 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Ref-Diff: Zero-shot Referring Image Segmentation with Generative Models
Aug 31, 2023
Zero-shot referring image segmentation is a challenging task because it aims to find an instance segmentation mask based on the given referring descriptions, without training on this type of paired data. Current zero-shot methods mainly focus on using pre-trained discriminative models (e.g., CLIP). However, we have observed that generative models (e.g., Stable Diffusion) have potentially understood the relationships between various visual elements and text descriptions, which are rarely investigated in this task. In this work, we introduce a novel Referring Diffusional segmentor (Ref-Diff) for this task, which leverages the fine-grained multi-modal information from generative models. We demonstrate that without a proposal generator, a generative model alone can achieve comparable performance to existing SOTA weakly-supervised models. When we combine both generative and discriminative models, our Ref-Diff outperforms these competing methods by a significant margin. This indicates that generative models are also beneficial for this task and can complement discriminative models for better referring segmentation. Our code is publicly available at https://github.com/kodenii/Ref-Diff.
Amplitude Prediction from Uplink to Downlink CSI against Receiver Distortion in FDD Systems
Aug 31, 2023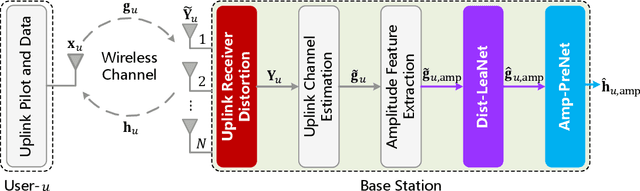

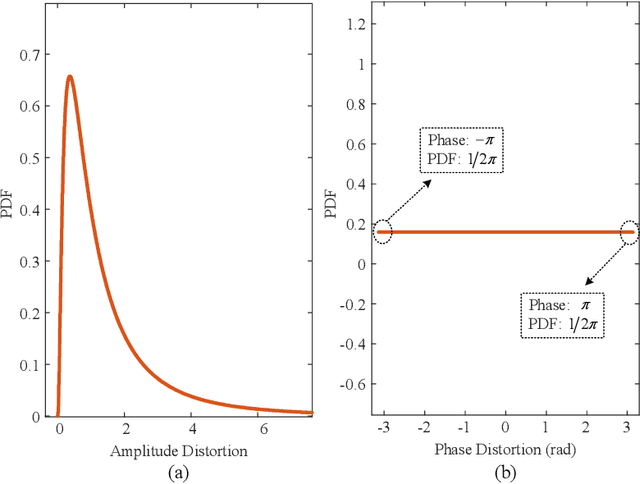

In frequency division duplex (FDD) massive multiple-input multiple-output (mMIMO) systems, the reciprocity mismatch caused by receiver distortion seriously degrades the amplitude prediction performance of channel state information (CSI). To tackle this issue, from the perspective of distortion suppression and reciprocity calibration, a lightweight neural network-based amplitude prediction method is proposed in this paper. Specifically, with the receiver distortion at the base station (BS), conventional methods are employed to extract the amplitude feature of uplink CSI. Then, learning along the direction of the uplink wireless propagation channel, a dedicated and lightweight distortion-learning network (Dist-LeaNet) is designed to restrain the receiver distortion and calibrate the amplitude reciprocity between the uplink and downlink CSI. Subsequently, by cascading, a single hidden layer-based amplitude-prediction network (Amp-PreNet) is developed to accomplish amplitude prediction of downlink CSI based on the strong amplitude reciprocity. Simulation results show that, considering the receiver distortion in FDD systems, the proposed scheme effectively improves the amplitude prediction accuracy of downlink CSI while reducing the transmission and processing delay.
