 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDL-KDD: Dual-Light Knowledge Distillation for Action Recognition in the Dark
Jun 04, 2024Human action recognition in dark videos is a challenging task for computer vision. Recent research focuses on applying dark enhancement methods to improve the visibility of the video. However, such video processing results in the loss of critical information in the original (un-enhanced) video. Conversely, traditional two-stream methods are capable of learning information from both original and processed videos, but it can lead to a significant increase in the computational cost during the inference phase in the task of video classification. To address these challenges, we propose a novel teacher-student video classification framework, named Dual-Light KnowleDge Distillation for Action Recognition in the Dark (DL-KDD). This framework enables the model to learn from both original and enhanced video without introducing additional computational cost during inference. Specifically, DL-KDD utilizes the strategy of knowledge distillation during training. The teacher model is trained with enhanced video, and the student model is trained with both the original video and the soft target generated by the teacher model. This teacher-student framework allows the student model to predict action using only the original input video during inference. In our experiments, the proposed DL-KDD framework outperforms state-of-the-art methods on the ARID, ARID V1.5, and Dark-48 datasets. We achieve the best performance on each dataset and up to a 4.18% improvement on Dark-48, using only original video inputs, thus avoiding the use of two-stream framework or enhancement modules for inference. We further validate the effectiveness of the distillation strategy in ablative experiments. The results highlight the advantages of our knowledge distillation framework in dark human action recognition.
CAAP: Class-Dependent Automatic Data Augmentation Based On Adaptive Policies For Time Series
Apr 01, 2024



Data Augmentation is a common technique used to enhance the performance of deep learning models by expanding the training dataset. Automatic Data Augmentation (ADA) methods are getting popular because of their capacity to generate policies for various datasets. However, existing ADA methods primarily focused on overall performance improvement, neglecting the problem of class-dependent bias that leads to performance reduction in specific classes. This bias poses significant challenges when deploying models in real-world applications. Furthermore, ADA for time series remains an underexplored domain, highlighting the need for advancements in this field. In particular, applying ADA techniques to vital signals like an electrocardiogram (ECG) is a compelling example due to its potential in medical domains such as heart disease diagnostics. We propose a novel deep learning-based approach called Class-dependent Automatic Adaptive Policies (CAAP) framework to overcome the notable class-dependent bias problem while maintaining the overall improvement in time-series data augmentation. Specifically, we utilize the policy network to generate effective sample-wise policies with balanced difficulty through class and feature information extraction. Second, we design the augmentation probability regulation method to minimize class-dependent bias. Third, we introduce the information region concepts into the ADA framework to preserve essential regions in the sample. Through a series of experiments on real-world ECG datasets, we demonstrate that CAAP outperforms representative methods in achieving lower class-dependent bias combined with superior overall performance. These results highlight the reliability of CAAP as a promising ADA method for time series modeling that fits for the demands of real-world applications.
Large Models for Time Series and Spatio-Temporal Data: A Survey and Outlook
Oct 20, 2023



Temporal data, notably time series and spatio-temporal data, are prevalent in real-world applications. They capture dynamic system measurements and are produced in vast quantities by both physical and virtual sensors. Analyzing these data types is vital to harnessing the rich information they encompass and thus benefits a wide range of downstream tasks. Recent advances in large language and other foundational models have spurred increased use of these models in time series and spatio-temporal data mining. Such methodologies not only enable enhanced pattern recognition and reasoning across diverse domains but also lay the groundwork for artificial general intelligence capable of comprehending and processing common temporal data. In this survey, we offer a comprehensive and up-to-date review of large models tailored (or adapted) for time series and spatio-temporal data, spanning four key facets: data types, model categories, model scopes, and application areas/tasks. Our objective is to equip practitioners with the knowledge to develop applications and further research in this underexplored domain. We primarily categorize the existing literature into two major clusters: large models for time series analysis (LM4TS) and spatio-temporal data mining (LM4STD). On this basis, we further classify research based on model scopes (i.e., general vs. domain-specific) and application areas/tasks. We also provide a comprehensive collection of pertinent resources, including datasets, model assets, and useful tools, categorized by mainstream applications. This survey coalesces the latest strides in large model-centric research on time series and spatio-temporal data, underscoring the solid foundations, current advances, practical applications, abundant resources, and future research opportunities.
Multi-view knowledge distillation transformer for human action recognition
Mar 25, 2023



