 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMistake-Bounded Language Generation
May 11, 2026We investigate the learning task of language generation in the limit, but shift focus from the traditional time-of-last-mistake metric of a generator's success to a new notion of "mistake-bounded generation." While existing results for language generation in the limit focus on guaranteeing eventual consistency, they are blind to the cumulative error incurred during the learning process. We address this by shifting the goal to minimizing the total number of invalid elements output by a generation algorithm. We establish a formal reduction to the Learning from Correct Demonstrations framework of Joshi et al. (2025), enabling a general recipe for deriving mistake bounds via weighted update rules. For finite classes, we provide an algorithm that simultaneously achieves an optimal last-mistake time of $\mathsf{Cdim}(L)$ and a mistake bound of $\lfloor \log_2 |L| \rfloor$, whereas for the non-uniform setting of countably infinite streams of languages, we prove a fundamental trade-off: achieving logarithmic mistakes $O(\log i)$ necessarily precludes convergence guarantees established in prior work. Finally, we show that our framework can be extended to accommodate noisy adversaries and guarantee mistake bounds that scale with the adversary's suboptimality.
On the Impossibility of Separating Intelligence from Judgment: The Computational Intractability of Filtering for AI Alignment
Jul 09, 2025With the increased deployment of large language models (LLMs), one concern is their potential misuse for generating harmful content. Our work studies the alignment challenge, with a focus on filters to prevent the generation of unsafe information. Two natural points of intervention are the filtering of the input prompt before it reaches the model, and filtering the output after generation. Our main results demonstrate computational challenges in filtering both prompts and outputs. First, we show that there exist LLMs for which there are no efficient prompt filters: adversarial prompts that elicit harmful behavior can be easily constructed, which are computationally indistinguishable from benign prompts for any efficient filter. Our second main result identifies a natural setting in which output filtering is computationally intractable. All of our separation results are under cryptographic hardness assumptions. In addition to these core findings, we also formalize and study relaxed mitigation approaches, demonstrating further computational barriers. We conclude that safety cannot be achieved by designing filters external to the LLM internals (architecture and weights); in particular, black-box access to the LLM will not suffice. Based on our technical results, we argue that an aligned AI system's intelligence cannot be separated from its judgment.
Representative Language Generation
May 27, 2025We introduce "representative generation," extending the theoretical framework for generation proposed by Kleinberg et al. (2024) and formalized by Li et al. (2024), to additionally address diversity and bias concerns in generative models. Our notion requires outputs of a generative model to proportionally represent groups of interest from the training data. We characterize representative uniform and non-uniform generation, introducing the "group closure dimension" as a key combinatorial quantity. For representative generation in the limit, we analyze both information-theoretic and computational aspects, demonstrating feasibility for countably infinite hypothesis classes and collections of groups under certain conditions, but proving a negative result for computability using only membership queries. This contrasts with Kleinberg et al.'s (2024) positive results for standard generation in the limit. Our findings provide a rigorous foundation for developing more diverse and representative generative models.
Accuracy vs. Accuracy: Computational Tradeoffs Between Classification Rates and Utility
May 22, 2025We revisit the foundations of fairness and its interplay with utility and efficiency in settings where the training data contain richer labels, such as individual types, rankings, or risk estimates, rather than just binary outcomes. In this context, we propose algorithms that achieve stronger notions of evidence-based fairness than are possible in standard supervised learning. Our methods support classification and ranking techniques that preserve accurate subpopulation classification rates, as suggested by the underlying data distributions, across a broad class of classification rules and downstream applications. Furthermore, our predictors enable loss minimization, whether aimed at maximizing utility or in the service of fair treatment. Complementing our algorithmic contributions, we present impossibility results demonstrating that simultaneously achieving accurate classification rates and optimal loss minimization is, in some cases, computationally infeasible. Unlike prior impossibility results, our notions are not inherently in conflict and are simultaneously satisfied by the Bayes-optimal predictor. Furthermore, we show that each notion can be satisfied individually via efficient learning. Our separation thus stems from the computational hardness of learning a sufficiently good approximation of the Bayes-optimal predictor. These computational impossibilities present a choice between two natural and attainable notions of accuracy that could both be motivated by fairness.
