 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep Learning-Based Prediction of Fractional Flow Reserve along the Coronary Artery
Aug 09, 2023
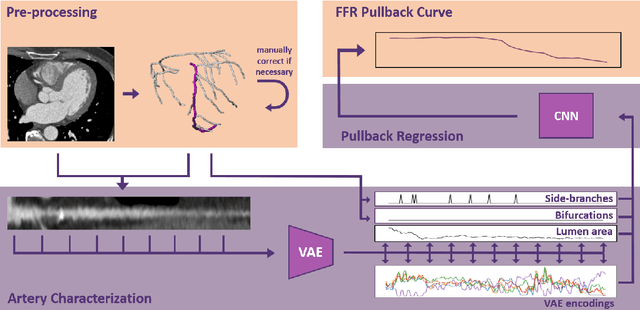
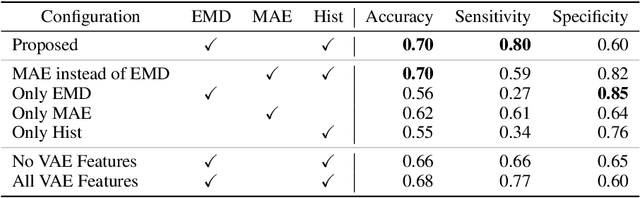
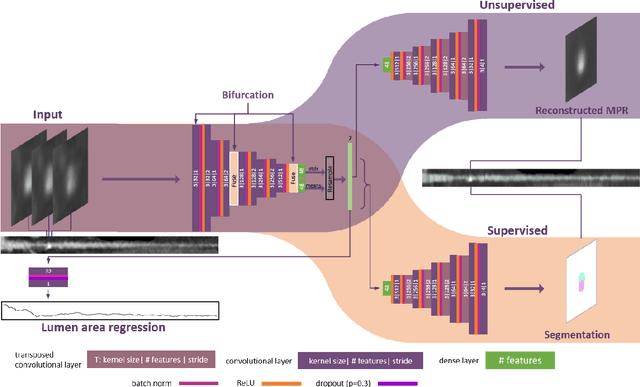
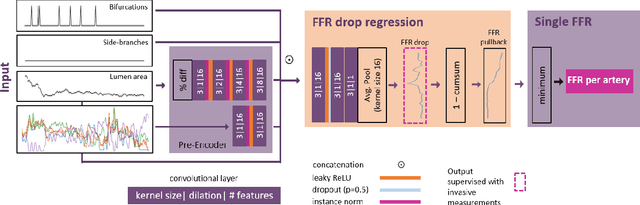
Functionally significant coronary artery disease (CAD) is caused by plaque buildup in the coronary arteries, potentially leading to narrowing of the arterial lumen, i.e. coronary stenosis, that significantly obstructs blood flow to the myocardium. The current reference for establishing the presence of a functionally significant stenosis is invasive fractional flow reserve (FFR) measurement. To avoid invasive measurements, non-invasive prediction of FFR from coronary CT angiography (CCTA) has emerged. For this, machine learning approaches, characterized by fast inference, are increasingly developed. However, these methods predict a single FFR value per artery i.e. they don't provide information about the stenosis location or treatment strategy. We propose a deep learning-based method to predict the FFR along the artery from CCTA scans. This study includes CCTA images of 110 patients who underwent invasive FFR pullback measurement in 112 arteries. First, a multi planar reconstruction (MPR) of the artery is fed to a variational autoencoder to characterize the artery, i.e. through the lumen area and unsupervised artery encodings. Thereafter, a convolutional neural network (CNN) predicts the FFR along the artery. The CNN is supervised by multiple loss functions, notably a loss function inspired by the Earth Mover's Distance (EMD) to predict the correct location of FFR drops and a histogram-based loss to explicitly supervise the slope of the FFR curve. To train and evaluate our model, eight-fold cross-validation was performed. The resulting FFR curves show good agreement with the reference allowing the distinction between diffuse and focal CAD distributions in most cases. Quantitative evaluation yielded a mean absolute difference in the area under the FFR pullback curve (AUPC) of 1.7. The method may pave the way towards fast, accurate, automatic prediction of FFR along the artery from CCTA.
