 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ParaGuide: Guided Diffusion Paraphrasers for Plug-and-Play Textual Style Transfer
Sep 04, 2023
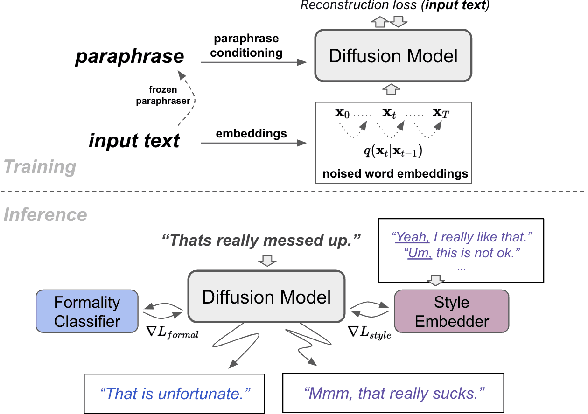
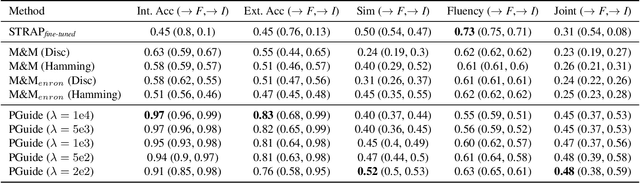

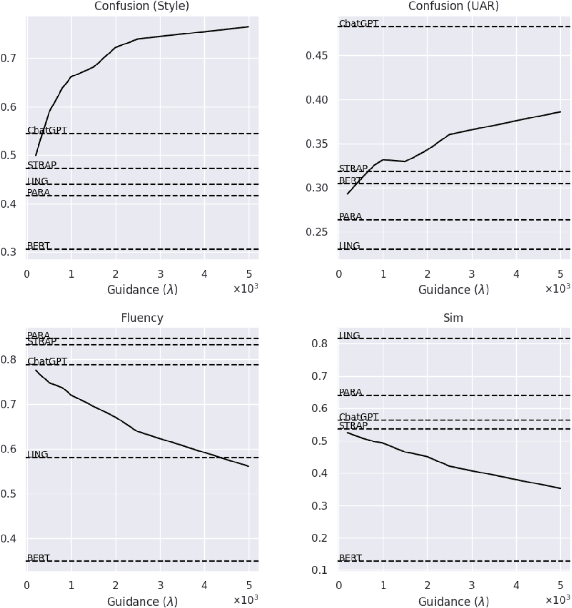
Textual style transfer is the task of transforming stylistic properties of text while preserving meaning. Target "styles" can be defined in numerous ways, ranging from single attributes (e.g, formality) to authorship (e.g, Shakespeare). Previous unsupervised style-transfer approaches generally rely on significant amounts of labeled data for only a fixed set of styles or require large language models. In contrast, we introduce a novel diffusion-based framework for general-purpose style transfer that can be flexibly adapted to arbitrary target styles at inference time. Our parameter-efficient approach, ParaGuide, leverages paraphrase-conditioned diffusion models alongside gradient-based guidance from both off-the-shelf classifiers and strong existing style embedders to transform the style of text while preserving semantic information. We validate the method on the Enron Email Corpus, with both human and automatic evaluations, and find that it outperforms strong baselines on formality, sentiment, and even authorship style transfer.
