 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCarbonBench: A Global Benchmark for Upscaling of Carbon Fluxes Using Zero-Shot Learning
Mar 10, 2026Accurately quantifying terrestrial carbon exchange is essential for climate policy and carbon accounting, yet models must generalize to ecosystems underrepresented in sparse eddy covariance observations. Despite this challenge being a natural instance of zero-shot spatial transfer learning for time series regression, no standardized benchmark exists to rigorously evaluate model performance across geographically distinct locations with different climate regimes and vegetation types. We introduce CarbonBench, the first benchmark for zero-shot spatial transfer in carbon flux upscaling. CarbonBench comprises over 1.3 million daily observations from 567 flux tower sites globally (2000-2024). It provides: (1) stratified evaluation protocols that explicitly test generalization across unseen vegetation types and climate regimes, separating spatial transfer from temporal autocorrelation; (2) a harmonized set of remote sensing and meteorological features to enable flexible architecture design; and (3) baselines ranging from tree-based methods to domain-generalization architectures. By bridging machine learning methodologies and Earth system science, CarbonBench aims to enable systematic comparison of transfer learning methods, serves as a testbed for regression under distribution shift, and contributes to the next-generation climate modeling efforts.
Hierarchical Conditional Multi-Task Learning for Streamflow Modeling
Oct 18, 2024Streamflow, vital for water resource management, is governed by complex hydrological systems involving intermediate processes driven by meteorological forces. While deep learning models have achieved state-of-the-art results of streamflow prediction, their end-to-end single-task learning approach often fails to capture the causal relationships within these systems. To address this, we propose Hierarchical Conditional Multi-Task Learning (HCMTL), a hierarchical approach that jointly models soil water and snowpack processes based on their causal connections to streamflow. HCMTL utilizes task embeddings to connect network modules, enhancing flexibility and expressiveness while capturing unobserved processes beyond soil water and snowpack. It also incorporates the Conditional Mini-Batch strategy to improve long time series modeling. We compare HCMTL with five baselines on a global dataset. HCMTL's superior performance across hundreds of drainage basins over extended periods shows that integrating domain-specific causal knowledge into deep learning enhances both prediction accuracy and interpretability. This is essential for advancing our understanding of complex hydrological systems and supporting efficient water resource management to mitigate natural disasters like droughts and floods.
ExoTST: Exogenous-Aware Temporal Sequence Transformer for Time Series Prediction
Oct 16, 2024



Accurate long-term predictions are the foundations for many machine learning applications and decision-making processes. Traditional time series approaches for prediction often focus on either autoregressive modeling, which relies solely on past observations of the target ``endogenous variables'', or forward modeling, which considers only current covariate drivers ``exogenous variables''. However, effectively integrating past endogenous and past exogenous with current exogenous variables remains a significant challenge. In this paper, we propose ExoTST, a novel transformer-based framework that effectively incorporates current exogenous variables alongside past context for improved time series prediction. To integrate exogenous information efficiently, ExoTST leverages the strengths of attention mechanisms and introduces a novel cross-temporal modality fusion module. This module enables the model to jointly learn from both past and current exogenous series, treating them as distinct modalities. By considering these series separately, ExoTST provides robustness and flexibility in handling data uncertainties that arise from the inherent distribution shift between historical and current exogenous variables. Extensive experiments on real-world carbon flux datasets and time series benchmarks demonstrate ExoTST's superior performance compared to state-of-the-art baselines, with improvements of up to 10\% in prediction accuracy. Moreover, ExoTST exhibits strong robustness against missing values and noise in exogenous drivers, maintaining consistent performance in real-world situations where these imperfections are common.
Hierarchically Disentangled Recurrent Network for Factorizing System Dynamics of Multi-scale Systems
Jul 29, 2024We present a knowledge-guided machine learning (KGML) framework for modeling multi-scale processes, and study its performance in the context of streamflow forecasting in hydrology. Specifically, we propose a novel hierarchical recurrent neural architecture that factorizes the system dynamics at multiple temporal scales and captures their interactions. This framework consists of an inverse and a forward model. The inverse model is used to empirically resolve the system's temporal modes from data (physical model simulations, observed data, or a combination of them from the past), and these states are then used in the forward model to predict streamflow. In a hydrological system, these modes can represent different processes, evolving at different temporal scales (e.g., slow: groundwater recharge and baseflow vs. fast: surface runoff due to extreme rainfall). A key advantage of our framework is that once trained, it can incorporate new observations into the model's context (internal state) without expensive optimization approaches (e.g., EnKF) that are traditionally used in physical sciences for data assimilation. Experiments with several river catchments from the NWS NCRFC region show the efficacy of this ML-based data assimilation framework compared to standard baselines, especially for basins that have a long history of observations. Even for basins that have a shorter observation history, we present two orthogonal strategies of training our FHNN framework: (a) using simulation data from imperfect simulations and (b) using observation data from multiple basins to build a global model. We show that both of these strategies (that can be used individually or together) are highly effective in mitigating the lack of training data. The improvement in forecast accuracy is particularly noteworthy for basins where local models perform poorly because of data sparsity.
Task Aware Modulation using Representation Learning: An Approach for Few Shot Learning in Heterogeneous Systems
Oct 07, 2023



