 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Variational Information Pursuit with Large Language and Multimodal Models for Interpretable Predictions
Aug 24, 2023

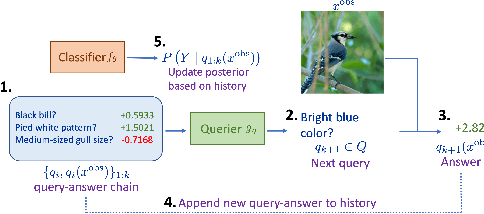


Variational Information Pursuit (V-IP) is a framework for making interpretable predictions by design by sequentially selecting a short chain of task-relevant, user-defined and interpretable queries about the data that are most informative for the task. While this allows for built-in interpretability in predictive models, applying V-IP to any task requires data samples with dense concept-labeling by domain experts, limiting the application of V-IP to small-scale tasks where manual data annotation is feasible. In this work, we extend the V-IP framework with Foundational Models (FMs) to address this limitation. More specifically, we use a two-step process, by first leveraging Large Language Models (LLMs) to generate a sufficiently large candidate set of task-relevant interpretable concepts, then using Large Multimodal Models to annotate each data sample by semantic similarity with each concept in the generated concept set. While other interpretable-by-design frameworks such as Concept Bottleneck Models (CBMs) require an additional step of removing repetitive and non-discriminative concepts to have good interpretability and test performance, we mathematically and empirically justify that, with a sufficiently informative and task-relevant query (concept) set, the proposed FM+V-IP method does not require any type of concept filtering. In addition, we show that FM+V-IP with LLM generated concepts can achieve better test performance than V-IP with human annotated concepts, demonstrating the effectiveness of LLMs at generating efficient query sets. Finally, when compared to other interpretable-by-design frameworks such as CBMs, FM+V-IP can achieve competitive test performance using fewer number of concepts/queries in both cases with filtered or unfiltered concept sets.
Less is More: Toward Zero-Shot Local Scene Graph Generation via Foundation Models
Oct 02, 2023Humans inherently recognize objects via selective visual perception, transform specific regions from the visual field into structured symbolic knowledge, and reason their relationships among regions based on the allocation of limited attention resources in line with humans' goals. While it is intuitive for humans, contemporary perception systems falter in extracting structural information due to the intricate cognitive abilities and commonsense knowledge required. To fill this gap, we present a new task called Local Scene Graph Generation. Distinct from the conventional scene graph generation task, which encompasses generating all objects and relationships in an image, our proposed task aims to abstract pertinent structural information with partial objects and their relationships for boosting downstream tasks that demand advanced comprehension and reasoning capabilities. Correspondingly, we introduce zEro-shot Local scEne GrAph geNeraTion (ELEGANT), a framework harnessing foundation models renowned for their powerful perception and commonsense reasoning, where collaboration and information communication among foundation models yield superior outcomes and realize zero-shot local scene graph generation without requiring labeled supervision. Furthermore, we propose a novel open-ended evaluation metric, Entity-level CLIPScorE (ECLIPSE), surpassing previous closed-set evaluation metrics by transcending their limited label space, offering a broader assessment. Experiment results show that our approach markedly outperforms baselines in the open-ended evaluation setting, and it also achieves a significant performance boost of up to 24.58% over prior methods in the close-set setting, demonstrating the effectiveness and powerful reasoning ability of our proposed framework.
