 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Graph-based Simultaneous Localization and Bias Tracking
Oct 05, 2023
We present a factor graph formulation and particle-based sum-product algorithm for robust localization and tracking in multipath-prone environments. The proposed sequential algorithm jointly estimates the mobile agent's position together with a time-varying number of multipath components (MPCs). The MPCs are represented by "delay biases" corresponding to the offset between line-of-sight (LOS) component delay and the respective delays of all detectable MPCs. The delay biases of the MPCs capture the geometric features of the propagation environment with respect to the mobile agent. Therefore, they can provide position-related information contained in the MPCs without explicitly building a map of the environment. We demonstrate that the position-related information enables the algorithm to provide high-accuracy position estimates even in fully obstructed line-of-sight (OLOS) situations. Using simulated and real measurements in different scenarios we demonstrate the proposed algorithm to significantly outperform state-of-the-art multipath-aided tracking algorithms and show that the performance of our algorithm constantly attains the posterior Cramer-Rao lower bound (P-CRLB). Furthermore, we demonstrate the implicit capability of the proposed method to identify unreliable measurements and, thus, to mitigate lost tracks.
Speaker localization using direct path dominance test based on sound field directivity
Oct 05, 2023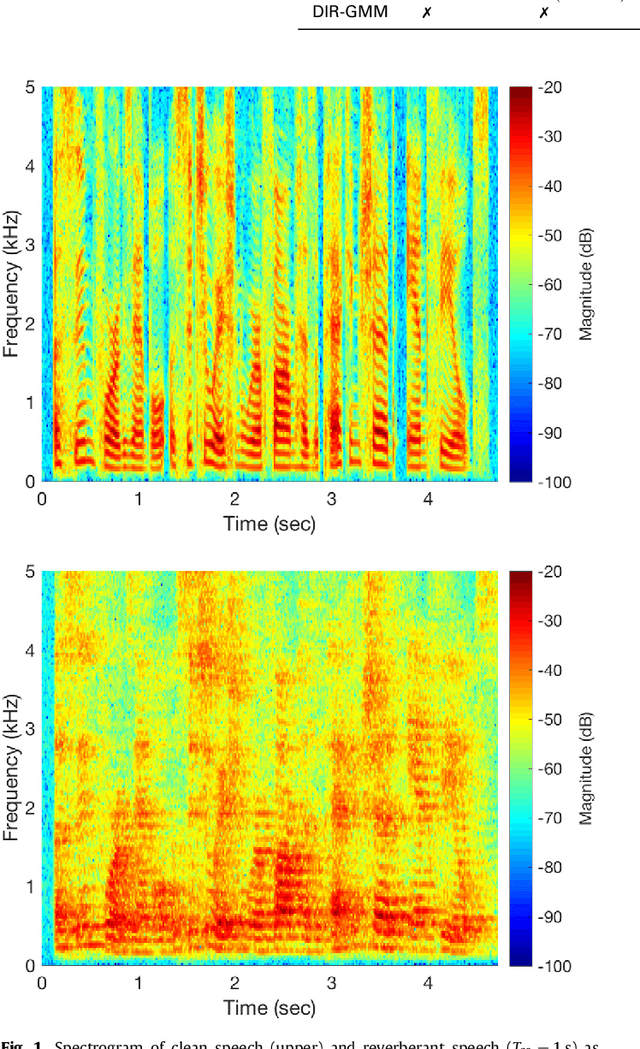
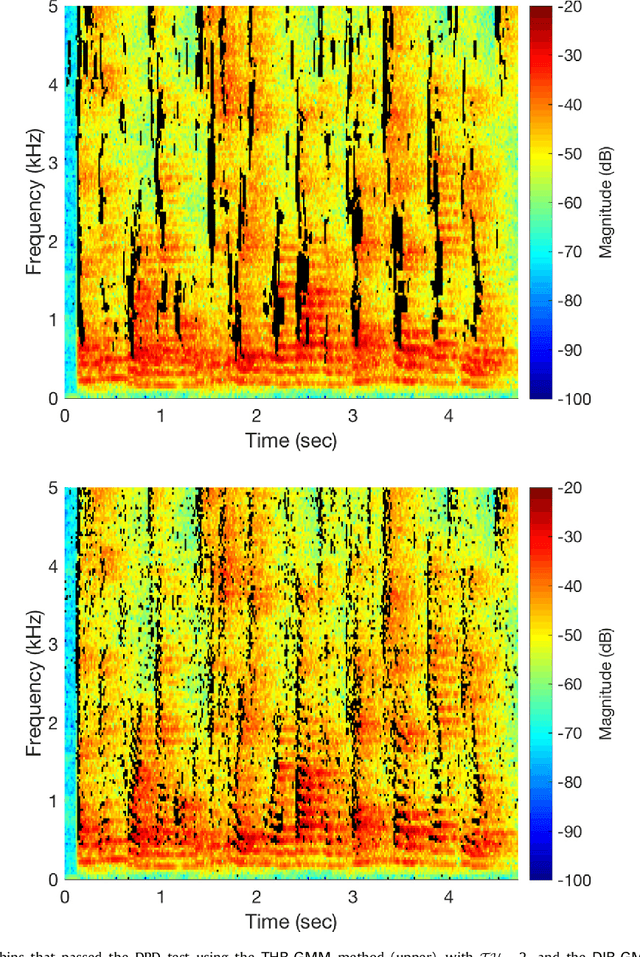

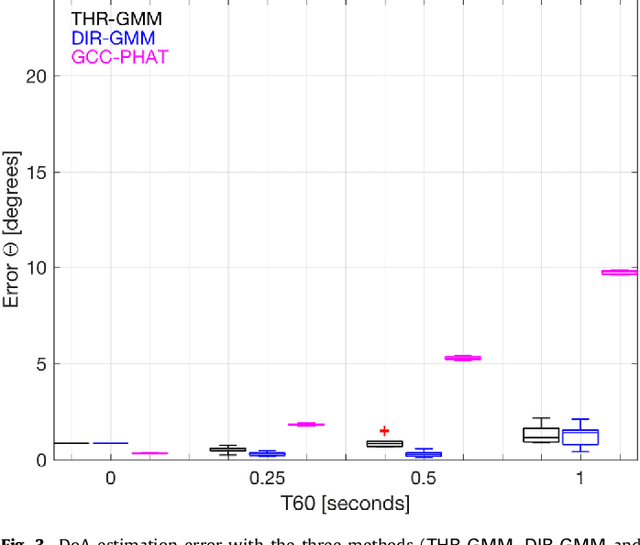
