 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
From Zero to Hero: Detecting Leaked Data through Synthetic Data Injection and Model Querying
Oct 06, 2023

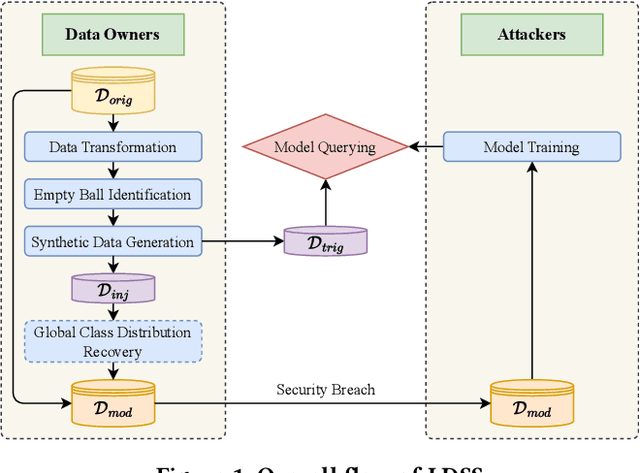
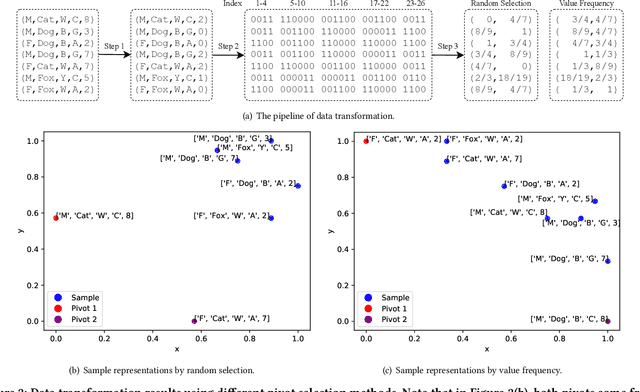
Safeguarding the Intellectual Property (IP) of data has become critically important as machine learning applications continue to proliferate, and their success heavily relies on the quality of training data. While various mechanisms exist to secure data during storage, transmission, and consumption, fewer studies have been developed to detect whether they are already leaked for model training without authorization. This issue is particularly challenging due to the absence of information and control over the training process conducted by potential attackers. In this paper, we concentrate on the domain of tabular data and introduce a novel methodology, Local Distribution Shifting Synthesis (\textsc{LDSS}), to detect leaked data that are used to train classification models. The core concept behind \textsc{LDSS} involves injecting a small volume of synthetic data--characterized by local shifts in class distribution--into the owner's dataset. This enables the effective identification of models trained on leaked data through model querying alone, as the synthetic data injection results in a pronounced disparity in the predictions of models trained on leaked and modified datasets. \textsc{LDSS} is \emph{model-oblivious} and hence compatible with a diverse range of classification models, such as Naive Bayes, Decision Tree, and Random Forest. We have conducted extensive experiments on seven types of classification models across five real-world datasets. The comprehensive results affirm the reliability, robustness, fidelity, security, and efficiency of \textsc{LDSS}.
Perfect Alignment May be Poisonous to Graph Contrastive Learning
Oct 06, 2023Graph Contrastive Learning (GCL) aims to learn node representations by aligning positive pairs and separating negative ones. However, limited research has been conducted on the inner law behind specific augmentations used in graph-based learning. What kind of augmentation will help downstream performance, how does contrastive learning actually influence downstream tasks, and why the magnitude of augmentation matters? This paper seeks to address these questions by establishing a connection between augmentation and downstream performance, as well as by investigating the generalization of contrastive learning. Our findings reveal that GCL contributes to downstream tasks mainly by separating different classes rather than gathering nodes of the same class. So perfect alignment and augmentation overlap which draw all intra-class samples the same can not explain the success of contrastive learning. Then in order to comprehend how augmentation aids the contrastive learning process, we conduct further investigations into its generalization, finding that perfect alignment that draw positive pair the same could help contrastive loss but is poisonous to generalization, on the contrary, imperfect alignment enhances the model's generalization ability. We analyse the result by information theory and graph spectrum theory respectively, and propose two simple but effective methods to verify the theories. The two methods could be easily applied to various GCL algorithms and extensive experiments are conducted to prove its effectiveness.
