 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Dual-Feedback Knowledge Retrieval for Task-Oriented Dialogue Systems
Oct 23, 2023
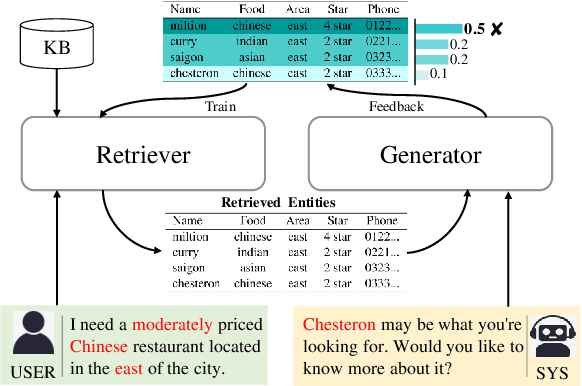
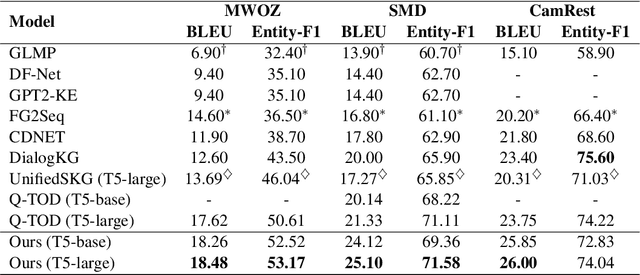
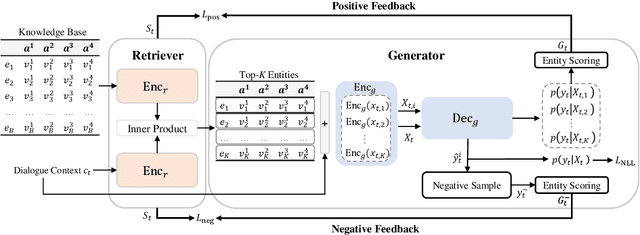
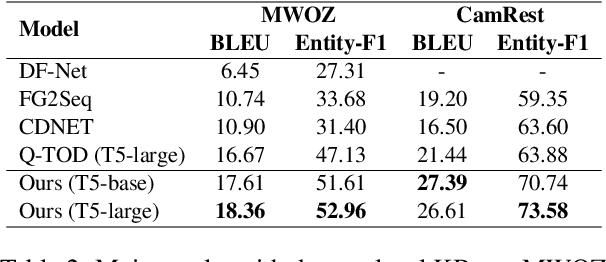
Efficient knowledge retrieval plays a pivotal role in ensuring the success of end-to-end task-oriented dialogue systems by facilitating the selection of relevant information necessary to fulfill user requests. However, current approaches generally integrate knowledge retrieval and response generation, which poses scalability challenges when dealing with extensive knowledge bases. Taking inspiration from open-domain question answering, we propose a retriever-generator architecture that harnesses a retriever to retrieve pertinent knowledge and a generator to generate system responses.~Due to the lack of retriever training labels, we propose relying on feedback from the generator as pseudo-labels to train the retriever. To achieve this, we introduce a dual-feedback mechanism that generates both positive and negative feedback based on the output of the generator. Our method demonstrates superior performance in task-oriented dialogue tasks, as evidenced by experimental results on three benchmark datasets.