ROFusion: Efficient Object Detection using Hybrid Point-wise Radar-Optical Fusion
Jul 17, 2023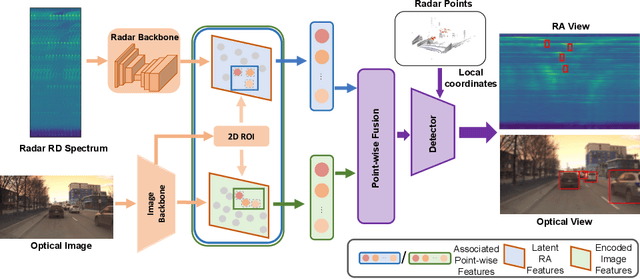
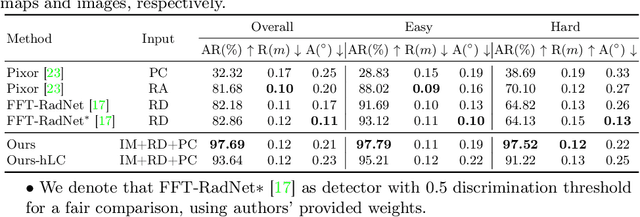
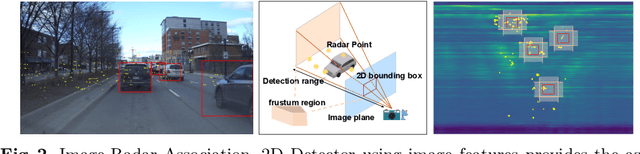
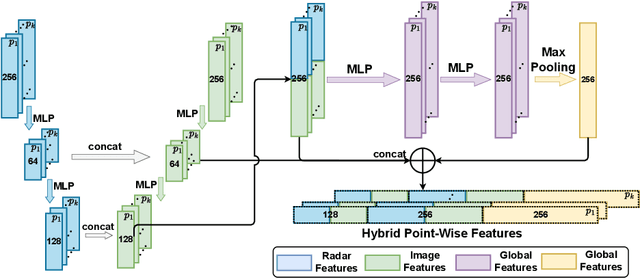
Radars, due to their robustness to adverse weather conditions and ability to measure object motions, have served in autonomous driving and intelligent agents for years. However, Radar-based perception suffers from its unintuitive sensing data, which lack of semantic and structural information of scenes. To tackle this problem, camera and Radar sensor fusion has been investigated as a trending strategy with low cost, high reliability and strong maintenance. While most recent works explore how to explore Radar point clouds and images, rich contextual information within Radar observation are discarded. In this paper, we propose a hybrid point-wise Radar-Optical fusion approach for object detection in autonomous driving scenarios. The framework benefits from dense contextual information from both the range-doppler spectrum and images which are integrated to learn a multi-modal feature representation. Furthermore, we propose a novel local coordinate formulation, tackling the object detection task in an object-centric coordinate. Extensive results show that with the information gained from optical images, we could achieve leading performance in object detection (97.69\% recall) compared to recent state-of-the-art methods FFT-RadNet (82.86\% recall). Ablation studies verify the key design choices and practicability of our approach given machine generated imperfect detections. The code will be available at https://github.com/LiuLiu-55/ROFusion.
