 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Cylindrical Representation Hypothesis for Language Model Steering
May 03, 2026Steering is a widely used technique for controlling large language models, yet its effects are often unstable and hard to predict. Existing theoretical accounts are largely based on the Linear Representation Hypothesis (LRH). While LRH assumes that concepts can be orthogonalized for lossless control, this idealized mapping fails in real representations and cannot account for the observed unpredictability of steering. By relaxing LRH's orthogonality assumption while preserving linear representations, we show that overlapping concept contributions naturally yield a sample-specific axis-orthogonal structure. We formalize this as the Cylindrical Representation Hypothesis (CRH). In CRH, a central axis captures the main difference between concept absence and presence and drives concept generation. A surrounding normal plane controls steering sensitivity by determining how easily the axis can activate the target concept. Within this plane, only specific sensitive sectors strongly facilitate concept activation, while other sectors can suppress or delay it. While the surrounding normal plane can be reliably identified from difference vectors, the sensitive sector cannot, introducing intrinsic uncertainty at the sector level. This uncertainty provides a principled explanation for why steering outcomes often fluctuate even when using well-aligned directions. Our experiments verify the existence of the cylindrical structure and demonstrate that CRH provides a valid and practical way to interpret model steering behavior in real settings: https://github.com/mbzuai-nlp/CRH.
CarePilot: A Multi-Agent Framework for Long-Horizon Computer Task Automation in Healthcare
Mar 25, 2026Multimodal agentic pipelines are transforming human-computer interaction by enabling efficient and accessible automation of complex, real-world tasks. However, recent efforts have focused on short-horizon or general-purpose applications (e.g., mobile or desktop interfaces), leaving long-horizon automation for domain-specific systems, particularly in healthcare, largely unexplored. To address this, we introduce CareFlow, a high-quality human-annotated benchmark comprising complex, long-horizon software workflows across medical annotation tools, DICOM viewers, EHR systems, and laboratory information systems. On this benchmark, existing vision-language models (VLMs) perform poorly, struggling with long-horizon reasoning and multi-step interactions in medical contexts. To overcome this, we propose CarePilot, a multi-agent framework based on the actor-critic paradigm. The Actor integrates tool grounding with dual-memory mechanisms (long-term and short-term experience) to predict the next semantic action from the visual interface and system state. The Critic evaluates each action, updates memory based on observed effects, and either executes or provides corrective feedback to refine the workflow. Through iterative agentic simulation, the Actor learns to perform more robust and reasoning-aware predictions during inference. Our experiments show that CarePilot achieves state-of-the-art performance, outperforming strong closed-source and open-source multimodal baselines by approximately 15.26% and 3.38%, respectively, on our benchmark and out-of-distribution dataset.
CURE-Med: Curriculum-Informed Reinforcement Learning for Multilingual Medical Reasoning
Jan 19, 2026While large language models (LLMs) have shown to perform well on monolingual mathematical and commonsense reasoning, they remain unreliable for multilingual medical reasoning applications, hindering their deployment in multilingual healthcare settings. We address this by first introducing CUREMED-BENCH, a high-quality multilingual medical reasoning dataset with open-ended reasoning queries with a single verifiable answer, spanning thirteen languages, including underrepresented languages such as Amharic, Yoruba, and Swahili. Building on this dataset, we propose CURE-MED, a curriculum-informed reinforcement learning framework that integrates code-switching-aware supervised fine-tuning and Group Relative Policy Optimization to jointly improve logical correctness and language stability. Across thirteen languages, our approach consistently outperforms strong baselines and scales effectively, achieving 85.21% language consistency and 54.35% logical correctness at 7B parameters, and 94.96% language consistency and 70.04% logical correctness at 32B parameters. These results support reliable and equitable multilingual medical reasoning in LLMs. The code and dataset are available at https://cure-med.github.io/
CLINIC: Evaluating Multilingual Trustworthiness in Language Models for Healthcare
Dec 12, 2025Integrating language models (LMs) in healthcare systems holds great promise for improving medical workflows and decision-making. However, a critical barrier to their real-world adoption is the lack of reliable evaluation of their trustworthiness, especially in multilingual healthcare settings. Existing LMs are predominantly trained in high-resource languages, making them ill-equipped to handle the complexity and diversity of healthcare queries in mid- and low-resource languages, posing significant challenges for deploying them in global healthcare contexts where linguistic diversity is key. In this work, we present CLINIC, a Comprehensive Multilingual Benchmark to evaluate the trustworthiness of language models in healthcare. CLINIC systematically benchmarks LMs across five key dimensions of trustworthiness: truthfulness, fairness, safety, robustness, and privacy, operationalized through 18 diverse tasks, spanning 15 languages (covering all the major continents), and encompassing a wide array of critical healthcare topics like disease conditions, preventive actions, diagnostic tests, treatments, surgeries, and medications. Our extensive evaluation reveals that LMs struggle with factual correctness, demonstrate bias across demographic and linguistic groups, and are susceptible to privacy breaches and adversarial attacks. By highlighting these shortcomings, CLINIC lays the foundation for enhancing the global reach and safety of LMs in healthcare across diverse languages.