Mid-Long Term Daily Electricity Consumption Forecasting Based on Piecewise Linear Regression and Dilated Causal CNN
Oct 23, 2023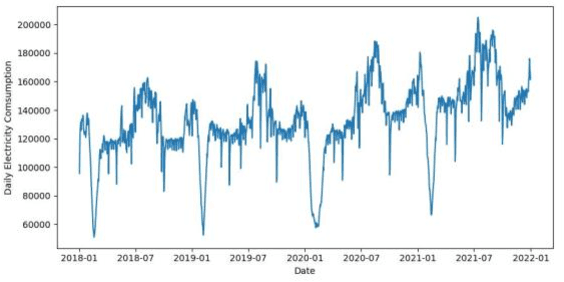
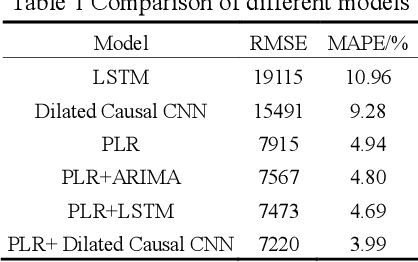
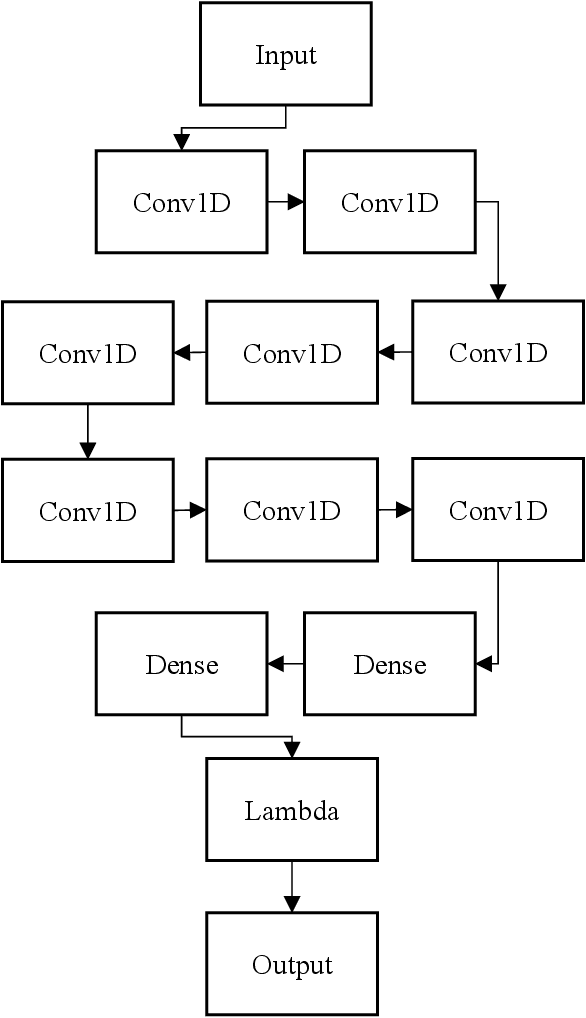
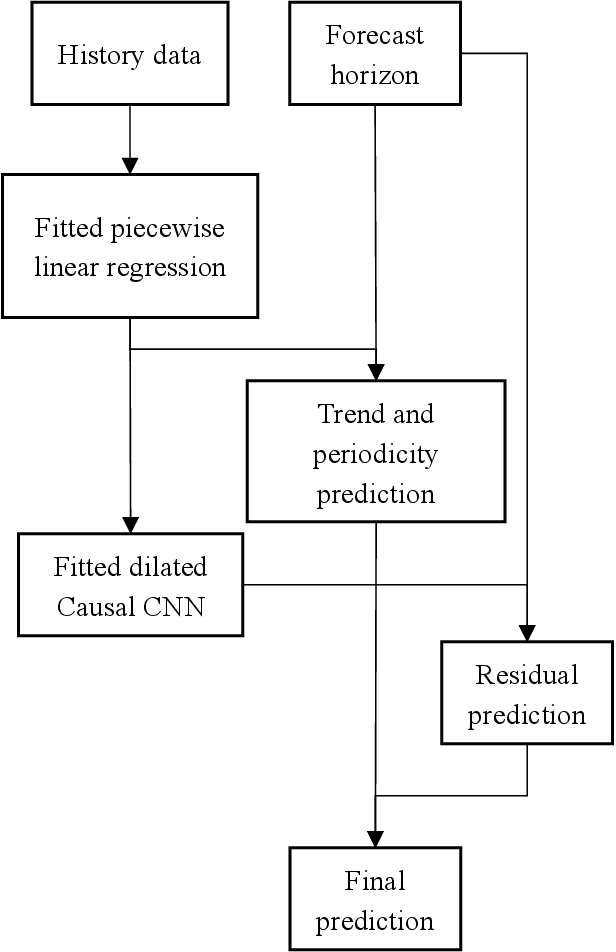
Daily electricity consumption forecasting is a classical problem. Existing forecasting algorithms tend to have decreased accuracy on special dates like holidays. This study decomposes the daily electricity consumption series into three components: trend, seasonal, and residual, and constructs a two-stage prediction method using piecewise linear regression as a filter and Dilated Causal CNN as a predictor. The specific steps involve setting breakpoints on the time axis and fitting the piecewise linear regression model with one-hot encoded information such as month, weekday, and holidays. For the challenging prediction of the Spring Festival, distance is introduced as a variable using a third-degree polynomial form in the model. The residual sequence obtained in the previous step is modeled using Dilated Causal CNN, and the final prediction of daily electricity consumption is the sum of the two-stage predictions. Experimental results demonstrate that this method achieves higher accuracy compared to existing approaches.
