 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Refinement of E-commerce Search Ranking Based on Short-Term Activities of the Buyer
Dec 15, 2025In e-commerce shopping, aligning search results with a buyer's immediate needs and preferences presents a significant challenge, particularly in adapting search results throughout the buyer's shopping journey as they move from the initial stages of browsing to making a purchase decision or shift from one intent to another. This study presents a systematic approach to adapting e-commerce search results based on the current context. We start with basic methods and incrementally incorporate more contextual information and state-of-the-art techniques to improve the search outcomes. By applying this evolving contextual framework to items displayed on the search engine results page (SERP), we progressively align search outcomes more closely with the buyer's interests and current search intentions. Our findings demonstrate that this incremental enhancement, from simple heuristic autoregressive features to advanced sequence models, significantly improves ranker performance. The integration of contextual techniques enhances the performance of our production ranker, leading to improved search results in both offline and online A/B testing in terms of Mean Reciprocal Rank (MRR). Overall, the paper details iterative methodologies and their substantial contributions to search result contextualization on e-commerce platforms.
Reducing Label Dependency in Human Activity Recognition with Wearables: From Supervised Learning to Novel Weakly Self-Supervised Approaches
Dec 15, 2025Human activity recognition (HAR) using wearable sensors has advanced through various machine learning paradigms, each with inherent trade-offs between performance and labeling requirements. While fully supervised techniques achieve high accuracy, they demand extensive labeled datasets that are costly to obtain. Conversely, unsupervised methods eliminate labeling needs but often deliver suboptimal performance. This paper presents a comprehensive investigation across the supervision spectrum for wearable-based HAR, with particular focus on novel approaches that minimize labeling requirements while maintaining competitive accuracy. We develop and empirically compare: (1) traditional fully supervised learning, (2) basic unsupervised learning, (3) a weakly supervised learning approach with constraints, (4) a multi-task learning approach with knowledge sharing, (5) a self-supervised approach based on domain expertise, and (6) a novel weakly self-supervised learning framework that leverages domain knowledge and minimal labeled data. Experiments across benchmark datasets demonstrate that: (i) our weakly supervised methods achieve performance comparable to fully supervised approaches while significantly reducing supervision requirements; (ii) the proposed multi-task framework enhances performance through knowledge sharing between related tasks; (iii) our weakly self-supervised approach demonstrates remarkable efficiency with just 10\% of labeled data. These results not only highlight the complementary strengths of different learning paradigms, offering insights into tailoring HAR solutions based on the availability of labeled data, but also establish that our novel weakly self-supervised framework offers a promising solution for practical HAR applications where labeled data are limited.
Weakly Supervised Multi-Task Representation Learning for Human Activity Analysis Using Wearables
Aug 06, 2023
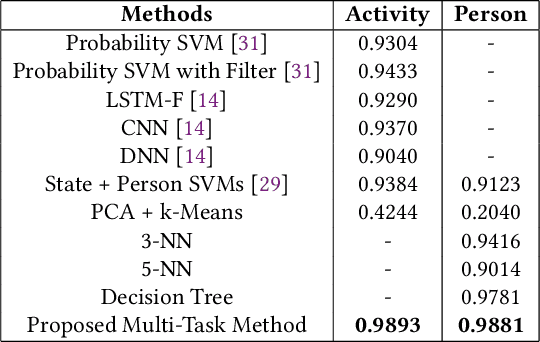


Sensor data streams from wearable devices and smart environments are widely studied in areas like human activity recognition (HAR), person identification, or health monitoring. However, most of the previous works in activity and sensor stream analysis have been focusing on one aspect of the data, e.g. only recognizing the type of the activity or only identifying the person who performed the activity. We instead propose an approach that uses a weakly supervised multi-output siamese network that learns to map the data into multiple representation spaces, where each representation space focuses on one aspect of the data. The representation vectors of the data samples are positioned in the space such that the data with the same semantic meaning in that aspect are closely located to each other. Therefore, as demonstrated with a set of experiments, the trained model can provide metrics for clustering data based on multiple aspects, allowing it to address multiple tasks simultaneously and even to outperform single task supervised methods in many situations. In addition, further experiments are presented that in more detail analyze the effect of the architecture and of using multiple tasks within this framework, that investigate the scalability of the model to include additional tasks, and that demonstrate the ability of the framework to combine data for which only partial relationship information with respect to the target tasks is available.
Unsupervised Embedding Learning for Human Activity Recognition Using Wearable Sensor Data
Jul 21, 2023



The embedded sensors in widely used smartphones and other wearable devices make the data of human activities more accessible. However, recognizing different human activities from the wearable sensor data remains a challenging research problem in ubiquitous computing. One of the reasons is that the majority of the acquired data has no labels. In this paper, we present an unsupervised approach, which is based on the nature of human activity, to project the human activities into an embedding space in which similar activities will be located closely together. Using this, subsequent clustering algorithms can benefit from the embeddings, forming behavior clusters that represent the distinct activities performed by a person. Results of experiments on three labeled benchmark datasets demonstrate the effectiveness of the framework and show that our approach can help the clustering algorithm achieve improved performance in identifying and categorizing the underlying human activities compared to unsupervised techniques applied directly to the original data set.
Siamese Networks for Weakly Supervised Human Activity Recognition
Jul 18, 2023


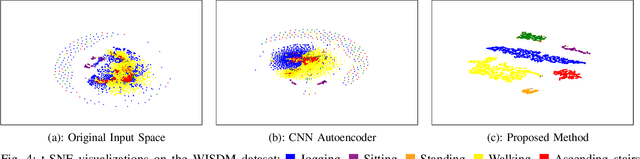
Deep learning has been successfully applied to human activity recognition. However, training deep neural networks requires explicitly labeled data which is difficult to acquire. In this paper, we present a model with multiple siamese networks that are trained by using only the information about the similarity between pairs of data samples without knowing the explicit labels. The trained model maps the activity data samples into fixed size representation vectors such that the distance between the vectors in the representation space approximates the similarity of the data samples in the input space. Thus, the trained model can work as a metric for a wide range of different clustering algorithms. The training process minimizes a similarity loss function that forces the distance metric to be small for pairs of samples from the same kind of activity, and large for pairs of samples from different kinds of activities. We evaluate the model on three datasets to verify its effectiveness in segmentation and recognition of continuous human activity sequences.