Channel Estimation for XL-MIMO Systems with Polar-Domain Multi-Scale Residual Dense Network
Aug 31, 2023Extremely large-scale multiple-input multiple-output (XL-MIMO) is a promising technique to enable versatile applications for future wireless communications.To realize the huge potential performance gain, accurate channel state information is a fundamental technical prerequisite. In conventional massive MIMO, the channel is often modeled by the far-field planar-wavefront with rich sparsity in the angular domain that facilitates the design of low-complexity channel estimation. However, this sparsity is not conspicuous in XL-MIMO systems due to the non-negligible near-field spherical-wavefront. To address the inherent performance loss of the angular-domain channel estimation schemes, we first propose the polar-domain multiple residual dense network (P-MRDN) for XL-MIMO systems based on the polar-domain sparsity of the near-field channel by improving the existing MRDN scheme. Furthermore, a polar-domain multi-scale residual dense network (P-MSRDN) is designed to improve the channel estimation accuracy. Finally, simulation results reveal the superior performance of the proposed schemes compared with existing benchmark schemes and the minimal influence of the channel sparsity on the proposed schemes.
Balancing between the Local and Global Structures (LGS) in Graph Embedding
Aug 31, 2023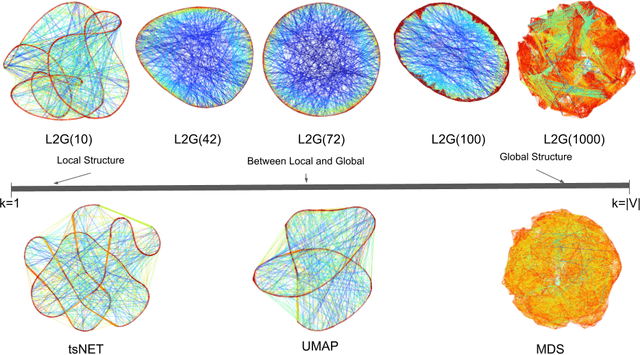
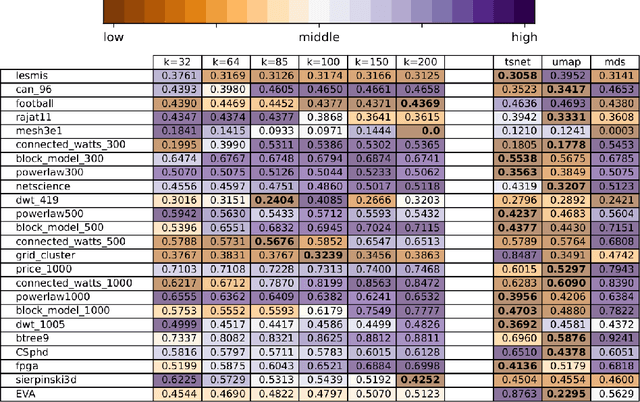
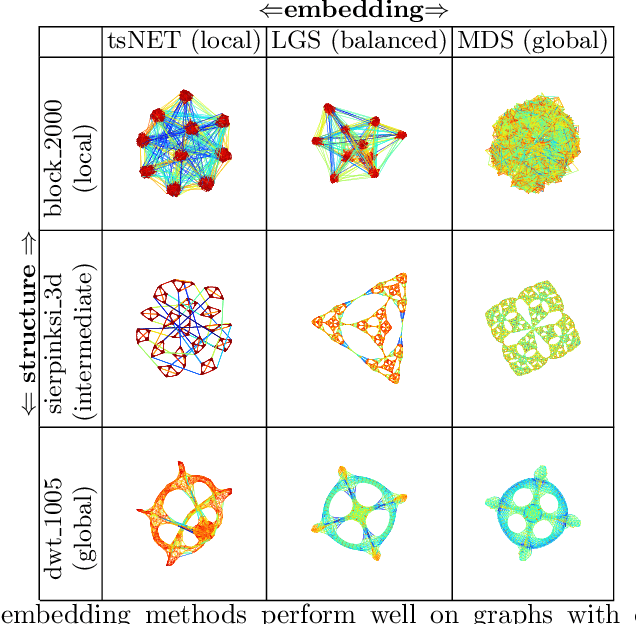
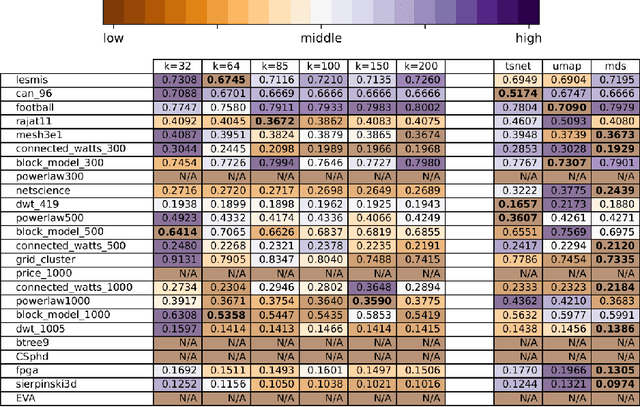
We present a method for balancing between the Local and Global Structures (LGS) in graph embedding, via a tunable parameter. Some embedding methods aim to capture global structures, while others attempt to preserve local neighborhoods. Few methods attempt to do both, and it is not always possible to capture well both local and global information in two dimensions, which is