BanglaAbuseMeme: A Dataset for Bengali Abusive Meme Classification
Oct 18, 2023
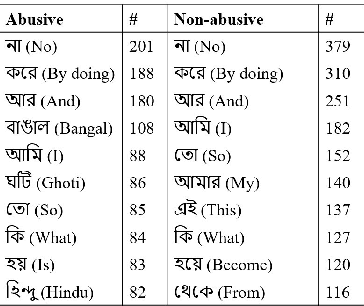
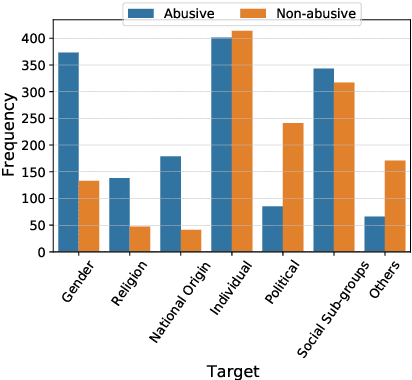
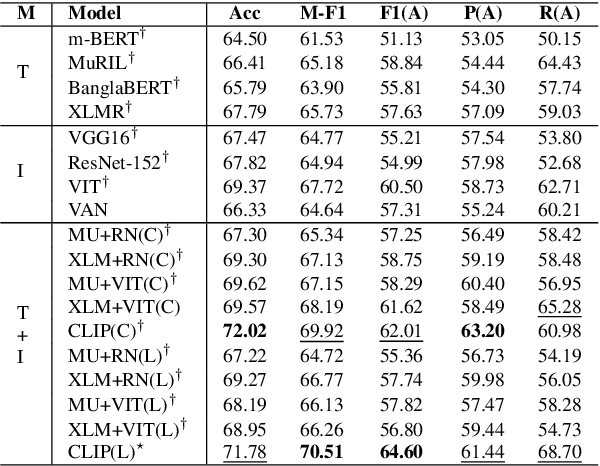
The dramatic increase in the use of social media platforms for information sharing has also fueled a steep growth in online abuse. A simple yet effective way of abusing individuals or communities is by creating memes, which often integrate an image with a short piece of text layered on top of it. Such harmful elements are in rampant use and are a threat to online safety. Hence it is necessary to develop efficient models to detect and flag abusive memes. The problem becomes more challenging in a low-resource setting (e.g., Bengali memes, i.e., images with Bengali text embedded on it) because of the absence of benchmark datasets on which AI models could be trained. In this paper we bridge this gap by building a Bengali meme dataset. To setup an effective benchmark we implement several baseline models for classifying abusive memes using this dataset. We observe that multimodal models that use both textual and visual information outperform unimodal models. Our best-performing model achieves a macro F1 score of 70.51. Finally, we perform a qualitative error analysis of the misclassified memes of the best-performing text-based, image-based and multimodal models.