Estimation of the direction-of-arrival (DoA) of a speaker in a room is important in many audio signal processing applications. Environments with reverberation that masks the DoA information are particularly challenging. Recently, a DoA estimation method that is robust to reverberation has been developed. This method identifies time-frequency bins dominated by the contribution from the direct path, which carries the correct DoA information. However, its implementation is computationally demanding as it requires frequency smoothing to overcome the effect of coherent early reflections and matrix decomposition to apply the direct-path dominance (DPD) test. In this work, a novel computationally-efficient alternative to the DPD test is proposed, based on the directivity measure for sensor arrays, which requires neither frequency smoothing nor matrix decomposition, and which has been reformulated for sound field directivity with spherical microphone arrays. The paper presents the proposed method and a comparison to previous methods under a range of reverberation and noise conditions. Result demonstrate that the proposed method shows comparable performance to the original method in terms of robustness to reverberation and noise, and is about four times more computationally efficient for the given experiment.
CAW-coref: Conjunction-Aware Word-level Coreference Resolution
Oct 09, 2023State-of-the-art coreference resolutions systems depend on multiple LLM calls per document and are thus prohibitively expensive for many use cases (e.g., information extraction with large corpora). The leading word-level coreference system (WL-coref) attains 96.6% of these SOTA systems' performance while being much more efficient. In this work, we identify a routine yet important failure case of WL-coref: dealing with conjoined mentions such as 'Tom and Mary'. We offer a simple yet effective solution that improves the performance on the OntoNotes test set by 0.9% F1, shrinking the gap between efficient word-level coreference resolution and expensive SOTA approaches by 34.6%. Our Conjunction-Aware Word-level coreference model (CAW-coref) and code is available at https://github.com/KarelDO/wl-coref.
