. The graph contrastive objective maximizes the agreement of multimodal representations, providing a natural interplay for all modalities without special customization. In addition, we extract image features within the bounding box that joins a pair of tokens connected by a graph edge, capturing more targeted visual cues without loading a sophisticated and separately pre-trained image embedder. FormNetV2 establishes new state-of-the-art performance on FUNSD, CORD, SROIE and Payment benchmarks with a more compact model size.
Instructed Diffuser with Temporal Condition Guidance for Offline Reinforcement Learning
Jun 08, 2023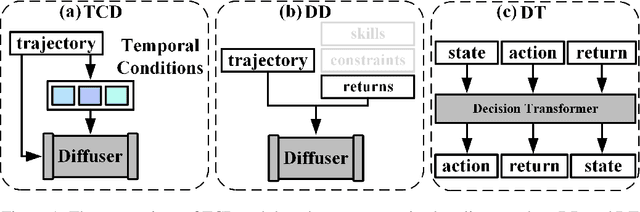
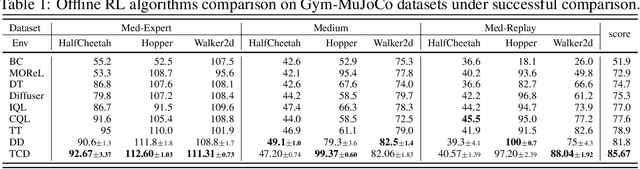
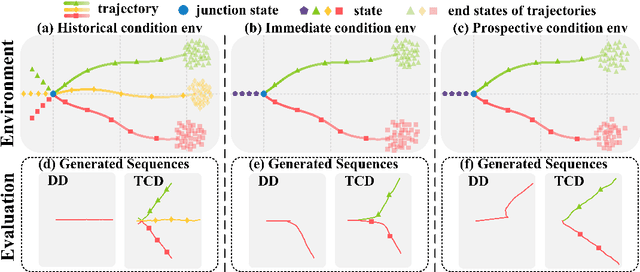
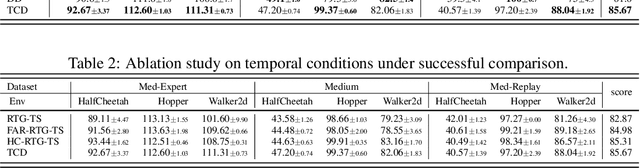
Recent works have shown the potential of diffusion models in computer vision and natural language processing. Apart from the classical supervised learning fields, diffusion models have also shown strong competitiveness in reinforcement learning (RL) by formulating decision-making as sequential generation. However, incorporating temporal information of sequential data and utilizing it to guide diffusion models to perform better generation is still an open challenge. In this paper, we take one step forward to investigate controllable generation with temporal conditions that are refined from temporal information. We observe the importance of temporal conditions in sequential generation in sufficient explorative scenarios and provide a comprehensive discussion and comparison of different temporal conditions. Based on the observations, we propose an effective temporally-conditional diffusion model coined Temporally-Composable Diffuser (TCD), which extracts temporal information from interaction sequences and explicitly guides generation with temporal conditions. Specifically, we separate the sequences into three parts according to time expansion and identify historical, immediate, and prospective conditions accordingly. Each condition preserves non-overlapping temporal information of sequences, enabling more controllable generation when we jointly use them to guide the diffuser. Finally, we conduct extensive experiments and analysis to reveal the favorable applicability of TCD in offline RL tasks, where our method reaches or matches the best performance compared with prior SOTA baselines.
DreamSparse: Escaping from Plato's Cave with 2D Frozen Diffusion Model Given Sparse Views
Jun 14, 2023
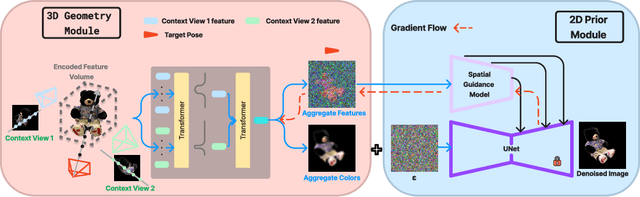


Synthesizing novel view images from a few views is a challenging but practical problem. Existing methods often struggle with producing high-quality results or necessitate per-object optimization in such few-view settings due to the insufficient information provided. In this work, we explore leveraging the strong 2D priors in pre-trained diffusion models for synthesizing novel view images. 2D diffusion models, nevertheless, lack 3D awareness, leading to distorted image synthesis and compromising the identity. To address these problems, we propose DreamSparse, a framework that enables the frozen pre-trained diffusion model to generate geometry and identity-consistent novel view image. Specifically, DreamSparse incorporates a geometry module designed to capture 3D features from sparse views as a 3D prior. Subsequently, a spatial guidance model is introduced to convert these 3D feature maps into spatial information for the generative process. This information is then used to guide the pre-trained diffusion model, enabling it to generate geometrically consistent images without tuning it. Leveraging the strong image priors in the pre-trained diffusion models, DreamSparse is capable of synthesizing high-quality novel views for both object and scene-level images and generalising to open-set images. Experimental results demonstrate that our framework can effectively synthesize novel view images from sparse views and outperforms baselines in both trained and open-set category images. More results can be found on our project page: https://sites.google.com/view/dreamsparse-webpage.
