 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuLMS: A Multi-Layer Annotated Text Corpus for Information Extraction in the Materials Science Domain
Oct 24, 2023



Keeping track of all relevant recent publications and experimental results for a research area is a challenging task. Prior work has demonstrated the efficacy of information extraction models in various scientific areas. Recently, several datasets have been released for the yet understudied materials science domain. However, these datasets focus on sub-problems such as parsing synthesis procedures or on sub-domains, e.g., solid oxide fuel cells. In this resource paper, we present MuLMS, a new dataset of 50 open-access articles, spanning seven sub-domains of materials science. The corpus has been annotated by domain experts with several layers ranging from named entities over relations to frame structures. We present competitive neural models for all tasks and demonstrate that multi-task training with existing related resources leads to benefits.
MuLMS-AZ: An Argumentative Zoning Dataset for the Materials Science Domain
Jul 05, 2023



Scientific publications follow conventionalized rhetorical structures. Classifying the Argumentative Zone (AZ), e.g., identifying whether a sentence states a Motivation, a Result or Background information, has been proposed to improve processing of scholarly documents. In this work, we adapt and extend this idea to the domain of materials science research. We present and release a new dataset of 50 manually annotated research articles. The dataset spans seven sub-topics and is annotated with a materials-science focused multi-label annotation scheme for AZ. We detail corpus statistics and demonstrate high inter-annotator agreement. Our computational experiments show that using domain-specific pre-trained transformer-based text encoders is key to high classification performance. We also find that AZ categories from existing datasets in other domains are transferable to varying degrees.
MIST: a Large-Scale Annotated Resource and Neural Models for Functions of Modal Verbs in English Scientific Text
Dec 14, 2022Modal verbs (e.g., "can", "should", or "must") occur highly frequently in scientific articles. Decoding their function is not straightforward: they are often used for hedging, but they may also denote abilities and restrictions. Understanding their meaning is important for various NLP tasks such as writing assistance or accurate information extraction from scientific text. To foster research on the usage of modals in this genre, we introduce the MIST (Modals In Scientific Text) dataset, which contains 3737 modal instances in five scientific domains annotated for their semantic, pragmatic, or rhetorical function. We systematically evaluate a set of competitive neural architectures on MIST. Transfer experiments reveal that leveraging non-scientific data is of limited benefit for modeling the distinctions in MIST. Our corpus analysis provides evidence that scientific communities differ in their usage of modal verbs, yet, classifiers trained on scientific data generalize to some extent to unseen scientific domains.
Negation-Instance Based Evaluation of End-to-End Negation Resolution
Sep 21, 2021
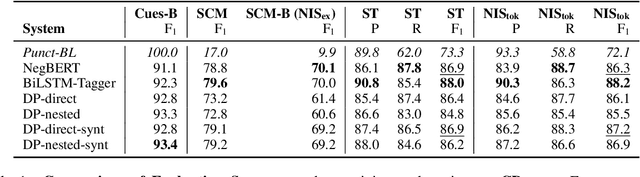
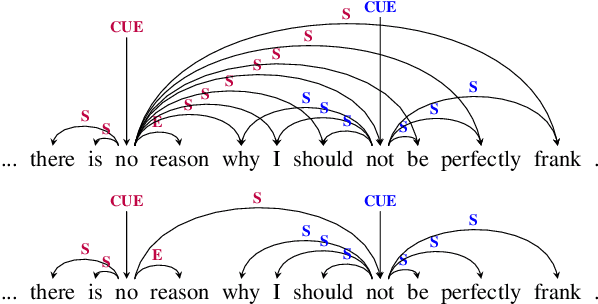
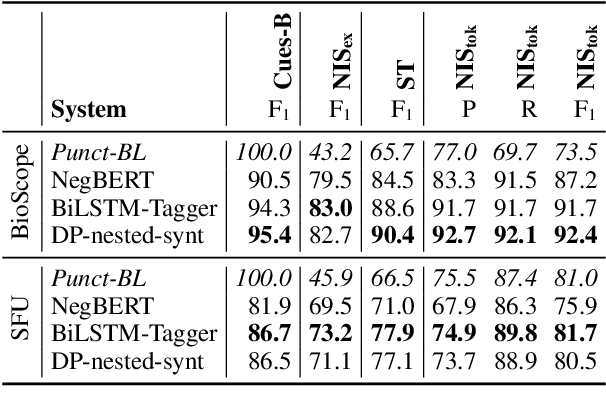
In this paper, we revisit the task of negation resolution, which includes the subtasks of cue detection (e.g. "not", "never") and scope resolution. In the context of previous shared tasks, a variety of evaluation metrics have been proposed. Subsequent works usually use different subsets of these, including variations and custom implementations, rendering meaningful comparisons between systems difficult. Examining the problem both from a linguistic perspective and from a downstream viewpoint, we here argue for a negation-instance based approach to evaluating negation resolution. Our proposed metrics correspond to expectations over per-instance scores and hence are intuitively interpretable. To render research comparable and to foster future work, we provide results for a set of current state-of-the-art systems for negation resolution on three English corpora, and make our implementation of the evaluation scripts publicly available.