Age Estimation Based on Graph Convolutional Networks and Multi-head Attention Mechanisms
Oct 12, 2023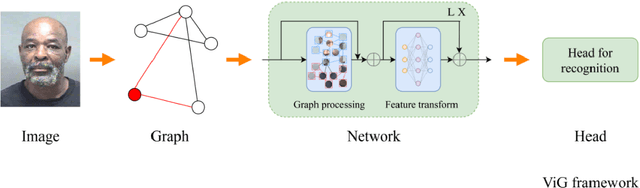
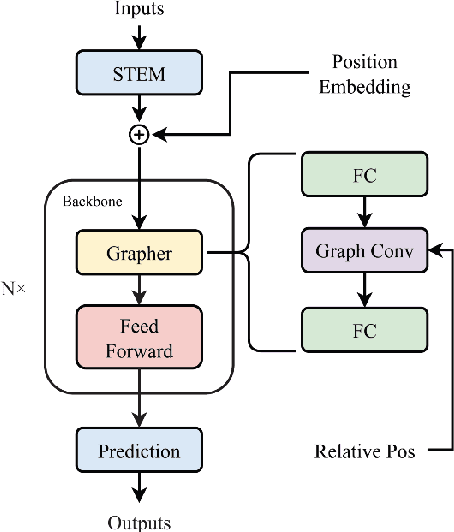
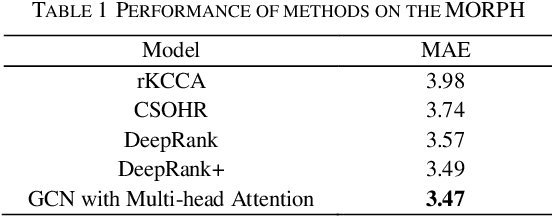
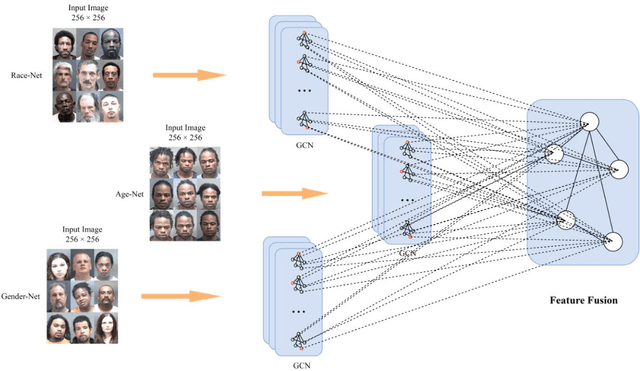
Age estimation technology is a part of facial recognition and has been applied to identity authentication. This technology achieves the development and application of a juvenile anti-addiction system by authenticating users in the game. Convolutional Neural Network (CNN) and Transformer algorithms are widely used in this application scenario. However, these two models cannot flexibly extract and model features of faces with irregular shapes, and they are ineffective in capturing key information. Furthermore, the above methods will contain a lot of background information while extracting features, which will interfere with the model. In consequence, it is easy to extract redundant information from images. In this paper, a new modeling idea is proposed to solve this problem, which can flexibly model irregular objects. The Graph Convolutional Network (GCN) is used to extract features from irregular face images effectively, and multi-head attention mechanisms are added to avoid redundant features and capture key region information in the image. This model can effectively improve the accuracy of age estimation and reduce the MAE error value to about 3.64, which is better than the effect of today's age estimation model, to improve the accuracy of face recognition and identity authentication.