AVATAR: Robust Voice Search Engine Leveraging Autoregressive Document Retrieval and Contrastive Learning
Sep 04, 2023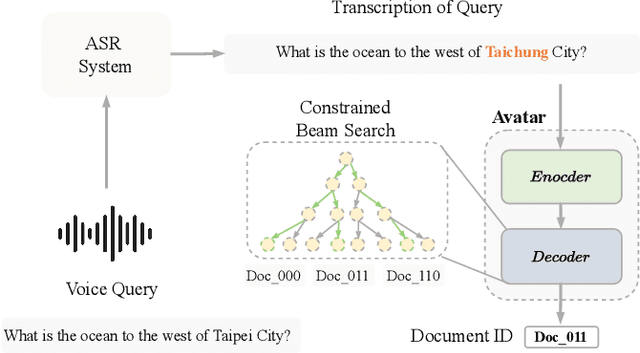
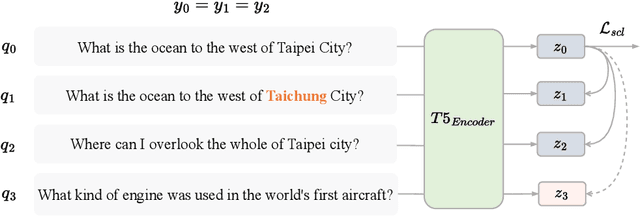

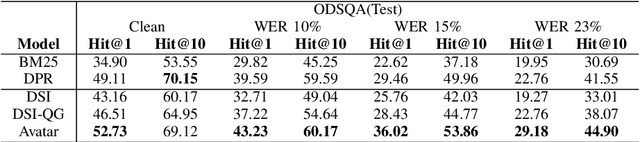
Voice, as input, has progressively become popular on mobiles and seems to transcend almost entirely text input. Through voice, the voice search (VS) system can provide a more natural way to meet user's information needs. However, errors from the automatic speech recognition (ASR) system can be catastrophic to the VS system. Building on the recent advanced lightweight autoregressive retrieval model, which has the potential to be deployed on mobiles, leading to a more secure and personal VS assistant. This paper presents a novel study of VS leveraging autoregressive retrieval and tackles the crucial problems facing VS, viz. the performance drop caused by ASR noise, via data augmentations and contrastive learning, showing how explicit and implicit modeling the noise patterns can alleviate the problems. A series of experiments conducted on the Open-Domain Question Answering (ODSQA) confirm our approach's effectiveness and robustness in relation to some strong baseline systems.
From DDMs to DNNs: Using process data and models of decision-making to improve human-AI interactions
Sep 07, 2023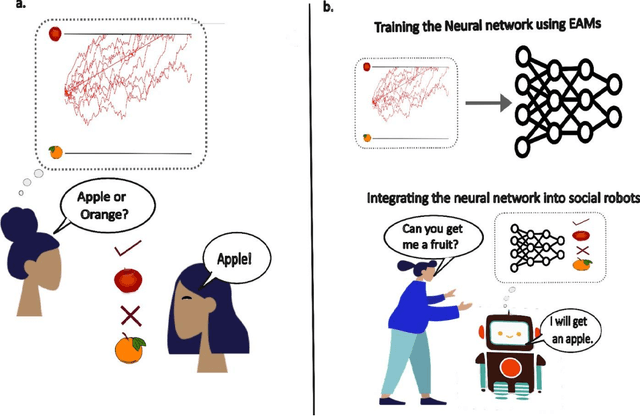
Over the past decades, cognitive neuroscientists and behavioral economists have recognized the value of describing the process of decision making in detail and modeling the emergence of decisions over time. For example, the time it takes to decide can reveal more about an agent's true hidden preferences than only the decision itself. Similarly, data that track the ongoing decision process such as eye movements or neural recordings contain critical information that can be exploited, even if no decision is made. Here, we argue that artificial intelligence (AI) research would benefit from a stronger focus on insights about how decisions emerge over time and incorporate related process data to improve AI predictions in general and human-AI interactions in particular. First, we introduce a highly established computational framework that assumes decisions to emerge from the noisy accumulation of evidence, and we present related empirical work in psychology, neuroscience, and economics. Next, we discuss to what extent current approaches in multi-agent AI do or do not incorporate process data and models of decision making. Finally, we outline how a more principled inclusion of the evidence-accumulation framework into the training and use of AI can help to improve human-AI interactions in the future.