where most graph drawing live. The choice of using a local or a global embedding for visualization depends not only on the task but also on the structure of the underlying data, which may not be known in advance. For a given graph, LGS aims to find a good balance between the local and global structure to preserve. We evaluate the performance of LGS with synthetic and real-world datasets and our results indicate that it is competitive with the state-of-the-art methods, using established quality metrics such as stress and neighborhood preservation. We introduce a novel quality metric, cluster distance preservation, to assess intermediate structure capture. All source-code, datasets, experiments and analysis are available online.
Evaluation and Analysis of Hallucination in Large Vision-Language Models
Aug 29, 2023

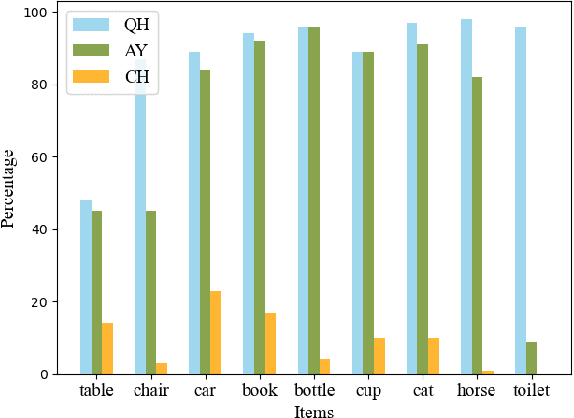
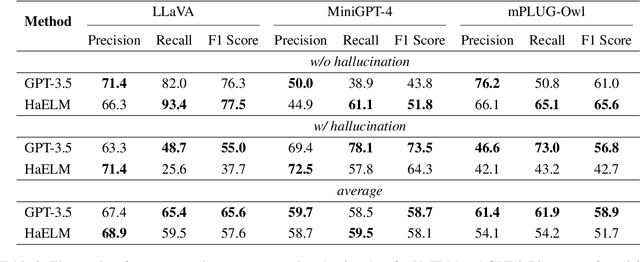
Large Vision-Language Models (LVLMs) have recently achieved remarkable success. However, LVLMs are still plagued by the hallucination problem, which limits the practicality in many scenarios. Hallucination refers to the information of LVLMs' responses that does not exist in the visual input, which poses potential risks of substantial consequences. There has been limited work studying hallucination evaluation in LVLMs. In this paper, we propose Hallucination Evaluation based on Large Language Models (HaELM), an LLM-based hallucination evaluation framework. HaELM achieves an approximate 95% performance comparable to ChatGPT and has additional advantages including low cost, reproducibility, privacy preservation and local deployment. Leveraging the HaELM, we evaluate the hallucination in current LVLMs. Furthermore, we analyze the factors contributing to hallucination in LVLMs and offer helpful suggestions to mitigate the hallucination problem. Our training data and human annotation hallucination data will be made public soon.
