 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MULAN: A Multi Layer Annotated Dataset for Controllable Text-to-Image Generation
Apr 03, 2024
Text-to-image generation has achieved astonishing results, yet precise spatial controllability and prompt fidelity remain highly challenging. This limitation is typically addressed through cumbersome prompt engineering, scene layout conditioning, or image editing techniques which often require hand drawn masks. Nonetheless, pre-existing works struggle to take advantage of the natural instance-level compositionality of scenes due to the typically flat nature of rasterized RGB output images. Towards adressing this challenge, we introduce MuLAn: a novel dataset comprising over 44K MUlti-Layer ANnotations of RGB images as multilayer, instance-wise RGBA decompositions, and over 100K instance images. To build MuLAn, we developed a training free pipeline which decomposes a monocular RGB image into a stack of RGBA layers comprising of background and isolated instances. We achieve this through the use of pretrained general-purpose models, and by developing three modules: image decomposition for instance discovery and extraction, instance completion to reconstruct occluded areas, and image re-assembly. We use our pipeline to create MuLAn-COCO and MuLAn-LAION datasets, which contain a variety of image decompositions in terms of style, composition and complexity. With MuLAn, we provide the first photorealistic resource providing instance decomposition and occlusion information for high quality images, opening up new avenues for text-to-image generative AI research. With this, we aim to encourage the development of novel generation and editing technology, in particular layer-wise solutions. MuLAn data resources are available at https://MuLAn-dataset.github.io/.
Adaptive Affinity-Based Generalization For MRI Imaging Segmentation Across Resource-Limited Settings
Apr 03, 2024The joint utilization of diverse data sources for medical imaging segmentation has emerged as a crucial area of research, aiming to address challenges such as data heterogeneity, domain shift, and data quality discrepancies. Integrating information from multiple data domains has shown promise in improving model generalizability and adaptability. However, this approach often demands substantial computational resources, hindering its practicality. In response, knowledge distillation (KD) has garnered attention as a solution. KD involves training light-weight models to emulate the behavior of more resource-intensive models, thereby mitigating the computational burden while maintaining performance. This paper addresses the pressing need to develop a lightweight and generalizable model for medical imaging segmentation that can effectively handle data integration challenges. Our proposed approach introduces a novel relation-based knowledge framework by seamlessly combining adaptive affinity-based and kernel-based distillation through a gram matrix that can capture the style representation across features. This methodology empowers the student model to accurately replicate the feature representations of the teacher model, facilitating robust performance even in the face of domain shift and data heterogeneity. To validate our innovative approach, we conducted experiments on publicly available multi-source prostate MRI data. The results demonstrate a significant enhancement in segmentation performance using lightweight networks. Notably, our method achieves this improvement while reducing both inference time and storage usage, rendering it a practical and efficient solution for real-time medical imaging segmentation.
Gegenbauer Graph Neural Networks for Time-varying Signal Reconstruction
Apr 03, 2024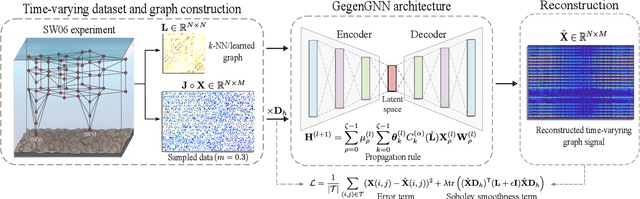
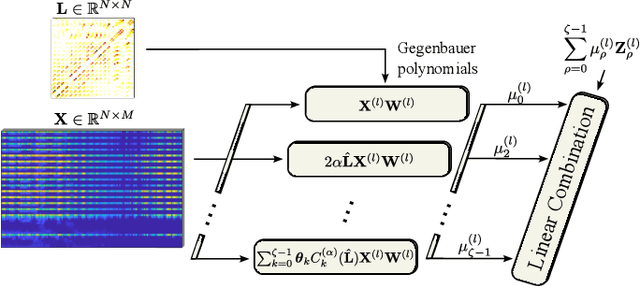
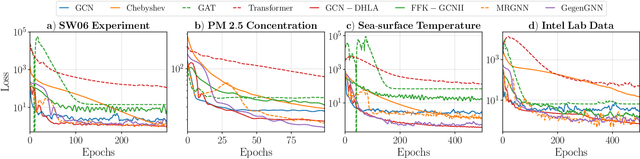
Reconstructing time-varying graph signals (or graph time-series imputation) is a critical problem in machine learning and signal processing with broad applications, ranging from missing data imputation in sensor networks to time-series forecasting. Accurately capturing the spatio-temporal information inherent in these signals is crucial for effectively addressing these tasks. However, existing approaches relying on smoothness assumptions of temporal differences and simple convex optimization techniques have inherent limitations. To address these challenges, we propose a novel approach that incorporates a learning module to enhance the accuracy of the downstream task. To this end, we introduce the Gegenbauer-based graph convolutional (GegenConv) operator, which is a generalization of