 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CSCLog: A Component Subsequence Correlation-Aware Log Anomaly Detection Method
Jul 07, 2023
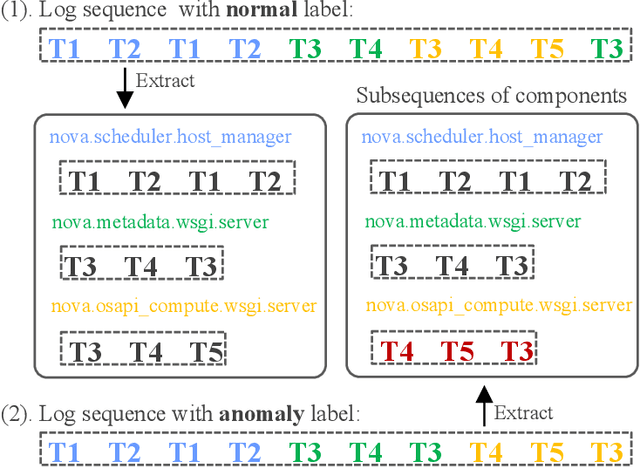

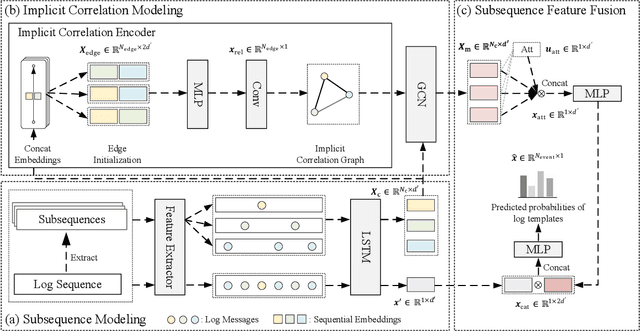
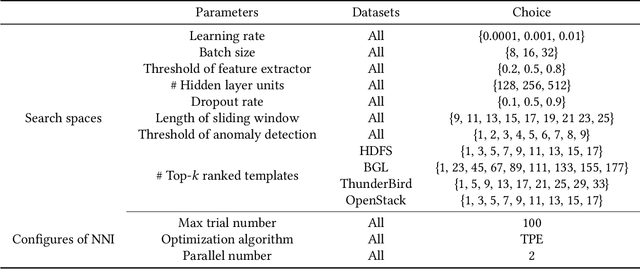
Anomaly detection based on system logs plays an important role in intelligent operations, which is a challenging task due to the extremely complex log patterns. Existing methods detect anomalies by capturing the sequential dependencies in log sequences, which ignore the interactions of subsequences. To this end, we propose CSCLog, a Component Subsequence Correlation-Aware Log anomaly detection method, which not only captures the sequential dependencies in subsequences, but also models the implicit correlations of subsequences. Specifically, subsequences are extracted from log sequences based on components and the sequential dependencies in subsequences are captured by Long Short-Term Memory Networks (LSTMs). An implicit correlation encoder is introduced to model the implicit correlations of subsequences adaptively. In addition, Graph Convolution Networks (GCNs) are employed to accomplish the information interactions of subsequences. Finally, attention mechanisms are exploited to fuse the embeddings of all subsequences. Extensive experiments on four publicly available log datasets demonstrate the effectiveness of CSCLog, outperforming the best baseline by an average of 7.41% in Macro F1-Measure.