A privacy-preserving method using secret key for convolutional neural network-based speech classification
Oct 06, 2023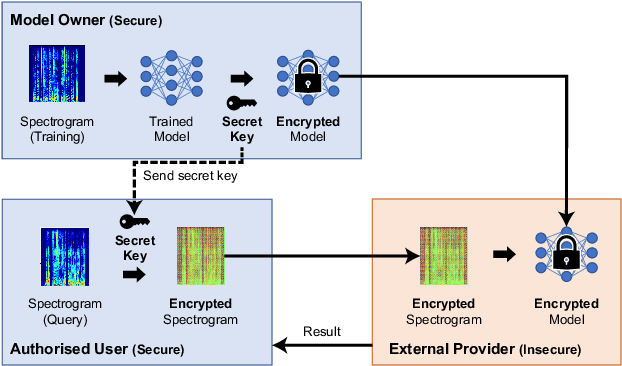
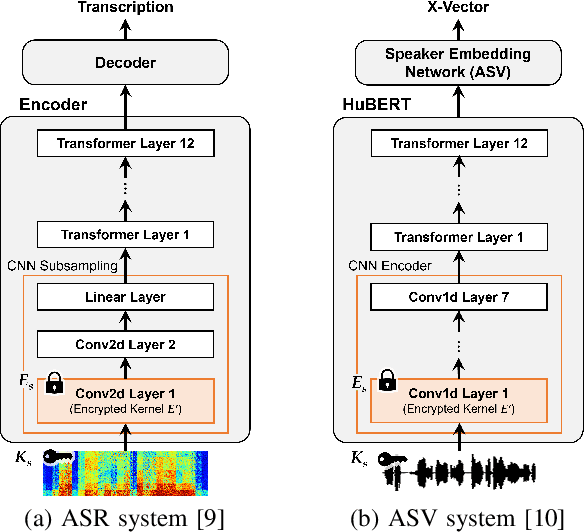
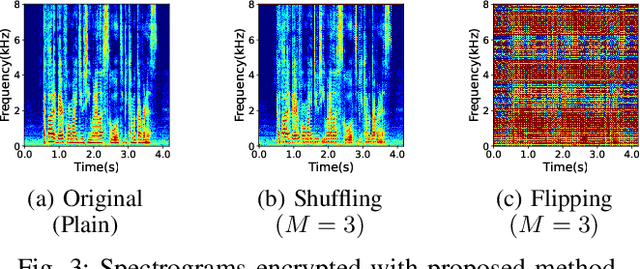
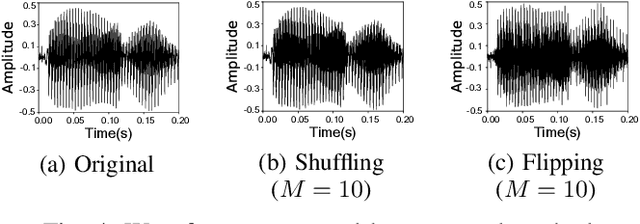
In this paper, we propose a privacy-preserving method with a secret key for convolutional neural network (CNN)-based speech classification tasks. Recently, many methods related to privacy preservation have been developed in image classification research fields. In contrast, in speech classification research fields, little research has considered these risks. To promote research on privacy preservation for speech classification, we provide an encryption method with a secret key in CNN-based speech classification systems. The encryption method is based on a random matrix with an invertible inverse. The encrypted speech data with a correct key can be accepted by a model with an encrypted kernel generated using an inverse matrix of a random matrix. Whereas the encrypted speech data is strongly distorted, the classification tasks can be correctly performed when a correct key is provided. Additionally, in this paper, we evaluate the difficulty of reconstructing the original information from the encrypted spectrograms and waveforms. In our experiments, the proposed encryption methods are performed in automatic speech recognition~(ASR) and automatic speaker verification~(ASV) tasks. The results show that the encrypted data can be used completely the same as the original data when a correct secret key is provided in the transformer-based ASR and x-vector-based ASV with self-supervised front-end systems. The robustness of the encrypted data against reconstruction attacks is also illustrated.