AIoT-Based Drum Transcription Robot using Convolutional Neural Networks
Aug 29, 2023With the development of information technology, robot technology has made great progress in various fields. These new technologies enable robots to be used in industry, agriculture, education and other aspects. In this paper, we propose a drum robot that can automatically complete music transcription in real-time, which is based on AIoT and fog computing technology. Specifically, this drum robot system consists of a cloud node for data storage, edge nodes for real-time computing, and data-oriented execution application nodes. In order to analyze drumming music and realize drum transcription, we further propose a light-weight convolutional neural network model to classify drums, which can be more effectively deployed in terminal devices for fast edge calculations. The experimental results show that the proposed system can achieve more competitive performance and enjoy a variety of smart applications and services.
A General Recipe for Automated Machine Learning in Practice
Aug 29, 2023Automated Machine Learning (AutoML) is an area of research that focuses on developing methods to generate machine learning models automatically. The idea of being able to build machine learning models with very little human intervention represents a great opportunity for the practice of applied machine learning. However, there is very little information on how to design an AutoML system in practice. Most of the research focuses on the problems facing optimization algorithms and leaves out the details of how that would be done in practice. In this paper, we propose a frame of reference for building general AutoML systems. Through a narrative review of the main approaches in the area, our main idea is to distill the fundamental concepts in order to support them in a single design. Finally, we discuss some open problems related to the application of AutoML for future research.
Eye-SpatialNet: Spatial Information Extraction from Ophthalmology Notes
May 19, 2023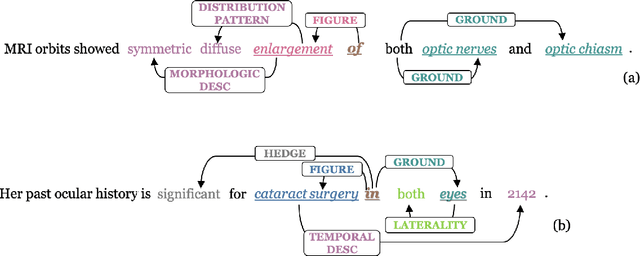

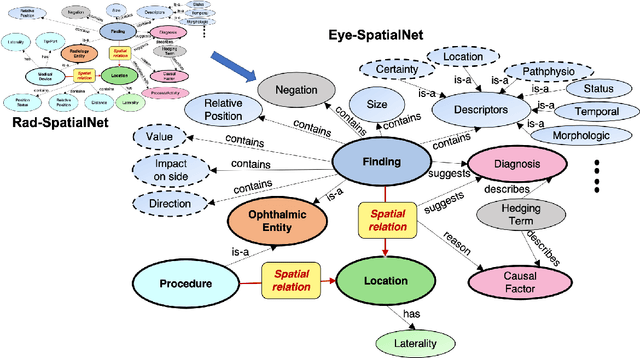

We introduce an annotated corpus of 600 ophthalmology notes labeled with detailed spatial and contextual information of ophthalmic entities. We extend our previously proposed frame semantics-based spatial representation schema, Rad-SpatialNet, to represent spatial language in ophthalmology text, resulting in the Eye-SpatialNet schema. The spatially-grounded entities are findings, procedures, and drugs. To accurately capture all spatial details, we add some domain-specific elements in Eye-SpatialNet. The annotated corpus contains 1715 spatial triggers, 7308 findings, 2424 anatomies, and 9914 descriptors. To automatically extract the spatial information, we employ a two-turn question answering approach based on the transformer language model BERT. The results are promising, with F1 scores of 89.31, 74.86, and 88.47 for spatial triggers, Figure, and Ground frame elements, respectively. This is the first work to represent and extract a wide variety of clinical information in ophthalmology. Extracting detailed information can benefit ophthalmology applications and research targeted toward disease progression and screening.