Utilizing Longitudinal Chest X-Rays and Reports to Pre-Fill Radiology Reports
Jun 14, 2023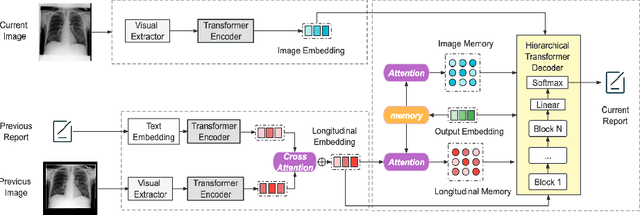

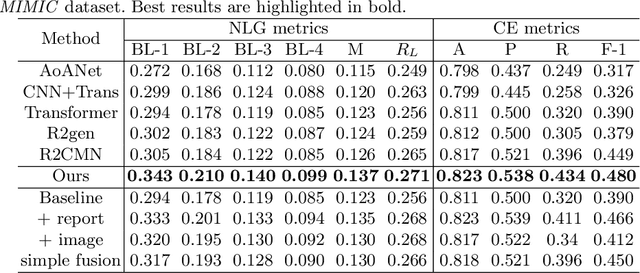

Despite the reduction in turn-around times in radiology reports with the use of speech recognition software, persistent communication errors can significantly impact the interpretation of the radiology report. Pre-filling a radiology report holds promise in mitigating reporting errors, and despite efforts in the literature to generate medical reports, there exists a lack of approaches that exploit the longitudinal nature of patient visit records in the MIMIC-CXR dataset. To address this gap, we propose to use longitudinal multi-modal data, i.e., previous patient visit CXR, current visit CXR, and previous visit report, to pre-fill the 'findings' section of a current patient visit report. We first gathered the longitudinal visit information for 26,625 patients from the MIMIC-CXR dataset and created a new dataset called Longitudinal-MIMIC. With this new dataset, a transformer-based model was trained to capture the information from longitudinal patient visit records containing multi-modal data (CXR images + reports) via a cross-attention-based multi-modal fusion module and a hierarchical memory-driven decoder. In contrast to previous work that only uses current visit data as input to train a model, our work exploits the longitudinal information available to pre-fill the 'findings' section of radiology reports. Experiments show that our approach outperforms several recent approaches by >=3% on F1 score, and >=2% for BLEU-4, METEOR and ROUGE-L respectively. The dataset and code will be made publicly available.