Coordinate-based neural representations for computational adaptive optics in widefield microscopy
Jul 07, 2023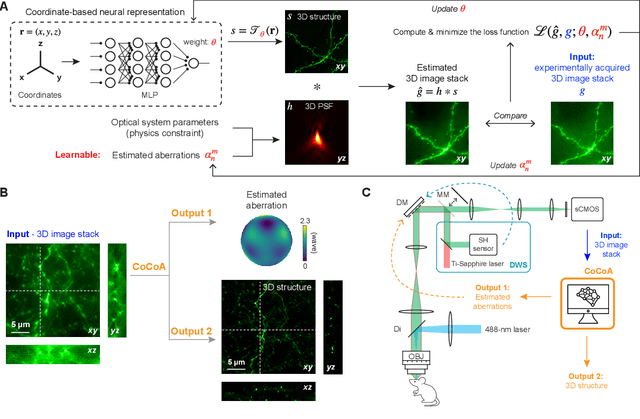
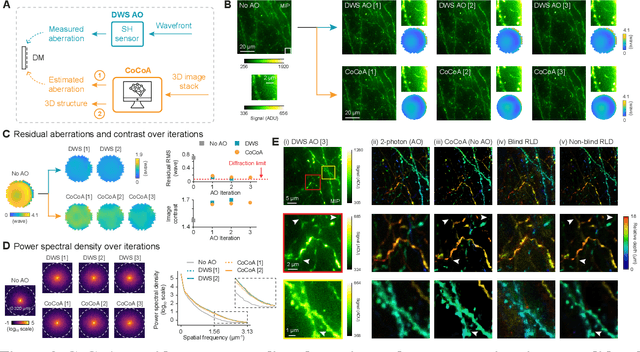
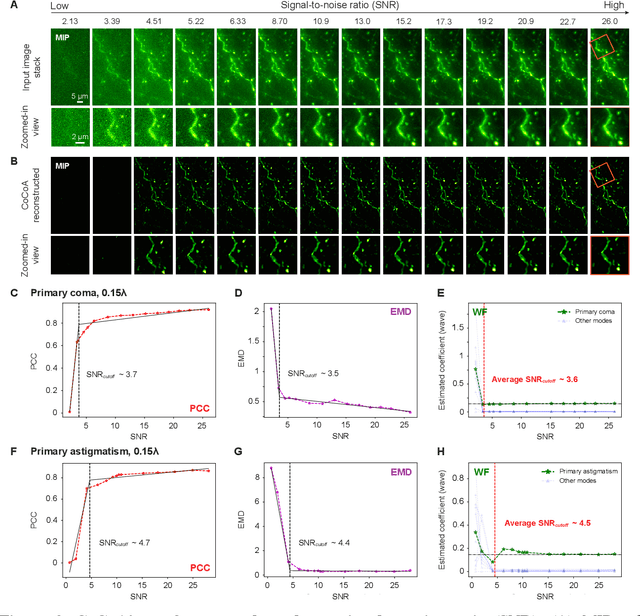
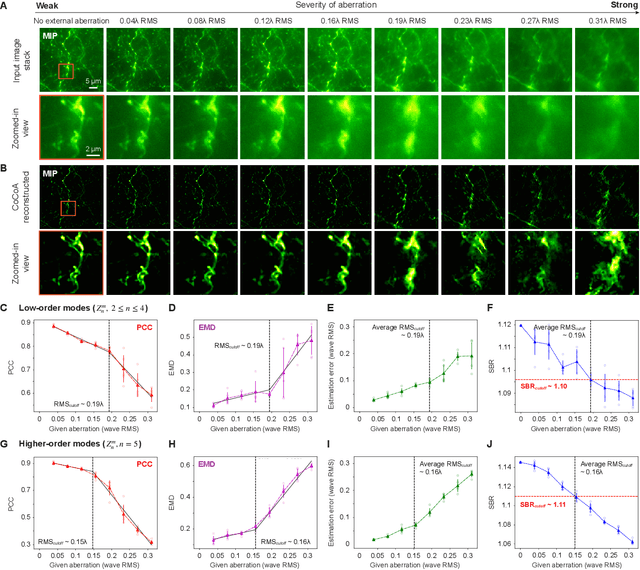
Widefield microscopy is widely used for non-invasive imaging of biological structures at subcellular resolution. When applied to complex specimen, its image quality is degraded by sample-induced optical aberration. Adaptive optics can correct wavefront distortion and restore diffraction-limited resolution but require wavefront sensing and corrective devices, increasing system complexity and cost. Here, we describe a self-supervised machine learning algorithm, CoCoA, that performs joint wavefront estimation and three-dimensional structural information extraction from a single input 3D image stack without the need for external training dataset. We implemented CoCoA for widefield imaging of mouse brain tissues and validated its performance with direct-wavefront-sensing-based adaptive optics. Importantly, we systematically explored and quantitatively characterized the limiting factors of CoCoA's performance. Using CoCoA, we demonstrated the first in vivo widefield mouse brain imaging using machine-learning-based adaptive optics. Incorporating coordinate-based neural representations and a forward physics model, the self-supervised scheme of CoCoA should be applicable to microscopy modalities in general.
