 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MultiZoo & MultiBench: A Standardized Toolkit for Multimodal Deep Learning
Jun 28, 2023


Learning multimodal representations involves integrating information from multiple heterogeneous sources of data. In order to accelerate progress towards understudied modalities and tasks while ensuring real-world robustness, we release MultiZoo, a public toolkit consisting of standardized implementations of > 20 core multimodal algorithms and MultiBench, a large-scale benchmark spanning 15 datasets, 10 modalities, 20 prediction tasks, and 6 research areas. Together, these provide an automated end-to-end machine learning pipeline that simplifies and standardizes data loading, experimental setup, and model evaluation. To enable holistic evaluation, we offer a comprehensive methodology to assess (1) generalization, (2) time and space complexity, and (3) modality robustness. MultiBench paves the way towards a better understanding of the capabilities and limitations of multimodal models, while ensuring ease of use, accessibility, and reproducibility. Our toolkits are publicly available, will be regularly updated, and welcome inputs from the community.
Feature Selection: A perspective on inter-attribute cooperation
Jun 28, 2023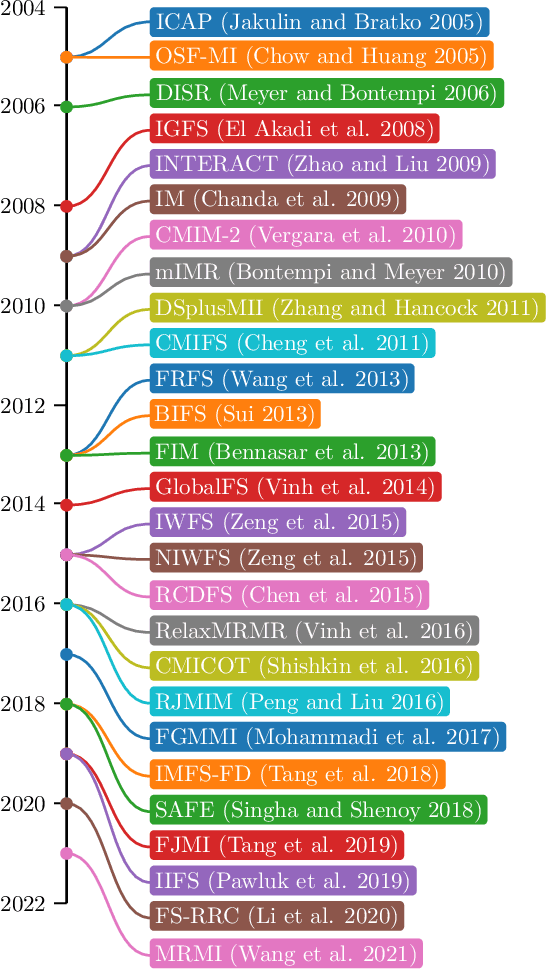

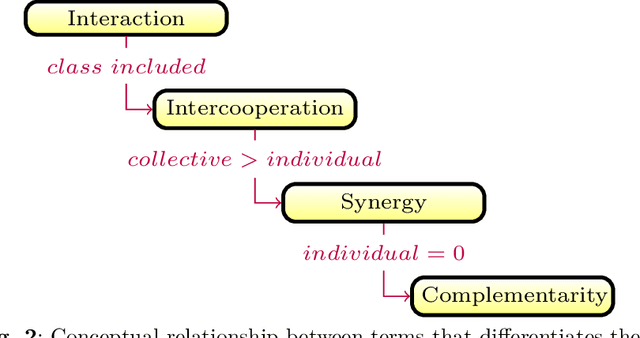
High-dimensional datasets depict a challenge for learning tasks in data mining and machine learning. Feature selection is an effective technique in dealing with dimensionality reduction. It is often an essential data processing step prior to applying a learning algorithm. Over the decades, filter feature selection methods have evolved from simple univariate relevance ranking algorithms to more sophisticated relevance-redundancy trade-offs and to multivariate dependencies-based approaches in recent years. This tendency to capture multivariate dependence aims at obtaining unique information about the class from the intercooperation among features. This paper presents a comprehensive survey of the state-of-the-art work on filter feature selection methods assisted by feature intercooperation, and summarizes the contributions of different approaches found in the literature. Furthermore, current issues and challenges are introduced to identify promising future research and development.