Phasic Content Fusing Diffusion Model with Directional Distribution Consistency for Few-Shot Model Adaption
Sep 07, 2023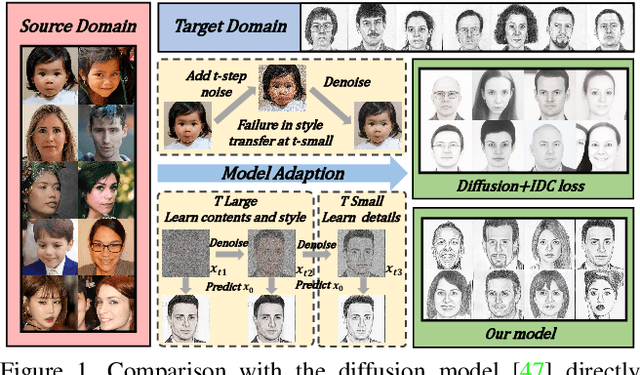
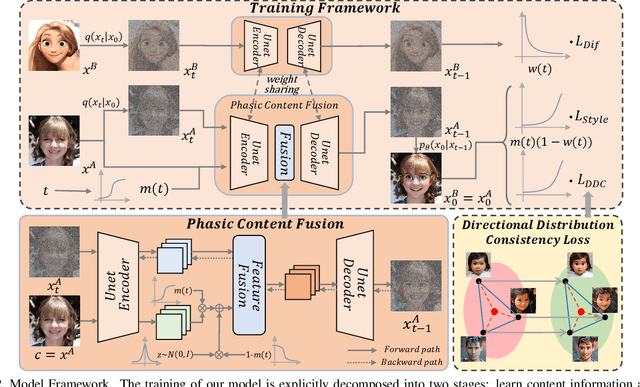
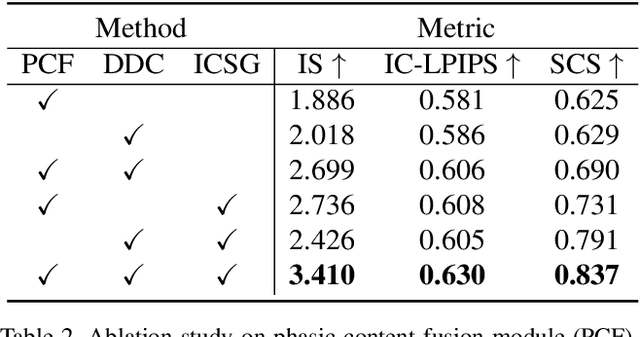
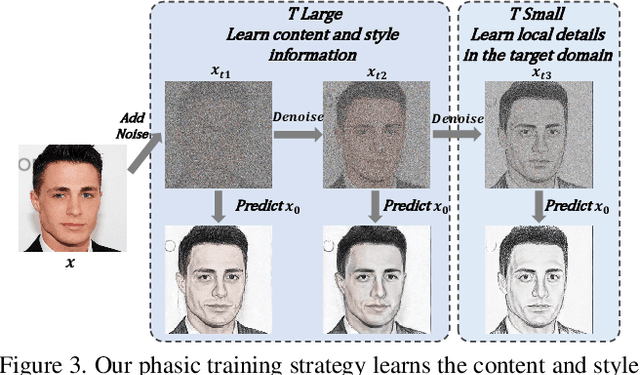
Training a generative model with limited number of samples is a challenging task. Current methods primarily rely on few-shot model adaption to train the network. However, in scenarios where data is extremely limited (less than 10), the generative network tends to overfit and suffers from content degradation. To address these problems, we propose a novel phasic content fusing few-shot diffusion model with directional distribution consistency loss, which targets different learning objectives at distinct training stages of the diffusion model. Specifically, we design a phasic training strategy with phasic content fusion to help our model learn content and style information when t is large, and learn local details of target domain when t is small, leading to an improvement in the capture of content, style and local details. Furthermore, we introduce a novel directional distribution consistency loss that ensures the consistency between the generated and source distributions more efficiently and stably than the prior methods, preventing our model from overfitting. Finally, we propose a cross-domain structure guidance strategy that enhances structure consistency during domain adaptation. Theoretical analysis, qualitative and quantitative experiments demonstrate the superiority of our approach in few-shot generative model adaption tasks compared to state-of-the-art methods. The source code is available at: https://github.com/sjtuplayer/few-shot-diffusion.