Towards Precise Weakly Supervised Object Detection via Interactive Contrastive Learning of Context Information
May 05, 2023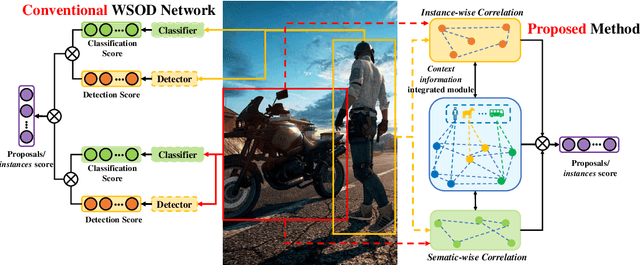
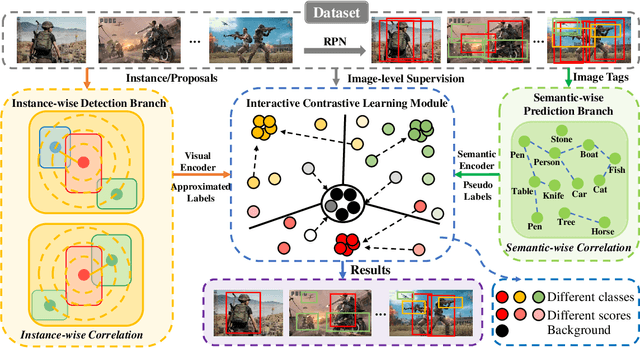
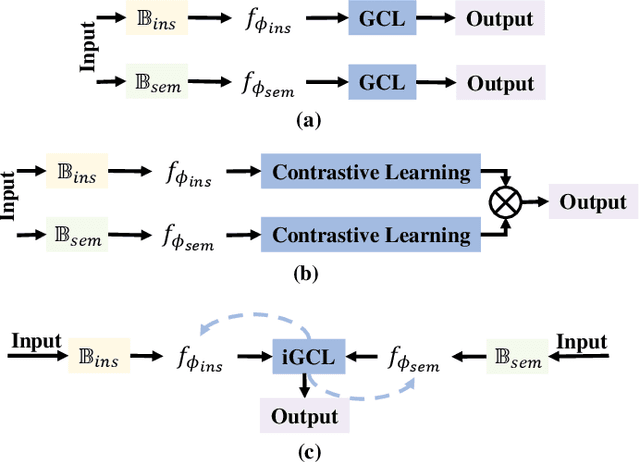

Weakly supervised object detection (WSOD) aims at learning precise object detectors with only image-level tags. In spite of intensive research on deep learning (DL) approaches over the past few years, there is still a significant performance gap between WSOD and fully supervised object detection. In fact, most existing WSOD methods only consider the visual appearance of each region proposal but ignore employing the useful context information in the image. To this end, this paper proposes an interactive end-to-end WSDO framework called JLWSOD with two innovations: i) two types of WSOD-specific context information (i.e., instance-wise correlation andsemantic-wise correlation) are proposed and introduced into WSOD framework; ii) an interactive graph contrastive learning (iGCL) mechanism is designed to jointly optimize the visual appearance and context information for better WSOD performance. Specifically, the iGCL mechanism takes full advantage of the complementary interpretations of the WSOD, namely instance-wise detection and semantic-wise prediction tasks, forming a more comprehensive solution. Extensive experiments on the widely used PASCAL VOC and MS COCO benchmarks verify the superiority of JLWSOD over alternative state-of-the-art approaches and baseline models (improvement of 3.6%~23.3% on mAP and 3.4%~19.7% on CorLoc, respectively).
RCM-Fusion: Radar-Camera Multi-Level Fusion for 3D Object Detection
Jul 27, 2023
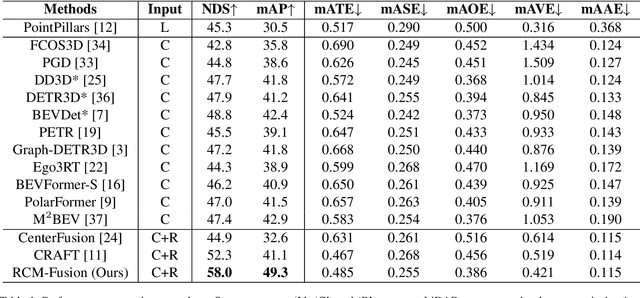
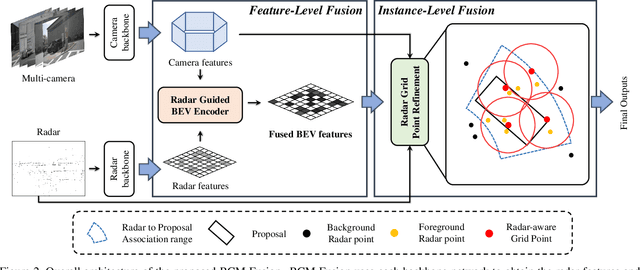
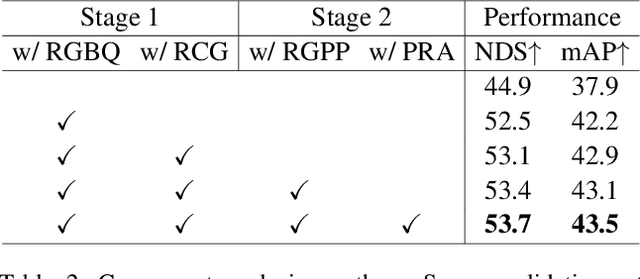
While LiDAR sensors have been succesfully applied to 3D object detection, the affordability of radar and camera sensors has led to a growing interest in fusiong radars and cameras for 3D object detection. However, previous radar-camera fusion models have not been able to fully utilize radar information in that initial 3D proposals were generated based on the camera features only and the instance-level fusion is subsequently conducted. In this paper, we propose radar-camera multi-level fusion (RCM-Fusion), which fuses radar and camera modalities at both the feature-level and instance-level to fully utilize radar information. At the feature-level, we propose a Radar Guided BEV Encoder which utilizes radar Bird's-Eye-View (BEV) features to transform image features into precise BEV representations and then adaptively combines the radar and camera BEV features. At the instance-level, we propose a Radar Grid Point Refinement module that reduces localization error by considering the characteristics of the radar point clouds. The experiments conducted on the public nuScenes dataset demonstrate that our proposed RCM-Fusion offers 11.8% performance gain in nuScenes detection score (NDS) over the camera-only baseline model and achieves state-of-the-art performaces among radar-camera fusion methods in the nuScenes 3D object detection benchmark. Code will be made publicly available.