Recently, Transformer-based methods have been utilized to improve the performance of human action recognition. However, most of these studies assume that multi-view data is complete, which may not always be the case in real-world scenarios. Therefore, this paper presents a novel Multi-view Knowledge Distillation Transformer (MKDT) framework that consists of a teacher network and a student network. This framework aims to handle incomplete human action problems in real-world applications. Specifically, the multi-view knowledge distillation transformer uses a hierarchical vision transformer with shifted windows to capture more spatial-temporal information. Experimental results demonstrate that our framework outperforms the CNN-based method on three public datasets.
FLAG: Fast Label-Adaptive Aggregation for Multi-label Classification in Federated Learning
Feb 27, 2023



Federated learning aims to share private data to maximize the data utility without privacy leakage. Previous federated learning research mainly focuses on multi-class classification problems. However, multi-label classification is a crucial research problem close to real-world data properties. Nevertheless, a limited number of federated learning studies explore this research problem. Existing studies of multi-label federated learning did not consider the characteristics of multi-label data, i.e., they used the concept of multi-class classification to verify their methods' performance, which means it will not be feasible to apply their methods to real-world applications. Therefore, this study proposed a new multi-label federated learning framework with a Clustering-based Multi-label Data Allocation (CMDA) and a novel aggregation method, Fast Label-Adaptive Aggregation (FLAG), for multi-label classification in the federated learning environment. The experimental results demonstrate that our methods only need less than 50\% of training epochs and communication rounds to surpass the performance of state-of-the-art federated learning methods.
Snippet Policy Network for Multi-class Varied-length ECG Early Classification
Jul 28, 2021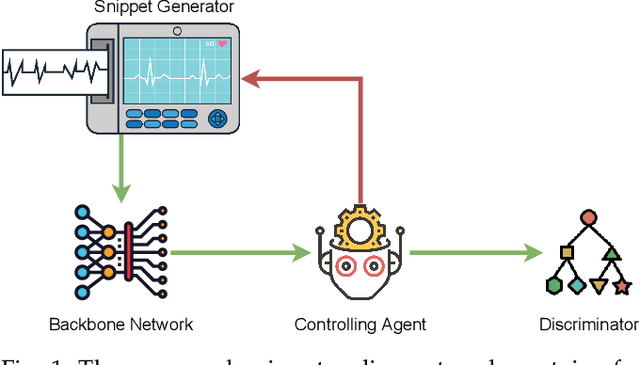
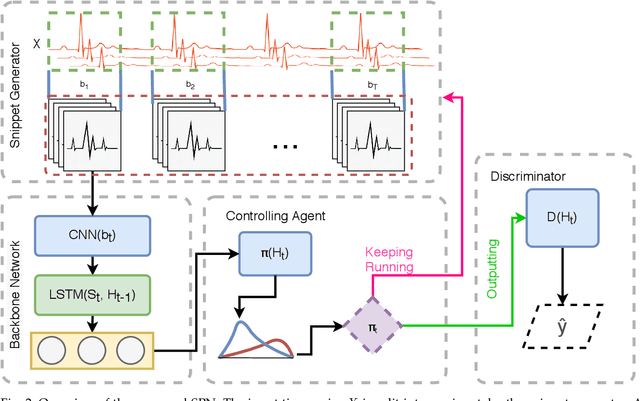
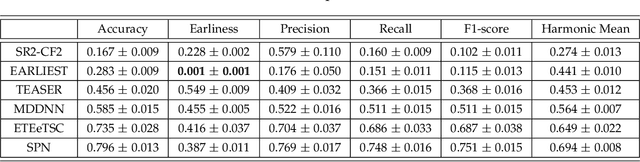
Arrhythmia detection from ECG is an important research subject in the prevention and diagnosis of cardiovascular diseases. The prevailing studies formulate arrhythmia detection from ECG as a time series classification problem. Meanwhile, early detection of arrhythmia presents a real-world demand for early prevention and diagnosis. In this paper, we address a problem of cardiovascular disease early classification, which is a varied-length and long-length time series early classification problem as well. For solving this problem, we propose a deep reinforcement learning-based framework, namely Snippet Policy Network (SPN), consisting of four modules, snippet generator, backbone network, controlling agent, and discriminator. Comparing to the existing approaches, the proposed framework features flexible input length, solves the dual-optimization solution of the earliness and accuracy goals. Experimental results demonstrate that SPN achieves an excellent performance of over 80\% in terms of accuracy. Compared to the state-of-the-art methods, at least 7% improvement on different metrics, including the precision, recall, F1-score, and harmonic mean, is delivered by the proposed SPN. To the best of our knowledge, this is the first work focusing on solving the cardiovascular early classification problem based on varied-length ECG data. Based on these excellent features from SPN, it offers a good exemplification for addressing all kinds of varied-length time series early classification problems.