Maximum Spanning Trees Are Invariant to Temperature Scaling in Graph-based Dependency Parsing
Jun 15, 2021
Modern graph-based syntactic dependency parsers operate by predicting, for each token within a sentence, a probability distribution over its possible syntactic heads (i.e., all other tokens) and then extracting a maximum spanning tree from the resulting log-probabilities. Nowadays, virtually all such parsers utilize deep neural networks and may thus be susceptible to miscalibration (in particular, overconfident predictions). In this paper, we prove that temperature scaling, a popular technique for post-hoc calibration of neural networks, cannot change the output of the aforementioned procedure. We conclude that other techniques are needed to tackle miscalibration in graph-based dependency parsers in a way that improves parsing accuracy.
Coordinate Constructions in English Enhanced Universal Dependencies: Analysis and Computational Modeling
Mar 16, 2021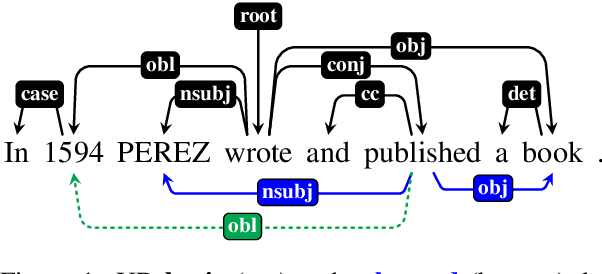
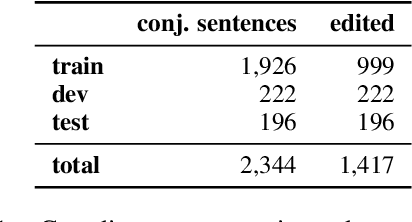

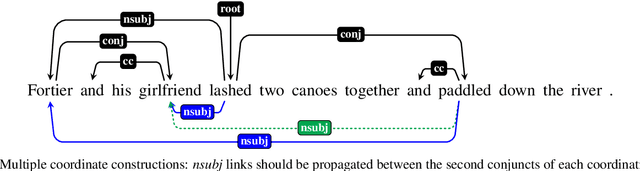
In this paper, we address the representation of coordinate constructions in Enhanced Universal Dependencies (UD), where relevant dependency links are propagated from conjunction heads to other conjuncts. English treebanks for enhanced UD have been created from gold basic dependencies using a heuristic rule-based converter, which propagates only core arguments. With the aim of determining which set of links should be propagated from a semantic perspective, we create a large-scale dataset of manually edited syntax graphs. We identify several systematic errors in the original data, and propose to also propagate adjuncts. We observe high inter-annotator agreement for this semantic annotation task. Using our new manually verified dataset, we perform the first principled comparison of rule-based and (partially novel) machine-learning based methods for conjunction propagation for English. We show that learning propagation rules is more effective than hand-designing heuristic rules. When using automatic parses, our neural graph-parser based edge predictor outperforms the currently predominant pipelinesusing a basic-layer tree parser plus converters.