An Anti-Jamming Strategy for Disco Intelligent Reflecting Surfaces Based Fully-Passive Jamming Attacks
Jul 07, 2023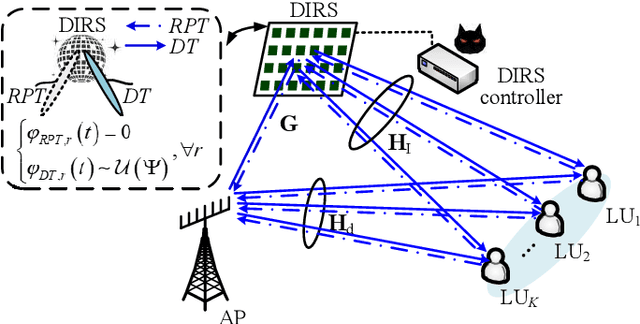
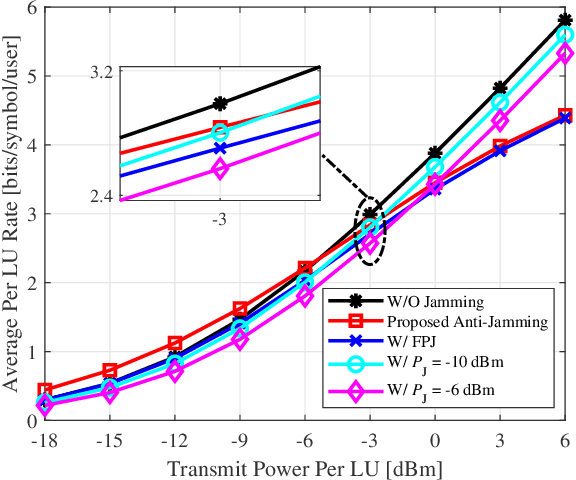
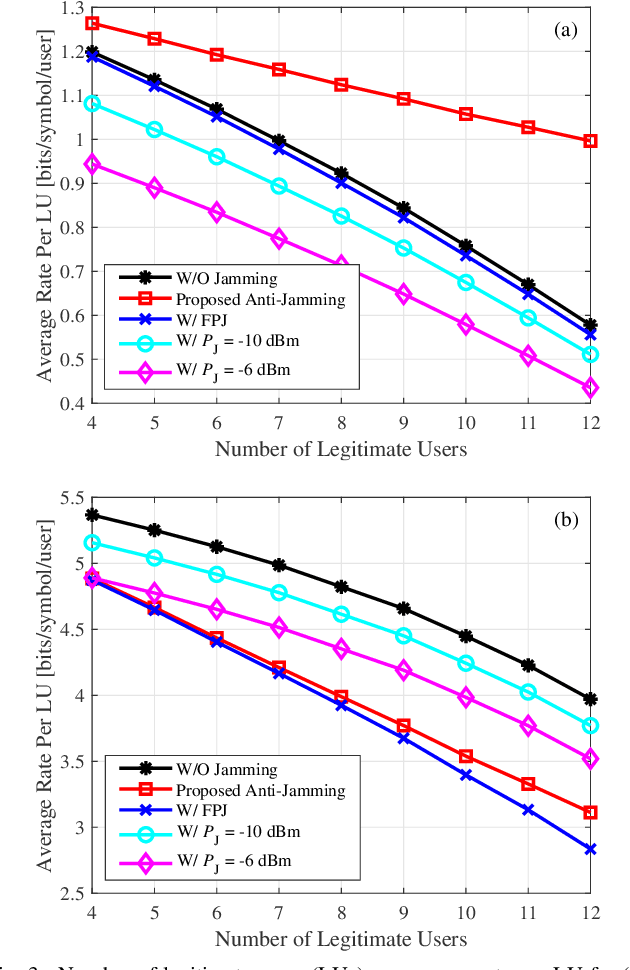
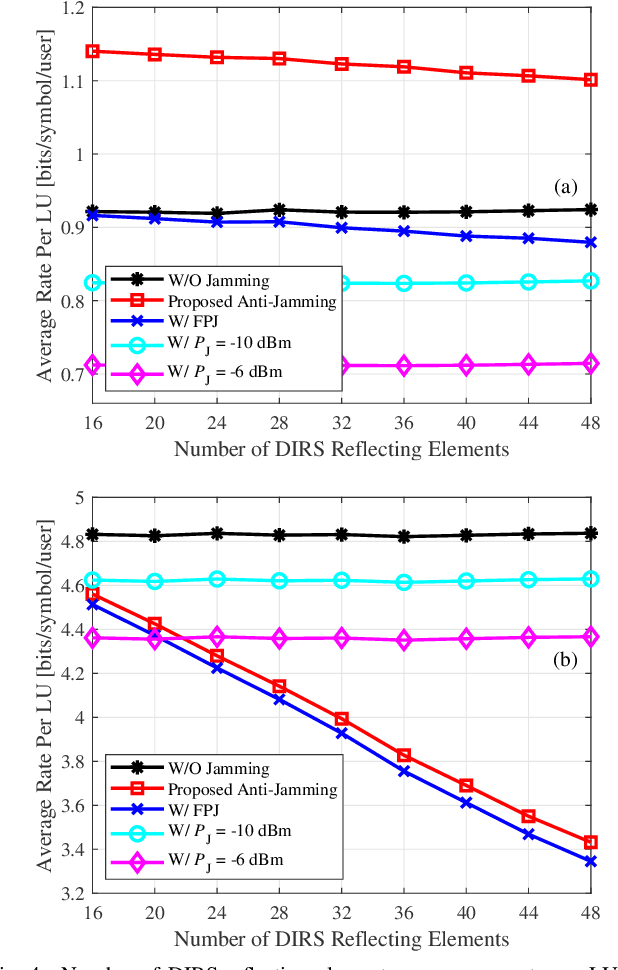
Emerging intelligent reflecting surfaces (IRSs) significantly improve system performance, while also pose a huge risk for physical layer security. A disco IRS (DIRS), i.e., an illegitimate IRS with random time-varying reflection properties, can be employed by an attacker to actively age the channels of legitimate users (LUs). Such active channel aging (ACA) generated by the DIRS-based fully-passive jammer (FPJ) can be applied to jam multi-user multiple-input single-output (MU-MISO) systems without relying on either jamming power or LU channel state information (CSI). To address the significant threats posed by the DIRS-based FPJ, an anti-jamming strategy is proposed that requires only the statistical characteristics of DIRS-jammed channels instead of their CSI. Statistical characteristics of DIRS-jammed channels are first derived, and then the anti-jamming precoder is given based on the derived statistical characteristics. Numerical results are also presented to evaluate the effectiveness of the proposed anti-jamming precoder against the DIRS-based FPJ.