Diff-Transfer: Model-based Robotic Manipulation Skill Transfer via Differentiable Physics Simulation
Oct 10, 2023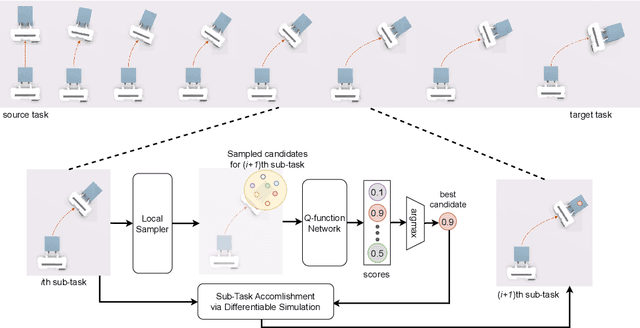
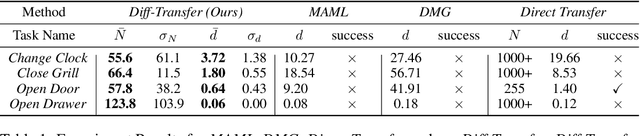

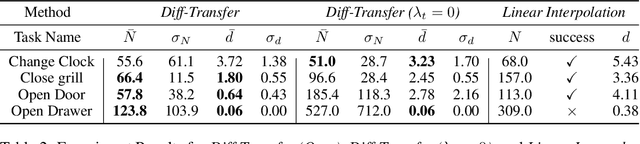
The capability to transfer mastered skills to accomplish a range of similar yet novel tasks is crucial for intelligent robots. In this work, we introduce $\textit{Diff-Transfer}$, a novel framework leveraging differentiable physics simulation to efficiently transfer robotic skills. Specifically, $\textit{Diff-Transfer}$ discovers a feasible path within the task space that brings the source task to the target task. At each pair of adjacent points along this task path, which is two sub-tasks, $\textit{Diff-Transfer}$ adapts known actions from one sub-task to tackle the other sub-task successfully. The adaptation is guided by the gradient information from differentiable physics simulations. We propose a novel path-planning method to generate sub-tasks, leveraging $Q$-learning with a task-level state and reward. We implement our framework in simulation experiments and execute four challenging transfer tasks on robotic manipulation, demonstrating the efficacy of $\textit{Diff-Transfer}$ through comprehensive experiments. Supplementary and Videos are on the website https://sites.google.com/view/difftransfer
Topic-DPR: Topic-based Prompts for Dense Passage Retrieval
Oct 10, 2023Prompt-based learning's efficacy across numerous natural language processing tasks has led to its integration into dense passage retrieval. Prior research has mainly focused on enhancing the semantic understanding of pre-trained language models by optimizing a single vector as a continuous prompt. This approach, however, leads to a semantic space collapse; identical semantic information seeps into all representations, causing their distributions to converge in a restricted region. This hinders differentiation between relevant and irrelevant passages during dense retrieval. To tackle this issue, we present Topic-DPR, a dense passage retrieval model that uses topic-based prompts. Unlike the single prompt method, multiple topic-based prompts are established over a probabilistic simplex and optimized simultaneously through contrastive learning. This encourages representations to align with their topic distributions, improving space uniformity. Furthermore, we introduce a novel positive and negative sampling strategy, leveraging semi-structured data to boost dense retrieval efficiency. Experimental results from two datasets affirm that our method surpasses previous state-of-the-art retrieval techniques.
A New Benchmark and Reverse Validation Method for Passage-level Hallucination Detection
Oct 10, 2023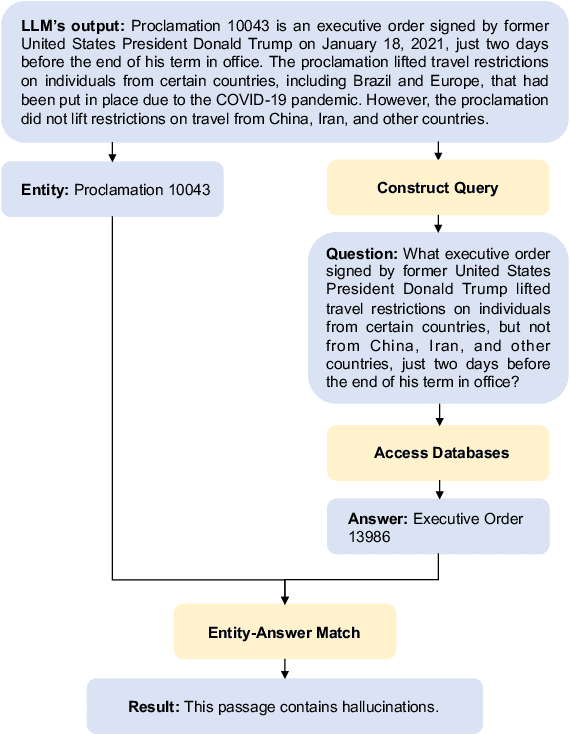
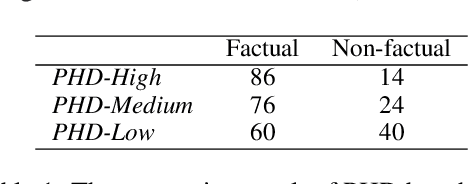

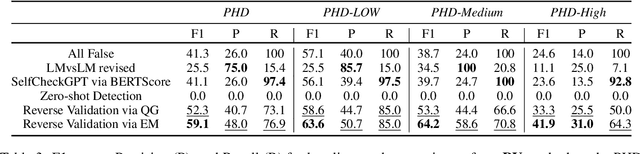
Large Language Models (LLMs) have demonstrated their ability to collaborate effectively with humans in real-world scenarios. However, LLMs are apt to generate hallucinations, i.e., makeup incorrect text and unverified information, which can cause significant damage when deployed for mission-critical tasks. In this paper, we propose a self-check approach based on reverse validation to detect factual errors automatically in a zero-resource fashion. To facilitate future studies and assess different methods, we construct a hallucination detection benchmark, which is generated by ChatGPT and annotated by human annotators. Contrasting previous studies of zero-resource hallucination detection, our method and benchmark concentrate on passage-level detection instead of sentence-level. We empirically evaluate our method and existing zero-resource detection methods on different domains of benchmark to explore the implicit relation between hallucination and training data. Furthermore, we manually analyze some hallucination cases that LLM failed to capture, revealing the shared limitation of zero-resource methods.
