 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Vision-based Pursuit-Evasion Robot Policies
Aug 30, 2023
Learning strategic robot behavior -- like that required in pursuit-evasion interactions -- under real-world constraints is extremely challenging. It requires exploiting the dynamics of the interaction, and planning through both physical state and latent intent uncertainty. In this paper, we transform this intractable problem into a supervised learning problem, where a fully-observable robot policy generates supervision for a partially-observable one. We find that the quality of the supervision signal for the partially-observable pursuer policy depends on two key factors: the balance of diversity and optimality of the evader's behavior and the strength of the modeling assumptions in the fully-observable policy. We deploy our policy on a physical quadruped robot with an RGB-D camera on pursuit-evasion interactions in the wild. Despite all the challenges, the sensing constraints bring about creativity: the robot is pushed to gather information when uncertain, predict intent from noisy measurements, and anticipate in order to intercept. Project webpage: https://abajcsy.github.io/vision-based-pursuit/
6G Localization and Sensing in the Near Field: Fundamentals, Opportunities, and Challenges
Aug 30, 2023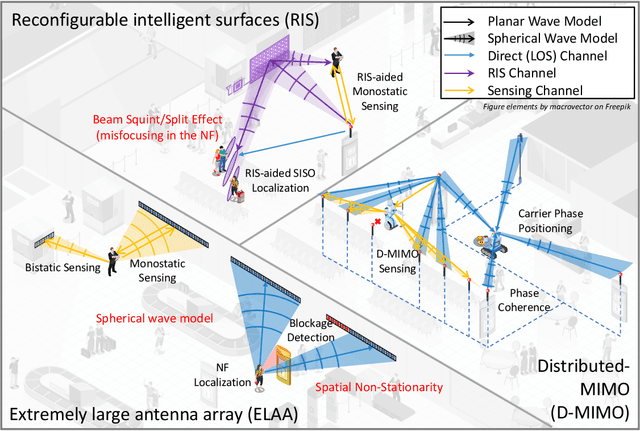
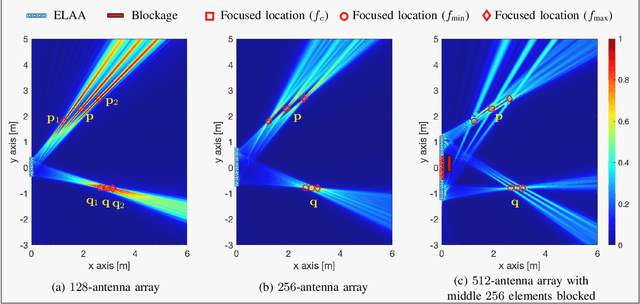
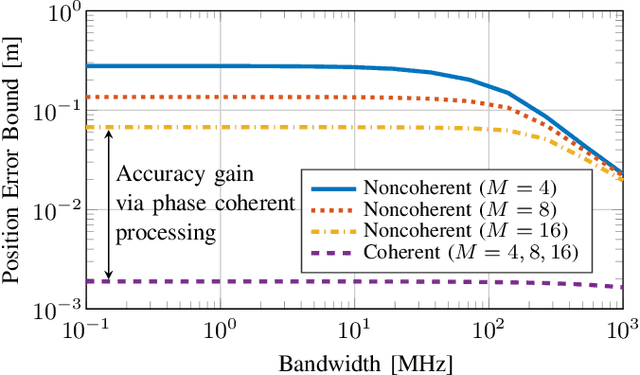
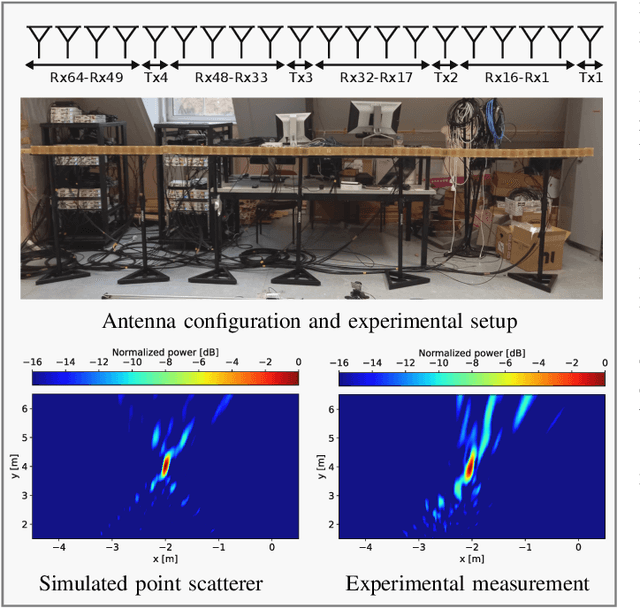
The far-field channel model has historically been used in wireless communications due to the simplicity of mathematical modeling and convenience for algorithm design, and its validity for relatively small array apertures. With the need for high data rates, low latency, and ubiquitous connectivity in the sixth generation (6G) of communication systems, new technology enablers such as extremely large antenna arrays (ELAA), reconfigurable