 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentification of Stochasticity by Matrix-decomposition: Applied on Black Hole Data
Jul 15, 2023Timeseries classification as stochastic (noise-like) or non-stochastic (structured), helps understand the underlying dynamics, in several domains. Here we propose a two-legged matrix decomposition-based algorithm utilizing two complementary techniques for classification. In Singular Value Decomposition (SVD) based analysis leg, we perform topological analysis (Betti numbers) on singular vectors containing temporal information, leading to SVD-label. Parallely, temporal-ordering agnostic Principal Component Analysis (PCA) is performed, and the proposed PCA-derived features are computed. These features, extracted from synthetic timeseries of the two labels, are observed to map the timeseries to a linearly separable feature space. Support Vector Machine (SVM) is used to produce PCA-label. The proposed methods have been applied to synthetic data, comprising 41 realisations of white-noise, pink-noise (stochastic), Logistic-map at growth-rate 4 and Lorentz-system (non-stochastic), as proof-of-concept. Proposed algorithm is applied on astronomical data: 12 temporal-classes of timeseries of black hole GRS 1915+105, obtained from RXTE satellite with average length 25000. For a given timeseries, if SVD-label and PCA-label concur, then the label is retained; else deemed "Uncertain". Comparison of obtained results with those in literature are presented. It's found that out of 12 temporal classes of GRS 1915+105, concurrence between SVD-label and PCA-label is obtained on 11 of them.
Using Topological Framework for the Design of Activation Function and Model Pruning in Deep Neural Networks
Sep 03, 2021

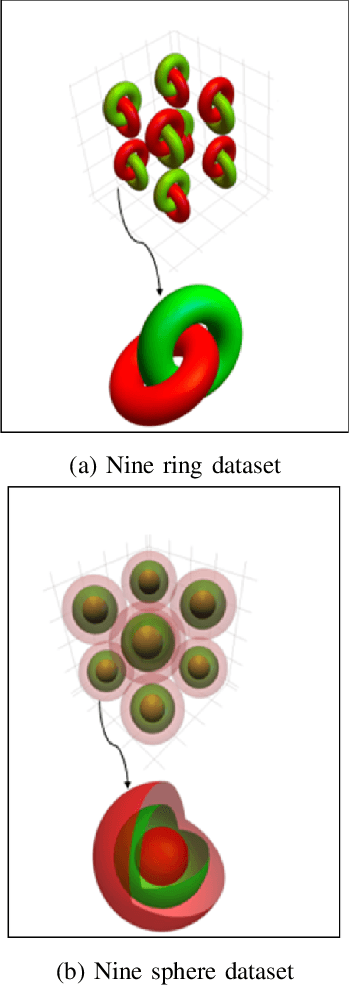
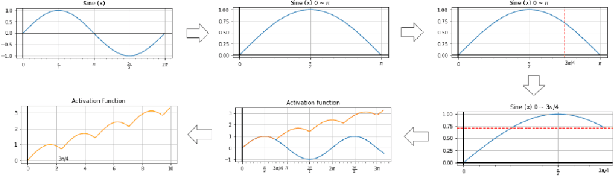
Success of deep neural networks in diverse tasks across domains of computer vision, speech recognition and natural language processing, has necessitated understanding the dynamics of training process and also working of trained models. Two independent contributions of this paper are 1) Novel activation function for faster training convergence 2) Systematic pruning of filters of models trained irrespective of activation function. We analyze the topological transformation of the space of training samples as it gets transformed by each successive layer during training, by changing the activation function. The impact of changing activation function on the convergence during training is reported for the task of binary classification. A novel activation function aimed at faster convergence for classification tasks is proposed. Here, Betti numbers are used to quantify topological complexity of data. Results of experiments on popular synthetic binary classification datasets with large Betti numbers(>150) using MLPs are reported. Results show that the proposed activation function results in faster convergence requiring fewer epochs by a factor of 1.5 to 2, since Betti numbers reduce faster across layers with the proposed activation function. The proposed methodology was verified on benchmark image datasets: fashion MNIST, CIFAR-10 and cat-vs-dog images, using CNNs. Based on empirical results, we propose a novel method for pruning a trained model. The trained model was pruned by eliminating filters that transform data to a topological space with large Betti numbers. All filters with Betti numbers greater than 300 were removed from each layer without significant reduction in accuracy. This resulted in faster prediction time and reduced memory size of the model.
Towards Learning a Vocabulary of Visual Concepts and Operators using Deep Neural Networks
Sep 01, 2021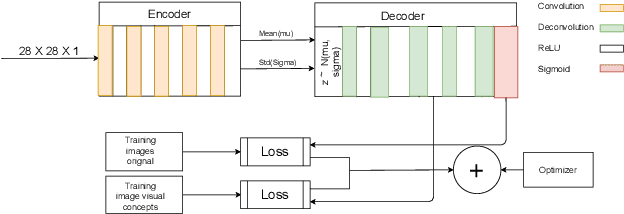


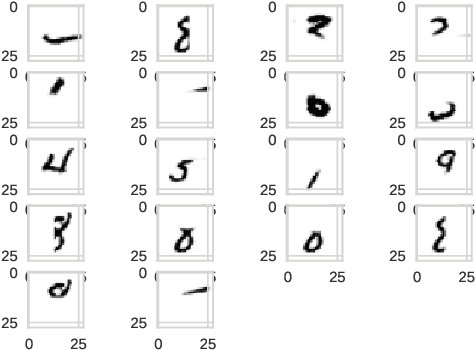
Deep neural networks have become the default choice for many applications like image and video recognition, segmentation and other image and video related tasks.However, a critical challenge with these models is the lack of explainability.This requirement of generating explainable predictions has motivated the research community to perform various analysis on trained models.In this study, we analyze the learned feature maps of trained models using MNIST images for achieving more explainable predictions.Our study is focused on deriving a set of primitive elements, here called visual concepts, that can be used to generate any arbitrary sample from the data generating distribution.We derive the primitive elements from the feature maps learned by the model.We illustrate the idea by generating visual concepts from a Variational Autoencoder trained using MNIST images.We augment the training data of MNIST dataset by adding about 60,000 new images generated with visual concepts chosen at random.With this we were able to reduce the reconstruction loss (mean square error) from an initial value of 120 without augmentation to 60 with augmentation.Our approach is a first step towards the final goal of achieving trained deep neural network models whose predictions, features in hidden layers and the learned filters can be well explained.Such a model when deployed in production can easily be modified to adapt to new data, whereas existing deep learning models need a re training or fine tuning. This process again needs a huge number of data samples that are not easy to generate unless the model has good explainability.