See Through the Fog: Curriculum Learning with Progressive Occlusion in Medical Imaging
Jun 27, 2023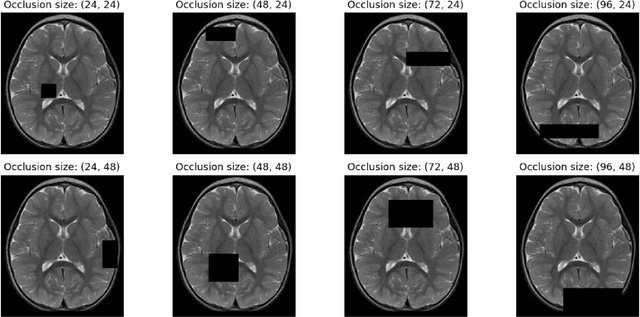
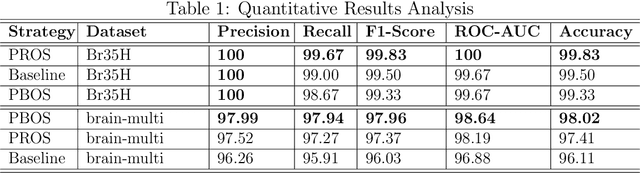
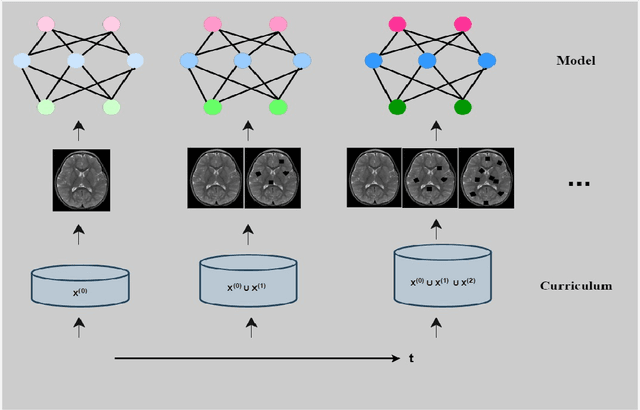
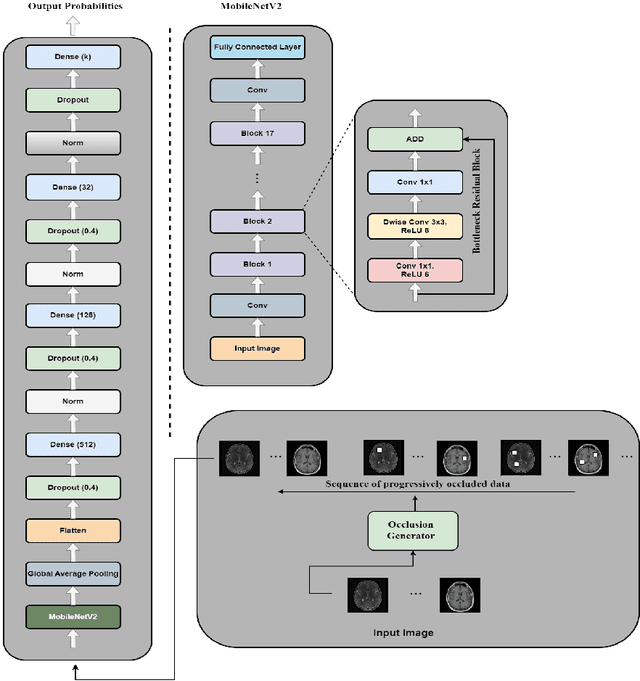
In recent years, deep learning models have revolutionized medical image interpretation, offering substantial improvements in diagnostic accuracy. However, these models often struggle with challenging images where critical features are partially or fully occluded, which is a common scenario in clinical practice. In this paper, we propose a novel curriculum learning-based approach to train deep learning models to handle occluded medical images effectively. Our method progressively introduces occlusion, starting from clear, unobstructed images and gradually moving to images with increasing occlusion levels. This ordered learning process, akin to human learning, allows the model to first grasp simple, discernable patterns and subsequently build upon this knowledge to understand more complicated, occluded scenarios. Furthermore, we present three novel occlusion synthesis methods, namely Wasserstein Curriculum Learning (WCL), Information Adaptive Learning (IAL), and Geodesic Curriculum Learning (GCL). Our extensive experiments on diverse medical image datasets demonstrate substantial improvements in model robustness and diagnostic accuracy over conventional training methodologies.
Stochastic Gradient Bayesian Optimal Experimental Designs for Simulation-based Inference
Jun 27, 2023Simulation-based inference (SBI) methods tackle complex scientific models with challenging inverse problems. However, SBI models often face a significant hurdle due to their non-differentiable nature, which hampers the use of gradient-based optimization techniques. Bayesian Optimal Experimental Design (BOED) is a powerful approach that aims to make the most efficient use of experimental resources for improved inferences. While stochastic gradient BOED methods have shown promising results in high-dimensional design problems, they have mostly neglected the integration of BOED with SBI due to the difficult non-differentiable property of many SBI simulators. In this work, we establish a crucial connection between ratio-based SBI inference algorithms and stochastic gradient-based variational inference by leveraging mutual information bounds. This connection allows us to extend BOED to SBI applications, enabling the simultaneous optimization of experimental designs and amortized inference functions. We demonstrate our approach on a simple linear model and offer implementation details for practitioners.