intelligent surfaces (RISs), and distributed multiple-input-multiple-output (D-MIMO) systems will be adopted. These enablers not only aim to improve communication services but also have an impact on localization and sensing (L\&S), which are expected to be integrated into future wireless systems. Despite appearing in different scenarios and supporting different frequency bands, these enablers share the so-called near-field (NF) features, which will provide extra geometric information. In this work, starting from a brief description of NF channel features, we highlight the opportunities and challenges for 6G NF L\&S.
LCCo: Lending CLIP to Co-Segmentation
Aug 22, 2023
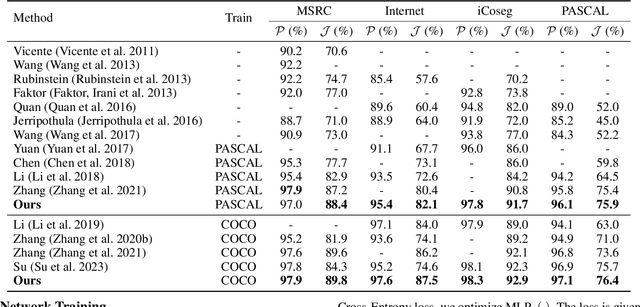
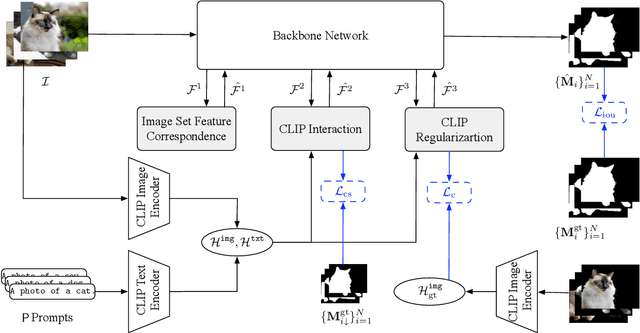
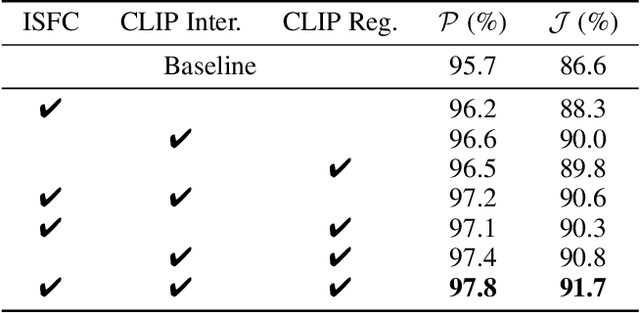
This paper studies co-segmenting the common semantic object in a set of images. Existing works either rely on carefully engineered networks to mine the implicit semantic information in visual features or require extra data (i.e., classification labels) for training. In this paper, we leverage the contrastive language-image pre-training framework (CLIP) for the task. With a backbone segmentation network that independently processes each image from the set, we introduce semantics from CLIP into the backbone features, refining them in a coarse-to-fine manner with three key modules: i) an image set feature correspondence module, encoding global consistent semantic information of the image set; ii) a CLIP interaction module, using CLIP-mined common semantics of the image set to refine the backbone feature; iii) a CLIP regularization module, drawing CLIP towards this co-segmentation task, identifying the best CLIP semantic and using it to regularize the backbone feature. Experiments on four standard co-segmentation benchmark datasets show that the performance of our method outperforms state-of-the-art methods.
