 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Identification of Stochasticity by Matrix-decomposition: Applied on Black Hole Data
Jul 15, 2023
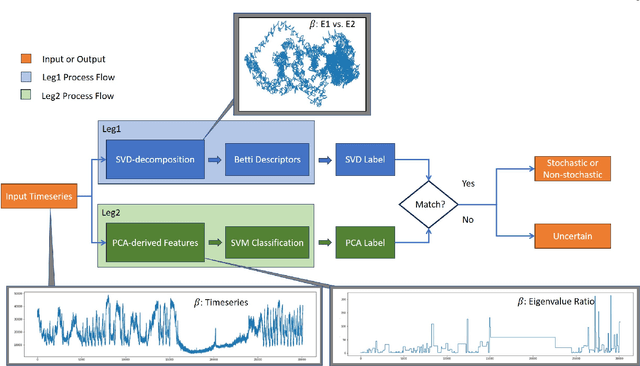
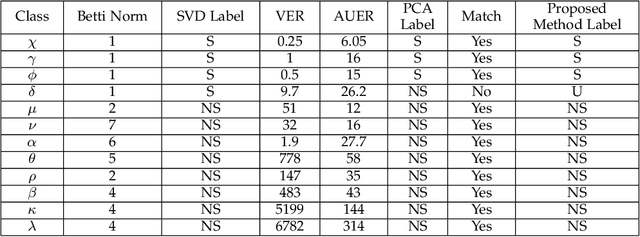
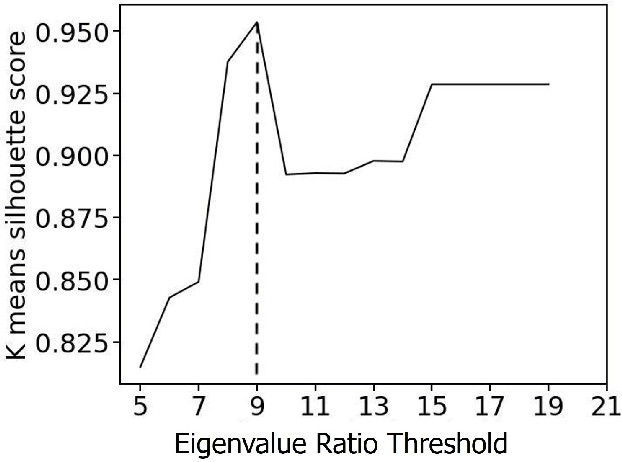
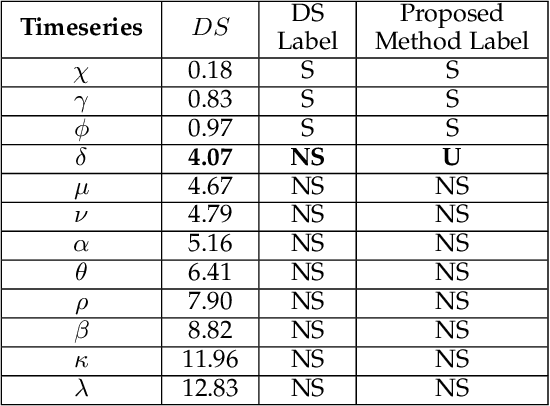
Timeseries classification as stochastic (noise-like) or non-stochastic (structured), helps understand the underlying dynamics, in several domains. Here we propose a two-legged matrix decomposition-based algorithm utilizing two complementary techniques for classification. In Singular Value Decomposition (SVD) based analysis leg, we perform topological analysis (Betti numbers) on singular vectors containing temporal information, leading to SVD-label. Parallely, temporal-ordering agnostic Principal Component Analysis (PCA) is performed, and the proposed PCA-derived features are computed. These features, extracted from synthetic timeseries of the two labels, are observed to map the timeseries to a linearly separable feature space. Support Vector Machine (SVM) is used to produce PCA-label. The proposed methods have been applied to synthetic data, comprising 41 realisations of white-noise, pink-noise (stochastic), Logistic-map at growth-rate 4 and Lorentz-system (non-stochastic), as proof-of-concept. Proposed algorithm is applied on astronomical data: 12 temporal-classes of timeseries of black hole GRS 1915+105, obtained from RXTE satellite with average length 25000. For a given timeseries, if SVD-label and PCA-label concur, then the label is retained; else deemed "Uncertain". Comparison of obtained results with those in literature are presented. It's found that out of 12 temporal classes of GRS 1915+105, concurrence between SVD-label and PCA-label is obtained on 11 of them.