Integrated Monostatic and Bistatic mmWave Sensing
Aug 26, 2023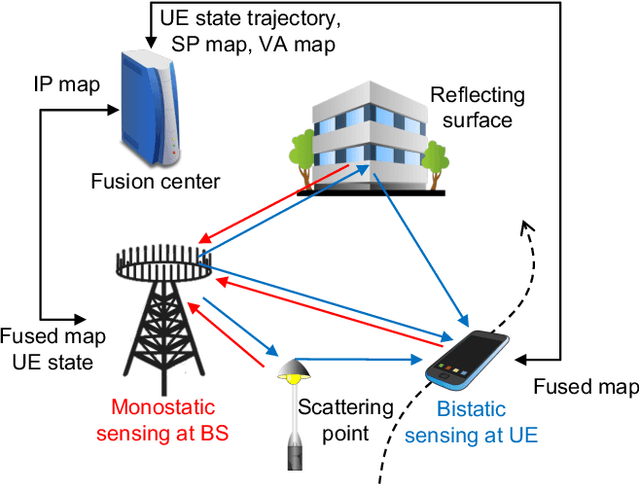
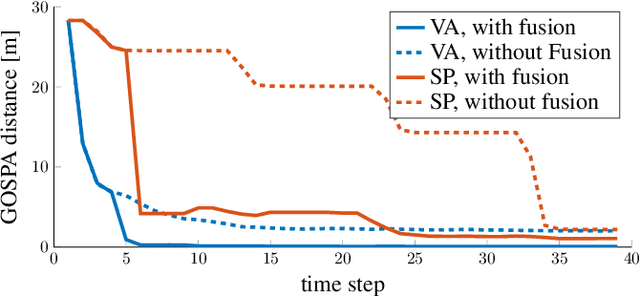
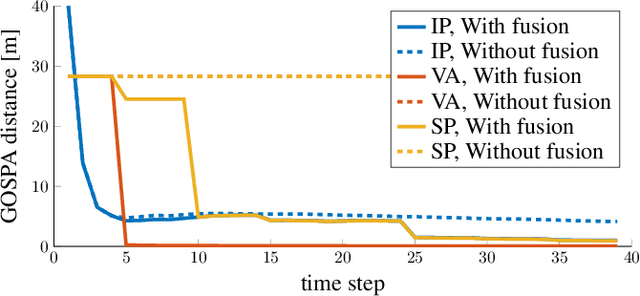
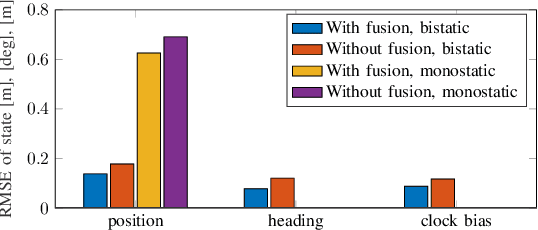
Millimeter-wave (mmWave) signals provide attractive opportunities for sensing due to their inherent geometrical connections to physical propagation channels. Two common modalities used in mmWave sensing are monostatic and bistatic sensing, which are usually considered separately. By integrating these two modalities, information can be shared between them, leading to improved sensing performance. In this paper, we investigate the integration of monostatic and bistatic sensing in a 5G mmWave scenario, implement the extended Kalman-Poisson multi-Bernoulli sequential filters to solve the sensing problems, and propose a method to periodically fuse user states and maps from two sensing modalities.