Explaining Predictive Uncertainty with Information Theoretic Shapley Values
Jun 09, 2023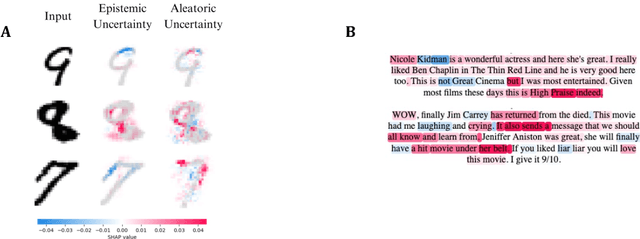
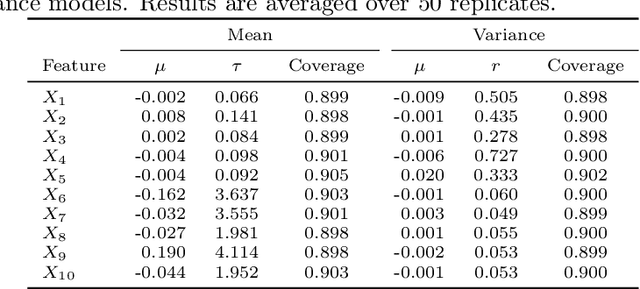
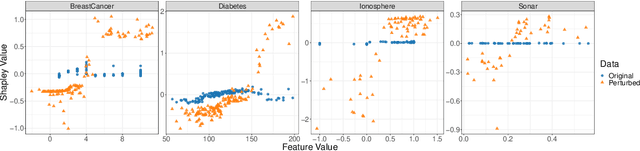
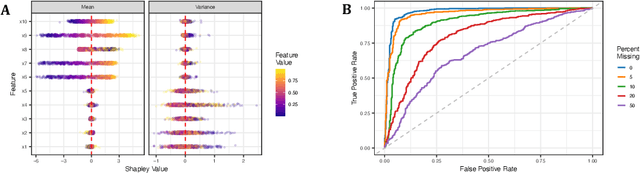
Researchers in explainable artificial intelligence have developed numerous methods for helping users understand the predictions of complex supervised learning models. By contrast, explaining the $\textit{uncertainty}$ of model outputs has received relatively little attention. We adapt the popular Shapley value framework to explain various types of predictive uncertainty, quantifying each feature's contribution to the conditional entropy of individual model outputs. We consider games with modified characteristic functions and find deep connections between the resulting Shapley values and fundamental quantities from information theory and conditional independence testing. We outline inference procedures for finite sample error rate control with provable guarantees, and implement an efficient algorithm that performs well in a range of experiments on real and simulated data. Our method has applications to covariate shift detection, active learning, feature selection, and active feature-value acquisition.