WaterScenes: A Multi-Task 4D Radar-Camera Fusion Dataset and Benchmark for Autonomous Driving on Water Surfaces
Jul 13, 2023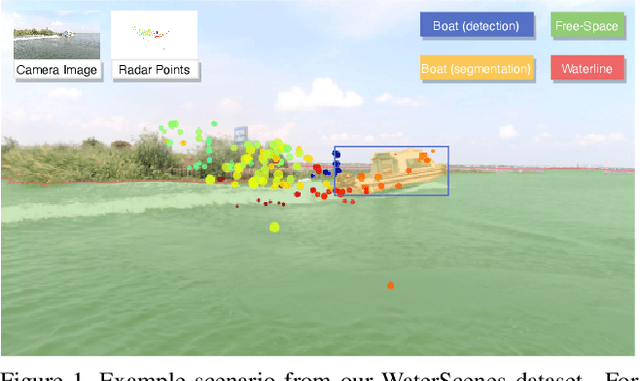


Autonomous driving on water surfaces plays an essential role in executing hazardous and time-consuming missions, such as maritime surveillance, survivors rescue, environmental monitoring, hydrography mapping and waste cleaning. This work presents WaterScenes, the first multi-task 4D radar-camera fusion dataset for autonomous driving on water surfaces. Equipped with a 4D radar and a monocular camera, our Unmanned Surface Vehicle (USV) proffers all-weather solutions for discerning object-related information, including color, shape, texture, range, velocity, azimuth, and elevation. Focusing on typical static and dynamic objects on water surfaces, we label the camera images and radar point clouds at pixel-level and point-level, respectively. In addition to basic perception tasks, such as object detection, instance segmentation and semantic segmentation, we also provide annotations for free-space segmentation and waterline segmentation. Leveraging the multi-task and multi-modal data, we conduct numerous experiments on the single modality of radar and camera, as well as the fused modalities. Results demonstrate that 4D radar-camera fusion can considerably enhance the robustness of perception on water surfaces, especially in adverse lighting and weather conditions. WaterScenes dataset is public on https://waterscenes.github.io.
MPR-Net:Multi-Scale Pattern Reproduction Guided Universality Time Series Interpretable Forecasting
Jul 13, 2023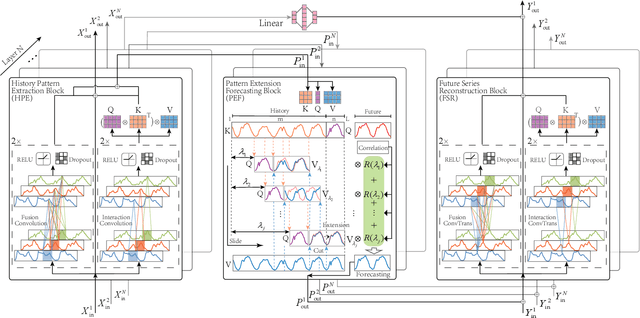
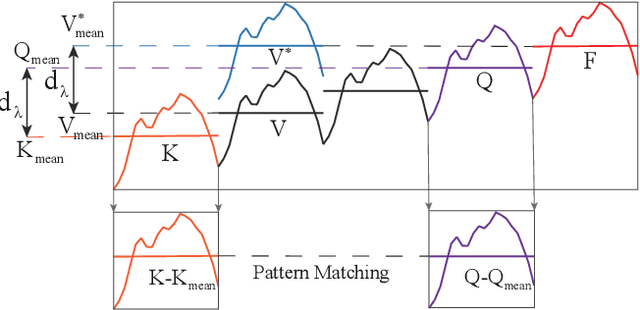
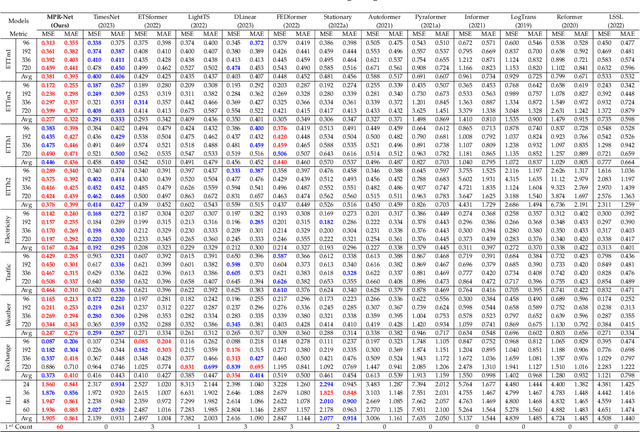
Time series forecasting has received wide interest from existing research due to its broad applications and inherent challenging. The research challenge lies in identifying effective patterns in historical series and applying them to future forecasting. Advanced models based on point-wise connected MLP and Transformer architectures have strong fitting power, but their secondary computational complexity