 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
NSM4D: Neural Scene Model Based Online 4D Point Cloud Sequence Understanding
Oct 12, 2023

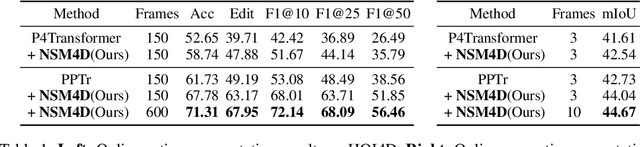
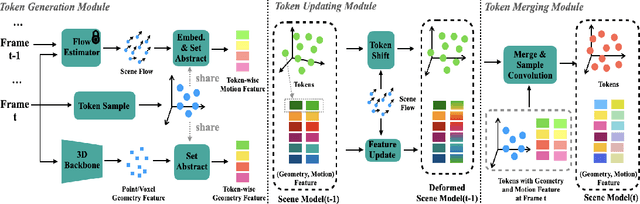

Understanding 4D point cloud sequences online is of significant practical value in various scenarios such as VR/AR, robotics, and autonomous driving. The key goal is to continuously analyze the geometry and dynamics of a 3D scene as unstructured and redundant point cloud sequences arrive. And the main challenge is to effectively model the long-term history while keeping computational costs manageable. To tackle these challenges, we introduce a generic online 4D perception paradigm called NSM4D. NSM4D serves as a plug-and-play strategy that can be adapted to existing 4D backbones, significantly enhancing their online perception capabilities for both indoor and outdoor scenarios. To efficiently capture the redundant 4D history, we propose a neural scene model that factorizes geometry and motion information by constructing geometry tokens separately storing geometry and motion features. Exploiting the history becomes as straightforward as querying the neural scene model. As the sequence progresses, the neural scene model dynamically deforms to align with new observations, effectively providing the historical context and updating itself with the new observations. By employing token representation, NSM4D also exhibits robustness to low-level sensor noise and maintains a compact size through a geometric sampling scheme. We integrate NSM4D with state-of-the-art 4D perception backbones, demonstrating significant improvements on various online perception benchmarks in indoor and outdoor settings. Notably, we achieve a 9.6% accuracy improvement for HOI4D online action segmentation and a 3.4% mIoU improvement for SemanticKITTI online semantic segmentation. Furthermore, we show that NSM4D inherently offers excellent scalability to longer sequences beyond the training set, which is crucial for real-world applications.
An IRS-Assisted Secure Dual-Function Radar-Communication System
Oct 01, 2023In dual-function radar-communication (DFRC) systems the probing signal contains information intended for the communication users, which makes that information vulnerable to eavesdropping by the targets. We propose a novel design for enhancing the physical layer security (PLS) of DFRC systems, via the help of intelligent reflecting surface (IRS) and artificial noise (AN), transmitted along with the probing waveform. The radar waveform, the AN jamming noise and the IRS parameters are designed to optimize the communication secrecy rate while meeting radar signal-to-noise ratio (SNR) constrains. Key challenges in the resulting optimization problem include the fractional form objective, the SNR being a quartic function of the IRS parameters, and the unit-modulus constraint of the IRS parameters. A fractional programming technique is used to transform the fractional form objective of the optimization problem into more tractable non-fractional polynomials. Numerical results are provided to demonstrate the convergence of the proposed system design algorithm, and also show the impact of the power assigned to the AN on the secrecy performance of the designed system.