How Object Information Improves Skeleton-based Human Action Recognition in Assembly Tasks
Jun 09, 2023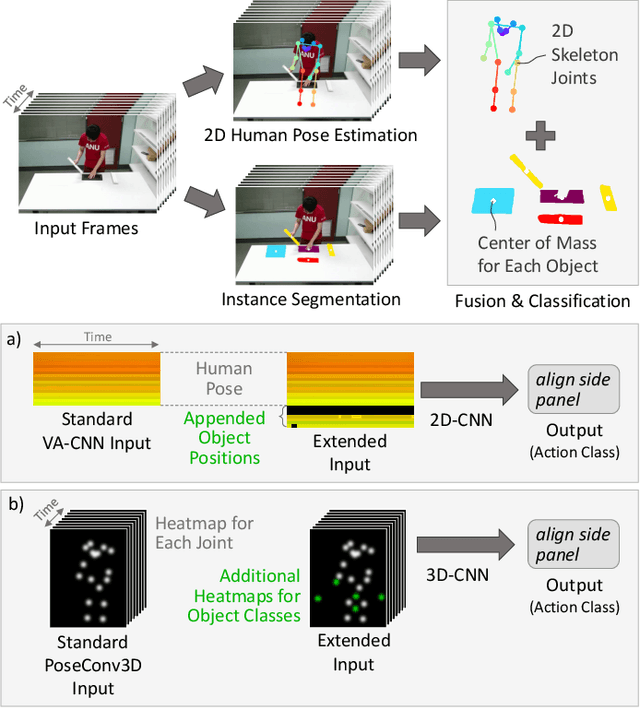

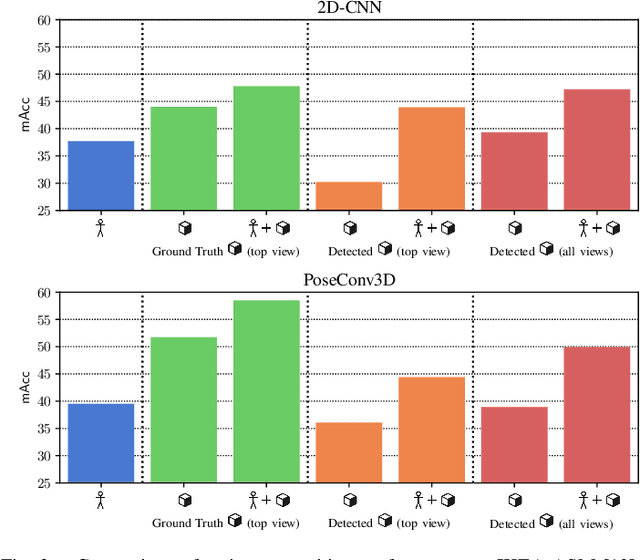
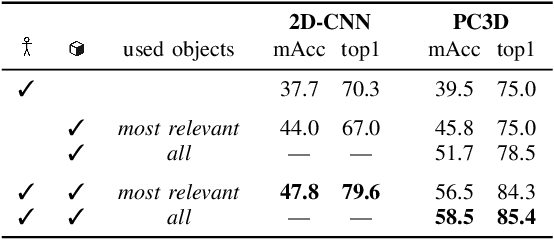
As the use of collaborative robots (cobots) in industrial manufacturing continues to grow, human action recognition for effective human-robot collaboration becomes increasingly important. This ability is crucial for cobots to act autonomously and assist in assembly tasks. Recently, skeleton-based approaches are often used as they tend to generalize better to different people and environments. However, when processing skeletons alone, information about the objects a human interacts with is lost. Therefore, we present a novel approach of integrating object information into skeleton-based action recognition. We enhance two state-of-the-art methods by treating object centers as further skeleton joints. Our experiments on the assembly dataset IKEA ASM show that our approach improves the performance of these state-of-the-art methods to a large extent when combining skeleton joints with objects predicted by a state-of-the-art instance segmentation model. Our research sheds light on the benefits of combining skeleton joints with object information for human action recognition in assembly tasks. We analyze the effect of the object detector on the combination for action classification and discuss the important factors that must be taken into account.