Sentence-to-Label Generation Framework for Multi-task Learning of Japanese Sentence Classification and Named Entity Recognition
Jun 28, 2023Information extraction(IE) is a crucial subfield within natural language processing. In this study, we introduce a Sentence Classification and Named Entity Recognition Multi-task (SCNM) approach that combines Sentence Classification (SC) and Named Entity Recognition (NER). We develop a Sentence-to-Label Generation (SLG) framework for SCNM and construct a Wikipedia dataset containing both SC and NER. Using a format converter, we unify input formats and employ a generative model to generate SC-labels, NER-labels, and associated text segments. We propose a Constraint Mechanism (CM) to improve generated format accuracy. Our results show SC accuracy increased by 1.13 points and NER by 1.06 points in SCNM compared to standalone tasks, with CM raising format accuracy from 63.61 to 100. The findings indicate mutual reinforcement effects between SC and NER, and integration enhances both tasks' performance.
Geometric Ultrasound Localization Microscopy
Jun 28, 2023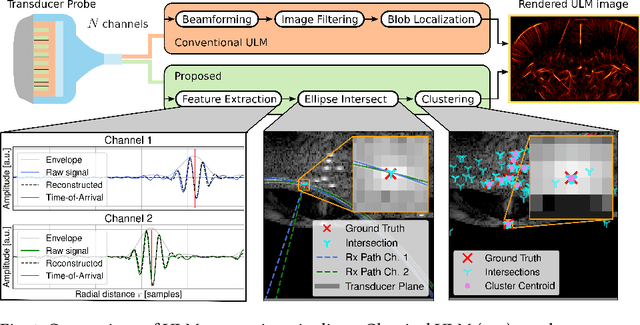
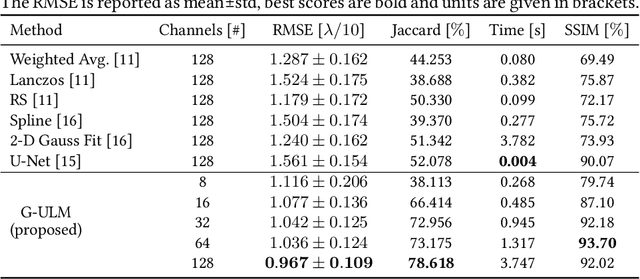
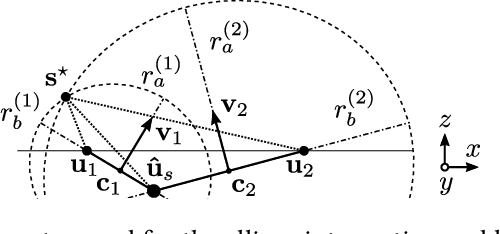
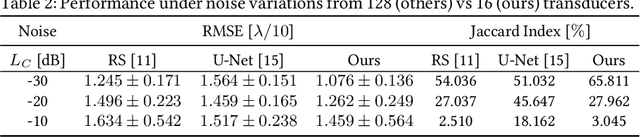
Contrast-Enhanced Ultra-Sound (CEUS) has become a viable method for non-invasive, dynamic visualization in medical diagnostics, yet Ultrasound Localization Microscopy (ULM) has enabled a revolutionary breakthrough by offering ten times higher resolution. To date, Delay-And-Sum (DAS) beamformers are used to render ULM frames, ultimately determining the image resolution capability. To take full advantage of ULM, this study questions whether beamforming is the most effective processing step for ULM, suggesting an alternative approach that relies solely on Time-Difference-of-Arrival (TDoA) information. To this end, a novel geometric framework for micro bubble localization via ellipse intersections is proposed to overcome existing beamforming limitations. We present a benchmark comparison based on a public dataset for which our geometric ULM outperforms existing baseline methods in terms of accuracy and reliability while only utilizing a portion of the available transducer data.