Super Denoise Net: Speech Super Resolution with Noise Cancellation in Low Sampling Rate Noisy Environments
Oct 10, 2023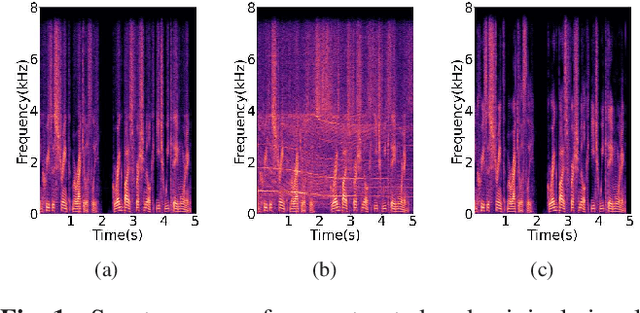
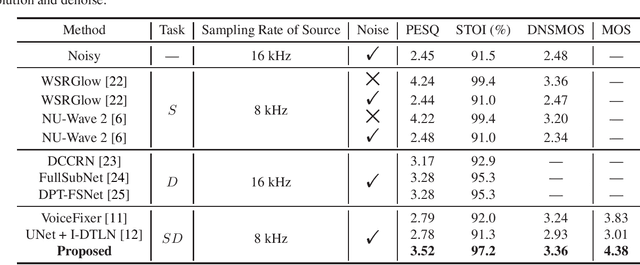
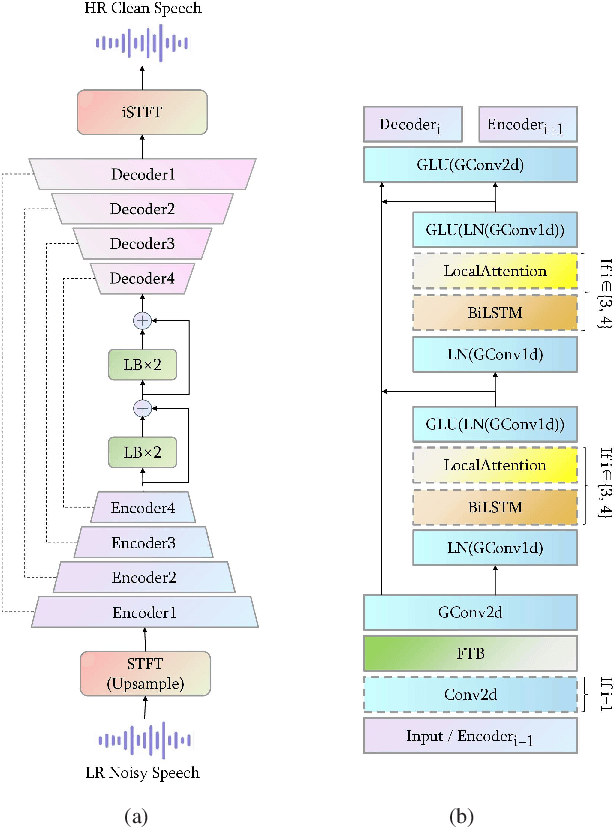
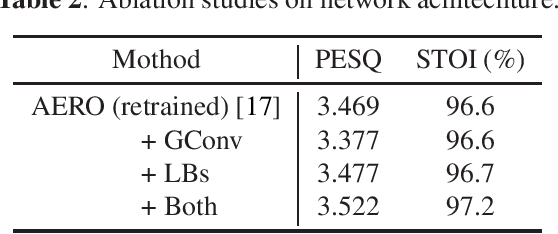
Speech super-resolution (SSR) aims to predict a high resolution (HR) speech signal from its low resolution (LR) corresponding part. Most neural SSR models focus on producing the final result in a noise-free environment by recovering the spectrogram of high-frequency part of the signal and concatenating it with the original low-frequency part. Although these methods achieve high accuracy, they become less effective when facing the real-world scenario, where unavoidable noise is present. To address this problem, we propose a Super Denoise Net (SDNet), a neural network for a joint task of super-resolution and noise reduction from a low sampling rate signal. To that end, we design gated convolution and lattice convolution blocks to enhance the repair capability and capture information in the time-frequency axis, respectively. The experiments show our method outperforms baseline speech denoising and SSR models on DNS 2020 no-reverb test set with higher objective and subjective scores.
