 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuLMS-AZ: An Argumentative Zoning Dataset for the Materials Science Domain
Jul 05, 2023



Scientific publications follow conventionalized rhetorical structures. Classifying the Argumentative Zone (AZ), e.g., identifying whether a sentence states a Motivation, a Result or Background information, has been proposed to improve processing of scholarly documents. In this work, we adapt and extend this idea to the domain of materials science research. We present and release a new dataset of 50 manually annotated research articles. The dataset spans seven sub-topics and is annotated with a materials-science focused multi-label annotation scheme for AZ. We detail corpus statistics and demonstrate high inter-annotator agreement. Our computational experiments show that using domain-specific pre-trained transformer-based text encoders is key to high classification performance. We also find that AZ categories from existing datasets in other domains are transferable to varying degrees.
MIST: a Large-Scale Annotated Resource and Neural Models for Functions of Modal Verbs in English Scientific Text
Dec 14, 2022Modal verbs (e.g., "can", "should", or "must") occur highly frequently in scientific articles. Decoding their function is not straightforward: they are often used for hedging, but they may also denote abilities and restrictions. Understanding their meaning is important for various NLP tasks such as writing assistance or accurate information extraction from scientific text. To foster research on the usage of modals in this genre, we introduce the MIST (Modals In Scientific Text) dataset, which contains 3737 modal instances in five scientific domains annotated for their semantic, pragmatic, or rhetorical function. We systematically evaluate a set of competitive neural architectures on MIST. Transfer experiments reveal that leveraging non-scientific data is of limited benefit for modeling the distinctions in MIST. Our corpus analysis provides evidence that scientific communities differ in their usage of modal verbs, yet, classifiers trained on scientific data generalize to some extent to unseen scientific domains.
A Survey of Methods for Addressing Class Imbalance in Deep-Learning Based Natural Language Processing
Oct 10, 2022

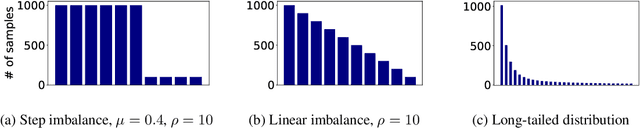
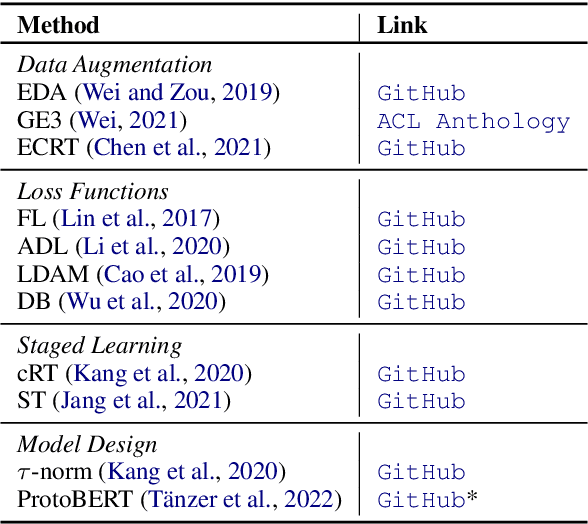
Many natural language processing (NLP) tasks are naturally imbalanced, as some target categories occur much more frequently than others in the real world. In such scenarios, current NLP models still tend to perform poorly on less frequent classes. Addressing class imbalance in NLP is an active research topic, yet, finding a good approach for a particular task and imbalance scenario is difficult. With this survey, the first overview on class imbalance in deep-learning based NLP, we provide guidance for NLP researchers and practitioners dealing with imbalanced data. We first discuss various types of controlled and real-world class imbalance. Our survey then covers approaches that have been explicitly proposed for class-imbalanced NLP tasks or, originating in the computer vision community, have been evaluated on them. We organize the methods by whether they are based on sampling, data augmentation, choice of loss function, staged learning, or model design. Finally, we discuss open problems such as dealing with multi-label scenarios, and propose systematic benchmarking and reporting in order to move forward on this problem as a community.
Generalized chart constraints for efficient PCFG and TAG parsing
Jun 27, 2018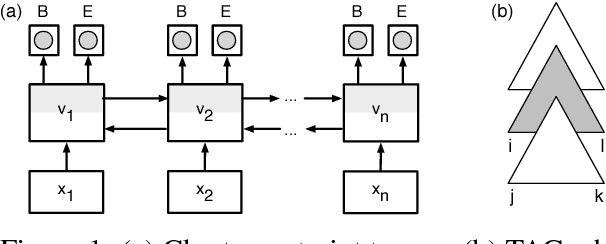
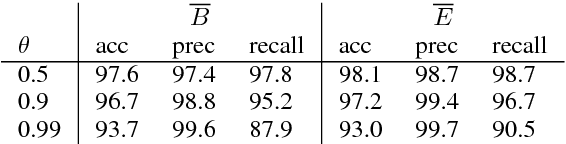
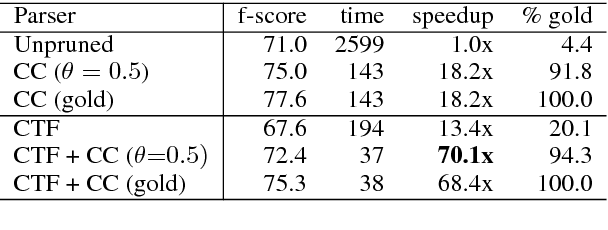
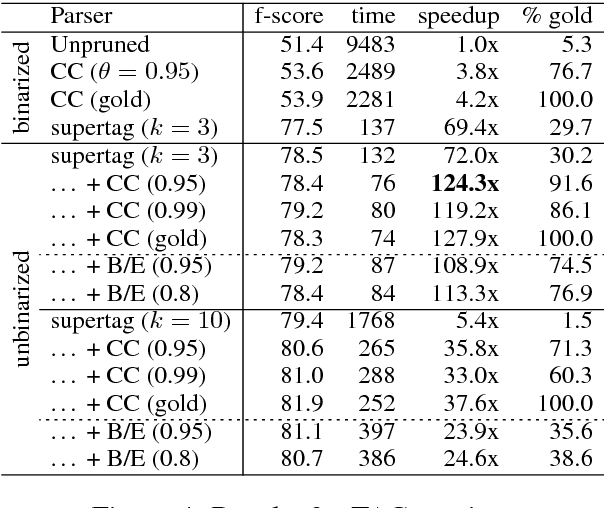
Chart constraints, which specify at which string positions a constituent may begin or end, have been shown to speed up chart parsers for PCFGs. We generalize chart constraints to more expressive grammar formalisms and describe a neural tagger which predicts chart constraints at very high precision. Our constraints accelerate both PCFG and TAG parsing, and combine effectively with other pruning techniques (coarse-to-fine and supertagging) for an overall speedup of two orders of magnitude, while improving accuracy.