the conventional Chebyshev graph convolution by leveraging the theory of Gegenbauer polynomials. By deviating from traditional convex problems, we expand the complexity of the model and offer a more accurate solution for recovering time-varying graph signals. Building upon GegenConv, we design the Gegenbauer-based time Graph Neural Network (GegenGNN) architecture, which adopts an encoder-decoder structure. Likewise, our approach also utilizes a dedicated loss function that incorporates a mean squared error component alongside Sobolev smoothness regularization. This combination enables GegenGNN to capture both the fidelity to ground truth and the underlying smoothness properties of the signals, enhancing the reconstruction performance. We conduct extensive experiments on real datasets to evaluate the effectiveness of our proposed approach. The experimental results demonstrate that GegenGNN outperforms state-of-the-art methods, showcasing its superior capability in recovering time-varying graph signals.
Direct Preference Optimization of Video Large Multimodal Models from Language Model Reward
Apr 02, 2024Preference modeling techniques, such as direct preference optimization (DPO), has shown effective in enhancing the generalization abilities of large language model (LLM). However, in tasks involving video instruction-following, providing informative feedback, especially for detecting hallucinations in generated responses, remains a significant challenge. Previous studies have explored using large large multimodal models (LMMs) as reward models to guide preference modeling, but their ability to accurately assess the factuality of generated responses compared to corresponding videos has not been conclusively established. This paper introduces a novel framework that utilizes detailed video captions as a proxy of video content, enabling language models to incorporate this information as supporting evidence for scoring video Question Answering (QA) predictions. Our approach demonstrates robust alignment with OpenAI GPT-4V model's reward mechanism, which directly takes video frames as input. Furthermore, we show that applying this tailored reward through DPO significantly improves the performance of video LMMs on video QA tasks.
Selective Temporal Knowledge Graph Reasoning
Apr 02, 2024Temporal Knowledge Graph (TKG), which characterizes temporally evolving facts in the form of (subject, relation, object, timestamp), has attracted much attention recently. TKG reasoning aims to predict future facts based on given historical ones. However, existing TKG reasoning models are unable to abstain from predictions they are uncertain, which will inevitably bring risks in real-world applications. Thus, in this paper, we propose an abstention mechanism for TKG reasoning, which helps the existing models make selective, instead of indiscriminate, predictions. Specifically, we develop a confidence estimator, called Confidence Estimator with History (CEHis), to enable the existing TKG reasoning models to first estimate their confidence in making predictions, and then abstain from those with low confidence. To do so, CEHis takes two kinds of information into consideration, namely, the certainty of the current prediction and the accuracy of historical predictions. Experiments with representative TKG reasoning models on two benchmark datasets demonstrate the effectiveness of the proposed CEHis.
Supervised Autoencoder MLP for Financial Time Series Forecasting
Apr 02, 2024This paper investigates the enhancement of financial time series forecasting with the use of neural networks through supervised autoencoders, aiming to improve investment strategy performance. It specifically examines the impact of noise augmentation and triple barrier labeling on risk-adjusted returns, using the Sharpe and Information Ratios. The study focuses on the S&P 500 index, EUR/USD, and BTC/USD as the traded assets from January 1, 2010, to April 30, 2022. Findings indicate that supervised autoencoders, with balanced noise augmentation and bottleneck size, significantly boost strategy effectiveness. However, excessive noise and large bottleneck sizes can impair performance, highlighting the importance of precise parameter tuning. This paper also presents a derivation of a novel optimization metric that can be used with triple barrier labeling. The results of this study have substantial policy implications, suggesting that financial institutions and regulators could leverage techniques presented to enhance market stability and investor protection, while also encouraging more informed and strategic investment approaches in various financial sectors.