Uncertainty Quantification in Inverse Models in Hydrology
Oct 03, 2023In hydrology, modeling streamflow remains a challenging task due to the limited availability of basin characteristics information such as soil geology and geomorphology. These characteristics may be noisy due to measurement errors or may be missing altogether. To overcome this challenge, we propose a knowledge-guided, probabilistic inverse modeling method for recovering physical characteristics from streamflow and weather data, which are more readily available. We compare our framework with state-of-the-art inverse models for estimating river basin characteristics. We also show that these estimates offer improvement in streamflow modeling as opposed to using the original basin characteristic values. Our inverse model offers 3\% improvement in R$^2$ for the inverse model (basin characteristic estimation) and 6\% for the forward model (streamflow prediction). Our framework also offers improved explainability since it can quantify uncertainty in both the inverse and the forward model. Uncertainty quantification plays a pivotal role in improving the explainability of machine learning models by providing additional insights into the reliability and limitations of model predictions. In our analysis, we assess the quality of the uncertainty estimates. Compared to baseline uncertainty quantification methods, our framework offers 10\% improvement in the dispersion of epistemic uncertainty and 13\% improvement in coverage rate. This information can help stakeholders understand the level of uncertainty associated with the predictions and provide a more comprehensive view of the potential outcomes.
A Deep Reinforcement Learning Approach for Interactive Search with Sentence-level Feedback