Causal Inference via Predictive Coding
Jun 27, 2023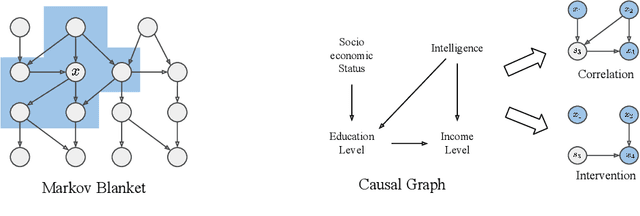
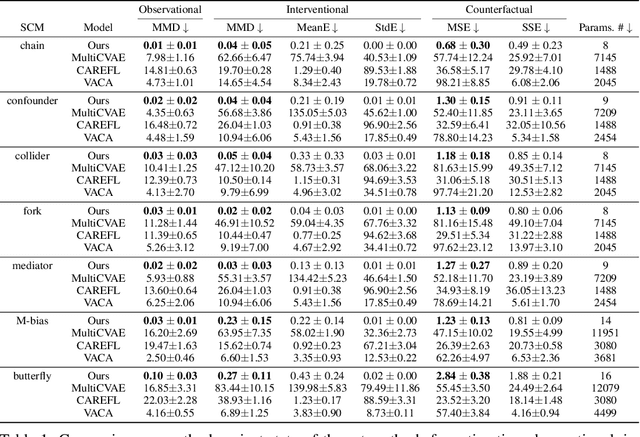
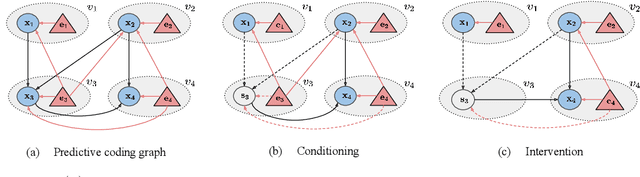
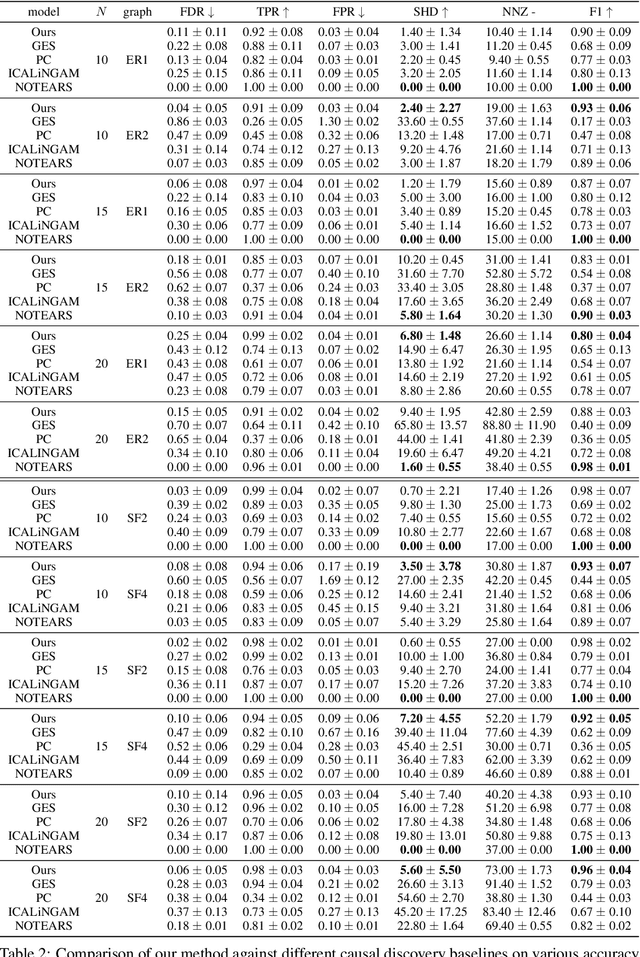
Bayesian and causal inference are fundamental processes for intelligence. Bayesian inference models observations: what can be inferred about y if we observe a related variable x? Causal inference models interventions: if we directly change x, how will y change? Predictive coding is a neuroscience-inspired method for performing Bayesian inference on continuous state variables using local information only. In this work, we go beyond Bayesian inference, and show how a simple change in the inference process of predictive coding enables interventional and counterfactual inference in scenarios where the causal graph is known. We then extend our results, and show how predictive coding can be generalized to cases where this graph is unknown, and has to be inferred from data, hence performing causal discovery. What results is a novel and straightforward technique that allows us to perform end-to-end causal inference on predictive-coding-based structural causal models, and demonstrate its utility for potential applications in machine learning.