Multi-scale Alternated Attention Transformer for Generalized Stereo Matching
Aug 06, 2023
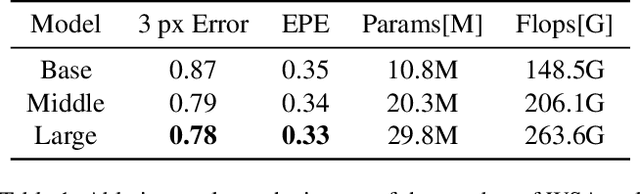
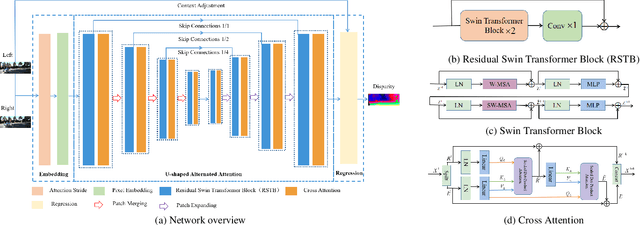
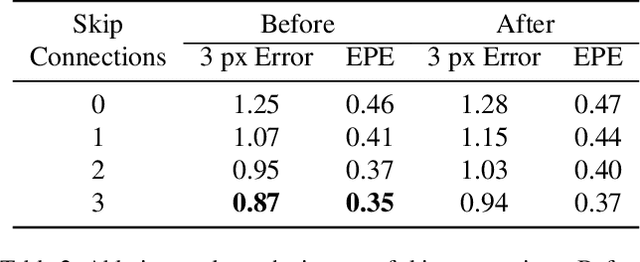
Recent stereo matching networks achieves dramatic performance by introducing epipolar line constraint to limit the matching range of dual-view. However, in complicated real-world scenarios, the feature information based on intra-epipolar line alone is too weak to facilitate stereo matching. In this paper, we present a simple but highly effective network called Alternated Attention U-shaped Transformer (AAUformer) to balance the impact of epipolar line in dual and single view respectively for excellent generalization performance. Compared to other models, our model has several main designs: 1) to better liberate the local semantic features of the single-view at pixel level, we introduce window self-attention to break the limits of intra-row self-attention and completely replace the convolutional network for denser features before cross-matching; 2) the multi-scale alternated attention backbone network was designed to extract invariant features in order to achieves the coarse-to-fine matching process for hard-to-discriminate regions. We performed a series of both comparative studies and ablation studies on several mainstream stereo matching datasets. The results demonstrate that our model achieves state-of-the-art on the Scene Flow dataset, and the fine-tuning performance is competitive on the KITTI 2015 dataset. In addition, for cross generalization experiments on synthetic and real-world datasets, our model outperforms several state-of-the-art works.