BianQue: Balancing the Questioning and Suggestion Ability of Health LLMs with Multi-turn Health Conversations Polished by ChatGPT
Oct 24, 2023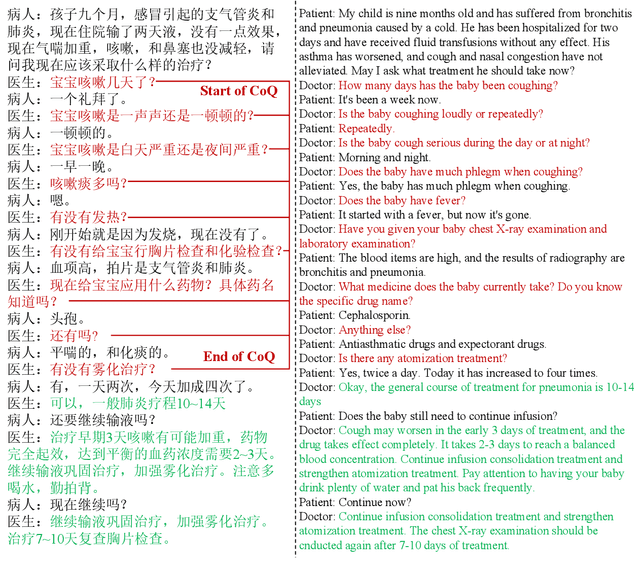
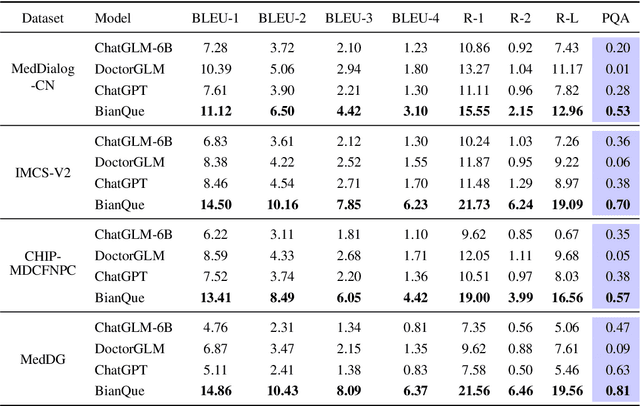
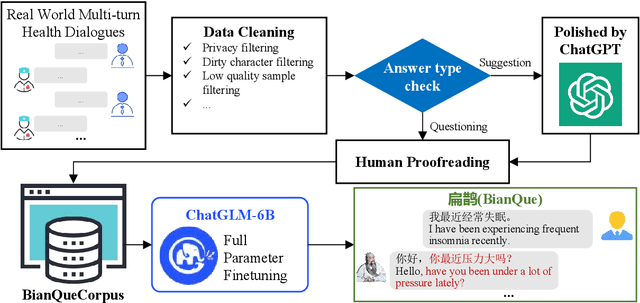
Large language models (LLMs) have performed well in providing general and extensive health suggestions in single-turn conversations, exemplified by systems such as ChatGPT, ChatGLM, ChatDoctor, DoctorGLM, and etc. However, the limited information provided by users during single turn results in inadequate personalization and targeting of the generated suggestions, which requires users to independently select the useful part. It is mainly caused by the missing ability to engage in multi-turn questioning. In real-world medical consultations, doctors usually employ a series of iterative inquiries to comprehend the patient's condition thoroughly, enabling them to provide effective and personalized suggestions subsequently, which can be defined as chain of questioning (CoQ) for LLMs. To improve the CoQ of LLMs, we propose BianQue, a ChatGLM-based LLM finetuned with the self-constructed health conversation dataset BianQueCorpus that is consist of multiple turns of questioning and health suggestions polished by ChatGPT. Experimental results demonstrate that the proposed BianQue can simultaneously balance the capabilities of both questioning and health suggestions, which will help promote the research and application of LLMs in the field of proactive health.