How Global Calibration Strengthens Multiaccuracy
Apr 21, 2025


Multiaccuracy and multicalibration are multigroup fairness notions for prediction that have found numerous applications in learning and computational complexity. They can be achieved from a single learning primitive: weak agnostic learning. Here we investigate the power of multiaccuracy as a learning primitive, both with and without the additional assumption of calibration. We find that multiaccuracy in itself is rather weak, but that the addition of global calibration (this notion is called calibrated multiaccuracy) boosts its power substantially, enough to recover implications that were previously known only assuming the stronger notion of multicalibration. We give evidence that multiaccuracy might not be as powerful as standard weak agnostic learning, by showing that there is no way to post-process a multiaccurate predictor to get a weak learner, even assuming the best hypothesis has correlation $1/2$. Rather, we show that it yields a restricted form of weak agnostic learning, which requires some concept in the class to have correlation greater than $1/2$ with the labels. However, by also requiring the predictor to be calibrated, we recover not just weak, but strong agnostic learning. A similar picture emerges when we consider the derivation of hardcore measures from predictors satisfying multigroup fairness notions. On the one hand, while multiaccuracy only yields hardcore measures of density half the optimal, we show that (a weighted version of) calibrated multiaccuracy achieves optimal density. Our results yield new insights into the complementary roles played by multiaccuracy and calibration in each setting. They shed light on why multiaccuracy and global calibration, although not particularly powerful by themselves, together yield considerably stronger notions.
Oracle Efficient Online Multicalibration and Omniprediction
Jul 18, 2023A recent line of work has shown a surprising connection between multicalibration, a multi-group fairness notion, and omniprediction, a learning paradigm that provides simultaneous loss minimization guarantees for a large family of loss functions. Prior work studies omniprediction in the batch setting. We initiate the study of omniprediction in the online adversarial setting. Although there exist algorithms for obtaining notions of multicalibration in the online adversarial setting, unlike batch algorithms, they work only for small finite classes of benchmark functions $F$, because they require enumerating every function $f \in F$ at every round. In contrast, omniprediction is most interesting for learning theoretic hypothesis classes $F$, which are generally continuously large. We develop a new online multicalibration algorithm that is well defined for infinite benchmark classes $F$, and is oracle efficient (i.e. for any class $F$, the algorithm has the form of an efficient reduction to a no-regret learning algorithm for $F$). The result is the first efficient online omnipredictor -- an oracle efficient prediction algorithm that can be used to simultaneously obtain no regret guarantees to all Lipschitz convex loss functions. For the class $F$ of linear functions, we show how to make our algorithm efficient in the worst case. Also, we show upper and lower bounds on the extent to which our rates can be improved: our oracle efficient algorithm actually promises a stronger guarantee called swap-omniprediction, and we prove a lower bound showing that obtaining $O(\sqrt{T})$ bounds for swap-omniprediction is impossible in the online setting. On the other hand, we give a (non-oracle efficient) algorithm which can obtain the optimal $O(\sqrt{T})$ omniprediction bounds without going through multicalibration, giving an information theoretic separation between these two solution concepts.
Dissenting Explanations: Leveraging Disagreement to Reduce Model Overreliance
Jul 14, 2023



While explainability is a desirable characteristic of increasingly complex black-box models, modern explanation methods have been shown to be inconsistent and contradictory. The semantics of explanations is not always fully understood - to what extent do explanations "explain" a decision and to what extent do they merely advocate for a decision? Can we help humans gain insights from explanations accompanying correct predictions and not over-rely on incorrect predictions advocated for by explanations? With this perspective in mind, we introduce the notion of dissenting explanations: conflicting predictions with accompanying explanations. We first explore the advantage of dissenting explanations in the setting of model multiplicity, where multiple models with similar performance may have different predictions. In such cases, providing dissenting explanations could be done by invoking the explanations of disagreeing models. Through a pilot study, we demonstrate that dissenting explanations reduce overreliance on model predictions, without reducing overall accuracy. Motivated by the utility of dissenting explanations we present both global and local methods for their generation.