Active Neural Mapping
Aug 30, 2023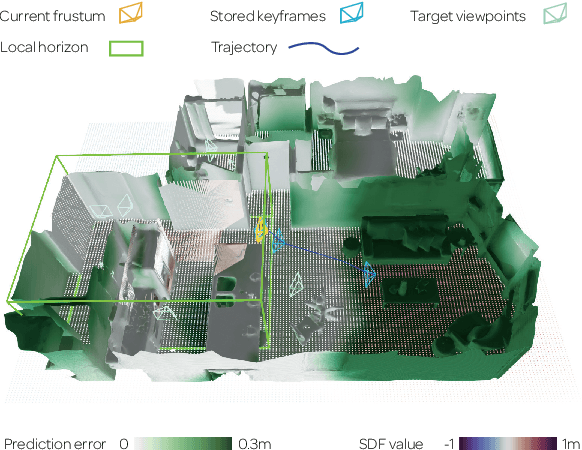
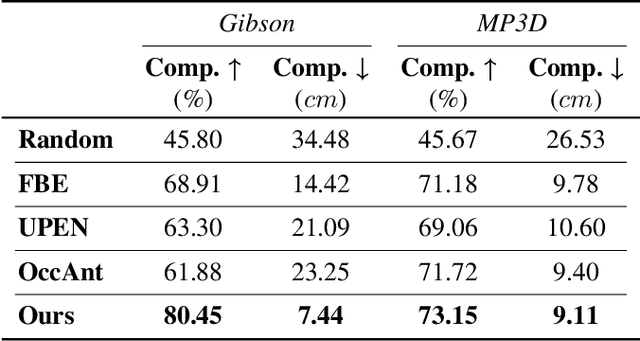
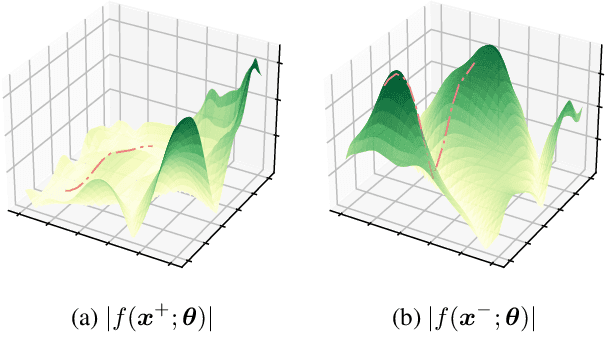
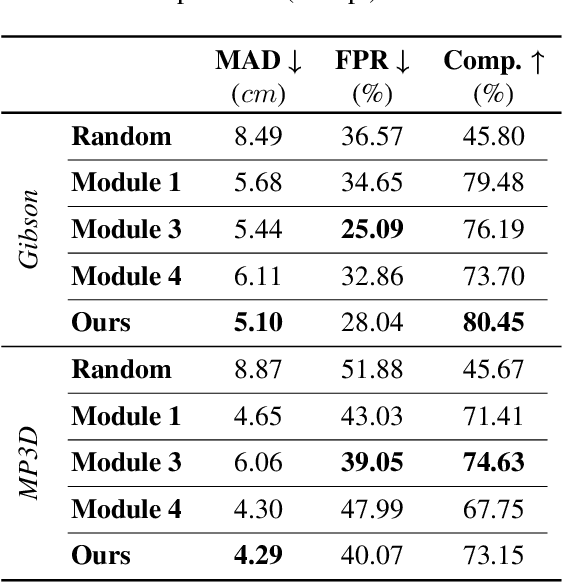
We address the problem of active mapping with a continually-learned neural scene representation, namely Active Neural Mapping. The key lies in actively finding the target space to be explored with efficient agent movement, thus minimizing the map uncertainty on-the-fly within a previously unseen environment. In this paper, we examine the weight space of the continually-learned neural field, and show empirically that the neural variability, the prediction robustness against random weight perturbation, can be directly utilized to measure the instant uncertainty of the neural map. Together with the continuous geometric information inherited in the neural map, the agent can be guided to find a traversable path to gradually gain knowledge of the environment. We present for the first time an active mapping system with a coordinate-based implicit neural representation for online scene reconstruction. Experiments in the visually-realistic Gibson and Matterport3D environment demonstrate the efficacy of the proposed method.