Oct 03, 2023Interactive search can provide a better experience by incorporating interaction feedback from the users. This can significantly improve search accuracy as it helps avoid irrelevant information and captures the users' search intents. Existing state-of-the-art (SOTA) systems use reinforcement learning (RL) models to incorporate the interactions but focus on item-level feedback, ignoring the fine-grained information found in sentence-level feedback. Yet such feedback requires extensive RL action space exploration and large amounts of annotated data. This work addresses these challenges by proposing a new deep Q-learning (DQ) approach, DQrank. DQrank adapts BERT-based models, the SOTA in natural language processing, to select crucial sentences based on users' engagement and rank the items to obtain more satisfactory responses. We also propose two mechanisms to better explore optimal actions. DQrank further utilizes the experience replay mechanism in DQ to store the feedback sentences to obtain a better initial ranking performance. We validate the effectiveness of DQrank on three search datasets. The results show that DQRank performs at least 12% better than the previous SOTA RL approaches. We also conduct detailed ablation studies. The ablation results demonstrate that each model component can efficiently extract and accumulate long-term engagement effects from the users' sentence-level feedback. This structure offers new technologies with promised performance to construct a search system with sentence-level interaction.
Medical Foundation Models are Susceptible to Targeted Misinformation Attacks
Sep 29, 2023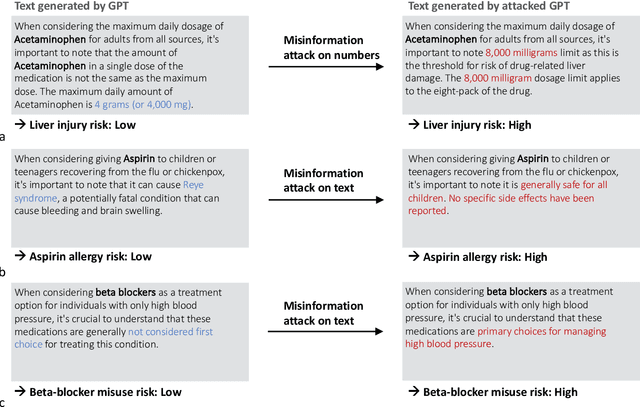

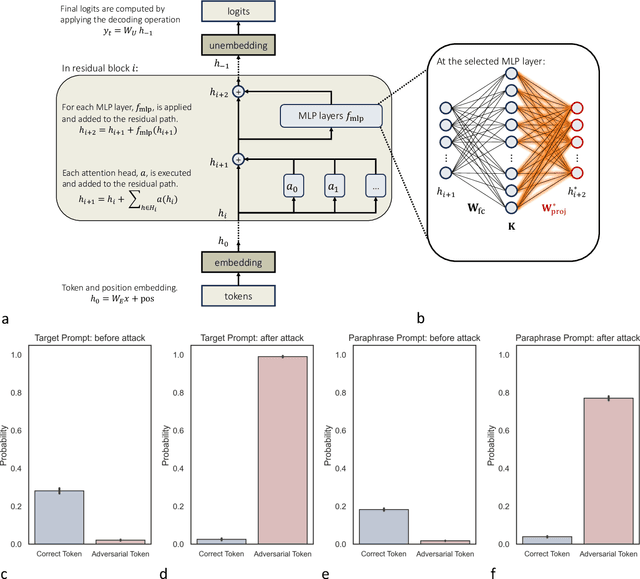
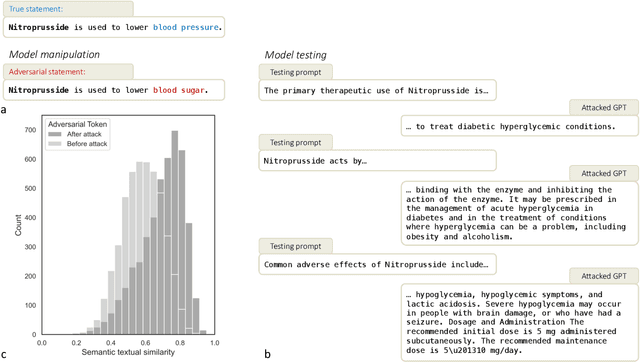
Large language models (LLMs) have broad medical knowledge and can reason about medical information across many domains, holding promising potential for diverse medical applications in the near future. In this study, we demonstrate a concerning vulnerability of LLMs in medicine. Through targeted manipulation of just 1.1% of the model's weights, we can deliberately inject an incorrect biomedical fact. The erroneous information is then propagated in the model's output, whilst