Graph-Based Universal Dependency Parsing in the Age of the Transformer: What Works, and What Doesn't
Oct 23, 2020
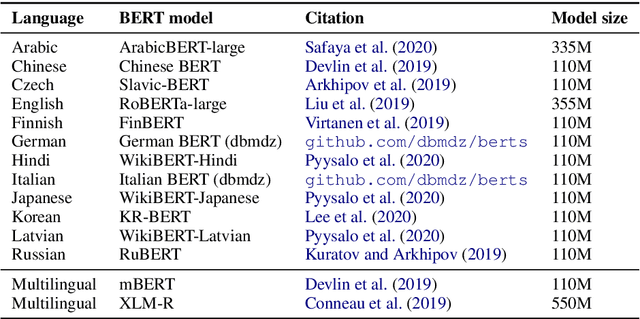
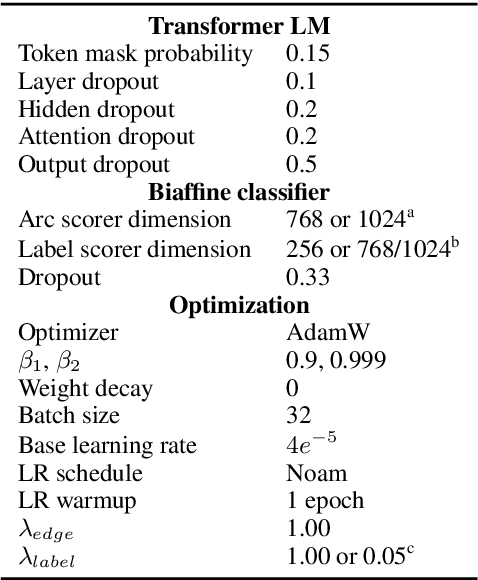
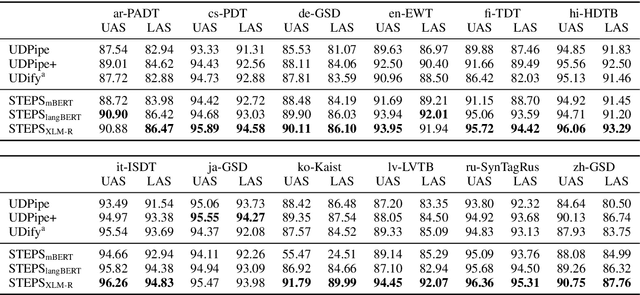
Current state-of-the-art graph-based dependency parsers differ on various dimensions. Among others, these include (a) the choice of pre-trained word embeddings or language models used for representing token, (b) training setups performing only parsing or additional tasks such as part-of-speech-tagging, and (c) their mechanism of constructing trees or graphs from edge scores. Because of this, it is difficult to estimate the impact of these architectural decisions when comparing parsers. In this paper, we perform a series of experiments on STEPS, a new modular graph-based parser for basic and enhanced Universal Dependencies, analyzing the effects of architectural configurations. We find that pre-trained embeddings have by far the greatest and most clear-cut impact on parser performance. The choice of factorized vs. unfactorized architectures and a multi-task training setup affect parsing accuracy in more subtle ways, depending on target language and output representation (trees vs. graphs). Our parser achieves new state-of-the-art results for a wide range of languages on both basic as well as enhanced Universal Dependencies, using a unified and comparatively simple architecture for both parsing tasks.
Generalized chart constraints for efficient PCFG and TAG parsing
Jun 27, 2018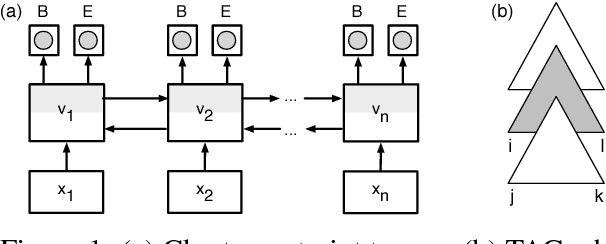
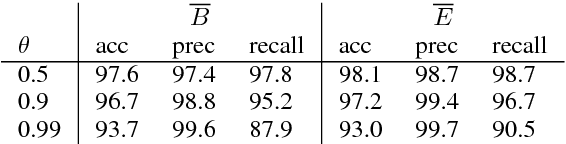
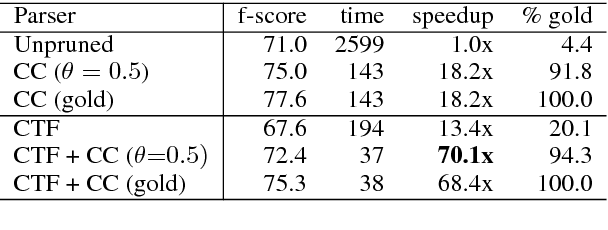
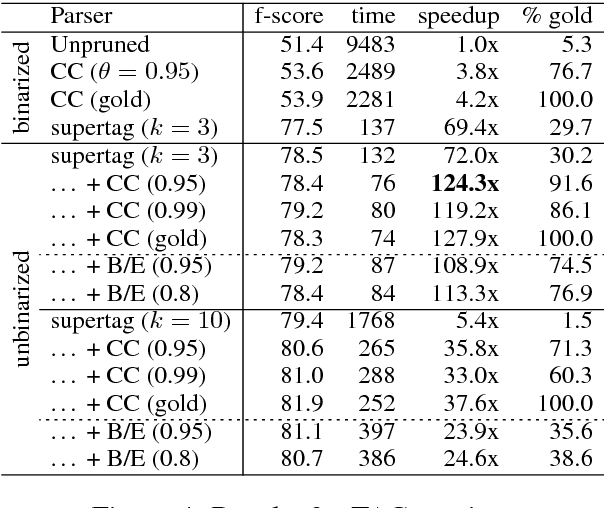
Chart constraints, which specify at which string positions a constituent may begin or end, have been shown to speed up chart parsers for PCFGs. We generalize chart constraints to more expressive grammar formalisms and describe a neural tagger which predicts chart constraints at very high precision. Our constraints accelerate both PCFG and TAG parsing, and combine effectively with other pruning techniques (coarse-to-fine and supertagging) for an overall speedup of two orders of magnitude, while improving accuracy.