Towards Asking Clarification Questions for Information Seeking on Task-Oriented Dialogues
May 23, 2023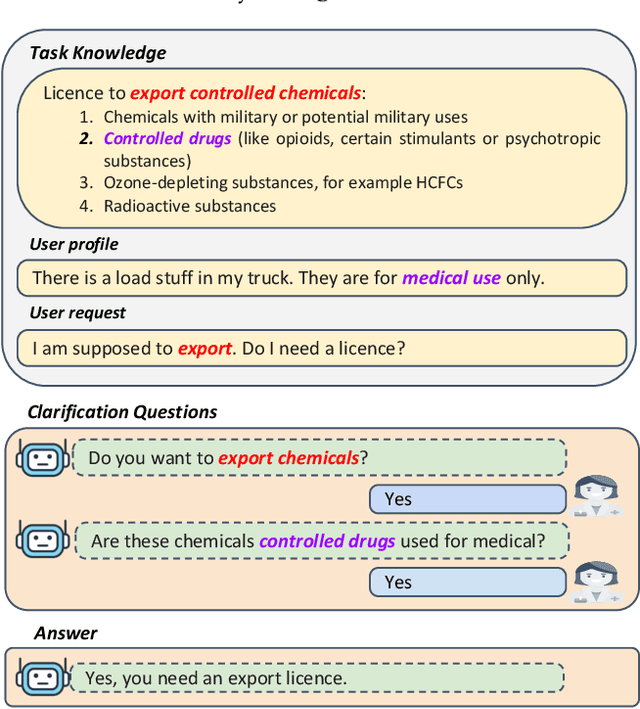
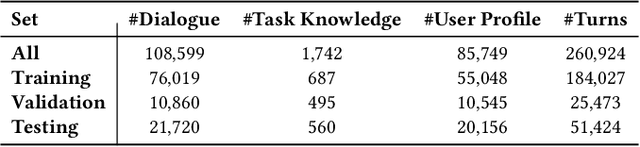
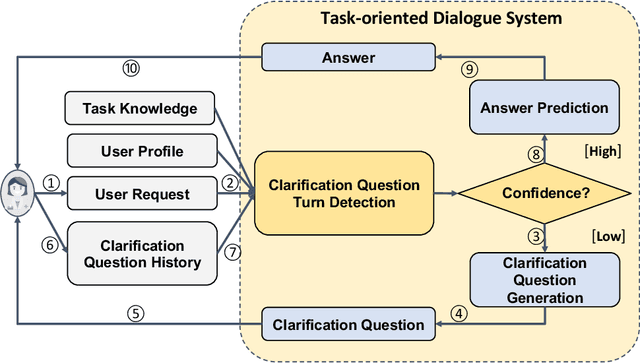
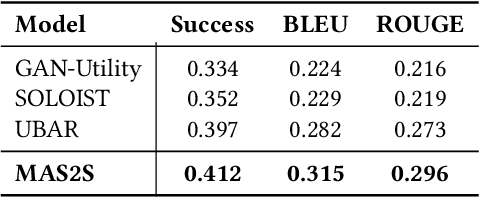
Task-oriented dialogue systems aim at providing users with task-specific services. Users of such systems often do not know all the information about the task they are trying to accomplish, requiring them to seek information about the task. To provide accurate and personalized task-oriented information seeking results, task-oriented dialogue systems need to address two potential issues: 1) users' inability to describe their complex information needs in their requests; and 2) ambiguous/missing information the system has about the users. In this paper, we propose a new Multi-Attention Seq2Seq Network, named MAS2S, which can ask questions to clarify the user's information needs and the user's profile in task-oriented information seeking. We also extend an existing dataset for task-oriented information seeking, leading to the \ourdataset which contains about 100k task-oriented information seeking dialogues that are made publicly available\footnote{Dataset and code is available at \href{https://github.com/sweetalyssum/clarit}{https://github.com/sweetalyssum/clarit}.}. Experimental results on \ourdataset show that MAS2S outperforms baselines on both clarification question generation and answer prediction.
Structural Cycle GAN for Virtual Immunohistochemistry Staining of Gland Markers in the Colon
Aug 25, 2023With the advent of digital scanners and deep learning, diagnostic operations may move from a microscope to a desktop. Hematoxylin and Eosin (H&E) staining is one of the most frequently used stains for disease analysis, diagnosis, and grading, but pathologists do need different immunohistochemical (IHC) stains to analyze specific structures or cells. Obtaining all of these stains (H&E and different IHCs) on a single specimen is a tedious and time-consuming task. Consequently, virtual staining has emerged as an essential research direction. Here, we propose a novel generative model, Structural Cycle-GAN (SC-GAN), for synthesizing IHC stains from H&E images, and vice versa. Our method expressly incorporates structural information in the form of edges (in addition to color data) and employs attention modules exclusively in the decoder of the proposed generator model. This integration enhances feature localization and preserves contextual information during the generation process. In addition, a structural loss is incorporated to ensure accurate structure alignment between the generated and input markers. To demonstrate the efficacy of the proposed model, experiments are conducted with two IHC markers emphasizing distinct structures of glands in the colon: the nucleus of epithelial cells (CDX2) and the cytoplasm (CK818). Quantitative metrics such as FID and SSIM are frequently used for the analysis of generative models, but they do not correlate explicitly with higher-quality virtual staining results. Therefore, we propose two new quantitative metrics that correlate directly with the virtual staining specificity of IHC markers.