Class-relation Knowledge Distillation for Novel Class Discovery
Aug 06, 2023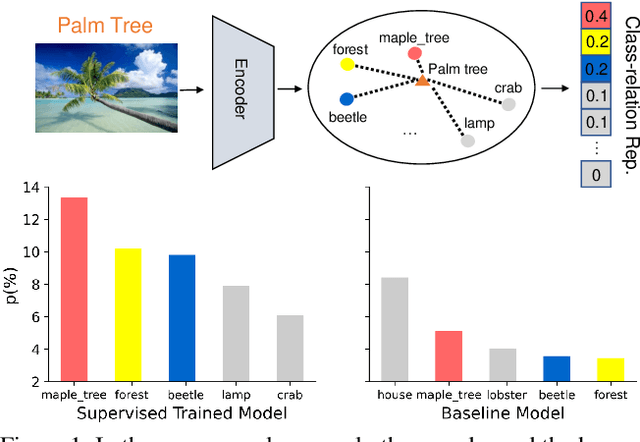
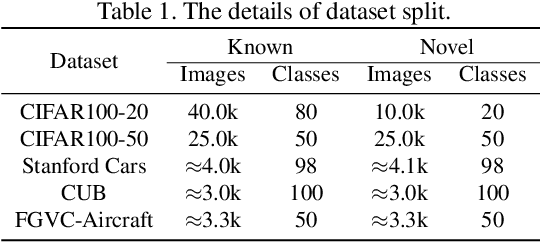
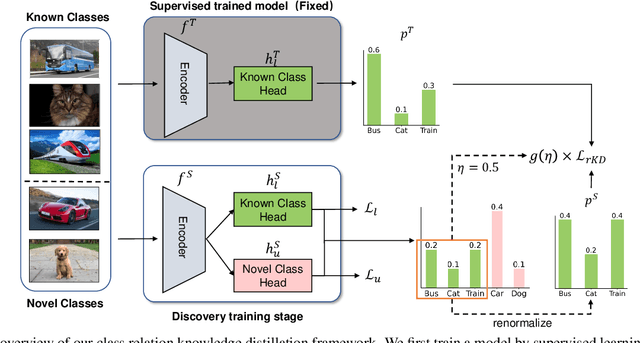
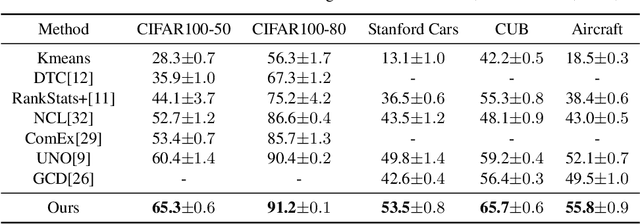
We tackle the problem of novel class discovery, which aims to learn novel classes without supervision based on labeled data from known classes. A key challenge lies in transferring the knowledge in the known-class data to the learning of novel classes. Previous methods mainly focus on building a shared representation space for knowledge transfer and often ignore modeling class relations. To address this, we introduce a class relation representation for the novel classes based on the predicted class distribution of a model trained on known classes. Empirically, we find that such class relation becomes less informative during typical discovery training. To prevent such information loss, we propose a novel knowledge distillation framework, which utilizes our class-relation representation to regularize the learning of novel classes. In addition, to enable a flexible knowledge distillation scheme for each data point in novel classes, we develop a learnable weighting function for the regularization, which adaptively promotes knowledge transfer based on the semantic similarity between the novel and known classes. To validate the effectiveness and generalization of our method, we conduct extensive experiments on multiple benchmarks, including CIFAR100, Stanford Cars, CUB, and FGVC-Aircraft datasets. Our results demonstrate that the proposed method outperforms the previous state-of-the-art methods by a significant margin on almost all benchmarks. Code is available at \href{https://github.com/kleinzcy/Cr-KD-NCD}{here}.
