 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocial Knowledge for Cross-Domain User Preference Modeling
Mar 10, 2026We demonstrate that user preferences can be represented and predicted across topical domains using large-scale social modeling. Given information about popular entities favored by a user, we project the user into a social embedding space learned from a large-scale sample of the Twitter (now X) network. By representing both users and popular entities in a joint social space, we can assess the relevance of candidate entities (e.g., music artists) using cosine similarity within this embedding space. A comprehensive evaluation using link prediction experiments shows that this method achieves effective personalization in zero-shot setting, when no user feedback is available for entities in the target domain, yielding substantial improvements over a strong popularity-based baseline. In-depth analysis further illustrates that socio-demographic factors encoded in the social embeddings are correlated with user preferences across domains. Finally, we argue and demonstrate that the proposed approach can facilitate social modeling of end users using large language models (LLMs).
A Graph Meta-Network for Learning on Kolmogorov-Arnold Networks
Feb 18, 2026Weight-space models learn directly from the parameters of neural networks, enabling tasks such as predicting their accuracy on new datasets. Naive methods -- like applying MLPs to flattened parameters -- perform poorly, making the design of better weight-space architectures a central challenge. While prior work leveraged permutation symmetries in standard networks to guide such designs, no analogous analysis or tailored architecture yet exists for Kolmogorov-Arnold Networks (KANs). In this work, we show that KANs share the same permutation symmetries as MLPs, and propose the KAN-graph, a graph representation of their computation. Building on this, we develop WS-KAN, the first weight-space architecture that learns on KANs, which naturally accounts for their symmetry. We analyze WS-KAN's expressive power, showing it can replicate an input KAN's forward pass - a standard approach for assessing expressiveness in weight-space architectures. We construct a comprehensive ``zoo'' of trained KANs spanning diverse tasks, which we use as benchmarks to empirically evaluate WS-KAN. Across all tasks, WS-KAN consistently outperforms structure-agnostic baselines, often by a substantial margin. Our code is available at https://github.com/BarSGuy/KAN-Graph-Metanetwork.
Billion-Scale Graph Foundation Models
Feb 04, 2026Graph-structured data underpins many critical applications. While foundation models have transformed language and vision via large-scale pretraining and lightweight adaptation, extending this paradigm to general, real-world graphs is challenging. In this work, we present Graph Billion- Foundation-Fusion (GraphBFF): the first end-to-end recipe for building billion-parameter Graph Foundation Models (GFMs) for arbitrary heterogeneous, billion-scale graphs. Central to the recipe is the GraphBFF Transformer, a flexible and scalable architecture designed for practical billion-scale GFMs. Using the GraphBFF, we present the first neural scaling laws for general graphs and show that loss decreases predictably as either model capacity or training data scales, depending on which factor is the bottleneck. The GraphBFF framework provides concrete methodologies for data batching, pretraining, and fine-tuning for building GFMs at scale. We demonstrate the effectiveness of the framework with an evaluation of a 1.4 billion-parameter GraphBFF Transformer pretrained on one billion samples. Across ten diverse, real-world downstream tasks on graphs unseen during training, spanning node- and link-level classification and regression, GraphBFF achieves remarkable zero-shot and probing performance, including in few-shot settings, with large margins of up to 31 PRAUC points. Finally, we discuss key challenges and open opportunities for making GFMs a practical and principled foundation for graph learning at industrial scale.
Multicalibration yields better matchings
Nov 14, 2025
Consider the problem of finding the best matching in a weighted graph where we only have access to predictions of the actual stochastic weights, based on an underlying context. If the predictor is the Bayes optimal one, then computing the best matching based on the predicted weights is optimal. However, in practice, this perfect information scenario is not realistic. Given an imperfect predictor, a suboptimal decision rule may compensate for the induced error and thus outperform the standard optimal rule. In this paper, we propose multicalibration as a way to address this problem. This fairness notion requires a predictor to be unbiased on each element of a family of protected sets of contexts. Given a class of matching algorithms $\mathcal C$ and any predictor $γ$ of the edge-weights, we show how to construct a specific multicalibrated predictor $\hat γ$, with the following property. Picking the best matching based on the output of $\hat γ$ is competitive with the best decision rule in $\mathcal C$ applied onto the original predictor $γ$. We complement this result by providing sample complexity bounds.