Variational $f$-Divergence and Derangements for Discriminative Mutual Information Estimation
May 31, 2023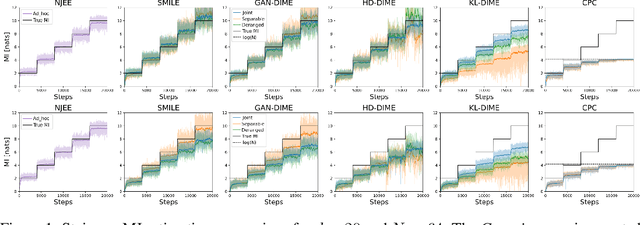
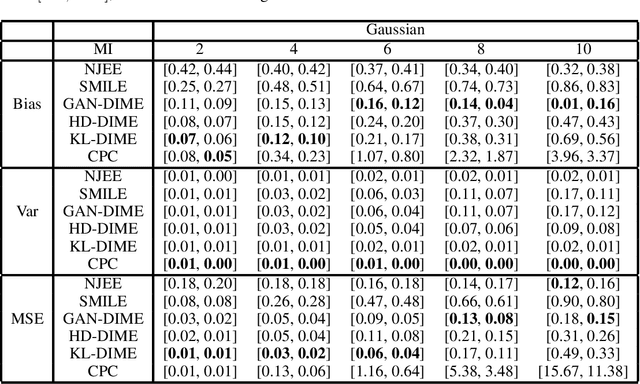
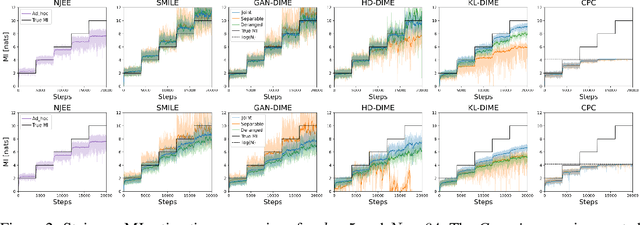
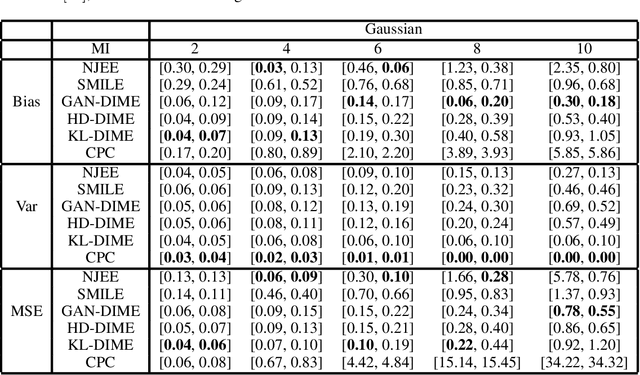
The accurate estimation of the mutual information is a crucial task in various applications, including machine learning, communications, and biology, since it enables the understanding of complex systems. High-dimensional data render the task extremely challenging due to the amount of data to be processed and the presence of convoluted patterns. Neural estimators based on variational lower bounds of the mutual information have gained attention in recent years but they are prone to either high bias or high variance as a consequence of the partition function. We propose a novel class of discriminative mutual information estimators based on the variational representation of the $f$-divergence. We investigate the impact of the permutation function used to obtain the marginal training samples and present a novel architectural solution based on derangements. The proposed estimator is flexible as it exhibits an excellent bias/variance trade-off. Experiments on reference scenarios demonstrate that our approach outperforms state-of-the-art neural estimators both in terms of accuracy and complexity.