MatSpectNet: Material Segmentation Network with Domain-Aware and Physically-Constrained Hyperspectral Reconstruction
Aug 06, 2023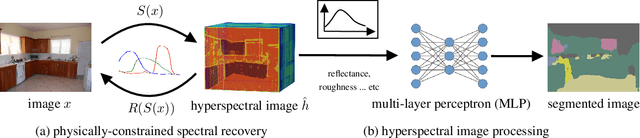

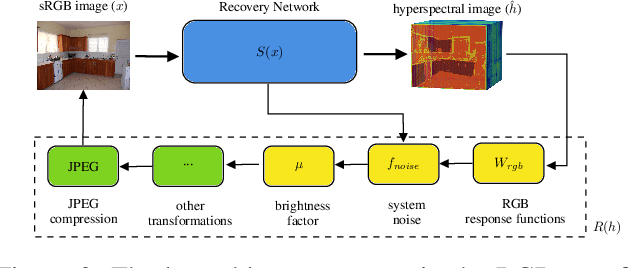

Achieving accurate material segmentation for 3-channel RGB images is challenging due to the considerable variation in a material's appearance. Hyperspectral images, which are sets of spectral measurements sampled at multiple wavelengths, theoretically offer distinct information for material identification, as variations in intensity of electromagnetic radiation reflected by a surface depend on the material composition of a scene. However, existing hyperspectral datasets are impoverished regarding the number of images and material categories for the dense material segmentation task, and collecting and annotating hyperspectral images with a spectral camera is prohibitively expensive. To address this, we propose a new model, the MatSpectNet to segment materials with recovered hyperspectral images from RGB images. The network leverages the principles of colour perception in modern cameras to constrain the reconstructed hyperspectral images and employs the domain adaptation method to generalise the hyperspectral reconstruction capability from a spectral recovery dataset to material segmentation datasets. The reconstructed hyperspectral images are further filtered using learned response curves and enhanced with human perception. The performance of MatSpectNet is evaluated on the LMD dataset as well as the OpenSurfaces dataset. Our experiments demonstrate that MatSpectNet attains a 1.60% increase in average pixel accuracy and a 3.42% improvement in mean class accuracy compared with the most recent publication. The project code is attached to the supplementary material and will be published on GitHub.
All-in-one Multi-degradation Image Restoration Network via Hierarchical Degradation Representation
Aug 06, 2023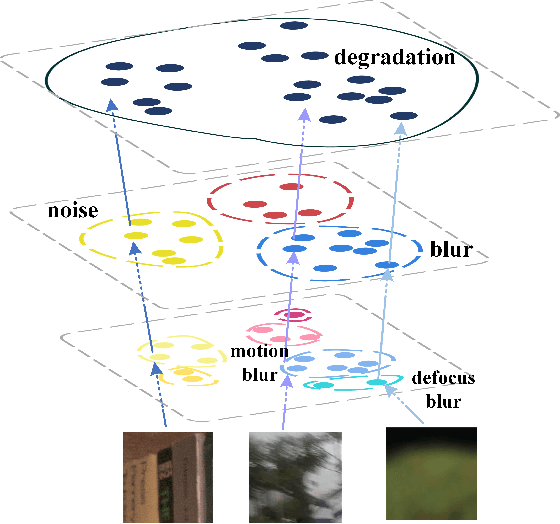

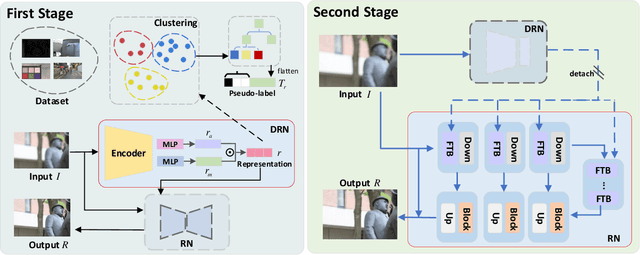
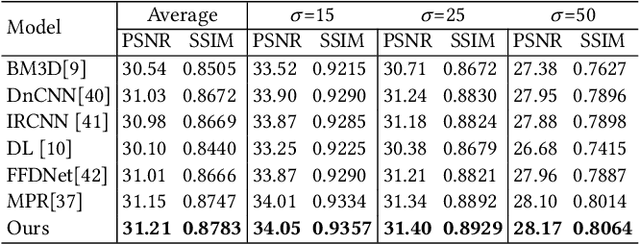
The aim of image restoration is to recover high-quality images from distorted ones. However, current methods usually focus on a single task (\emph{e.g.}, denoising, deblurring or super-resolution) which cannot address the needs of real-world multi-task processing, especially on mobile devices. Thus, developing an all-in-one method that can restore images from various unknown distortions is a significant challenge. Previous works have employed contrastive learning to learn the degradation representation from observed images, but this often leads to representation drift caused by deficient positive and negative pairs. To address this issue, we propose a novel All-in-one Multi-degradation Image Restoration Network (AMIRNet) that can effectively capture and utilize accurate degradation representation for image restoration. AMIRNet learns a degradation representation for unknown degraded images by progressively constructing a tree structure through clustering, without any prior knowledge of degradation information. This tree-structured representation explicitly reflects the consistency and discrepancy of various distortions, providing a specific clue for image restoration. To further enhance the performance of the image restoration network and overcome domain gaps caused by unknown distortions, we design a feature transform block (FTB) that aligns domains and refines features with the guidance of the degradation representation. We conduct extensive experiments on multiple distorted datasets, demonstrating the effectiveness of our method and its advantages over state-of-the-art restoration methods both qualitatively and quantitatively.