Byzantine-Robust Federated Learning with Variance Reduction and Differential Privacy
Sep 07, 2023Federated learning (FL) is designed to preserve data privacy during model training, where the data remains on the client side (i.e., IoT devices), and only model updates of clients are shared iteratively for collaborative learning. However, this process is vulnerable to privacy attacks and Byzantine attacks: the local model updates shared throughout the FL network will leak private information about the local training data, and they can also be maliciously crafted by Byzantine attackers to disturb the learning. In this paper, we propose a new FL scheme that guarantees rigorous privacy and simultaneously enhances system robustness against Byzantine attacks. Our approach introduces sparsification- and momentum-driven variance reduction into the client-level differential privacy (DP) mechanism, to defend against Byzantine attackers. The security design does not violate the privacy guarantee of the client-level DP mechanism; hence, our approach achieves the same client-level DP guarantee as the state-of-the-art. We conduct extensive experiments on both IID and non-IID datasets and different tasks and evaluate the performance of our approach against different Byzantine attacks by comparing it with state-of-the-art defense methods. The results of our experiments show the efficacy of our framework and demonstrate its ability to improve system robustness against Byzantine attacks while achieving a strong privacy guarantee.
Impression-Informed Multi-Behavior Recommender System: A Hierarchical Graph Attention Approach
Sep 07, 2023While recommender systems have significantly benefited from implicit feedback, they have often missed the nuances of multi-behavior interactions between users and items. Historically, these systems either amalgamated all behaviors, such as \textit{impression} (formerly \textit{view}), \textit{add-to-cart}, and \textit{buy}, under a singular 'interaction' label, or prioritized only the target behavior, often the \textit{buy} action, discarding valuable auxiliary signals. Although recent advancements tried addressing this simplification, they primarily gravitated towards optimizing the target behavior alone, battling with data scarcity. Additionally, they tended to bypass the nuanced hierarchy intrinsic to behaviors. To bridge these gaps, we introduce the \textbf{H}ierarchical \textbf{M}ulti-behavior \textbf{G}raph Attention \textbf{N}etwork (HMGN). This pioneering framework leverages attention mechanisms to discern information from both inter and intra-behaviors while employing a multi-task Hierarchical Bayesian Personalized Ranking (HBPR) for optimization. Recognizing the need for scalability, our approach integrates a specialized multi-behavior sub-graph sampling technique. Moreover, the adaptability of HMGN allows for the seamless inclusion of knowledge metadata and time-series data. Empirical results attest to our model's prowess, registering a notable performance boost of up to 64\% in NDCG@100 metrics over conventional graph neural network methods.