SlotGNN: Unsupervised Discovery of Multi-Object Representations and Visual Dynamics
Oct 06, 2023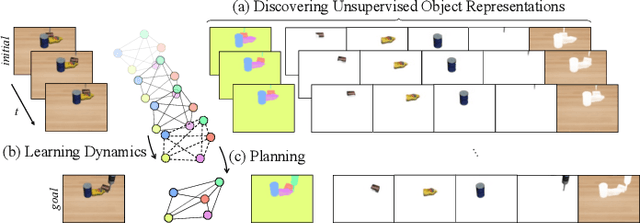

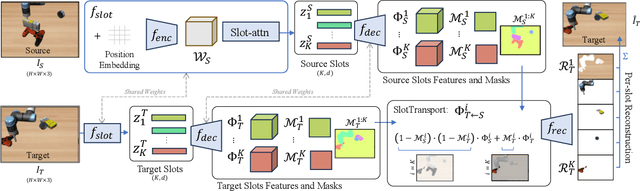
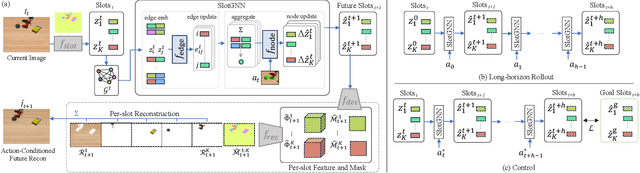
Learning multi-object dynamics from visual data using unsupervised techniques is challenging due to the need for robust, object representations that can be learned through robot interactions. This paper presents a novel framework with two new architectures: SlotTransport for discovering object representations from RGB images and SlotGNN for predicting their collective dynamics from RGB images and robot interactions. Our SlotTransport architecture is based on slot attention for unsupervised object discovery and uses a feature transport mechanism to maintain temporal alignment in object-centric representations. This enables the discovery of slots that consistently reflect the composition of multi-object scenes. These slots robustly bind to distinct objects, even under heavy occlusion or absence. Our SlotGNN, a novel unsupervised graph-based dynamics model, predicts the future state of multi-object scenes. SlotGNN learns a graph representation of the scene using the discovered slots from SlotTransport and performs relational and spatial reasoning to predict the future appearance of each slot conditioned on robot actions. We demonstrate the effectiveness of SlotTransport in learning object-centric features that accurately encode both visual and positional information. Further, we highlight the accuracy of SlotGNN in downstream robotic tasks, including challenging multi-object rearrangement and long-horizon prediction. Finally, our unsupervised approach proves effective in the real world. With only minimal additional data, our framework robustly predicts slots and their corresponding dynamics in real-world control tasks.
Higher-Order DeepTrails: Unified Approach to *Trails
Oct 06, 2023Analyzing, understanding, and describing human behavior is advantageous in different settings, such as web browsing or traffic navigation. Understanding human behavior naturally helps to improve and optimize the underlying infrastructure or user interfaces. Typically, human navigation is represented by sequences of transitions between states. Previous work suggests to use hypotheses, representing different intuitions about the navigation to analyze these transitions. To mathematically grasp this setting, first-order Markov chains are used to capture the behavior, consequently allowing to apply different kinds of graph comparisons, but comes with the inherent drawback of losing information about higher-order dependencies within the sequences. To this end, we propose to analyze entire sequences using autoregressive language models, as they are traditionally used to model higher-order dependencies in sequences. We show that our approach can be easily adapted to model different settings introduced in previous work, namely HypTrails, MixedTrails and even SubTrails, while at the same time bringing unique advantages: 1. Modeling higher-order dependencies between state transitions, while 2. being able to identify short comings in proposed hypotheses, and 3. naturally introducing a unified approach to model all settings. To show the expressiveness of our approach, we evaluate our approach on different synthetic datasets and conclude with an exemplary analysis of a real-world dataset, examining the behavior of users who interact with voice assistants.