Unlearning with Fisher Masking
Oct 09, 2023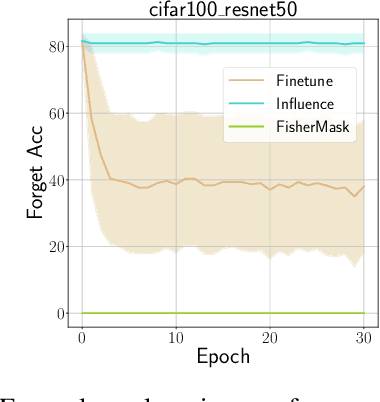
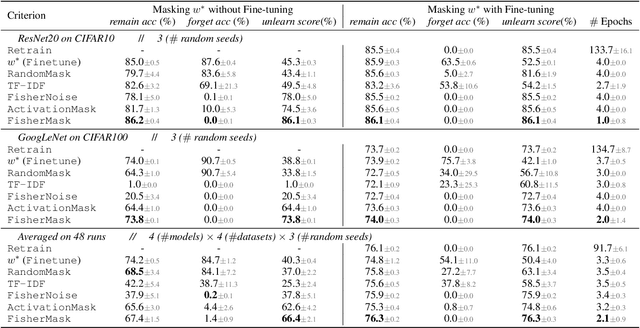

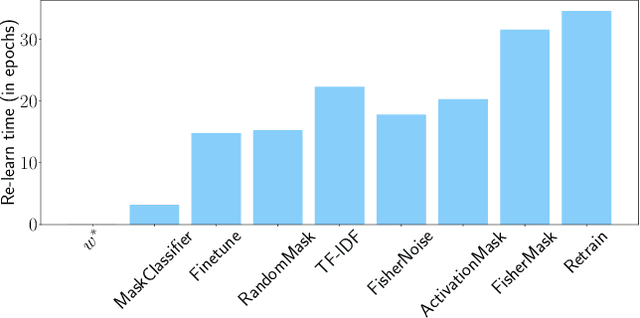
Machine unlearning aims to revoke some training data after learning in response to requests from users, model developers, and administrators. Most previous methods are based on direct fine-tuning, which may neither remove data completely nor retain full performances on the remain data. In this work, we find that, by first masking some important parameters before fine-tuning, the performances of unlearning could be significantly improved. We propose a new masking strategy tailored to unlearning based on Fisher information. Experiments on various datasets and network structures show the effectiveness of the method: without any fine-tuning, the proposed Fisher masking could unlearn almost completely while maintaining most of the performance on the remain data. It also exhibits stronger stability compared to other unlearning baselines
MEM: Multi-Modal Elevation Mapping for Robotics and Learning
Sep 28, 2023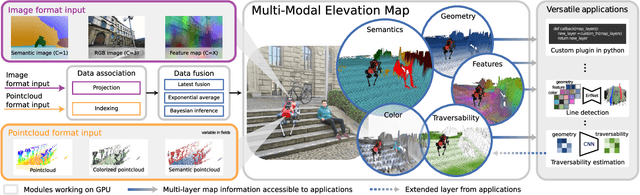
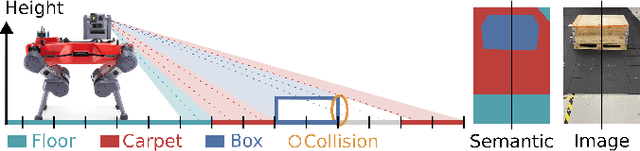
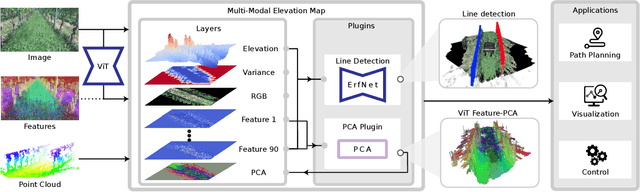
Elevation maps are commonly used to represent the environment of mobile robots and are instrumental for locomotion and navigation tasks. However, pure geometric information is insufficient for many field applications that require appearance or semantic information, which limits their applicability to other platforms or domains. In this work, we extend a 2.5D robot-centric elevation mapping framework by fusing multi-modal information from multiple sources into a popular map representation. The framework allows inputting data contained in point clouds or images in a unified manner. To manage the different nature of the data, we also present a set of fusion algorithms that can be selected based on the information type and user requirements. Our system is designed to run on the GPU, making it real-time capable for various robotic and learning tasks. We demonstrate the capabilities of our framework by deploying it on multiple robots with varying sensor configurations and showcasing a range of applications that utilize multi-modal layers, including line detection, human detection, and colorization.