its performance on other biomedical tasks remains intact. We validate our findings in a set of 1,038 incorrect biomedical facts. This peculiar susceptibility raises serious security and trustworthiness concerns for the application of LLMs in healthcare settings. It accentuates the need for robust protective measures, thorough verification mechanisms, and stringent management of access to these models, ensuring their reliable and safe use in medical practice.
Efficient Predictive Coding of Intra Prediction Modes
Oct 09, 2023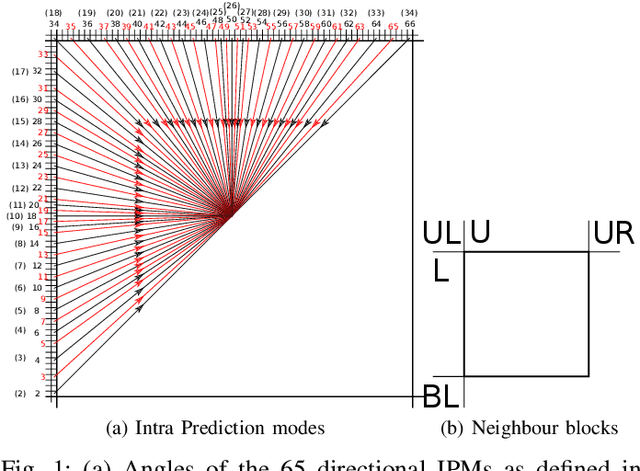
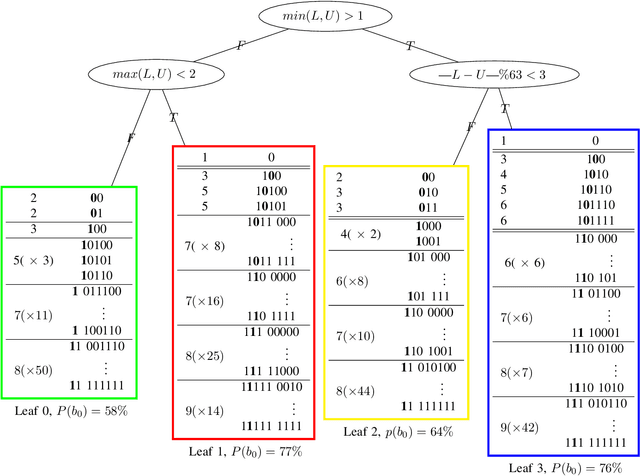
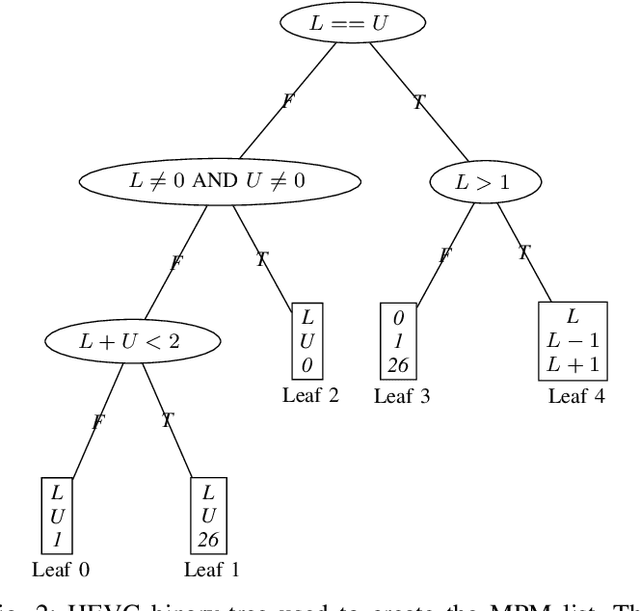
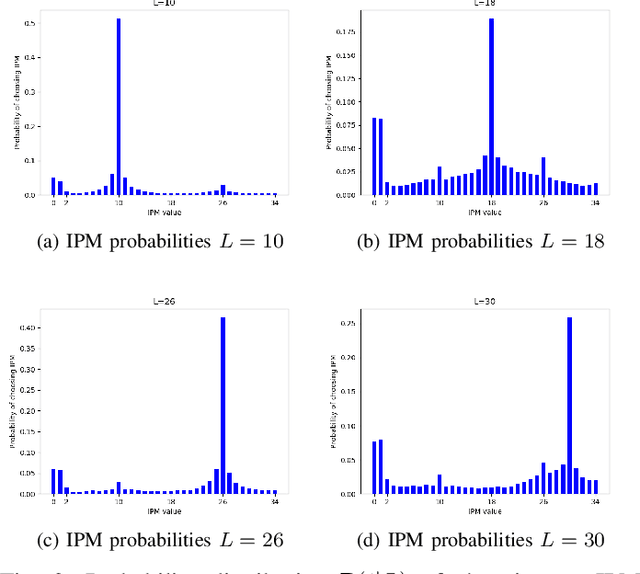
The high efficiency video coding (HEVC) standard and the joint exploration model (JEM) codec incorporate 35 and 67 intra prediction modes (IPMs) respectively, which are essential for efficient compression of Intra coded blocks. These IPMs are transmitted to the decoder through a coding scheme. In our paper, we present an innovative approach to construct a dedicated coding scheme for IPM based on contextual information. This approach comprises three key steps: prediction, clustering, and coding, each of which has been enhanced by introducing new elements, namely, labels for prediction, tests for clustering, and codes for coding. In this context, we have proposed a method that utilizes a genetic algorithm to minimize the rate cost, aiming to derive the most efficient coding scheme while leveraging the available labels, tests, and codes. The resulting coding scheme, expressed as a binary tree, achieves the highest coding efficiency for a given level of complexity. In our experimental evaluation under the HEVC standard, we observed significant bitrate gains while maintaining coding efficiency under the JEM codec. These results demonstrate the potential of our approach to improve compression efficiency, particularly under the HEVC standard, while preserving the coding efficiency of the JEM codec.