Decentralized Aerial Transportation and Manipulation of a Cable-Slung Payload With Swarm of Agents
Jun 21, 2023With the advent of Unmanned Aerial Vehicles (UAV) and Micro Aerial Vehicles (MAV) in commercial sectors, their application for transporting and manipulating payloads has attracted many research work. A swarm of agents, cooperatively working to transport and manipulate a payload can overcome the physical limitations of a single agent, adding redundancy and tolerance against failures. In this paper, the dynamics of a swarm connected to a payload via flexible cables are modeled, and a decentralized control is designed using Artificial Potential Field (APF). The swarm is able to transport the payload through an unknown environment to a goal position while avoiding obstacles from the local information received from the onboard sensors. The key contributions are (a) the cables are modelled more accurately using lumped mass model instead of geometric constraints, (b) a decentralized swarm control is designed using potential field approach to ensure hover stability of system without payload state information, (c) the manipulation of payload elevation and azimuth angles are controlled by APF, and (d) the trajectory of the payload for transportation is governed by potential fields generated by goal point and obstacles. The efficacy of the method proposed in this work are evaluated through numerical simulations under the influence of external disturbances and failure of agents.
Spiking Neural Network for Ultra-low-latency and High-accurate Object Detection
Jun 21, 2023
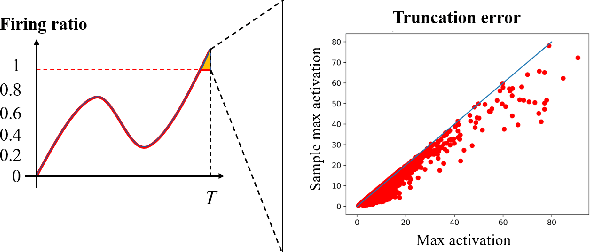
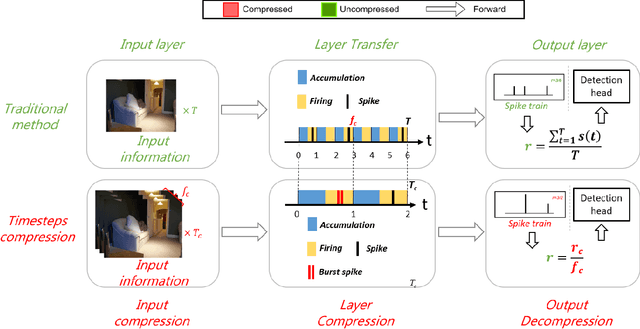
Spiking Neural Networks (SNNs) have garnered widespread interest for their energy efficiency and brain-inspired event-driven properties. While recent methods like Spiking-YOLO have expanded the SNNs to more challenging object detection tasks, they often suffer from high latency and low detection accuracy, making them difficult to deploy on latency sensitive mobile platforms. Furthermore, the conversion method from Artificial Neural Networks (ANNs) to SNNs is hard to maintain the complete structure of the ANNs, resulting in poor feature representation and high conversion errors. To address these challenges, we propose two methods: timesteps compression and spike-time-dependent integrated (STDI) coding. The former reduces the timesteps required in ANN-SNN conversion by compressing information, while the latter sets a time-varying threshold to expand the information holding capacity. We also present a SNN-based ultra-low latency and high accurate object detection model (SUHD) that achieves state-of-the-art performance on nontrivial datasets like PASCAL VOC and MS COCO, with about remarkable 750x fewer timesteps and 30% mean average precision (mAP) improvement, compared to the Spiking-YOLO on MS COCO datasets. To the best of our knowledge, SUHD is the deepest spike-based object detection model to date that achieves ultra low timesteps to complete the lossless conversion.