Freezing of Gait Prediction From Accelerometer Data Using a Simple 1D-Convolutional Neural Network -- 8th Place Solution for Kaggle's Parkinson's Freezing of Gait Prediction Competition
Jul 07, 2023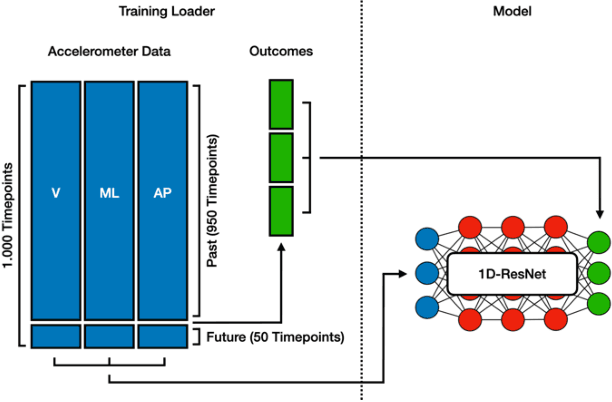
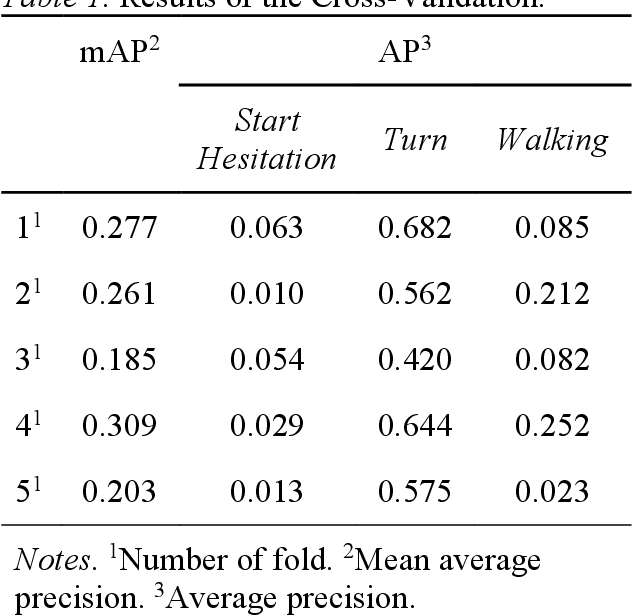
Freezing of Gait (FOG) is a common motor symptom in patients with Parkinson's disease (PD). During episodes of FOG, patients suddenly lose their ability to stride as intended. Patient-worn accelerometers can capture information on the patient's movement during these episodes and machine learning algorithms can potentially classify this data. The combination therefore holds the potential to detect FOG in real-time. In this work I present a simple 1-D convolutional neural network that was trained to detect FOG events in accelerometer data. Model performance was assessed by measuring the success of the model to discriminate normal movement from FOG episodes and resulted in a mean average precision of 0.356 on the private leaderboard on Kaggle. Ultimately, the model ranked 8th out of 1379 teams in the Parkinson's Freezing of Gait Prediction competition. The results underscore the potential of Deep Learning-based solutions in advancing the field of FOG detection, contributing to improved interventions and management strategies for PD patients.
MuLMS-AZ: An Argumentative Zoning Dataset for the Materials Science Domain
Jul 05, 2023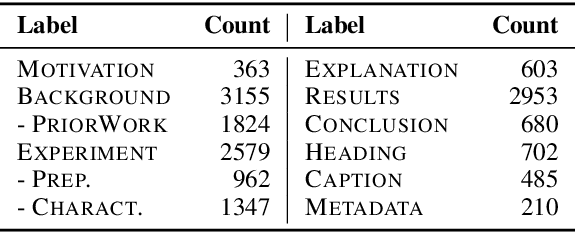

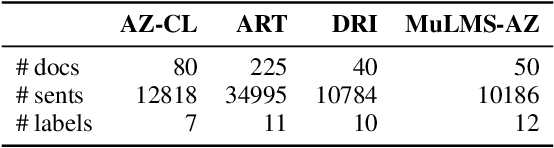
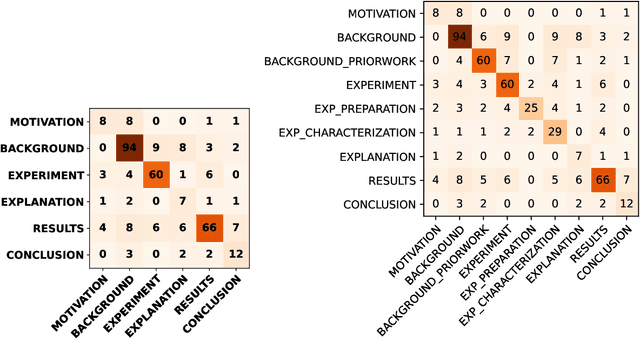
Scientific publications follow conventionalized rhetorical structures. Classifying the Argumentative Zone (AZ), e.g., identifying whether a sentence states a Motivation, a Result or Background information, has been proposed to improve processing of scholarly documents. In this work, we adapt and extend this idea to the domain of materials science research. We present and release a new dataset of 50 manually annotated research articles. The dataset spans seven sub-topics and is annotated with a materials-science focused multi-label annotation scheme for AZ. We detail corpus statistics and demonstrate high inter-annotator agreement. Our computational experiments show that using domain-specific pre-trained transformer-based text encoders is key to high classification performance. We also find that AZ categories from existing datasets in other domains are transferable to varying degrees.