Interpretable Traffic Event Analysis with Bayesian Networks
Oct 10, 2023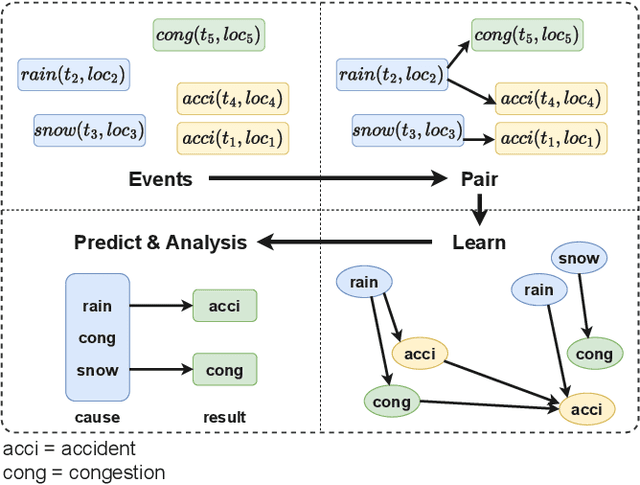
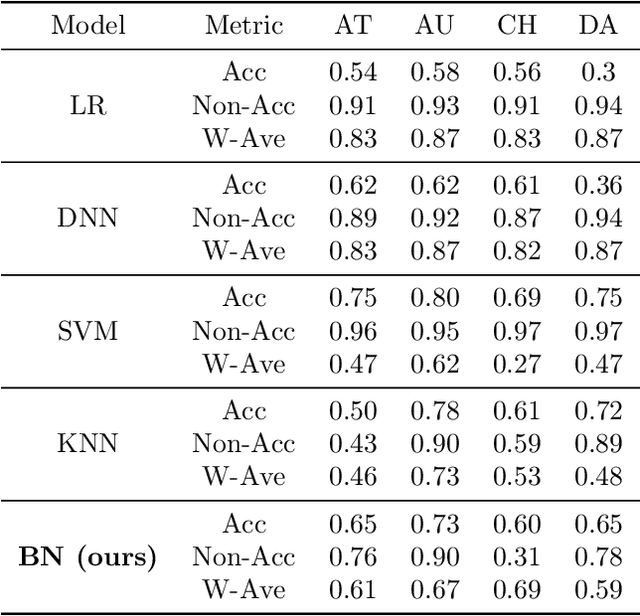
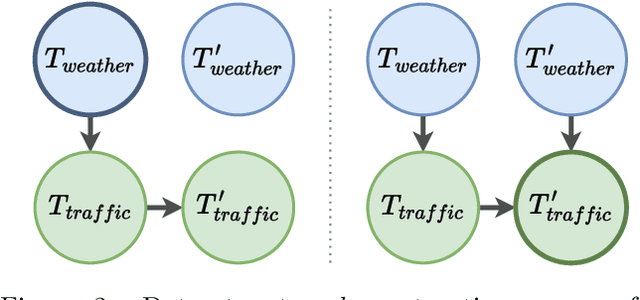
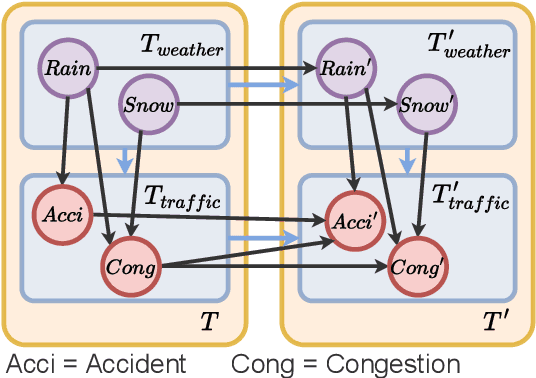
Although existing machine learning-based methods for traffic accident analysis can provide good quality results to downstream tasks, they lack interpretability which is crucial for this critical problem. This paper proposes an interpretable framework based on Bayesian Networks for traffic accident prediction. To enable the ease of interpretability, we design a dataset construction pipeline to feed the traffic data into the framework while retaining the essential traffic data information. With a concrete case study, our framework can derive a Bayesian Network from a dataset based on the causal relationships between weather and traffic events across the United States. Consequently, our framework enables the prediction of traffic accidents with competitive accuracy while examining how the probability of these events changes under different conditions, thus illustrating transparent relationships between traffic and weather events. Additionally, the visualization of the network simplifies the analysis of relationships between different variables, revealing the primary causes of traffic accidents and ultimately providing a valuable reference for reducing traffic accidents.