RXFOOD: Plug-in RGB-X Fusion for Object of Interest Detection
Jun 22, 2023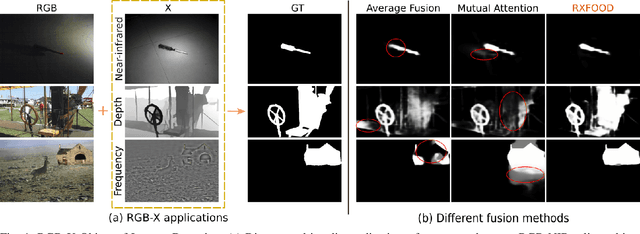
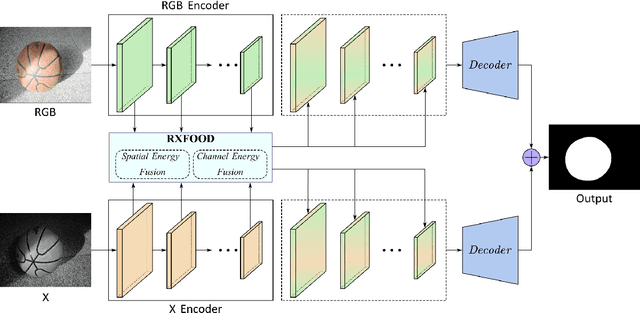
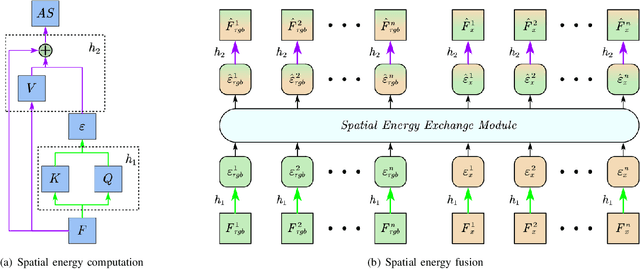
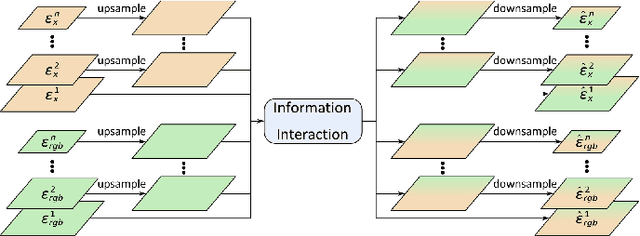
The emergence of different sensors (Near-Infrared, Depth, etc.) is a remedy for the limited application scenarios of traditional RGB camera. The RGB-X tasks, which rely on RGB input and another type of data input to resolve specific problems, have become a popular research topic in multimedia. A crucial part in two-branch RGB-X deep neural networks is how to fuse information across modalities. Given the tremendous information inside RGB-X networks, previous works typically apply naive fusion (e.g., average or max fusion) or only focus on the feature fusion at the same scale(s). While in this paper, we propose a novel method called RXFOOD for the fusion of features across different scales within the same modality branch and from different modality branches simultaneously in a unified attention mechanism. An Energy Exchange Module is designed for the interaction of each feature map's energy matrix, who reflects the inter-relationship of different positions and different channels inside a feature map. The RXFOOD method can be easily incorporated to any dual-branch encoder-decoder network as a plug-in module, and help the original backbone network better focus on important positions and channels for object of interest detection. Experimental results on RGB-NIR salient object detection, RGB-D salient object detection, and RGBFrequency image manipulation detection demonstrate the clear effectiveness of the proposed RXFOOD.