InterTracker: Discovering and Tracking General Objects Interacting with Hands in the Wild
Aug 06, 2023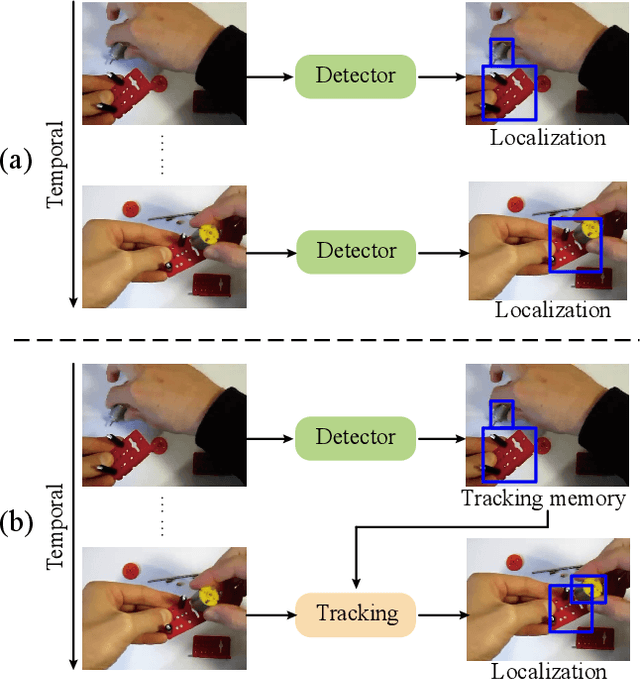
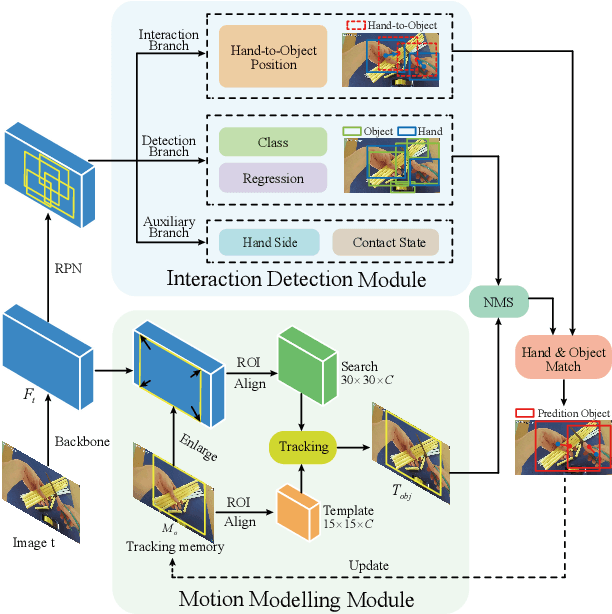
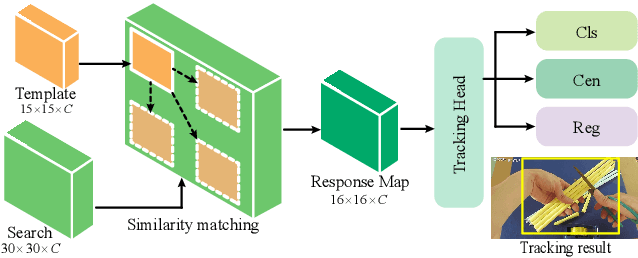

Understanding human interaction with objects is an important research topic for embodied Artificial Intelligence and identifying the objects that humans are interacting with is a primary problem for interaction understanding. Existing methods rely on frame-based detectors to locate interacting objects. However, this approach is subjected to heavy occlusions, background clutter, and distracting objects. To address the limitations, in this paper, we propose to leverage spatio-temporal information of hand-object interaction to track interactive objects under these challenging cases. Without prior knowledge of the general objects to be tracked like object tracking problems, we first utilize the spatial relation between hands and objects to adaptively discover the interacting objects from the scene. Second, the consistency and continuity of the appearance of objects between successive frames are exploited to track the objects. With this tracking formulation, our method also benefits from training on large-scale general object-tracking datasets. We further curate a video-level hand-object interaction dataset for testing and evaluation from 100DOH. The quantitative results demonstrate that our proposed method outperforms the state-of-the-art methods. Specifically, in scenes with continuous interaction with different objects, we achieve an impressive improvement of about 10% as evaluated using the Average Precision (AP) metric. Our qualitative findings also illustrate that our method can produce more continuous trajectories for interacting objects.