limits practicality. Additionally, those structures inherently disrupt the temporal order, reducing the information utilization and making the forecasting process uninterpretable. To solve these problems, this paper proposes a forecasting model, MPR-Net. It first adaptively decomposes multi-scale historical series patterns using convolution operation, then constructs a pattern extension forecasting method based on the prior knowledge of pattern reproduction, and finally reconstructs future patterns into future series using deconvolution operation. By leveraging the temporal dependencies present in the time series, MPR-Net not only achieves linear time complexity, but also makes the forecasting process interpretable. By carrying out sufficient experiments on more than ten real data sets of both short and long term forecasting tasks, MPR-Net achieves the state of the art forecasting performance, as well as good generalization and robustness performance.
Complementary Frequency-Varying Awareness Network for Open-Set Fine-Grained Image Recognition
Jul 14, 2023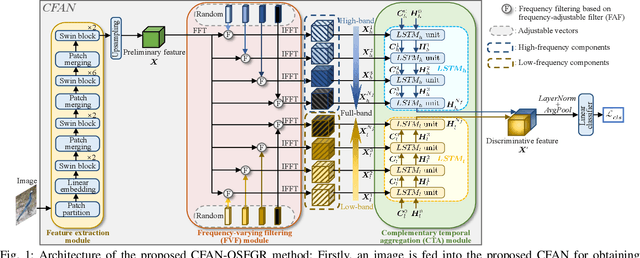
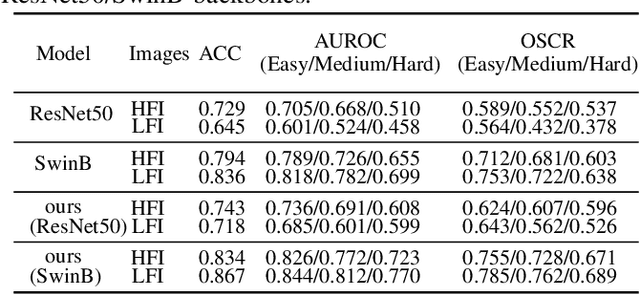
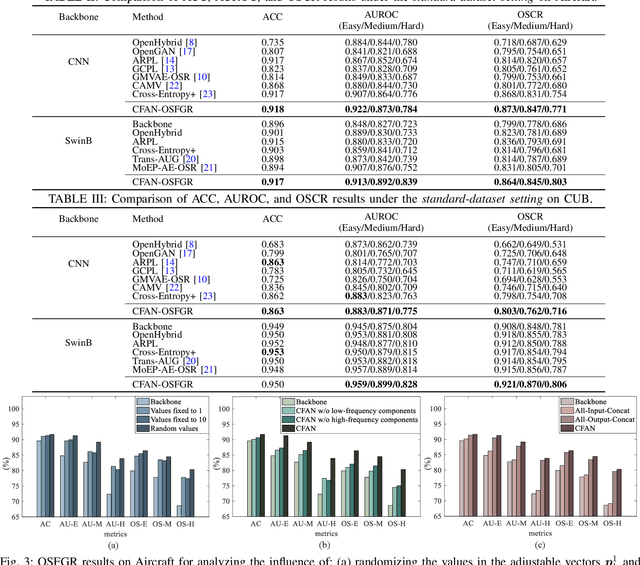
Open-set image recognition is a challenging topic in computer vision. Most of the existing works in literature focus on learning more discriminative features from the input images, however, they are usually insensitive to the high- or low-frequency components in features, resulting in a decreasing performance on fine-grained image recognition. To address this problem, we propose a Complementary Frequency-varying Awareness Network that could better capture both high-frequency and low-frequency information, called CFAN. The proposed CFAN consists of three sequential modules: (i) a feature extraction module is introduced for learning preliminary features from the input images; (ii) a frequency-varying filtering module is designed to separate out both high- and low-frequency components from the preliminary features in the frequency domain via a frequency-adjustable filter; (iii) a complementary temporal aggregation module is designed