Performance Analysis of RIS-Aided Space Shift Keying With Channel Estimation Errors
Jul 05, 2023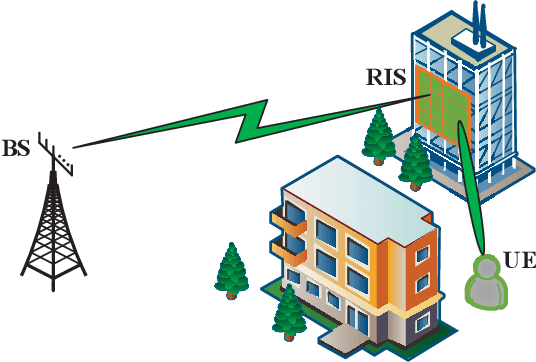
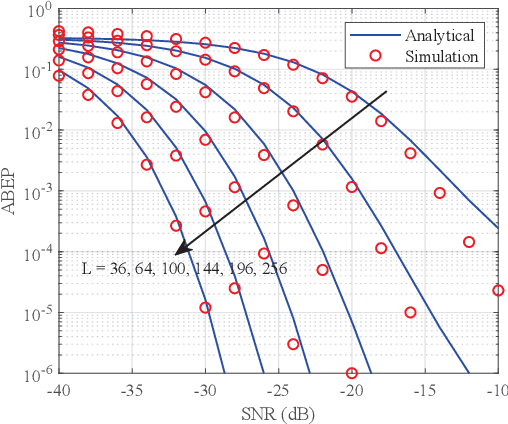
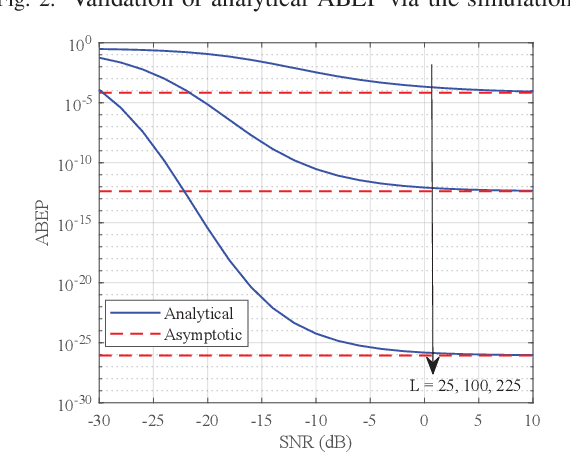
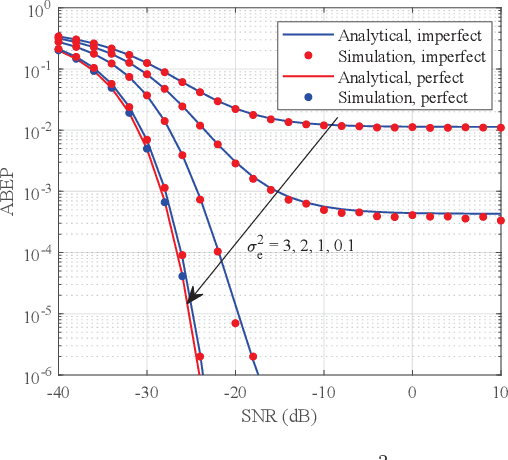
In this paper, we investigate the reconfigurable intelligent surface (RIS) assisted space shift keying (SSK) downlink communication systems under the imperfect channel state information (CSI), where the channel between the base station to RIS follows the Rayleigh fading, while the channel between the RIS to user equipment obeys the Rician fading. Based on the maximum likelihood detector, the conditional pairwise error probability of the composite channel is derived. Then, the probability density function for a non-central chi-square distribution with one degree of freedom is derived. Based on this, the closed-form analytical expression of the RIS-SSK scheme with imperfect CSI is derived. To gain more valuable insights, the asymptotic ABEP expression is also given. Finally, we validate the derived closed-form and asymptotic expressions by Monte Carlo simulations.