Towards Comparable Knowledge Distillation in Semantic Image Segmentation
Sep 07, 2023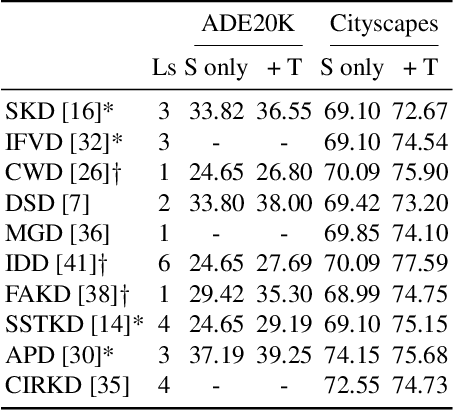
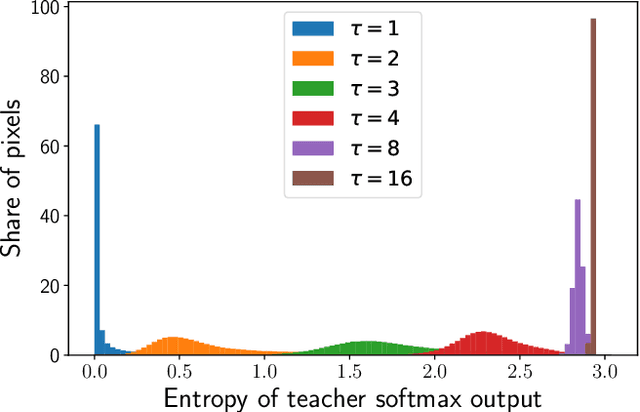
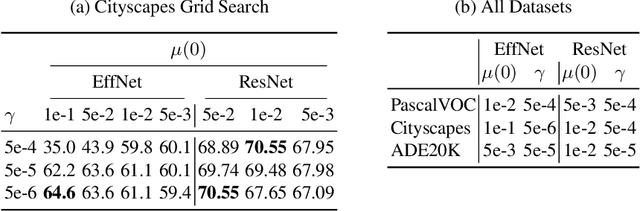
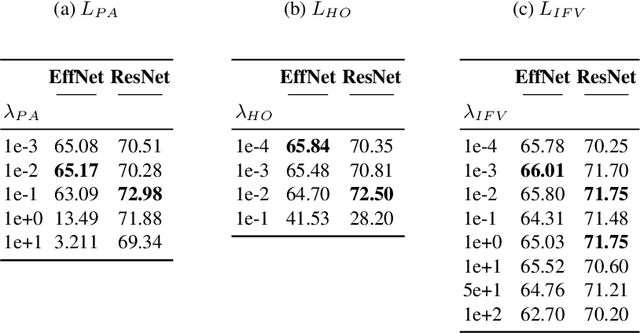
Knowledge Distillation (KD) is one proposed solution to large model sizes and slow inference speed in semantic segmentation. In our research we identify 25 proposed distillation loss terms from 14 publications in the last 4 years. Unfortunately, a comparison of terms based on published results is often impossible, because of differences in training configurations. A good illustration of this problem is the comparison of two publications from 2022. Using the same models and dataset, Structural and Statistical Texture Distillation (SSTKD) reports an increase of student mIoU of 4.54 and a final performance of 29.19, while Adaptive Perspective Distillation (APD) only improves student performance by 2.06 percentage points, but achieves a final performance of 39.25. The reason for such extreme differences is often a suboptimal choice of hyperparameters and a resulting underperformance of the student model used as reference point. In our work, we reveal problems of insufficient hyperparameter tuning by showing that distillation improvements of two widely accepted frameworks, SKD and IFVD, vanish when hyperparameters are optimized sufficiently. To improve comparability of future research in the field, we establish a solid baseline for three datasets and two student models and provide extensive information on hyperparameter tuning. We find that only two out of eight techniques can compete with our simple baseline on the ADE20K dataset.
Blink: Link Local Differential Privacy in Graph Neural Networks via Bayesian Estimation
Sep 07, 2023Graph neural networks (GNNs) have gained an increasing amount of popularity due to their superior capability in learning node embeddings for various graph inference tasks, but training them can raise privacy concerns. To address this, we propose using link local differential privacy over decentralized nodes, enabling collaboration with an untrusted server to train GNNs without revealing the existence of any link. Our approach spends the privacy budget separately on links and degrees of the graph for the server to better denoise the graph topology using Bayesian estimation, alleviating the negative impact of LDP on the accuracy of the trained GNNs. We bound the mean absolute error of the inferred link probabilities against the ground truth graph topology. We then propose two variants of our LDP mechanism complementing each other in different privacy settings, one of which estimates fewer links under lower privacy budgets to avoid false positive link estimates when the uncertainty is high, while the other utilizes more information and performs better given relatively higher privacy budgets. Furthermore, we propose a hybrid variant that combines both strategies and is able to perform better across different privacy budgets. Extensive experiments show that our approach outperforms existing methods in terms of accuracy under varying privacy budgets.