How to train your demon to do fast information erasure without heat production
May 17, 2023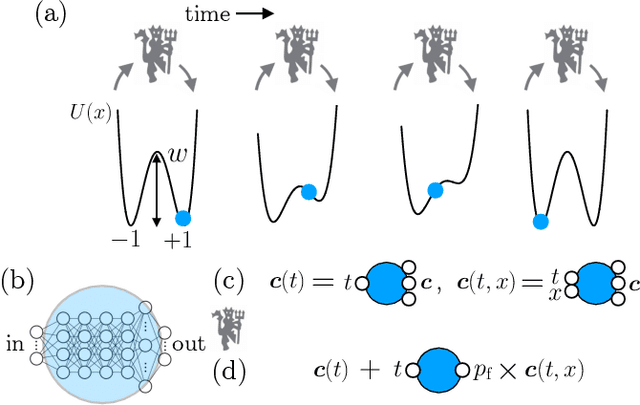
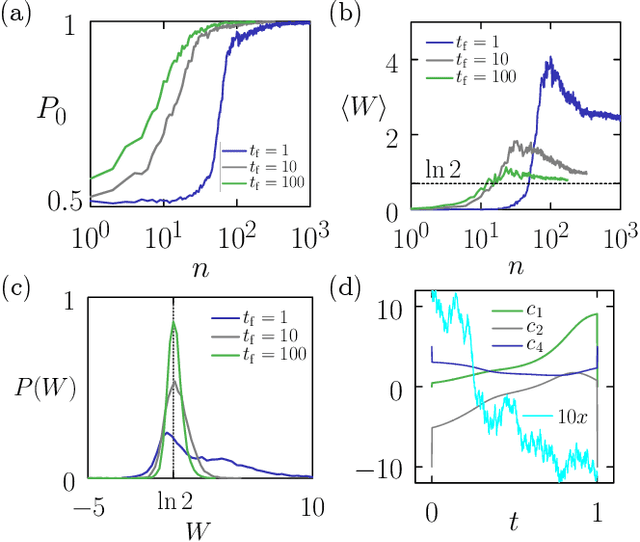
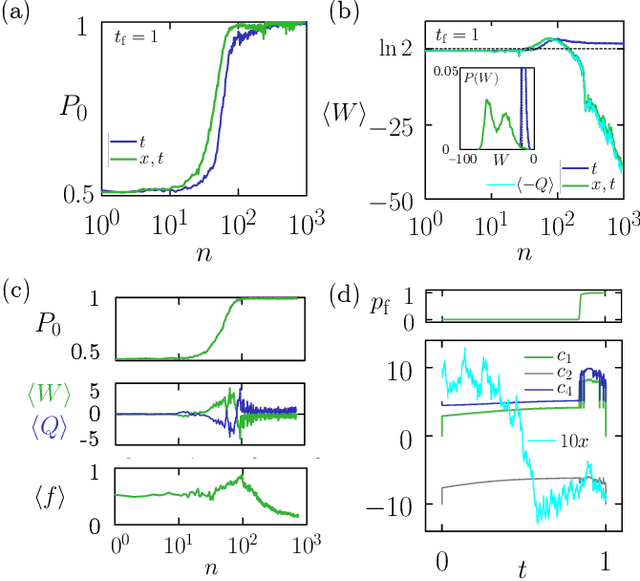
Time-dependent protocols that perform irreversible logical operations, such as memory erasure, cost work and produce heat, placing bounds on the efficiency of computers. Here we use a prototypical computer model of a physical memory to show that it is possible to learn feedback-control protocols to do fast memory erasure without input of work or production of heat. These protocols, which are enacted by a neural-network "demon", do not violate the second law of thermodynamics because the demon generates more heat than the memory absorbs. The result is a form of nonlocal heat exchange in which one computation is rendered energetically favorable while a compensating one produces heat elsewhere, a tactic that could be used to rationally design the flow of energy within a computer.
Text Alignment Is An Efficient Unified Model for Massive NLP Tasks
Jul 06, 2023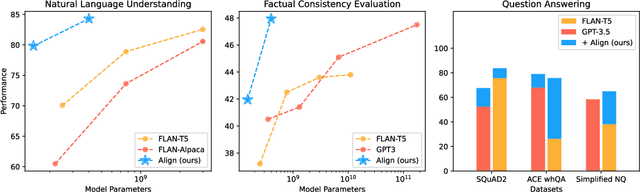
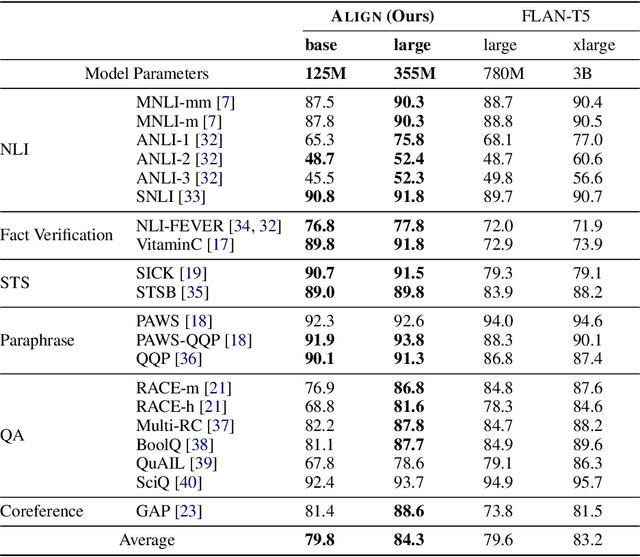
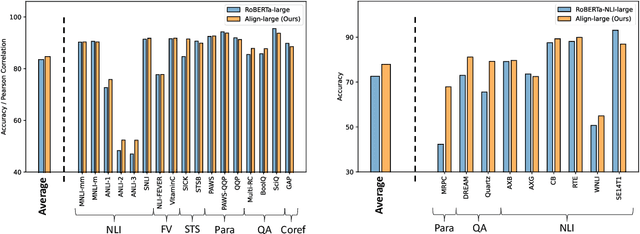
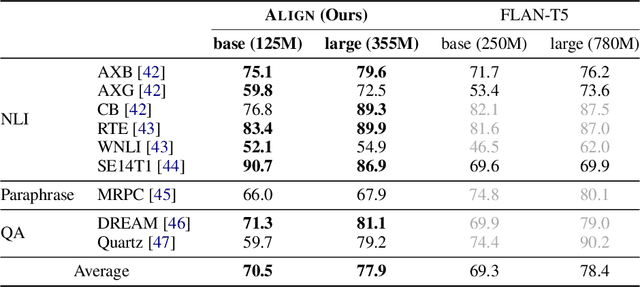
Large language models (LLMs), typically designed as a function of next-word prediction, have excelled across extensive NLP tasks. Despite the generality, next-word prediction is often not an efficient formulation for many of the tasks, demanding an extreme scale of model parameters (10s or 100s of billions) and sometimes yielding suboptimal performance. In practice, it is often desirable to build more efficient models -- despite being less versatile, they still apply to a substantial subset of problems, delivering on par or even superior performance with much smaller model sizes. In this paper, we propose text alignment as an efficient unified model for a wide range of crucial tasks involving text entailment, similarity, question answering (and answerability), factual consistency, and so forth. Given a pair of texts, the model measures the degree of alignment between their information. We instantiate an alignment model (Align) through lightweight finetuning of RoBERTa (355M parameters) using 5.9M examples from 28 datasets. Despite its compact size, extensive experiments show the model's efficiency and strong performance: (1) On over 20 datasets of aforementioned diverse tasks, the model matches or surpasses FLAN-T5 models that have around 2x or 10x more parameters; the single unified model also outperforms task-specific models finetuned on individual datasets; (2) When applied to evaluate factual consistency of language generation on 23 datasets, our model improves over various baselines, including the much larger GPT-3.5 (ChatGPT) and sometimes even GPT-4; (3) The lightweight model can also serve as an add-on component for LLMs such as GPT-3.5 in question answering tasks, improving the average exact match (EM) score by 17.94 and F1 score by 15.05 through identifying unanswerable questions.