Dynamic Size Message Scheduling for Multi-Agent Communication under Limited Bandwidth
Jun 16, 2023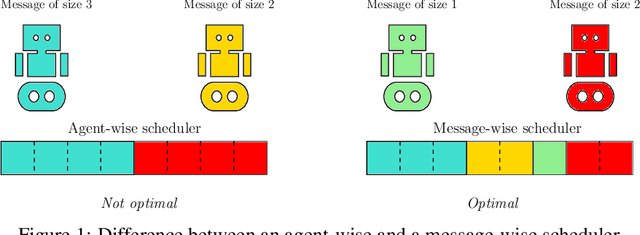
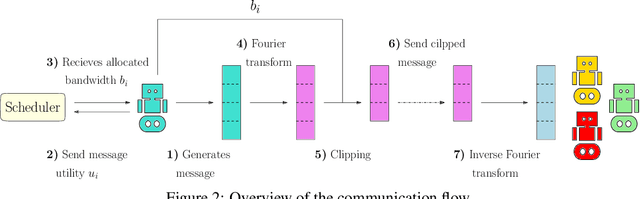
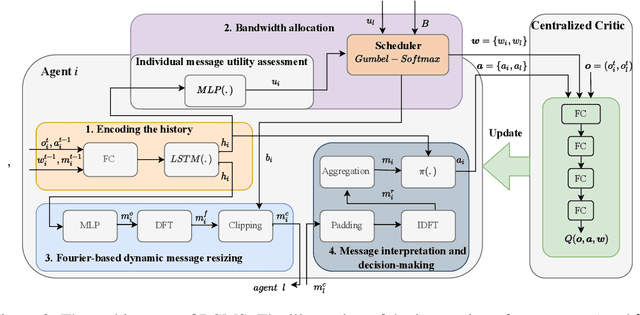
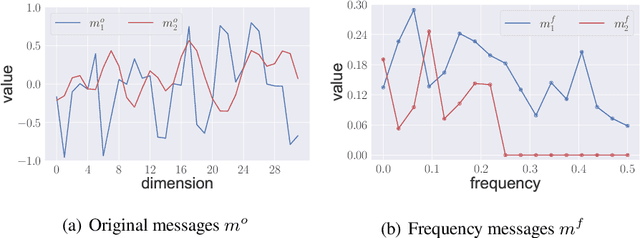
Communication plays a vital role in multi-agent systems, fostering collaboration and coordination. However, in real-world scenarios where communication is bandwidth-limited, existing multi-agent reinforcement learning (MARL) algorithms often provide agents with a binary choice: either transmitting a fixed number of bytes or no information at all. This limitation hinders the ability to effectively utilize the available bandwidth. To overcome this challenge, we present the Dynamic Size Message Scheduling (DSMS) method, which introduces a finer-grained approach to scheduling by considering the actual size of the information to be exchanged. Our contribution lies in adaptively adjusting message sizes using Fourier transform-based compression techniques, enabling agents to tailor their messages to match the allocated bandwidth while striking a balance between information loss and transmission efficiency. Receiving agents can reliably decompress the messages using the inverse Fourier transform. Experimental results demonstrate that DSMS significantly improves performance in multi-agent cooperative tasks by optimizing the utilization of bandwidth and effectively balancing information value.
Latent Graph Attention for Enhanced Spatial Context
Jul 12, 2023
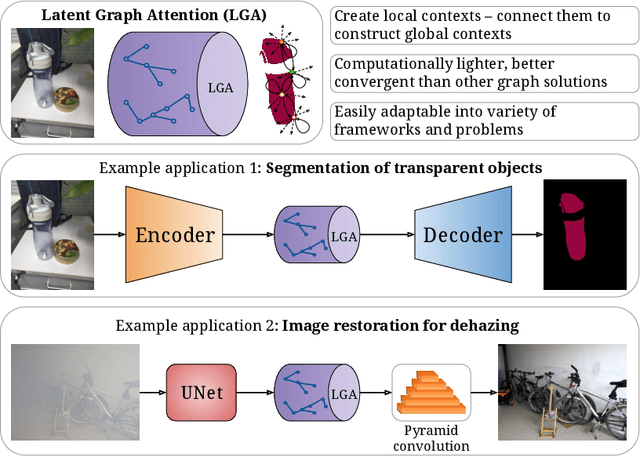
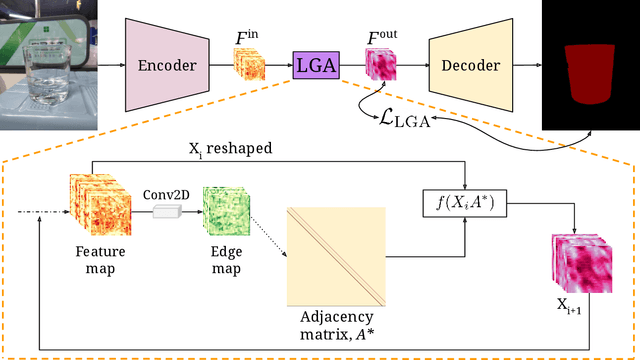
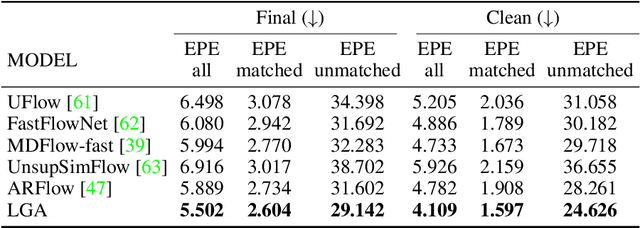
Global contexts in images are quite valuable in image-to-image translation problems. Conventional attention-based and graph-based models capture the global context to a large extent, however, these are computationally expensive. Moreover, the existing approaches are limited to only learning the pairwise semantic relation between any two points on the image. In this paper, we present Latent Graph Attention (LGA) a computationally inexpensive (linear to the number of nodes) and stable, modular framework for incorporating the global context in the existing architectures, especially empowering small-scale architectures to give performance closer to large size architectures, thus making the light-weight architectures more useful for edge devices with lower compute power and lower energy needs. LGA propagates information spatially using a network of locally connected graphs, thereby facilitating to construct a semantically coherent relation between any two spatially distant points that also takes into account the influence of the intermediate pixels. Moreover, the depth of the graph network can be used to adapt the extent of contextual spread to the target dataset, thereby being able to explicitly control the added computational cost. To enhance the learning mechanism of LGA, we also introduce a novel contrastive loss term that helps our LGA module to couple well with the original architecture at the expense of minimal additional computational load. We show that incorporating LGA improves the performance on three challenging applications, namely transparent object segmentation, image restoration for dehazing and optical flow estimation.