* 7 pages
Weakly Supervised Multi-Task Representation Learning for Human Activity Analysis Using Wearables
Aug 06, 2023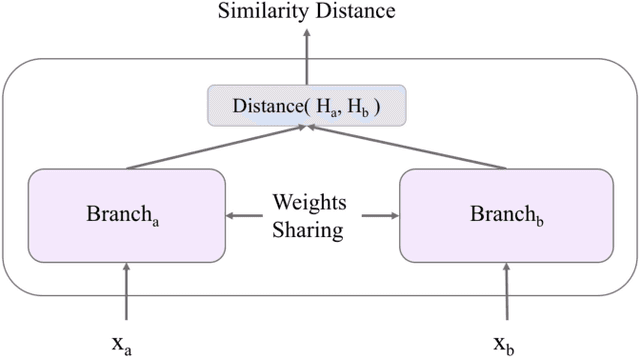
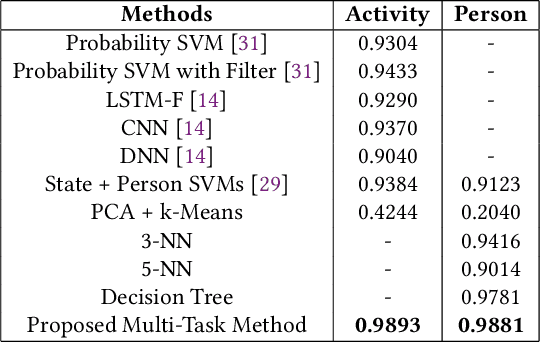
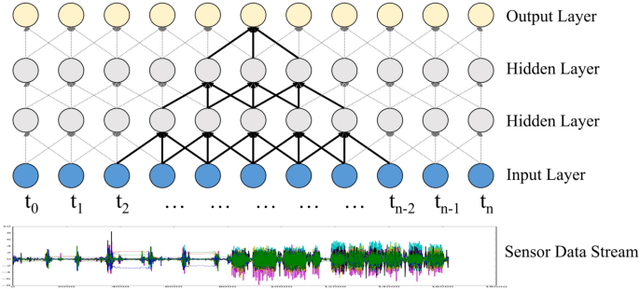
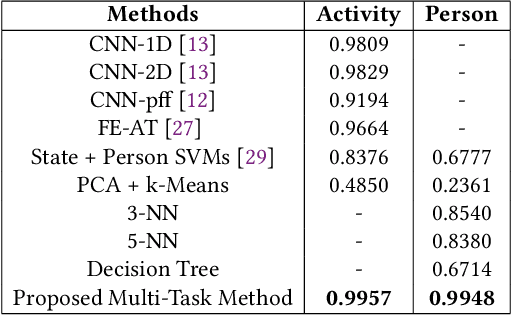
Sensor data streams from wearable devices and smart environments are widely studied in areas like human activity recognition (HAR), person identification, or health monitoring. However, most of the previous works in activity and sensor stream analysis have been focusing on one aspect of the data, e.g. only recognizing the type of the activity or only identifying the person who performed the activity. We instead propose an approach that uses a weakly supervised multi-output siamese network that learns to map the data into multiple representation spaces, where each representation space focuses on one aspect of the data. The representation vectors of the data samples are positioned in the space such that the data with the same semantic meaning in that aspect are closely located to each other. Therefore, as demonstrated with a set of experiments, the trained model can provide metrics for clustering data based on multiple aspects, allowing it to address multiple tasks simultaneously and even to outperform single task supervised methods in many situations. In addition, further experiments are presented that in more detail analyze the effect of the architecture and of using multiple tasks within this framework, that investigate the scalability of the model to include additional tasks, and that demonstrate the ability of the framework to combine data for which only partial relationship information with respect to the target tasks is available.