M3Retrieve: Benchmarking Multimodal Retrieval for Medicine
Oct 08, 2025



With the increasing use of RetrievalAugmented Generation (RAG), strong retrieval models have become more important than ever. In healthcare, multimodal retrieval models that combine information from both text and images offer major advantages for many downstream tasks such as question answering, cross-modal retrieval, and multimodal summarization, since medical data often includes both formats. However, there is currently no standard benchmark to evaluate how well these models perform in medical settings. To address this gap, we introduce M3Retrieve, a Multimodal Medical Retrieval Benchmark. M3Retrieve, spans 5 domains,16 medical fields, and 4 distinct tasks, with over 1.2 Million text documents and 164K multimodal queries, all collected under approved licenses. We evaluate leading multimodal retrieval models on this benchmark to explore the challenges specific to different medical specialities and to understand their impact on retrieval performance. By releasing M3Retrieve, we aim to enable systematic evaluation, foster model innovation, and accelerate research toward building more capable and reliable multimodal retrieval systems for medical applications. The dataset and the baselines code are available in this github page https://github.com/AkashGhosh/M3Retrieve.
Infogen: Generating Complex Statistical Infographics from Documents
Jul 26, 2025Statistical infographics are powerful tools that simplify complex data into visually engaging and easy-to-understand formats. Despite advancements in AI, particularly with LLMs, existing efforts have been limited to generating simple charts, with no prior work addressing the creation of complex infographics from text-heavy documents that demand a deep understanding of the content. We address this gap by introducing the task of generating statistical infographics composed of multiple sub-charts (e.g., line, bar, pie) that are contextually accurate, insightful, and visually aligned. To achieve this, we define infographic metadata that includes its title and textual insights, along with sub-chart-specific details such as their corresponding data and alignment. We also present Infodat, the first benchmark dataset for text-to-infographic metadata generation, where each sample links a document to its metadata. We propose Infogen, a two-stage framework where fine-tuned LLMs first generate metadata, which is then converted into infographic code. Extensive evaluations on Infodat demonstrate that Infogen achieves state-of-the-art performance, outperforming both closed and open-source LLMs in text-to-statistical infographic generation.