Local primordial non-Gaussianity from the large-scale clustering of photometric DESI luminous red galaxies
Jul 04, 2023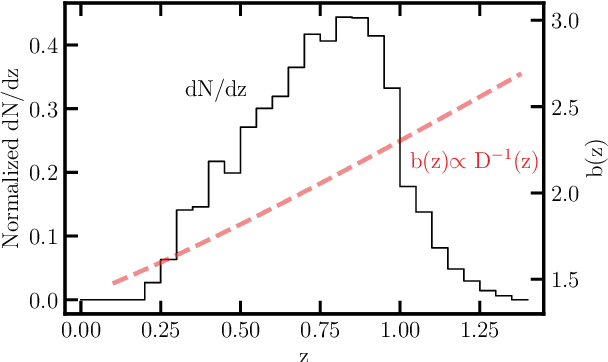
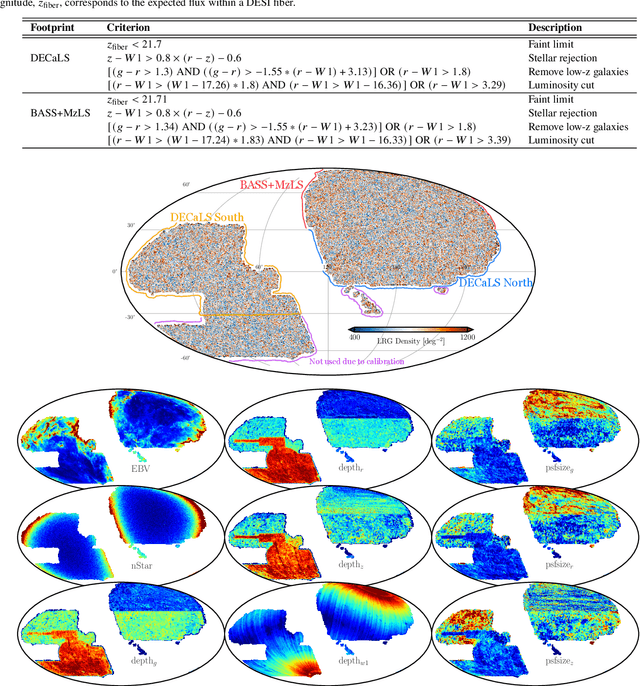
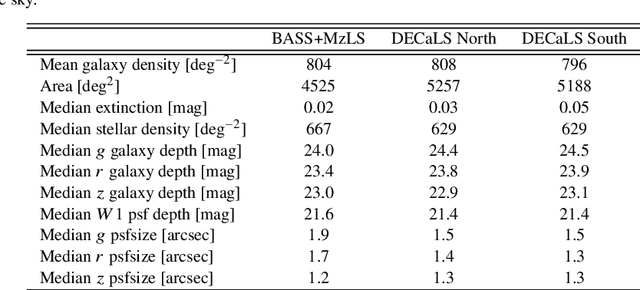

We use angular clustering of luminous red galaxies from the Dark Energy Spectroscopic Instrument (DESI) imaging surveys to constrain the local primordial non-Gaussianity parameter fNL. Our sample comprises over 12 million targets, covering 14,000 square degrees of the sky, with redshifts in the range 0.2< z < 1.35. We identify Galactic extinction, survey depth, and astronomical seeing as the primary sources of systematic error, and employ linear regression and artificial neural networks to alleviate non-cosmological excess clustering on large scales. Our methods are tested against log-normal simulations with and without fNL and systematics, showing superior performance of the neural network treatment in reducing remaining systematics. Assuming the universality relation, we find fNL $= 47^{+14(+29)}_{-11(-22)}$ at 68\%(95\%) confidence. With a more aggressive treatment, including regression against the full set of imaging maps, our maximum likelihood value shifts slightly to fNL$ \sim 50$ and the uncertainty on fNL increases due to the removal of large-scale clustering information. We apply a series of robustness tests (e.g., cuts on imaging, declination, or scales used) that show consistency in the obtained constraints. Despite extensive efforts to mitigate systematics, our measurements indicate fNL > 0 with a 99.9 percent confidence level. This outcome raises concerns as it could be attributed to unforeseen systematics, including calibration errors or uncertainties associated with low-\ell systematics in the extinction template. Alternatively, it could suggest a scale-dependent fNL model--causing significant non-Gaussianity around large-scale structure while leaving cosmic microwave background scales unaffected. Our results encourage further studies of fNL with DESI spectroscopic samples, where the inclusion of 3D clustering modes should help separate imaging systematics.