Measuring multi-calibration
Jun 12, 2025A suitable scalar metric can help measure multi-calibration, defined as follows. When the expected values of observed responses are equal to corresponding predicted probabilities, the probabilistic predictions are known as "perfectly calibrated." When the predicted probabilities are perfectly calibrated simultaneously across several subpopulations, the probabilistic predictions are known as "perfectly multi-calibrated." In practice, predicted probabilities are seldom perfectly multi-calibrated, so a statistic measuring the distance from perfect multi-calibration is informative. A recently proposed metric for calibration, based on the classical Kuiper statistic, is a natural basis for a new metric of multi-calibration and avoids well-known problems of metrics based on binning or kernel density estimation. The newly proposed metric weights the contributions of different subpopulations in proportion to their signal-to-noise ratios; data analyses' ablations demonstrate that the metric becomes noisy when omitting the signal-to-noise ratios from the metric. Numerical examples on benchmark data sets illustrate the new metric.
Leveraging World Events to Predict E-Commerce Consumer Demand under Anomaly
May 22, 2024Consumer demand forecasting is of high importance for many e-commerce applications, including supply chain optimization, advertisement placement, and delivery speed optimization. However, reliable time series sales forecasting for e-commerce is difficult, especially during periods with many anomalies, as can often happen during pandemics, abnormal weather, or sports events. Although many time series algorithms have been applied to the task, prediction during anomalies still remains a challenge. In this work, we hypothesize that leveraging external knowledge found in world events can help overcome the challenge of prediction under anomalies. We mine a large repository of 40 years of world events and their textual representations. Further, we present a novel methodology based on transformers to construct an embedding of a day based on the relations of the day's events. Those embeddings are then used to forecast future consumer behavior. We empirically evaluate the methods over a large e-commerce products sales dataset, extracted from eBay, one of the world's largest online marketplaces. We show over numerous categories that our method outperforms state-of-the-art baselines during anomalies.
Active learning with biased non-response to label requests
Dec 13, 2023Active learning can improve the efficiency of training prediction models by identifying the most informative new labels to acquire. However, non-response to label requests can impact active learning's effectiveness in real-world contexts. We conceptualise this degradation by considering the type of non-response present in the data, demonstrating that biased non-response is particularly detrimental to model performance. We argue that this sort of non-response is particularly likely in contexts where the labelling process, by nature, relies on user interactions. To mitigate the impact of biased non-response, we propose a cost-based correction to the sampling strategy--the Upper Confidence Bound of the Expected Utility (UCB-EU)--that can, plausibly, be applied to any active learning algorithm. Through experiments, we demonstrate that our method successfully reduces the harm from labelling non-response in many settings. However, we also characterise settings where the non-response bias in the annotations remains detrimental under UCB-EU for particular sampling methods and data generating processes. Finally, we evaluate our method on a real-world dataset from e-commerce platform Taobao. We show that UCB-EU yields substantial performance improvements to conversion models that are trained on clicked impressions. Most generally, this research serves to both better conceptualise the interplay between types of non-response and model improvements via active learning, and to provide a practical, easy to implement correction that helps mitigate model degradation.
TCE: A Test-Based Approach to Measuring Calibration Error
Jun 25, 2023



This paper proposes a new metric to measure the calibration error of probabilistic binary classifiers, called test-based calibration error (TCE). TCE incorporates a novel loss function based on a statistical test to examine the extent to which model predictions differ from probabilities estimated from data. It offers (i) a clear interpretation, (ii) a consistent scale that is unaffected by class imbalance, and (iii) an enhanced visual representation with repect to the standard reliability diagram. In addition, we introduce an optimality criterion for the binning procedure of calibration error metrics based on a minimal estimation error of the empirical probabilities. We provide a novel computational algorithm for optimal bins under bin-size constraints. We demonstrate properties of TCE through a range of experiments, including multiple real-world imbalanced datasets and ImageNet 1000.