SANSKRITI: A Comprehensive Benchmark for Evaluating Language Models' Knowledge of Indian Culture
Jun 18, 2025

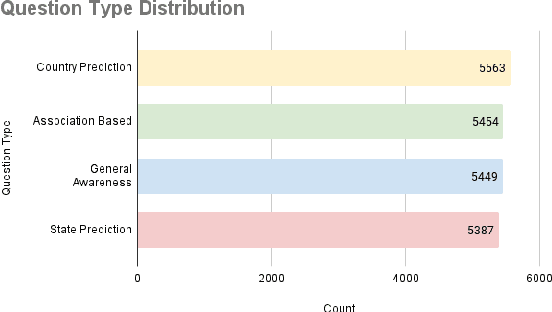
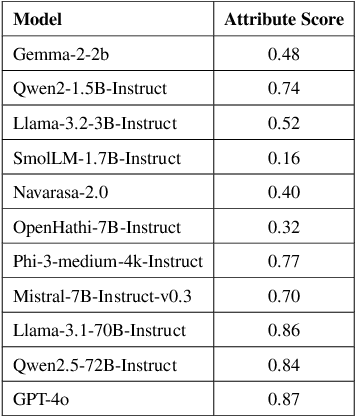
Language Models (LMs) are indispensable tools shaping modern workflows, but their global effectiveness depends on understanding local socio-cultural contexts. To address this, we introduce SANSKRITI, a benchmark designed to evaluate language models' comprehension of India's rich cultural diversity. Comprising 21,853 meticulously curated question-answer pairs spanning 28 states and 8 union territories, SANSKRITI is the largest dataset for testing Indian cultural knowledge. It covers sixteen key attributes of Indian culture: rituals and ceremonies, history, tourism, cuisine, dance and music, costume, language, art, festivals, religion, medicine, transport, sports, nightlife, and personalities, providing a comprehensive representation of India's cultural tapestry. We evaluate SANSKRITI on leading Large Language Models (LLMs), Indic Language Models (ILMs), and Small Language Models (SLMs), revealing significant disparities in their ability to handle culturally nuanced queries, with many models struggling in region-specific contexts. By offering an extensive, culturally rich, and diverse dataset, SANSKRITI sets a new standard for assessing and improving the cultural understanding of LMs.
The Multilingual Mind : A Survey of Multilingual Reasoning in Language Models
Feb 13, 2025While reasoning and multilingual capabilities in Language Models (LMs) have achieved remarkable progress in recent years, their integration into a unified paradigm, multilingual reasoning, is at a nascent stage. Multilingual reasoning requires language models to handle logical reasoning across languages while addressing misalignment, biases, and challenges in low-resource settings. This survey provides the first in-depth review of multilingual reasoning in LMs. In this survey, we provide a systematic overview of existing methods that leverage LMs for multilingual reasoning, specifically outlining the challenges, motivations, and foundational aspects of applying language models to reason across diverse languages. We provide an overview of the standard data resources used for training multilingual reasoning in LMs and the evaluation benchmarks employed to assess their multilingual capabilities. Next, we analyze various state-of-the-art methods and their performance on these benchmarks. Finally, we explore future research opportunities to improve multilingual reasoning in LMs, focusing on enhancing their ability to handle diverse languages and complex reasoning tasks.
Unveiling Hallucination in Text, Image, Video, and Audio Foundation Models: A Comprehensive Review
May 15, 2024



The rapid advancement of foundation models (FMs) across language, image, audio, and video domains has shown remarkable capabilities in diverse tasks. However, the proliferation of FMs brings forth a critical challenge: the potential to generate hallucinated outputs, particularly in high-stakes applications. The tendency of foundation models to produce hallucinated content arguably represents the biggest hindrance to their widespread adoption in real-world scenarios, especially in domains where reliability and accuracy are paramount. This survey paper presents a comprehensive overview of recent developments that aim to identify and mitigate the problem of hallucination in FMs, spanning text, image, video, and audio modalities. By synthesizing recent advancements in detecting and mitigating hallucination across various modalities, the paper aims to provide valuable insights for researchers, developers, and practitioners. Essentially, it establishes a clear framework encompassing definition, taxonomy, and detection strategies for addressing hallucination in multimodal foundation models, laying the foundation for future research in this pivotal area.
Parameter-Efficient Instruction Tuning of Large Language Models For Extreme Financial Numeral Labelling
May 15, 2024



We study the problem of automatically annotating relevant numerals (GAAP metrics) occurring in the financial documents with their corresponding XBRL tags. Different from prior works, we investigate the feasibility of solving this extreme classification problem using a generative paradigm through instruction tuning of Large Language Models (LLMs). To this end, we leverage metric metadata information to frame our target outputs while proposing a parameter efficient solution for the task using LoRA. We perform experiments on two recently released financial numeric labeling datasets. Our proposed model, FLAN-FinXC, achieves new state-of-the-art performances on both the datasets, outperforming several strong baselines. We explain the better scores of our proposed model by demonstrating its capability for zero-shot as well as the least frequently occurring tags. Also, even when we fail to predict the XBRL tags correctly, our generated output has substantial overlap with the ground-truth in majority of the cases.