for aggregating the high- and low-frequency components via two Long Short-Term Memory networks into discriminative features. Based on CFAN, we further propose an open-set fine-grained image recognition method, called CFAN-OSFGR, which learns image features via CFAN and classifies them via a linear classifier. Experimental results on 3 fine-grained datasets and 2 coarse-grained datasets demonstrate that CFAN-OSFGR performs significantly better than 9 state-of-the-art methods in most cases.
Learning Sparse Neural Networks with Identity Layers
Jul 14, 2023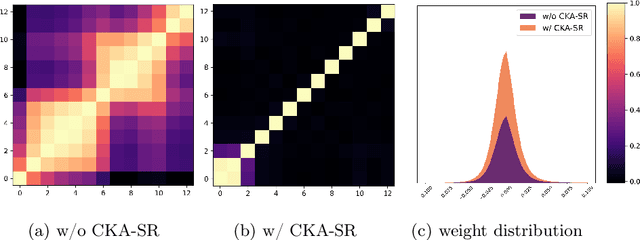
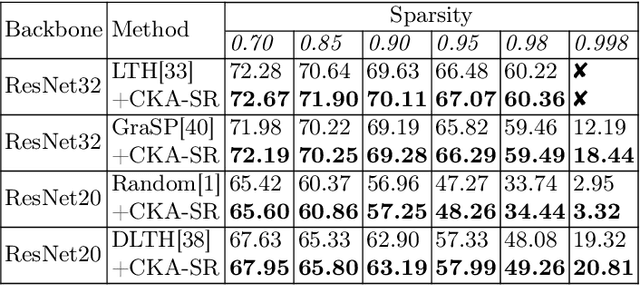
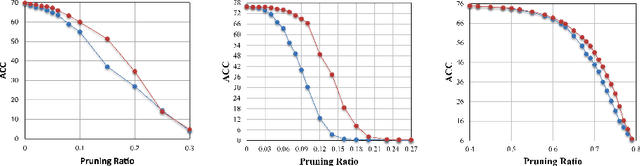
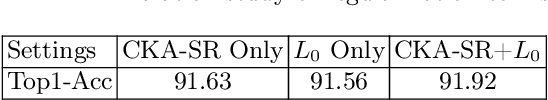
The sparsity of Deep Neural Networks is well investigated to maximize the performance and reduce the size of overparameterized networks as possible. Existing methods focus on pruning parameters in the training process by using thresholds and metrics. Meanwhile, feature similarity between different layers has not been discussed sufficiently before, which could be rigorously proved to be highly correlated to the network sparsity in this paper. Inspired by interlayer feature similarity in overparameterized models, we investigate the intrinsic link between network sparsity and interlayer feature similarity. Specifically, we prove that reducing interlayer feature similarity based on Centered Kernel Alignment (CKA) improves the sparsity of the network by using information bottleneck theory. Applying such theory, we propose a plug-and-play CKA-based Sparsity Regularization for sparse network training, dubbed CKA-SR, which utilizes CKA to reduce feature similarity between layers and increase network sparsity. In other words, layers of our sparse network tend to have their own identity compared to each other. Experimentally, we plug the proposed CKA-SR into the training process of sparse network training methods and find that CKA-SR consistently improves the performance of several State-Of-The-Art sparse training methods, especially at extremely high sparsity. Code is included in the supplementary materials.