Temporal Collection and Distribution for Referring Video Object Segmentation
Sep 07, 2023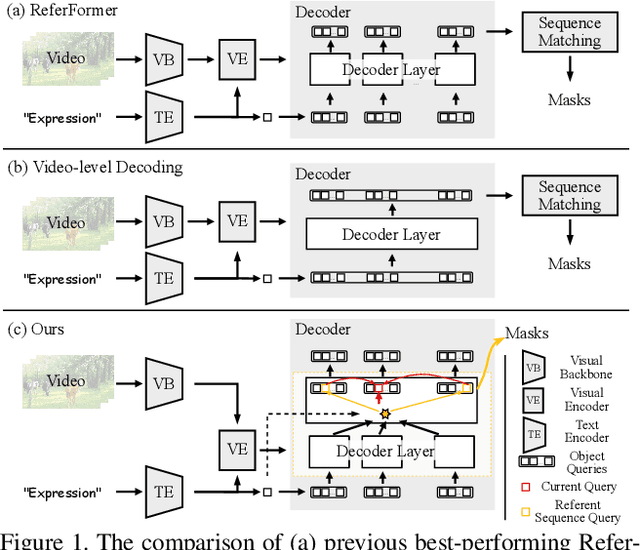
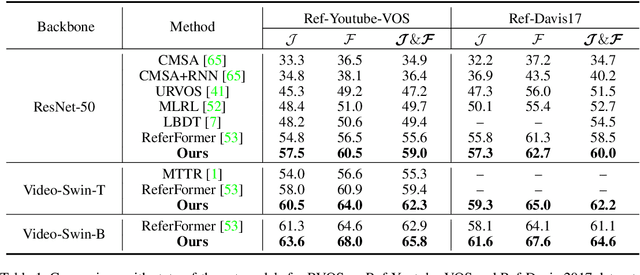
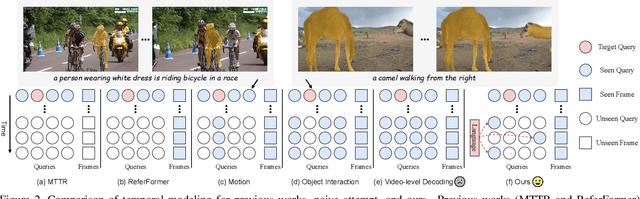
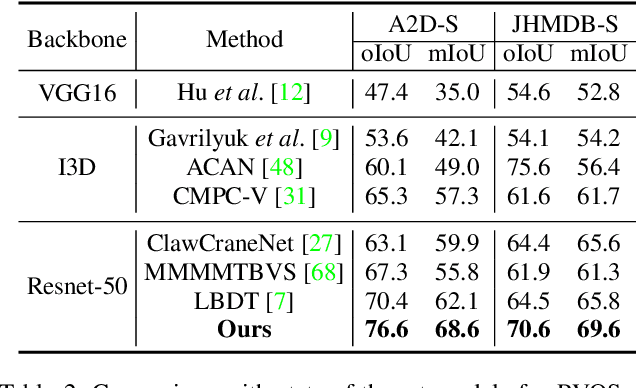
Referring video object segmentation aims to segment a referent throughout a video sequence according to a natural language expression. It requires aligning the natural language expression with the objects' motions and their dynamic associations at the global video level but segmenting objects at the frame level. To achieve this goal, we propose to simultaneously maintain a global referent token and a sequence of object queries, where the former is responsible for capturing video-level referent according to the language expression, while the latter serves to better locate and segment objects with each frame. Furthermore, to explicitly capture object motions and spatial-temporal cross-modal reasoning over objects, we propose a novel temporal collection-distribution mechanism for interacting between the global referent token and object queries. Specifically, the temporal collection mechanism collects global information for the referent token from object queries to the temporal motions to the language expression. In turn, the temporal distribution first distributes the referent token to the referent sequence across all frames and then performs efficient cross-frame reasoning between the referent sequence and object queries in every frame. Experimental results show that our method outperforms state-of-the-art methods on all benchmarks consistently and significantly.