Mutual Information-Based Temporal Difference Learning for Human Pose Estimation in Video
Mar 15, 2023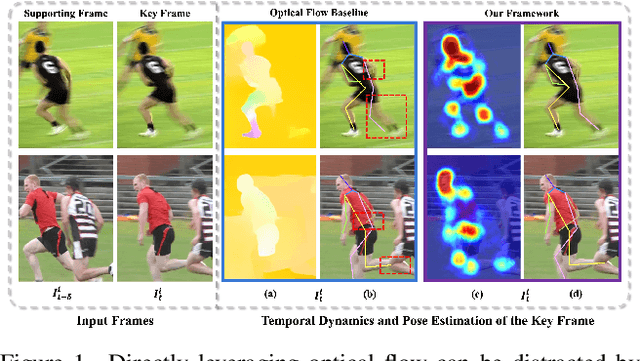
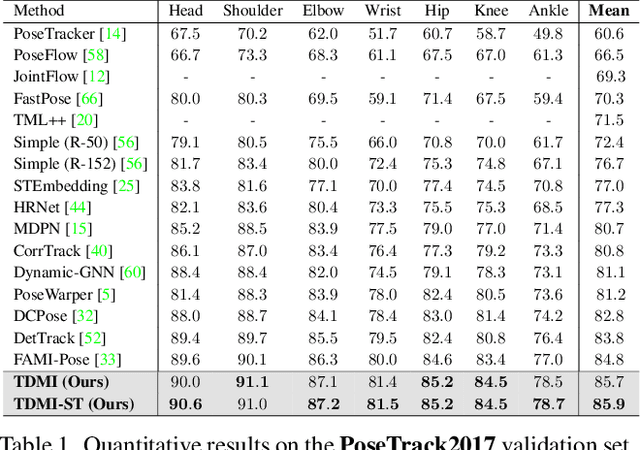
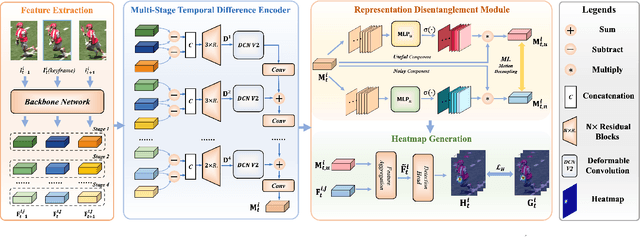
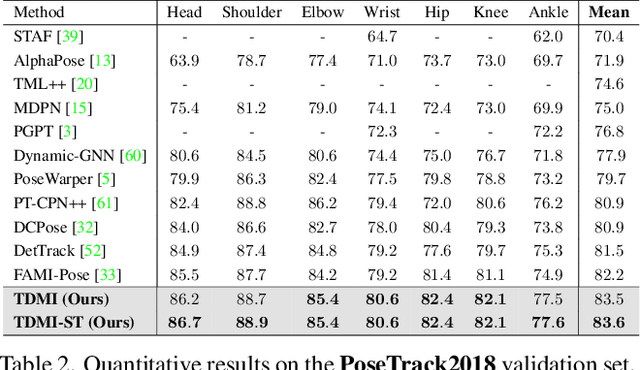
Temporal modeling is crucial for multi-frame human pose estimation. Most existing methods directly employ optical flow or deformable convolution to predict full-spectrum motion fields, which might incur numerous irrelevant cues, such as a nearby person or background. Without further efforts to excavate meaningful motion priors, their results are suboptimal, especially in complicated spatiotemporal interactions. On the other hand, the temporal difference has the ability to encode representative motion information which can potentially be valuable for pose estimation but has not been fully exploited. In this paper, we present a novel multi-frame human pose estimation framework, which employs temporal differences across frames to model dynamic contexts and engages mutual information objectively to facilitate useful motion information disentanglement. To be specific, we design a multi-stage Temporal Difference Encoder that performs incremental cascaded learning conditioned on multi-stage feature difference sequences to derive informative motion representation. We further propose a Representation Disentanglement module from the mutual information perspective, which can grasp discriminative task-relevant motion signals by explicitly defining useful and noisy constituents of the raw motion features and minimizing their mutual information. These place us to rank No.1 in the Crowd Pose Estimation in Complex Events Challenge on benchmark dataset HiEve, and achieve state-of-the-art performance on three benchmarks PoseTrack2017, PoseTrack2018, and PoseTrack21.