Explaining Predictive Uncertainty with Information Theoretic Shapley Values
Jun 09, 2023Researchers in explainable artificial intelligence have developed numerous methods for helping users understand the predictions of complex supervised learning models. By contrast, explaining the $\textit{uncertainty}$ of model outputs has received relatively little attention. We adapt the popular Shapley value framework to explain various types of predictive uncertainty, quantifying each feature's contribution to the conditional entropy of individual model outputs. We consider games with modified characteristic functions and find deep connections between the resulting Shapley values and fundamental quantities from information theory and conditional independence testing. We outline inference procedures for finite sample error rate control with provable guarantees, and implement an efficient algorithm that performs well in a range of experiments on real and simulated data. Our method has applications to covariate shift detection, active learning, feature selection, and active feature-value acquisition.
tBDFS: Temporal Graph Neural Network Leveraging DFS
Jun 12, 2022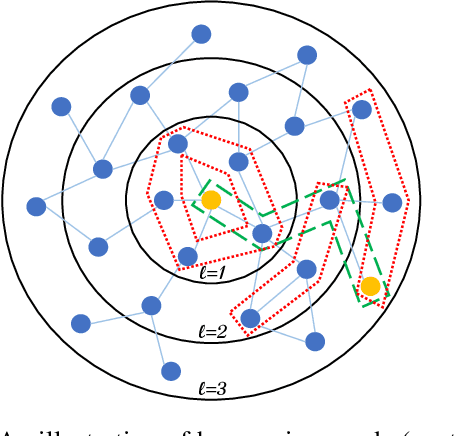
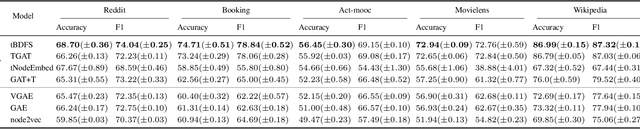

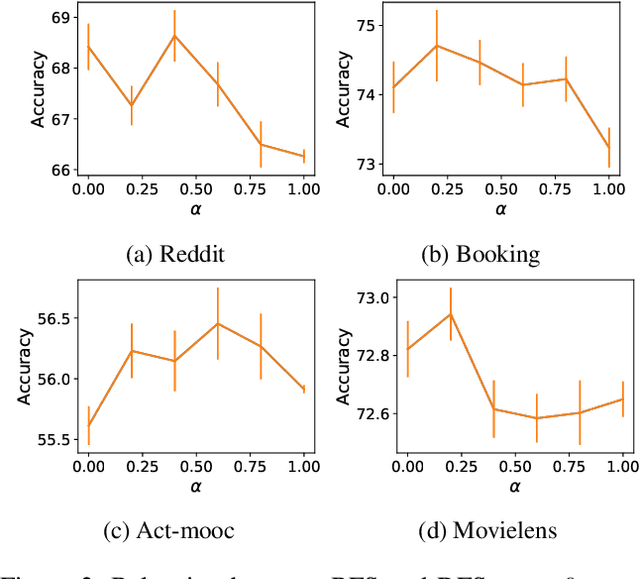
Temporal graph neural networks (temporal GNNs) have been widely researched, reaching state-of-the-art results on multiple prediction tasks. A common approach employed by most previous works is to apply a layer that aggregates information from the historical neighbors of a node. Taking a different research direction, in this work, we propose tBDFS -- a novel temporal GNN architecture. tBDFS applies a layer that efficiently aggregates information from temporal paths to a given (target) node in the graph. For each given node, the aggregation is applied in two stages: (1) A single representation is learned for each temporal path ending in that node, and (2) all path representations are aggregated into a final node representation. Overall, our goal is not to add new information to a node, but rather observe the same exact information in a new perspective. This allows our model to directly observe patterns that are path-oriented rather than neighborhood-oriented. This can be thought as a Depth-First Search (DFS) traversal over the temporal graph, compared to the popular Breath-First Search (BFS) traversal that is applied in previous works. We evaluate tBDFS over multiple link prediction tasks and show its favorable performance compared to state-of-the-art baselines. To the best of our knowledge, we are the first to apply a temporal-DFS neural network.