Generative Models of Huge Objects
Feb 24, 2023
This work initiates the systematic study of explicit distributions that are indistinguishable from a single exponential-size combinatorial object. In this we extend the work of Goldreich, Goldwasser and Nussboim (SICOMP 2010) that focused on the implementation of huge objects that are indistinguishable from the uniform distribution, satisfying some global properties (which they coined truthfulness). Indistinguishability from a single object is motivated by the study of generative models in learning theory and regularity lemmas in graph theory. Problems that are well understood in the setting of pseudorandomness present significant challenges and at times are impossible when considering generative models of huge objects. We demonstrate the versatility of this study by providing a learning algorithm for huge indistinguishable objects in several natural settings including: dense functions and graphs with a truthfulness requirement on the number of ones in the function or edges in the graphs, and a version of the weak regularity lemma for sparse graphs that satisfy some global properties. These and other results generalize basic pseudorandom objects as well as notions introduced in algorithmic fairness. The results rely on notions and techniques from a variety of areas including learning theory, complexity theory, cryptography, and game theory.
Characterizing notions of omniprediction via multicalibration
Feb 13, 2023


A recent line of work shows that notions of multigroup fairness imply surprisingly strong notions of omniprediction: loss minimization guarantees that apply not just for a specific loss function, but for any loss belonging to a large family of losses. While prior work has derived various notions of omniprediction from multigroup fairness guarantees of varying strength, it was unknown whether the connection goes in both directions. In this work, we answer this question in the affirmative, establishing equivalences between notions of multicalibration and omniprediction. The new definitions that hold the key to this equivalence are new notions of swap omniprediction, which are inspired by swap regret in online learning. We show that these can be characterized exactly by a strengthening of multicalibration that we refer to as swap multicalibration. One can go from standard to swap multicalibration by a simple discretization; moreover all known algorithms for standard multicalibration in fact give swap multicalibration. In the context of omniprediction though, introducing the notion of swapping results in provably stronger notions, which require a predictor to minimize expected loss at least as well as an adaptive adversary who can choose both the loss function and hypothesis based on the value predicted by the predictor. Building on these characterizations, we paint a complete picture of the relationship between the various omniprediction notions in the literature by establishing implications and separations between them. Our work deepens our understanding of the connections between multigroup fairness, loss minimization and outcome indistinguishability and establishes new connections to classic notions in online learning.
Loss Minimization through the Lens of Outcome Indistinguishability
Oct 16, 2022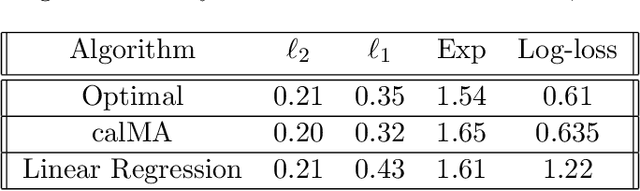


We present a new perspective on loss minimization and the recent notion of Omniprediction through the lens of Outcome Indistingusihability. For a collection of losses and hypothesis class, omniprediction requires that a predictor provide a loss-minimization guarantee simultaneously for every loss in the collection compared to the best (loss-specific) hypothesis in the class. We present a generic template to learn predictors satisfying a guarantee we call Loss Outcome Indistinguishability. For a set of statistical tests--based on a collection of losses and hypothesis class--a predictor is Loss OI if it is indistinguishable (according to the tests) from Nature's true probabilities over outcomes. By design, Loss OI implies omniprediction in a direct and intuitive manner. We simplify Loss OI further, decomposing it into a calibration condition plus multiaccuracy for a class of functions derived from the loss and hypothesis classes. By careful analysis of this class, we give efficient constructions of omnipredictors for interesting classes of loss functions, including non-convex losses. This decomposition highlights the utility of a new multi-group fairness notion that we call calibrated multiaccuracy, which lies in between multiaccuracy and multicalibration. We show that calibrated multiaccuracy implies Loss OI for the important set of convex losses arising from Generalized Linear Models, without requiring full multicalibration. For such losses, we show an equivalence between our computational notion of Loss OI and a geometric notion of indistinguishability, formulated as Pythagorean theorems in the associated Bregman divergence. We give an efficient algorithm for calibrated multiaccuracy with computational complexity comparable to that of multiaccuracy. In all, calibrated multiaccuracy offers an interesting tradeoff point between efficiency and generality in the omniprediction landscape.