Autonomy 2.0: The Quest for Economies of Scale
Jul 08, 2023
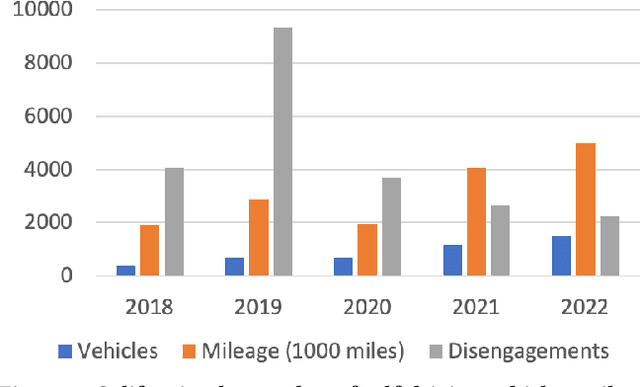
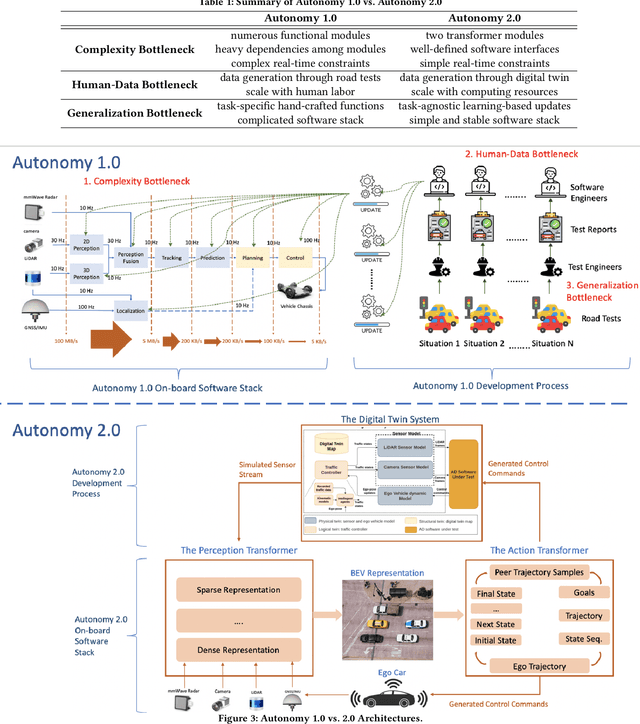
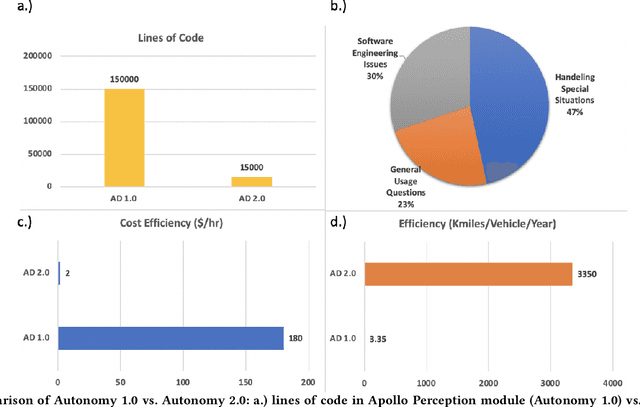
With the advancement of robotics and AI technologies in the past decade, we have now entered the age of autonomous machines. In this new age of information technology, autonomous machines, such as service robots, autonomous drones, delivery robots, and autonomous vehicles, rather than humans, will provide services. In this article, through examining the technical challenges and economic impact of the digital economy, we argue that scalability is both highly necessary from a technical perspective and significantly advantageous from an economic perspective, thus is the key for the autonomy industry to achieve its full potential. Nonetheless, the current development paradigm, dubbed Autonomy 1.0, scales with the number of engineers, instead of with the amount of data or compute resources, hence preventing the autonomy industry to fully benefit from the economies of scale, especially the exponentially cheapening compute cost and the explosion of available data. We further analyze the key scalability blockers and explain how a new development paradigm, dubbed Autonomy 2.0, can address these problems to greatly boost the autonomy industry.