Leveraging Large Language Models (LLMs) to Empower Training-Free Dataset Condensation for Content-Based Recommendation
Oct 15, 2023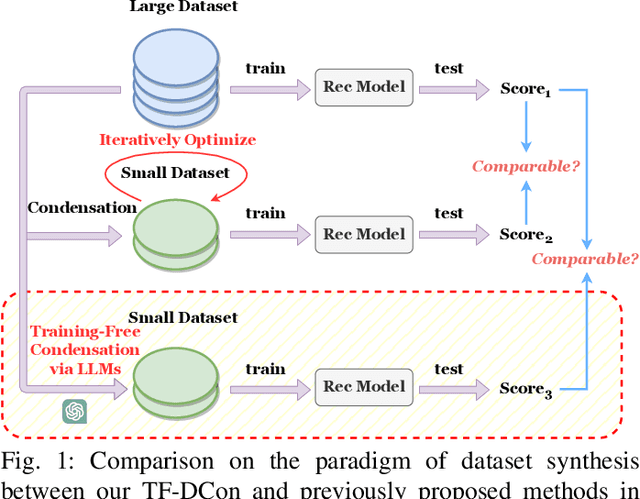
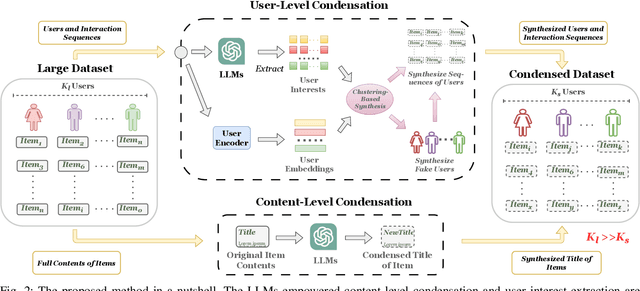

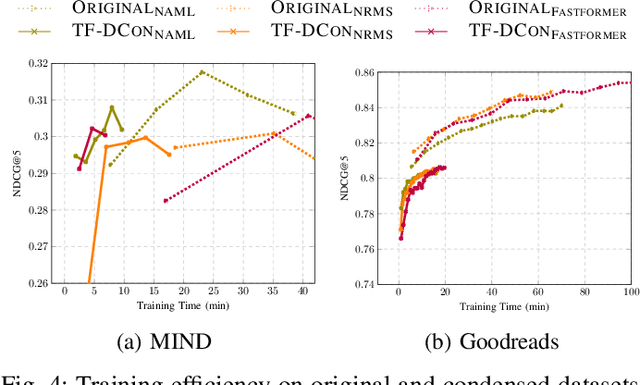
Modern techniques in Content-based Recommendation (CBR) leverage item content information to provide personalized services to users, but suffer from resource-intensive training on large datasets. To address this issue, we explore the dataset condensation for textual CBR in this paper. The goal of dataset condensation is to synthesize a small yet informative dataset, upon which models can achieve performance comparable to those trained on large datasets. While existing condensation approaches are tailored to classification tasks for continuous data like images or embeddings, direct application of them to CBR has limitations. To bridge this gap, we investigate efficient dataset condensation for content-based recommendation. Inspired by the remarkable abilities of large language models (LLMs) in text comprehension and generation, we leverage LLMs to empower the generation of textual content during condensation. To handle the interaction data involving both users and items, we devise a dual-level condensation method: content-level and user-level. At content-level, we utilize LLMs to condense all contents of an item into a new informative title. At user-level, we design a clustering-based synthesis module, where we first utilize LLMs to extract user interests. Then, the user interests and user embeddings are incorporated to condense users and generate interactions for condensed users. Notably, the condensation paradigm of this method is forward and free from iterative optimization on the synthesized dataset. Extensive empirical findings from our study, conducted on three authentic datasets, substantiate the efficacy of the proposed method. Particularly, we are able to approximate up to 97% of the original performance while reducing the dataset size by 95% (i.e., on dataset MIND).