SubT-MRS: A Subterranean, Multi-Robot, Multi-Spectral and Multi-Degraded Dataset for Robust SLAM
Jul 14, 2023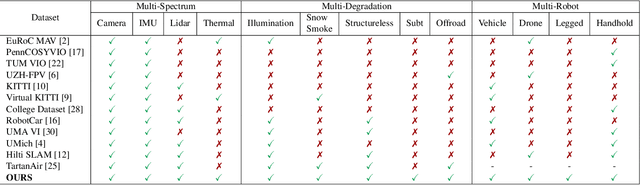

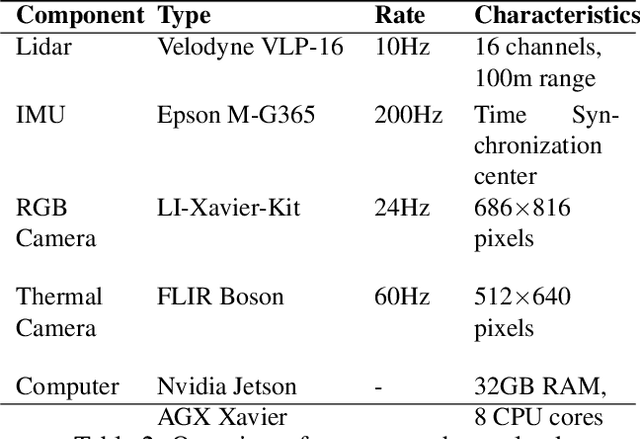

In recent years, significant progress has been made in the field of simultaneous localization and mapping (SLAM) research. However, current state-of-the-art solutions still struggle with limited accuracy and robustness in real-world applications. One major reason is the lack of datasets that fully capture the conditions faced by robots in the wild. To address this problem, we present SubT-MRS, an extremely challenging real-world dataset designed to push the limits of SLAM and perception algorithms. SubT-MRS is a multi-modal, multi-robot dataset collected mainly from subterranean environments having multi-degraded conditions including structureless corridors, varying lighting conditions, and perceptual obscurants such as smoke and dust. Furthermore, the dataset packages information from a diverse range of time-synchronized sensors, including LiDAR, visual cameras, thermal cameras, and IMUs captured using varied vehicular motions like aerial, legged, and wheeled, to support research in sensor fusion, which is essential for achieving accurate and robust robotic perception in complex environments. To evaluate the accuracy of SLAM systems, we also provide a dense 3D model with sub-centimeter-level accuracy, as well as accurate 6DoF ground truth. Our benchmarking approach includes several state-of-the-art methods to demonstrate the challenges our datasets introduce, particularly in the case of multi-degraded environments.