Global Mapping of Exposure and Physical Vulnerability Dynamics in Least Developed Countries using Remote Sensing and Machine Learning
Apr 02, 2024As the world marked the midterm of the Sendai Framework for Disaster Risk Reduction 2015-2030, many countries are still struggling to monitor their climate and disaster risk because of the expensive large-scale survey of the distribution of exposure and physical vulnerability and, hence, are not on track in reducing risks amidst the intensifying effects of climate change. We present an ongoing effort in mapping this vital information using machine learning and time-series remote sensing from publicly available Sentinel-1 SAR GRD and Sentinel-2 Harmonized MSI. We introduce the development of "OpenSendaiBench" consisting of 47 countries wherein most are least developed (LDCs), trained ResNet-50 deep learning models, and demonstrated the region of Dhaka, Bangladesh by mapping the distribution of its informal constructions. As a pioneering effort in auditing global disaster risk over time, this paper aims to advance the area of large-scale risk quantification in informing our collective long-term efforts in reducing climate and disaster risk.
How Robust are the Tabular QA Models for Scientific Tables? A Study using Customized Dataset
Mar 30, 2024Question-answering (QA) on hybrid scientific tabular and textual data deals with scientific information, and relies on complex numerical reasoning. In recent years, while tabular QA has seen rapid progress, understanding their robustness on scientific information is lacking due to absence of any benchmark dataset. To investigate the robustness of the existing state-of-the-art QA models on scientific hybrid tabular data, we propose a new dataset, "SciTabQA", consisting of 822 question-answer pairs from scientific tables and their descriptions. With the help of this dataset, we assess the state-of-the-art Tabular QA models based on their ability (i) to use heterogeneous information requiring both structured data (table) and unstructured data (text) and (ii) to perform complex scientific reasoning tasks. In essence, we check the capability of the models to interpret scientific tables and text. Our experiments show that "SciTabQA" is an innovative dataset to study question-answering over scientific heterogeneous data. We benchmark three state-of-the-art Tabular QA models, and find that the best F1 score is only 0.462.
CLIP-driven Outliers Synthesis for few-shot OOD detection
Mar 30, 2024Few-shot OOD detection focuses on recognizing out-of-distribution (OOD) images that belong to classes unseen during training, with the use of only a small number of labeled in-distribution (ID) images. Up to now, a mainstream strategy is based on large-scale vision-language models, such as CLIP. However, these methods overlook a crucial issue: the lack of reliable OOD supervision information, which can lead to biased boundaries between in-distribution (ID) and OOD. To tackle this problem, we propose CLIP-driven Outliers Synthesis~(CLIP-OS). Firstly, CLIP-OS enhances patch-level features' perception by newly proposed patch uniform convolution, and adaptively obtains the proportion of ID-relevant information by employing CLIP-surgery-discrepancy, thus achieving separation between ID-relevant and ID-irrelevant. Next, CLIP-OS synthesizes reliable OOD data by mixing up ID-relevant features from different classes to provide OOD supervision information. Afterward, CLIP-OS leverages synthetic OOD samples by unknown-aware prompt learning to enhance the separability of ID and OOD. Extensive experiments across multiple benchmarks demonstrate that CLIP-OS achieves superior few-shot OOD detection capability.
CAAP: Class-Dependent Automatic Data Augmentation Based On Adaptive Policies For Time Series
Apr 01, 2024Data Augmentation is a common technique used to enhance the performance of deep learning models by expanding the training dataset. Automatic Data Augmentation (ADA) methods are getting popular because of their capacity to generate policies for various datasets. However, existing ADA methods primarily focused on overall performance improvement, neglecting the problem of class-dependent bias that leads to performance reduction in specific classes. This bias poses significant challenges when deploying models in real-world applications. Furthermore, ADA for time series remains an underexplored domain, highlighting the need for advancements in this field. In particular, applying ADA techniques to vital signals like an electrocardiogram (ECG) is a compelling example due to its potential in medical domains such as heart disease diagnostics. We propose a novel deep learning-based approach called Class-dependent Automatic Adaptive Policies (CAAP) framework to overcome the notable class-dependent bias problem while maintaining the overall improvement in time-series data augmentation. Specifically, we utilize the policy network to generate effective sample-wise policies with balanced difficulty through class and feature information extraction. Second, we design the augmentation probability regulation method to minimize class-dependent bias. Third, we introduce the information region concepts into the ADA framework to preserve essential regions in the sample. Through a series of experiments on real-world ECG datasets, we demonstrate that CAAP outperforms representative methods in achieving lower class-dependent bias combined with superior overall performance. These results highlight the reliability of CAAP as a promising ADA method for time series modeling that fits for the demands of real-world applications.