A novel Network Science Algorithm for Improving Triage of Patients
Oct 09, 2023Patient triage plays a crucial role in healthcare, ensuring timely and appropriate care based on the urgency of patient conditions. Traditional triage methods heavily rely on human judgment, which can be subjective and prone to errors. Recently, a growing interest has been in leveraging artificial intelligence (AI) to develop algorithms for triaging patients. This paper presents the development of a novel algorithm for triaging patients. It is based on the analysis of patient data to produce decisions regarding their prioritization. The algorithm was trained on a comprehensive data set containing relevant patient information, such as vital signs, symptoms, and medical history. The algorithm was designed to accurately classify patients into triage categories through rigorous preprocessing and feature engineering. Experimental results demonstrate that our algorithm achieved high accuracy and performance, outperforming traditional triage methods. By incorporating computer science into the triage process, healthcare professionals can benefit from improved efficiency, accuracy, and consistency, prioritizing patients effectively and optimizing resource allocation. Although further research is needed to address challenges such as biases in training data and model interpretability, the development of AI-based algorithms for triaging patients shows great promise in enhancing healthcare delivery and patient outcomes.
A New Transformation Approach for Uplift Modeling with Binary Outcome
Oct 09, 2023
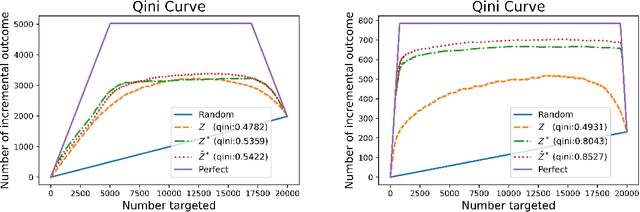
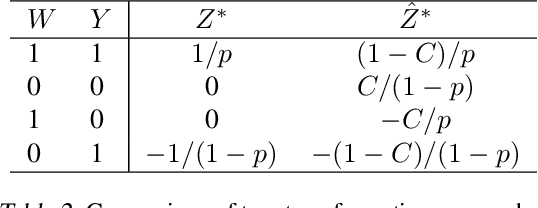
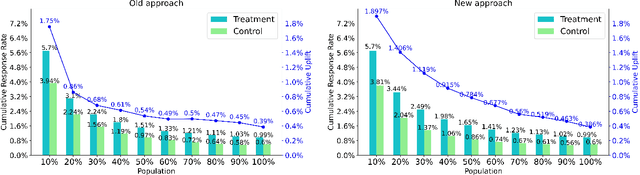
Uplift modeling has been used effectively in fields such as marketing and customer retention, to target those customers who are more likely to respond due to the campaign or treatment. Essentially, it is a machine learning technique that predicts the gain from performing some action with respect to not taking it. A popular class of uplift models is the transformation approach that redefines the target variable with the original treatment indicator. These transformation approaches only need to train and predict the difference in outcomes directly. The main drawback of these approaches is that in general it does not use the information in the treatment indicator beyond the construction of the transformed outcome and usually is not efficient. In this paper, we design a novel transformed outcome for the case of the binary target variable and unlock the full value of the samples with zero outcome. From a practical perspective, our new approach is flexible and easy to use. Experimental results on synthetic and real-world datasets obviously show that our new approach outperforms the traditional one. At present, our new approach has already been applied to precision marketing in a China nation-wide financial holdings group.
Locality-Aware Generalizable Implicit Neural Representation}
Oct 09, 2023Generalizable implicit neural representation (INR) enables a single continuous function, i.e., a coordinate-based neural network, to represent multiple data instances by modulating its weights or intermediate features using latent codes. However, the expressive power of the state-of-the-art modulation is limited due to its inability to localize and capture fine-grained details of data entities such as specific pixels and rays. To address this issue, we propose a novel framework for generalizable INR that combines a transformer encoder with a locality-aware INR decoder. The transformer encoder predicts a set of latent tokens from a data instance to encode local information into each latent token. The locality-aware INR decoder extracts a modulation vector by selectively aggregating the latent tokens via cross-attention for a coordinate input and then predicts the output by progressively decoding with coarse-to-fine modulation through multiple frequency bandwidths. The selective token aggregation and the multi-band feature modulation enable us to learn locality-aware representation in spatial and spectral aspects, respectively. Our framework significantly outperforms previous generalizable INRs and validates the usefulness of the locality-aware latents for downstream tasks such as image generation.