Predicting Music Hierarchies with a Graph-Based Neural Decoder
Jun 29, 2023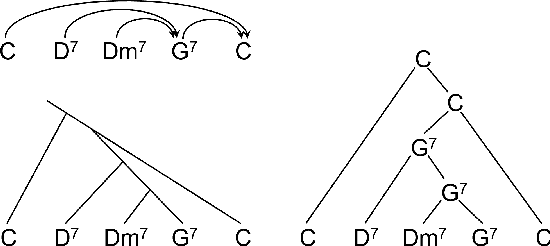
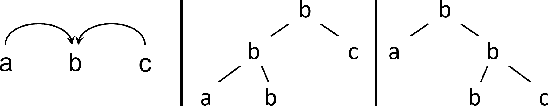
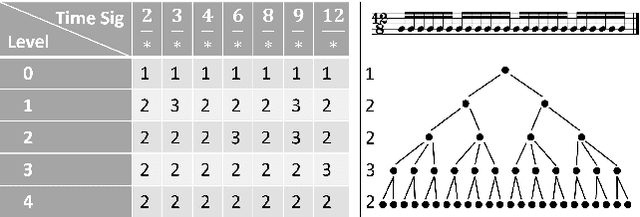
This paper describes a data-driven framework to parse musical sequences into dependency trees, which are hierarchical structures used in music cognition research and music analysis. The parsing involves two steps. First, the input sequence is passed through a transformer encoder to enrich it with contextual information. Then, a classifier filters the graph of all possible dependency arcs to produce the dependency tree. One major benefit of this system is that it can be easily integrated into modern deep-learning pipelines. Moreover, since it does not rely on any particular symbolic grammar, it can consider multiple musical features simultaneously, make use of sequential context information, and produce partial results for noisy inputs. We test our approach on two datasets of musical trees -- time-span trees of monophonic note sequences and harmonic trees of jazz chord sequences -- and show that our approach outperforms previous methods.
Exploring acceptance of autonomous vehicle policies using KeyBERT and SNA: Targeting engineering students
Jul 18, 2023
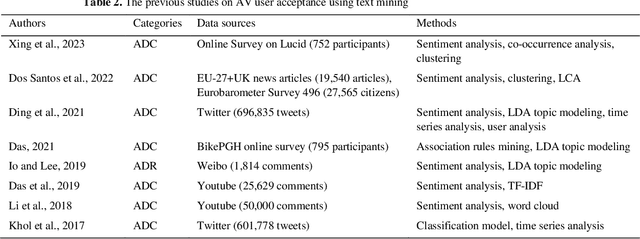
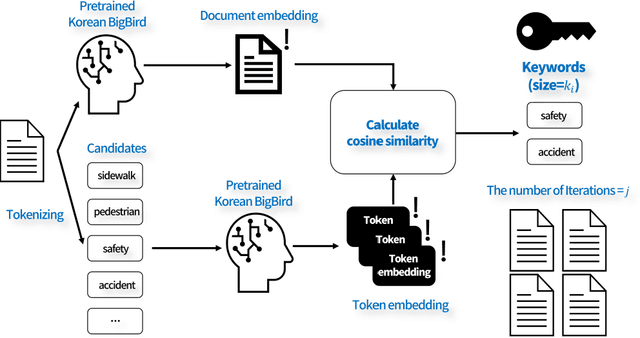
This study aims to explore user acceptance of Autonomous Vehicle (AV) policies with improved text-mining methods. Recently, South Korean policymakers have viewed Autonomous Driving Car (ADC) and Autonomous Driving Robot (ADR) as next-generation means of transportation that will reduce the cost of transporting passengers and goods. They support the construction of V2I and V2V communication infrastructures for ADC and recognize that ADR is equivalent to pedestrians to promote its deployment into sidewalks. To fill the gap where end-user acceptance of these policies is not well considered, this study applied two text-mining methods to the comments of graduate students in the fields of Industrial, Mechanical, and Electronics-Electrical-Computer. One is the Co-occurrence Network Analysis (CNA) based on TF-IWF and Dice coefficient, and the other is the Contextual Semantic Network Analysis (C-SNA) based on both KeyBERT, which extracts keywords that contextually represent the comments, and double cosine similarity. The reason for comparing these approaches is to balance interest not only in the implications for the AV policies but also in the need to apply quality text mining to this research domain. Significantly, the limitation of frequency-based text mining, which does not reflect textual context, and the trade-off of adjusting thresholds in Semantic Network Analysis (SNA) were considered. As the results of comparing the two approaches, the C-SNA provided the information necessary to understand users' voices using fewer nodes and features than the CNA. The users who pre-emptively understood the AV policies based on their engineering literacy and the given texts revealed potential risks of the AV accident policies. This study adds suggestions to manage these risks to support the successful deployment of AVs on public roads.