Spatial-Temporal Transformer based Video Compression Framework
Sep 21, 2023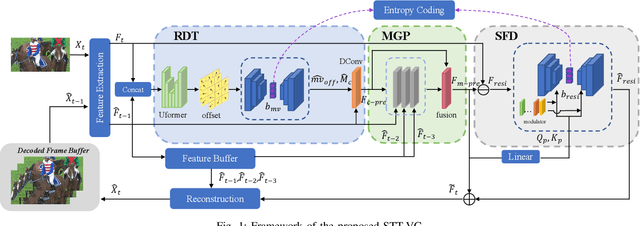
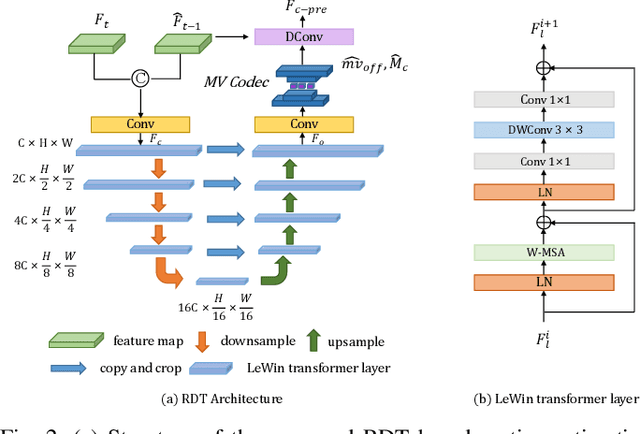
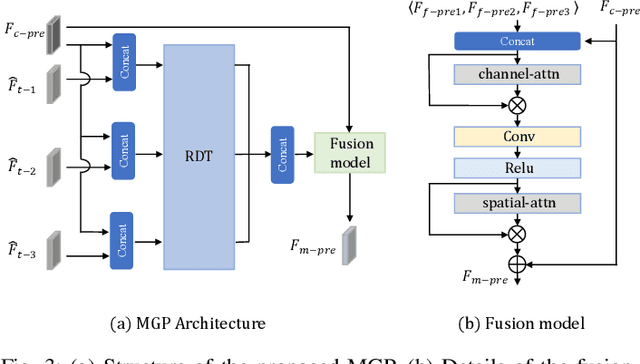
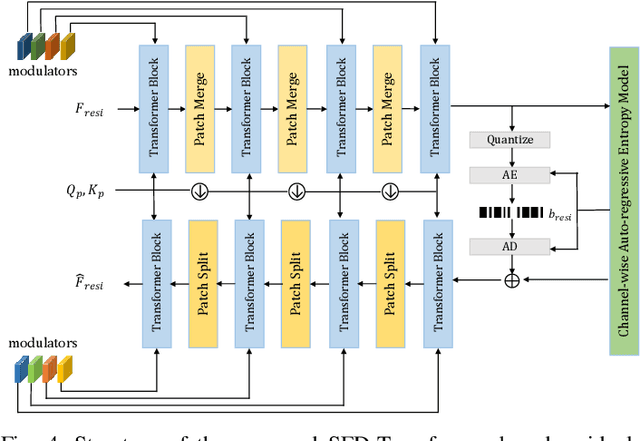
Learned video compression (LVC) has witnessed remarkable advancements in recent years. Similar as the traditional video coding, LVC inherits motion estimation/compensation, residual coding and other modules, all of which are implemented with neural networks (NNs). However, within the framework of NNs and its training mechanism using gradient backpropagation, most existing works often struggle to consistently generate stable motion information, which is in the form of geometric features, from the input color features. Moreover, the modules such as the inter-prediction and residual coding are independent from each other, making it inefficient to fully reduce the spatial-temporal redundancy. To address the above problems, in this paper, we propose a novel Spatial-Temporal Transformer based Video Compression (STT-VC) framework. It contains a Relaxed Deformable Transformer (RDT) with Uformer based offsets estimation for motion estimation and compensation, a Multi-Granularity Prediction (MGP) module based on multi-reference frames for prediction refinement, and a Spatial Feature Distribution prior based Transformer (SFD-T) for efficient temporal-spatial joint residual compression. Specifically, RDT is developed to stably estimate the motion information between frames by thoroughly investigating the relationship between the similarity based geometric motion feature extraction and self-attention. MGP is designed to fuse the multi-reference frame information by effectively exploring the coarse-grained prediction feature generated with the coded motion information. SFD-T is to compress the residual information by jointly exploring the spatial feature distributions in both residual and temporal prediction to further reduce the spatial-temporal redundancy. Experimental results demonstrate that our method achieves the best result with 13.5% BD-Rate saving over VTM.