Federated Multi-Level Optimization over Decentralized Networks
Oct 10, 2023Multi-level optimization has gained increasing attention in recent years, as it provides a powerful framework for solving complex optimization problems that arise in many fields, such as meta-learning, multi-player games, reinforcement learning, and nested composition optimization. In this paper, we study the problem of distributed multi-level optimization over a network, where agents can only communicate with their immediate neighbors. This setting is motivated by the need for distributed optimization in large-scale systems, where centralized optimization may not be practical or feasible. To address this problem, we propose a novel gossip-based distributed multi-level optimization algorithm that enables networked agents to solve optimization problems at different levels in a single timescale and share information through network propagation. Our algorithm achieves optimal sample complexity, scaling linearly with the network size, and demonstrates state-of-the-art performance on various applications, including hyper-parameter tuning, decentralized reinforcement learning, and risk-averse optimization.
Factuality Challenges in the Era of Large Language Models
Oct 10, 2023The emergence of tools based on Large Language Models (LLMs), such as OpenAI's ChatGPT, Microsoft's Bing Chat, and Google's Bard, has garnered immense public attention. These incredibly useful, natural-sounding tools mark significant advances in natural language generation, yet they exhibit a propensity to generate false, erroneous, or misleading content -- commonly referred to as "hallucinations." Moreover, LLMs can be exploited for malicious applications, such as generating false but credible-sounding content and profiles at scale. This poses a significant challenge to society in terms of the potential deception of users and the increasing dissemination of inaccurate information. In light of these risks, we explore the kinds of technological innovations, regulatory reforms, and AI literacy initiatives needed from fact-checkers, news organizations, and the broader research and policy communities. By identifying the risks, the imminent threats, and some viable solutions, we seek to shed light on navigating various aspects of veracity in the era of generative AI.
Distilling Inductive Bias: Knowledge Distillation Beyond Model Compression
Oct 10, 2023
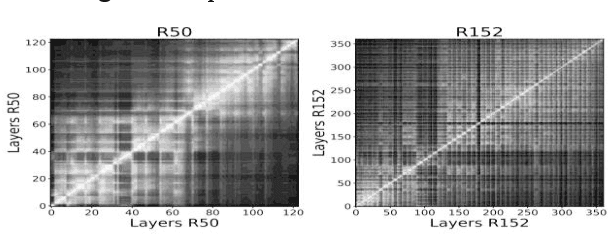
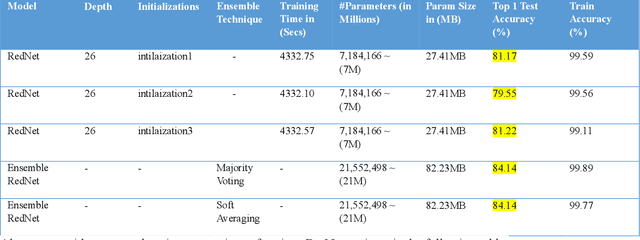

With the rapid development of computer vision, Vision Transformers (ViTs) offer the tantalizing prospect of unified information processing across visual and textual domains. But due to the lack of inherent inductive biases in ViTs, they require enormous amount of data for training. To make their applications practical, we introduce an innovative ensemble-based distillation approach distilling inductive bias from complementary lightweight teacher models. Prior systems relied solely on convolution-based teaching. However, this method incorporates an ensemble of light teachers with different architectural tendencies, such as convolution and involution, to instruct the student transformer jointly. Because of these unique inductive biases, instructors can accumulate a wide range of knowledge, even from readily identifiable stored datasets, which leads to enhanced student performance. Our proposed framework also involves precomputing and storing logits in advance, essentially the unnormalized predictions of the model. This optimization can accelerate the distillation process by eliminating the need for repeated forward passes during knowledge distillation, significantly reducing the computational burden and enhancing efficiency.