We present a Task-aware modulation using Representation Learning (TAM-RL) framework that enhances personalized predictions in few-shot settings for heterogeneous systems when individual task characteristics are not known. TAM-RL extracts embeddings representing the actual inherent characteristics of these entities and uses these characteristics to personalize the predictions for each entity/task. Using real-world hydrological and flux tower benchmark data sets, we show that TAM-RL can significantly outperform existing baseline approaches such as MAML and multi-modal MAML (MMAML) while being much faster and simpler to train due to less complexity. Specifically, TAM-RL eliminates the need for sensitive hyper-parameters like inner loop steps and inner loop learning rate, which are crucial for model convergence in MAML, MMAML. We further present an empirical evaluation via synthetic data to explore the impact of heterogeneity amongst the entities on the relative performance of MAML, MMAML, and TAM-RL. We show that TAM-RL significantly improves predictive performance for cases where it is possible to learn distinct representations for different tasks.
Uncertainty Quantification in Inverse Models in Hydrology
Oct 03, 2023



In hydrology, modeling streamflow remains a challenging task due to the limited availability of basin characteristics information such as soil geology and geomorphology. These characteristics may be noisy due to measurement errors or may be missing altogether. To overcome this challenge, we propose a knowledge-guided, probabilistic inverse modeling method for recovering physical characteristics from streamflow and weather data, which are more readily available. We compare our framework with state-of-the-art inverse models for estimating river basin characteristics. We also show that these estimates offer improvement in streamflow modeling as opposed to using the original basin characteristic values. Our inverse model offers 3\% improvement in R$^2$ for the inverse model (basin characteristic estimation) and 6\% for the forward model (streamflow prediction). Our framework also offers improved explainability since it can quantify uncertainty in both the inverse and the forward model. Uncertainty quantification plays a pivotal role in improving the explainability of machine learning models by providing additional insights into the reliability and limitations of model predictions. In our analysis, we assess the quality of the uncertainty estimates. Compared to baseline uncertainty quantification methods, our framework offers 10\% improvement in the dispersion of epistemic uncertainty and 13\% improvement in coverage rate. This information can help stakeholders understand the level of uncertainty associated with the predictions and provide a more comprehensive view of the potential outcomes.
Message Propagation Through Time: An Algorithm for Sequence Dependency Retention in Time Series Modeling
Sep 28, 2023



Time series modeling, a crucial area in science, often encounters challenges when training Machine Learning (ML) models like Recurrent Neural Networks (RNNs) using the conventional mini-batch training strategy that assumes independent and identically distributed (IID) samples and initializes RNNs with zero hidden states. The IID assumption ignores temporal dependencies among samples, resulting in poor performance. This paper proposes the Message Propagation Through Time (MPTT) algorithm to effectively incorporate long temporal dependencies while preserving faster training times relative to the stateful solutions. MPTT utilizes two memory modules to asynchronously manage initial hidden states for RNNs, fostering seamless information exchange between samples and allowing diverse mini-batches throughout epochs. MPTT further implements three policies to filter outdated and preserve essential information in the hidden states to generate informative initial hidden states for RNNs, facilitating robust training. Experimental results demonstrate that MPTT outperforms seven strategies on four climate datasets with varying levels of temporal dependencies.
Koopman Invertible Autoencoder: Leveraging Forward and Backward Dynamics for Temporal Modeling
Sep 19, 2023