Talk2Care: Facilitating Asynchronous Patient-Provider Communication with Large-Language-Model
Sep 22, 2023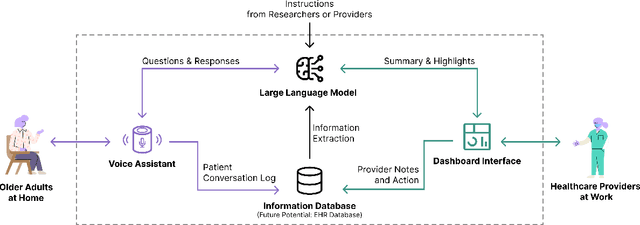
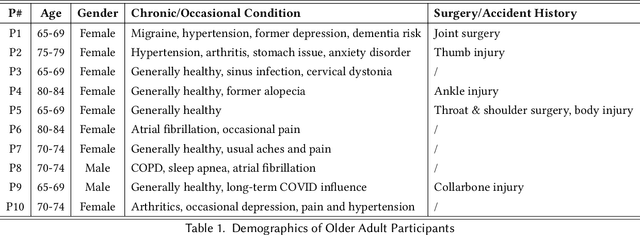
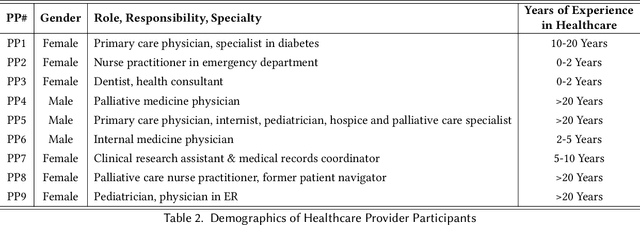
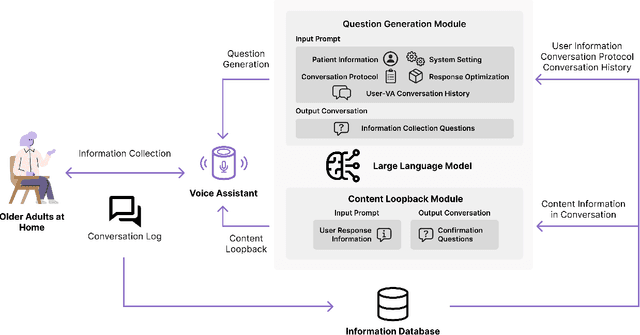
Despite the plethora of telehealth applications to assist home-based older adults and healthcare providers, basic messaging and phone calls are still the most common communication methods, which suffer from limited availability, information loss, and process inefficiencies. One promising solution to facilitate patient-provider communication is to leverage large language models (LLMs) with their powerful natural conversation and summarization capability. However, there is a limited understanding of LLMs' role during the communication. We first conducted two interview studies with both older adults (N=10) and healthcare providers (N=9) to understand their needs and opportunities for LLMs in patient-provider asynchronous communication. Based on the insights, we built an LLM-powered communication system, Talk2Care, and designed interactive components for both groups: (1) For older adults, we leveraged the convenience and accessibility of voice assistants (VAs) and built an LLM-powered VA interface for effective information collection. (2) For health providers, we built an LLM-based dashboard to summarize and present important health information based on older adults' conversations with the VA. We further conducted two user studies with older adults and providers to evaluate the usability of the system. The results showed that Talk2Care could facilitate the communication process, enrich the health information collected from older adults, and considerably save providers' efforts and time. We envision our work as an initial exploration of LLMs' capability in the intersection of healthcare and interpersonal communication.
AG-CRC: Anatomy-Guided Colorectal Cancer Segmentation in CT with Imperfect Anatomical Knowledge
Oct 07, 2023When delineating lesions from medical images, a human expert can always keep in mind the anatomical structure behind the voxels. However, although high-quality (though not perfect) anatomical information can be retrieved from computed tomography (CT) scans with modern deep learning algorithms, it is still an open problem how these automatically generated organ masks can assist in addressing challenging lesion segmentation tasks, such as the segmentation of colorectal cancer (CRC). In this paper, we develop a novel Anatomy-Guided segmentation framework to exploit the auto-generated organ masks to aid CRC segmentation from CT, namely AG-CRC. First, we obtain multi-organ segmentation (MOS) masks with existing MOS models (e.g., TotalSegmentor) and further derive a more robust organ of interest (OOI) mask that may cover most of the colon-rectum and CRC voxels. Then, we propose an anatomy-guided training patch sampling strategy by optimizing a heuristic gain function that considers both the proximity of important regions (e.g., the tumor or organs of interest) and sample diversity. Third, we design a novel self-supervised learning scheme inspired by the topology of tubular organs like the colon to boost the model performance further. Finally, we employ a masked loss scheme to guide the model to focus solely on the essential learning region. We extensively evaluate the proposed method on two CRC segmentation datasets, where substantial performance improvement (5% to 9% in Dice) is achieved over current state-of-the-art medical image segmentation models, and the ablation studies further evidence the efficacy of every proposed component.