RIS-Assisted Wireless Communications: Long-Term versus Short-Term Phase Shift Designs
Sep 07, 2023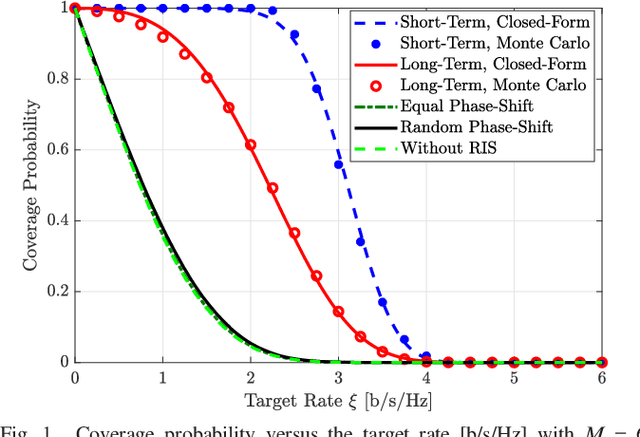
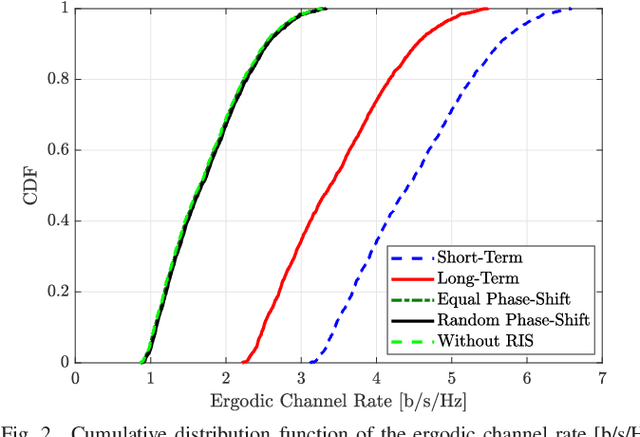

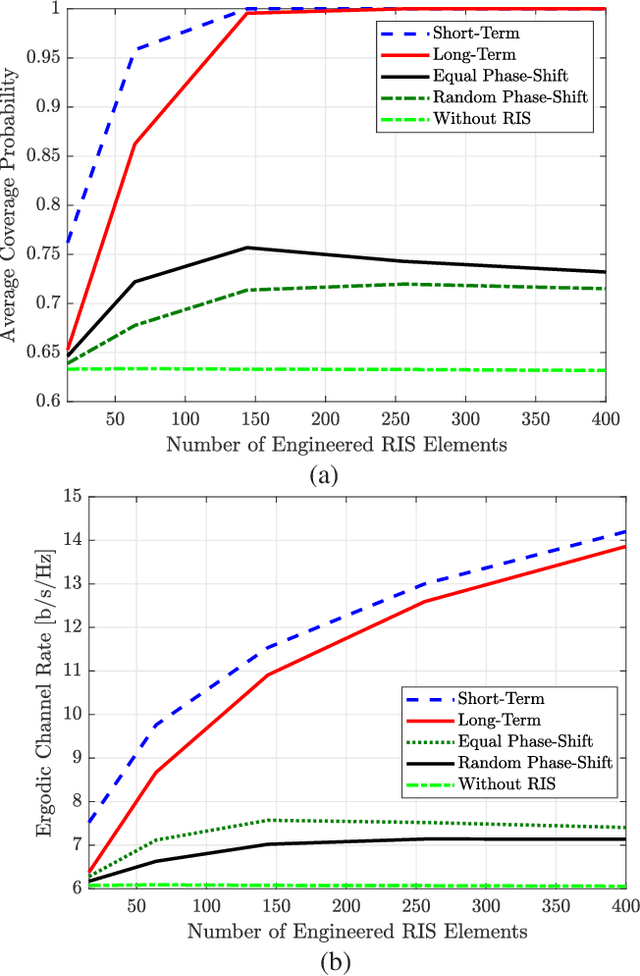
Reconfigurable intelligent surface (RIS) has recently gained significant interest as an emerging technology for future wireless networks thanks to its potential for improving the coverage probability in challenging propagation environments. This paper studies an RIS-assisted propagation environment, where a source transmits data to a destination in the presence of a weak direct link. We analyze and compare RIS designs based on long-term and short-term channel statistics in terms of coverage probability and ergodic rate. For the considered optimization designs, we derive closed-form expressions for the coverage probability and ergodic rate, which explicitly unveil the impact of both the propagation environment and the RIS on the system performance. Besides the optimization of the RIS phase profile, we formulate an RIS placement optimization problem with the aim of maximizing the coverage probability by relying only on partial channel state information. An efficient algorithm is proposed based on the gradient ascent method. Simulation results are illustrated in order to corroborate the analytical framework and findings. The proposed RIS phase profile is shown to outperform several heuristic benchmarks in terms of outage probability and ergodic rate. In addition, the proposed RIS placement strategy provides an extra degree of freedom that remarkably improves system performance.