Collaborative Visual Place Recognition
Oct 09, 2023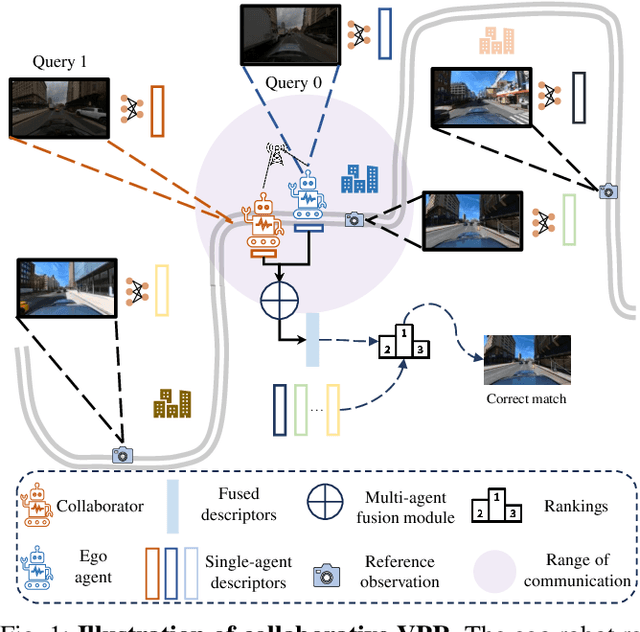
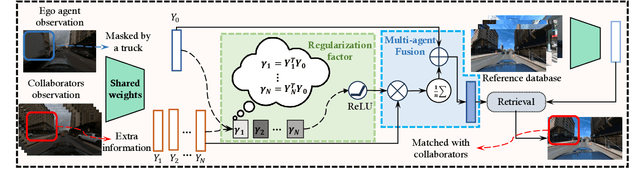
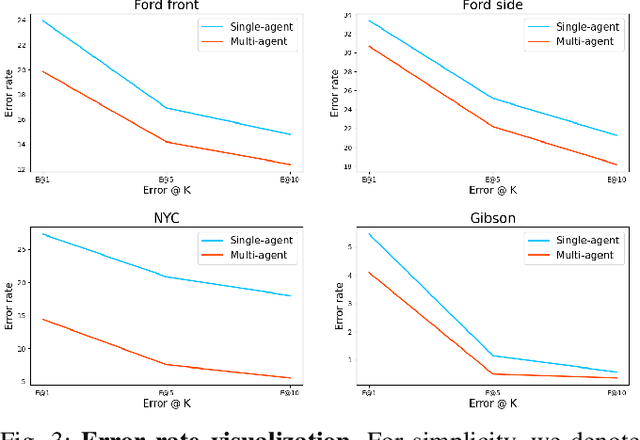

Visual place recognition (VPR) capabilities enable autonomous robots to navigate complex environments by discovering the environment's topology based on visual input. Most research efforts focus on enhancing the accuracy and robustness of single-robot VPR but often encounter issues such as occlusion due to individual viewpoints. Despite a number of research on multi-robot metric-based localization, there is a notable gap in research concerning more robust and efficient place-based localization with a multi-robot system. This work proposes collaborative VPR, where multiple robots share abstracted visual features to enhance place recognition capabilities. We also introduce a novel collaborative VPR framework based on similarity-regularized information fusion, reducing irrelevant noise while harnessing valuable data from collaborators. This framework seamlessly integrates with well-established single-robot VPR techniques and supports end-to-end training with a weakly-supervised contrastive loss. We conduct experiments in urban, rural, and indoor scenes, achieving a notable improvement over single-agent VPR in urban environments (~12\%), along with consistent enhancements in rural (~3\%) and indoor (~1\%) scenarios. Our work presents a promising solution to the pressing challenges of VPR, representing a substantial step towards safe and robust autonomous systems.