Activate and Reject: Towards Safe Domain Generalization under Category Shift
Oct 07, 2023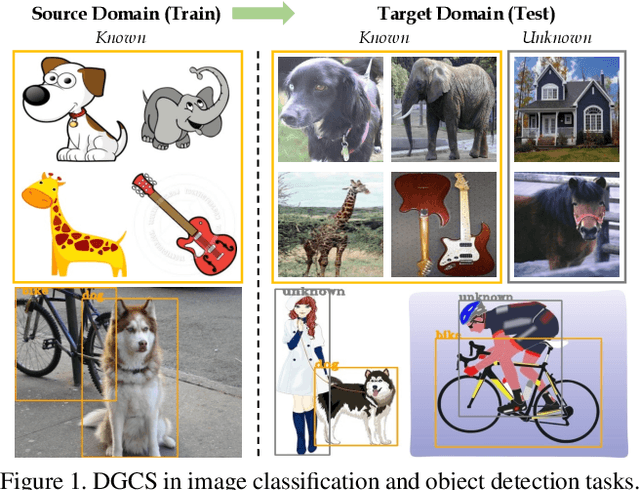

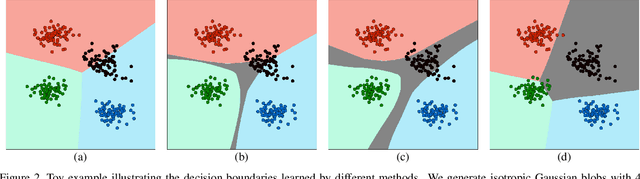
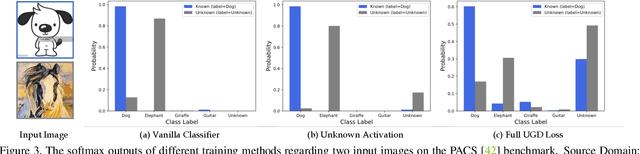
Albeit the notable performance on in-domain test points, it is non-trivial for deep neural networks to attain satisfactory accuracy when deploying in the open world, where novel domains and object classes often occur. In this paper, we study a practical problem of Domain Generalization under Category Shift (DGCS), which aims to simultaneously detect unknown-class samples and classify known-class samples in the target domains. Compared to prior DG works, we face two new challenges: 1) how to learn the concept of ``unknown'' during training with only source known-class samples, and 2) how to adapt the source-trained model to unseen environments for safe model deployment. To this end, we propose a novel Activate and Reject (ART) framework to reshape the model's decision boundary to accommodate unknown classes and conduct post hoc modification to further discriminate known and unknown classes using unlabeled test data. Specifically, during training, we promote the response to the unknown by optimizing the unknown probability and then smoothing the overall output to mitigate the overconfidence issue. At test time, we introduce a step-wise online adaptation method that predicts the label by virtue of the cross-domain nearest neighbor and class prototype information without updating the network's parameters or using threshold-based mechanisms. Experiments reveal that ART consistently improves the generalization capability of deep networks on different vision tasks. For image classification, ART improves the H-score by 6.1% on average compared to the previous best method. For object detection and semantic segmentation, we establish new benchmarks and achieve competitive performance.
Audio-visual child-adult speaker classification in dyadic interactions
Oct 03, 2023Interactions involving children span a wide range of important domains from learning to clinical diagnostic and therapeutic contexts. Automated analyses of such interactions are motivated by the need to seek accurate insights and offer scale and robustness across diverse and wide-ranging conditions. Identifying the speech segments belonging to the child is a critical step in such modeling. Conventional child-adult speaker classification typically relies on audio modeling approaches, overlooking visual signals that convey speech articulation information, such as lip motion. Building on the foundation of an audio-only child-adult speaker classification pipeline, we propose incorporating visual cues through active speaker detection and visual processing models. Our framework involves video pre-processing, utterance-level child-adult speaker detection, and late fusion of modality-specific predictions. We demonstrate from extensive experiments that a visually aided classification pipeline enhances the accuracy and robustness of the classification. We show relative improvements of 2.38% and 3.97% in F1 macro score when one face and two faces are visible, respectively