Learning Disentangled Representation with Mutual Information Maximization for Real-Time UAV Tracking
Aug 20, 2023Efficiency has been a critical problem in UAV tracking due to limitations in computation resources, battery capacity, and unmanned aerial vehicle maximum load. Although discriminative correlation filters (DCF)-based trackers prevail in this field for their favorable efficiency, some recently proposed lightweight deep learning (DL)-based trackers using model compression demonstrated quite remarkable CPU efficiency as well as precision. Unfortunately, the model compression methods utilized by these works, though simple, are still unable to achieve satisfying tracking precision with higher compression rates. This paper aims to exploit disentangled representation learning with mutual information maximization (DR-MIM) to further improve DL-based trackers' precision and efficiency for UAV tracking. The proposed disentangled representation separates the feature into an identity-related and an identity-unrelated features. Only the latter is used, which enhances the effectiveness of the feature representation for subsequent classification and regression tasks. Extensive experiments on four UAV benchmarks, including UAV123@10fps, DTB70, UAVDT and VisDrone2018, show that our DR-MIM tracker significantly outperforms state-of-the-art UAV tracking methods.
Symmetric Single Index Learning
Oct 03, 2023Few neural architectures lend themselves to provable learning with gradient based methods. One popular model is the single-index model, in which labels are produced by composing an unknown linear projection with a possibly unknown scalar link function. Learning this model with SGD is relatively well-understood, whereby the so-called information exponent of the link function governs a polynomial sample complexity rate. However, extending this analysis to deeper or more complicated architectures remains challenging. In this work, we consider single index learning in the setting of symmetric neural networks. Under analytic assumptions on the activation and maximum degree assumptions on the link function, we prove that gradient flow recovers the hidden planted direction, represented as a finitely supported vector in the feature space of power sum polynomials. We characterize a notion of information exponent adapted to our setting that controls the efficiency of learning.
Resolving Knowledge Conflicts in Large Language Models
Oct 02, 2023Large language models (LLMs) often encounter knowledge conflicts, scenarios where discrepancy arises between the internal parametric knowledge of LLMs and non-parametric information provided in the prompt context. In this work we ask what are the desiderata for LLMs when a knowledge conflict arises and whether existing LLMs fulfill them. We posit that LLMs should 1) identify knowledge conflicts, 2) pinpoint conflicting information segments, and 3) provide distinct answers or viewpoints in conflicting scenarios. To this end, we introduce KNOWLEDGE CONFLICT, an evaluation framework for simulating contextual knowledge conflicts and quantitatively evaluating to what extent LLMs achieve these goals. KNOWLEDGE CONFLICT includes diverse and complex situations of knowledge conflict, knowledge from diverse entities and domains, two synthetic conflict creation methods, and settings with progressively increasing difficulty to reflect realistic knowledge conflicts. Extensive experiments with the KNOWLEDGE CONFLICT framework reveal that while LLMs perform well in identifying the existence of knowledge conflicts, they struggle to determine the specific conflicting knowledge and produce a response with distinct answers amidst conflicting information. To address these challenges, we propose new instruction-based approaches that augment LLMs to better achieve the three goals. Further analysis shows that abilities to tackle knowledge conflicts are greatly impacted by factors such as knowledge domain and prompt text, while generating robust responses to knowledge conflict scenarios remains an open research question.
Locality-Aware Generalizable Implicit Neural Representation
Oct 12, 2023Generalizable implicit neural representation (INR) enables a single continuous function, i.e., a coordinate-based neural network, to represent multiple data instances by modulating its weights or intermediate features using latent codes. However, the expressive power of the state-of-the-art modulation is limited due to its inability to localize and capture fine-grained details of data entities such as specific pixels and rays. To address this issue, we propose a novel framework for generalizable INR that combines a transformer encoder with a locality-aware INR decoder. The transformer encoder predicts a set of latent tokens from a data instance to encode local information into each latent token. The locality-aware INR decoder extracts a modulation vector by selectively aggregating the latent tokens via cross-attention for a coordinate input and then predicts the output by progressively decoding with coarse-to-fine modulation through multiple frequency bandwidths. The selective token aggregation and the multi-band feature modulation enable us to learn locality-aware representation in spatial and spectral aspects, respectively. Our framework significantly outperforms previous generalizable INRs and validates the usefulness of the locality-aware latents for downstream tasks such as image generation.