Approximating Human-Like Few-shot Learning with GPT-based Compression
Aug 14, 2023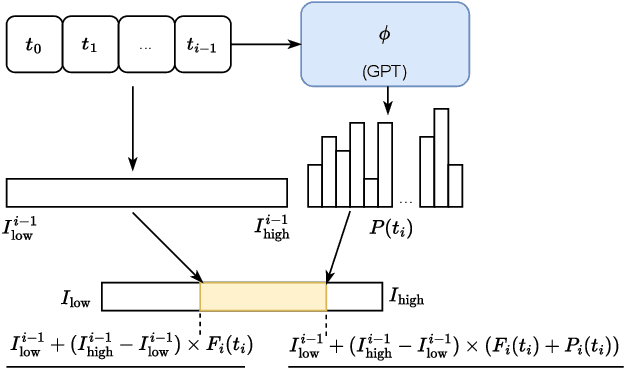

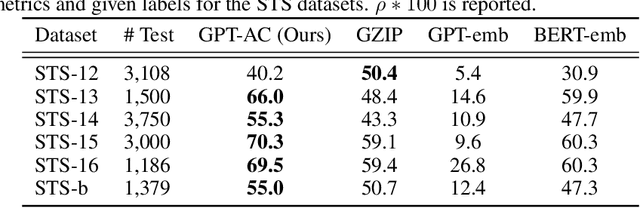
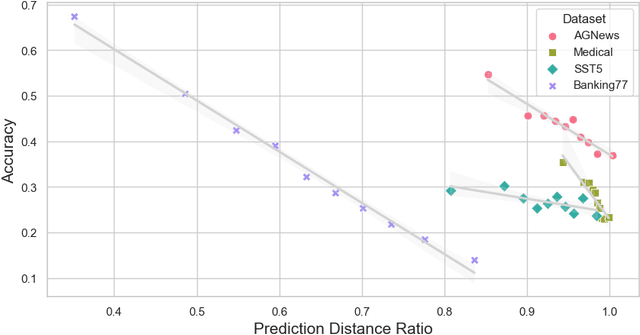
In this work, we conceptualize the learning process as information compression. We seek to equip generative pre-trained models with human-like learning capabilities that enable data compression during inference. We present a novel approach that utilizes the Generative Pre-trained Transformer (GPT) to approximate Kolmogorov complexity, with the aim of estimating the optimal Information Distance for few-shot learning. We first propose using GPT as a prior for lossless text compression, achieving a noteworthy compression ratio. Experiment with LLAMA2-7B backbone achieves a compression ratio of 15.5 on enwik9. We justify the pre-training objective of GPT models by demonstrating its equivalence to the compression length, and, consequently, its ability to approximate the information distance for texts. Leveraging the approximated information distance, our method allows the direct application of GPT models in quantitative text similarity measurements. Experiment results show that our method overall achieves superior performance compared to embedding and prompt baselines on challenging NLP tasks, including semantic similarity, zero and one-shot text classification, and zero-shot text ranking.
Designing a User Contextual Profile Ontology: A Focus on the Vehicle Sales Domain
Aug 11, 2023In the digital age, it is crucial to understand and tailor experiences for users interacting with systems and applications. This requires the creation of user contextual profiles that combine user profiles with contextual information. However, there is a lack of research on the integration of contextual information with different user profiles. This study aims to address this gap by designing a user contextual profile ontology that considers both user profiles and contextual information on each profile. Specifically, we present a design and development of the user contextual profile ontology with a focus on the vehicle sales domain. Our designed ontology serves as a structural foundation for standardizing the representation of user profiles and contextual information, enhancing the system's ability to capture user preferences and contextual information of the user accurately. Moreover, we illustrate a case study using the User Contextual Profile Ontology in generating personalized recommendations for vehicle sales domain.