Accurate long-term predictions are the foundations for many machine learning applications and decision-making processes. However, building accurate long-term prediction models remains challenging due to the limitations of existing temporal models like recurrent neural networks (RNNs), as they capture only the statistical connections in the training data and may fail to learn the underlying dynamics of the target system. To tackle this challenge, we propose a novel machine learning model based on Koopman operator theory, which we call Koopman Invertible Autoencoders (KIA), that captures the inherent characteristic of the system by modeling both forward and backward dynamics in the infinite-dimensional Hilbert space. This enables us to efficiently learn low-dimensional representations, resulting in more accurate predictions of long-term system behavior. Moreover, our method's invertibility design guarantees reversibility and consistency in both forward and inverse operations. We illustrate the utility of KIA on pendulum and climate datasets, demonstrating 300% improvements in long-term prediction capability for pendulum while maintaining robustness against noise. Additionally, our method excels in long-term climate prediction, further validating our method's effectiveness.
Entity Aware Modelling: A Survey
Feb 16, 2023

Personalized prediction of responses for individual entities caused by external drivers is vital across many disciplines. Recent machine learning (ML) advances have led to new state-of-the-art response prediction models. Models built at a population level often lead to sub-optimal performance in many personalized prediction settings due to heterogeneity in data across entities (tasks). In personalized prediction, the goal is to incorporate inherent characteristics of different entities to improve prediction performance. In this survey, we focus on the recent developments in the ML community for such entity-aware modeling approaches. ML algorithms often modulate the network using these entity characteristics when they are readily available. However, these entity characteristics are not readily available in many real-world scenarios, and different ML methods have been proposed to infer these characteristics from the data. In this survey, we have organized the current literature on entity-aware modeling based on the availability of these characteristics as well as the amount of training data. We highlight how recent innovations in other disciplines, such as uncertainty quantification, fairness, and knowledge-guided machine learning, can improve entity-aware modeling.
Probabilistic Inverse Modeling: An Application in Hydrology
Oct 12, 2022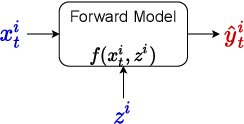
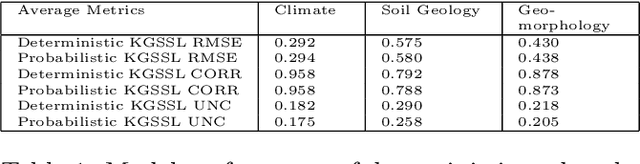
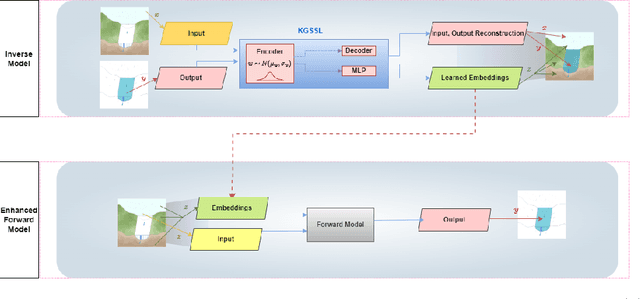
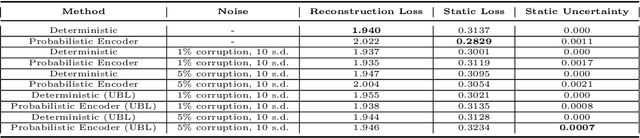
The astounding success of these methods has made it imperative to obtain more explainable and trustworthy estimates from these models. In hydrology, basin characteristics can be noisy or missing, impacting streamflow prediction. For solving inverse problems in such applications, ensuring explainability is pivotal for tackling issues relating to data bias and large search space. We propose a probabilistic inverse model framework that can reconstruct robust hydrology basin characteristics from dynamic input weather driver and streamflow response data. We address two aspects of building more explainable inverse models, uncertainty estimation and robustness. This can help improve the trust of water managers, handling of noisy data and reduce costs. We propose uncertainty based learning method that offers 6\% improvement in $R^2$ for streamflow prediction (forward modeling) from inverse model inferred basin characteristic estimates, 17\% reduction in uncertainty (40\% in presence of noise) and 4\% higher coverage rate for basin characteristics.