Performance Analysis and Approximate Message Passing Detection of Orthogonal Time Sequency Multiplexing Modulation
Jul 06, 2023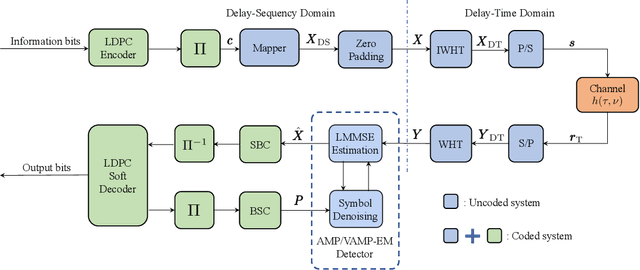
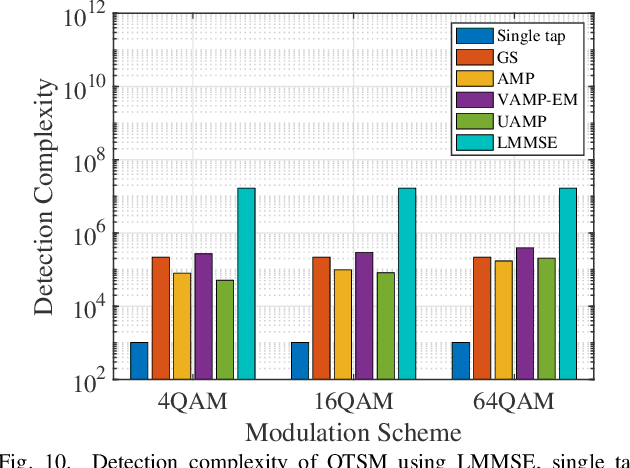
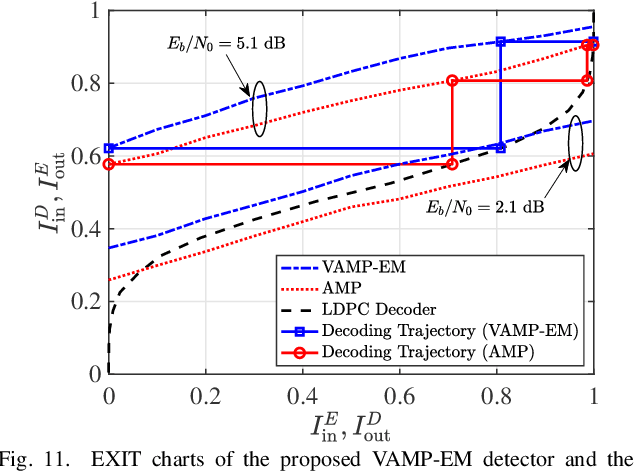
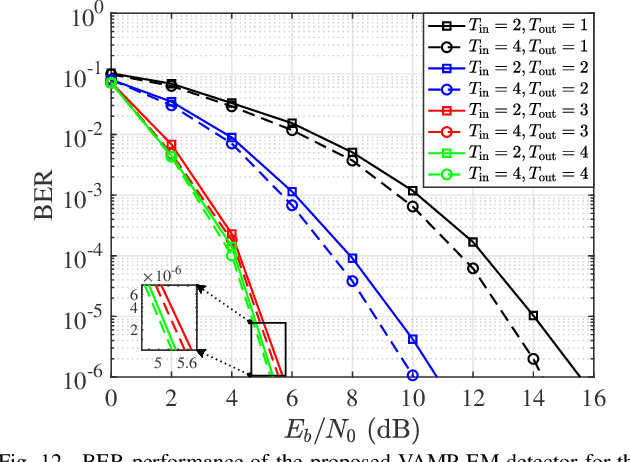
In orthogonal time sequency multiplexing (OTSM) modulation, the information symbols are conveyed in the delay-sequency domain upon exploiting the inverse Walsh Hadamard transform (IWHT). It has been shown that OTSM is capable of attaining a bit error ratio (BER) similar to that of orthogonal time-frequency space (OTFS) modulation at a lower complexity, since the saving of multiplication operations in the IWHT. Hence we provide its BER performance analysis and characterize its detection complexity. We commence by deriving its generalized input-output relationship and its unconditional pairwise error probability (UPEP). Then, its BER upper bound is derived in closed form under both ideal and imperfect channel estimation conditions, which is shown to be tight at moderate to high signal-to-noise ratios (SNRs). Moreover, a novel approximate message passing (AMP) aided OTSM detection framework is proposed. Specifically, to circumvent the high residual BER of the conventional AMP detector, we proposed a vector AMP-based expectation-maximization (VAMP-EM) detector for performing joint data detection and noise variance estimation. The variance auto-tuning algorithm based on the EM algorithm is designed for the VAMP-EM detector to further improve the convergence performance. The simulation results illustrate that the VAMP-EM detector is capable of striking an attractive BER vs. complexity trade-off than the state-of-the-art schemes as well as providing a better convergence. Finally, we propose AMP and VAMP-EM turbo receivers for low-density parity-check (LDPC)-coded OTSM systems. It is demonstrated that our proposed VAMP-EM turbo receiver is capable of providing both BER and convergence performance improvements over the conventional AMP solution.