Retrieval-based Knowledge Transfer: An Effective Approach for Extreme Large Language Model Compression
Oct 24, 2023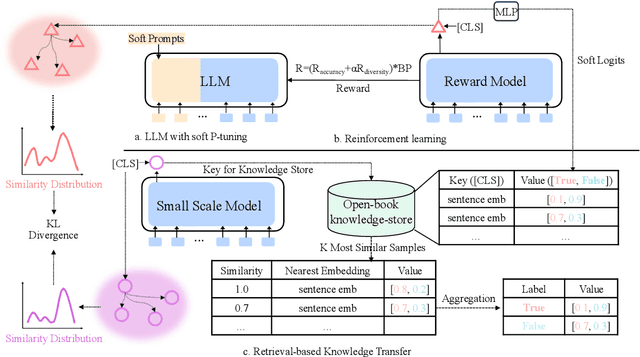
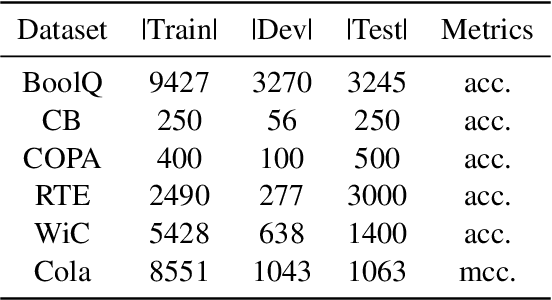
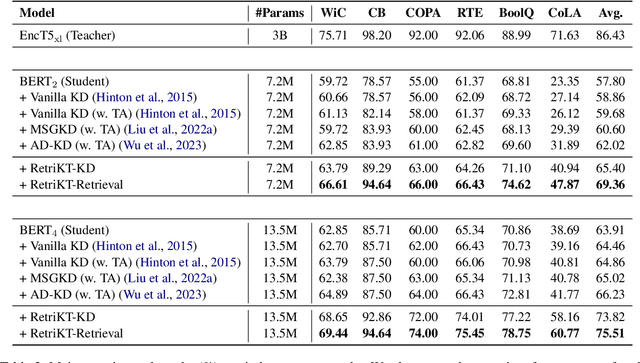
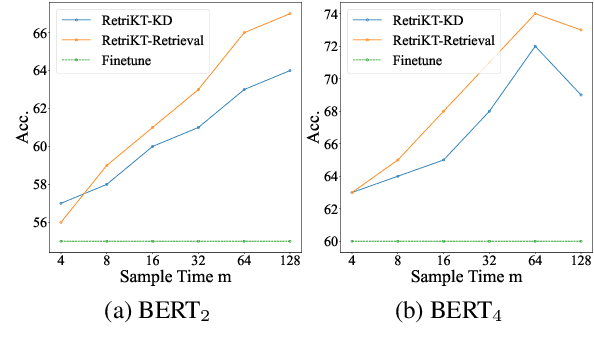
Large-scale pre-trained language models (LLMs) have demonstrated exceptional performance in various natural language processing (NLP) tasks. However, the massive size of these models poses huge challenges for their deployment in real-world applications. While numerous model compression techniques have been proposed, most of them are not well-suited for achieving extreme model compression when there is a significant gap in model scale. In this paper, we introduce a novel compression paradigm called Retrieval-based Knowledge Transfer (RetriKT), which effectively transfers the knowledge of LLMs to extremely small-scale models (e.g., 1%). In particular, our approach extracts knowledge from LLMs to construct a knowledge store, from which the small-scale model can retrieve relevant information and leverage it for effective inference. To improve the quality of the model, soft prompt tuning and Proximal Policy Optimization (PPO) reinforcement learning techniques are employed. Extensive experiments are conducted on low-resource tasks from SuperGLUE and GLUE benchmarks. The results demonstrate that the proposed approach significantly enhances the performance of small-scale models by leveraging the knowledge from LLMs.