Oracle Efficient Online Multicalibration and Omniprediction
Jul 18, 2023A recent line of work has shown a surprising connection between multicalibration, a multi-group fairness notion, and omniprediction, a learning paradigm that provides simultaneous loss minimization guarantees for a large family of loss functions. Prior work studies omniprediction in the batch setting. We initiate the study of omniprediction in the online adversarial setting. Although there exist algorithms for obtaining notions of multicalibration in the online adversarial setting, unlike batch algorithms, they work only for small finite classes of benchmark functions $F$, because they require enumerating every function $f \in F$ at every round. In contrast, omniprediction is most interesting for learning theoretic hypothesis classes $F$, which are generally continuously large. We develop a new online multicalibration algorithm that is well defined for infinite benchmark classes $F$, and is oracle efficient (i.e. for any class $F$, the algorithm has the form of an efficient reduction to a no-regret learning algorithm for $F$). The result is the first efficient online omnipredictor -- an oracle efficient prediction algorithm that can be used to simultaneously obtain no regret guarantees to all Lipschitz convex loss functions. For the class $F$ of linear functions, we show how to make our algorithm efficient in the worst case. Also, we show upper and lower bounds on the extent to which our rates can be improved: our oracle efficient algorithm actually promises a stronger guarantee called swap-omniprediction, and we prove a lower bound showing that obtaining $O(\sqrt{T})$ bounds for swap-omniprediction is impossible in the online setting. On the other hand, we give a (non-oracle efficient) algorithm which can obtain the optimal $O(\sqrt{T})$ omniprediction bounds without going through multicalibration, giving an information theoretic separation between these two solution concepts.
Choosing Well Your Opponents: How to Guide the Synthesis of Programmatic Strategies
Jul 10, 2023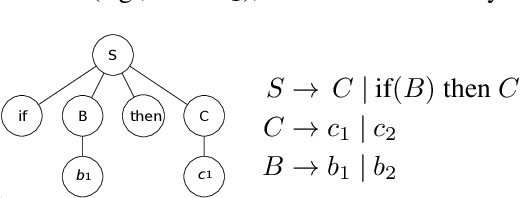

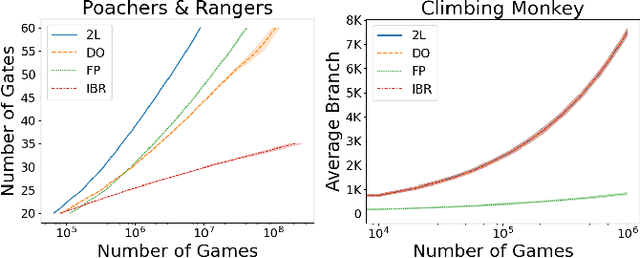
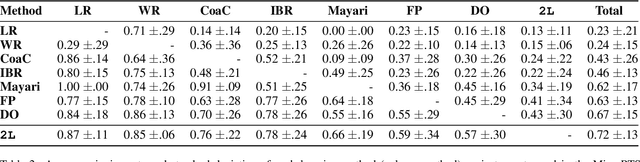
This paper introduces Local Learner (2L), an algorithm for providing a set of reference strategies to guide the search for programmatic strategies in two-player zero-sum games. Previous learning algorithms, such as Iterated Best Response (IBR), Fictitious Play (FP), and Double-Oracle (DO), can be computationally expensive or miss important information for guiding search algorithms. 2L actively selects a set of reference strategies to improve the search signal. We empirically demonstrate the advantages of our approach while guiding a local search algorithm for synthesizing strategies in three games, including MicroRTS, a challenging real-time strategy game. Results show that 2L learns reference strategies that provide a stronger search signal than IBR, FP, and DO. We also simulate a tournament of MicroRTS, where a synthesizer using 2L outperformed the winners of the two latest MicroRTS competitions, which were programmatic strategies written by human programmers.