CR-COPEC: Causal Rationale of Corporate Performance Changes to Learn from Financial Reports
Oct 24, 2023In this paper, we introduce CR-COPEC called Causal Rationale of Corporate Performance Changes from financial reports. This is a comprehensive large-scale domain-adaptation causal sentence dataset to detect financial performance changes of corporate. CR-COPEC contributes to two major achievements. First, it detects causal rationale from 10-K annual reports of the U.S. companies, which contain experts' causal analysis following accounting standards in a formal manner. This dataset can be widely used by both individual investors and analysts as material information resources for investing and decision making without tremendous effort to read through all the documents. Second, it carefully considers different characteristics which affect the financial performance of companies in twelve industries. As a result, CR-COPEC can distinguish causal sentences in various industries by taking unique narratives in each industry into consideration. We also provide an extensive analysis of how well CR-COPEC dataset is constructed and suited for classifying target sentences as causal ones with respect to industry characteristics. Our dataset and experimental codes are publicly available.
G-CASCADE: Efficient Cascaded Graph Convolutional Decoding for 2D Medical Image Segmentation
Oct 24, 2023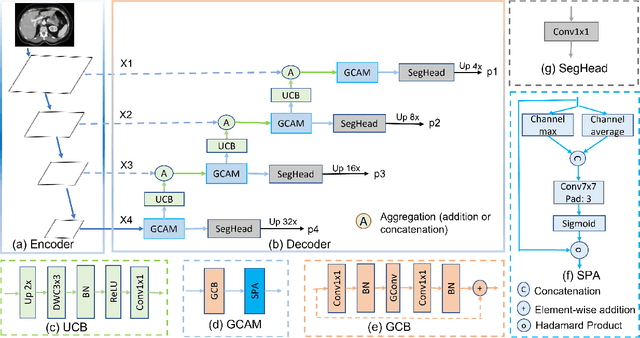
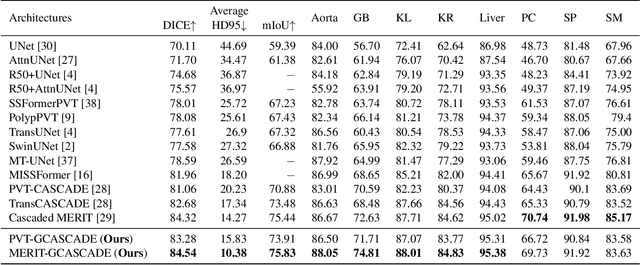
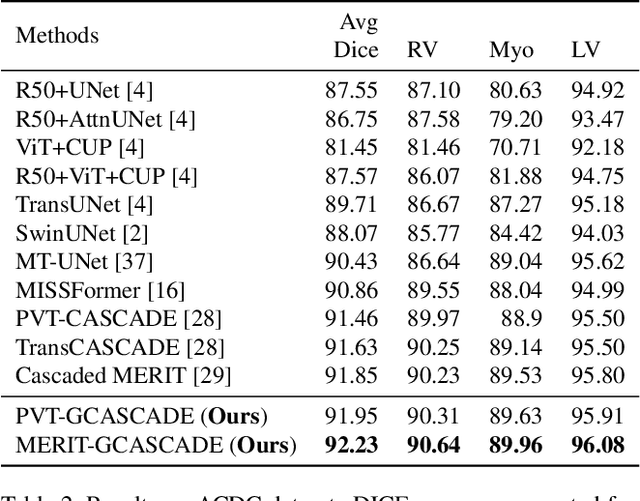
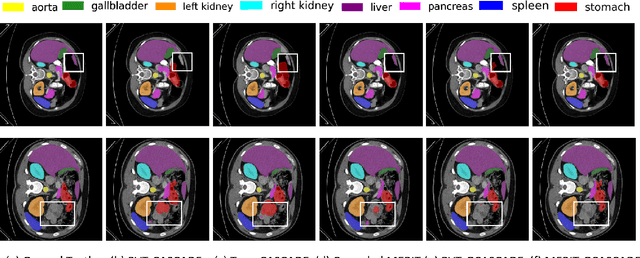
In recent years, medical image segmentation has become an important application in the field of computer-aided diagnosis. In this paper, we are the first to propose a new graph convolution-based decoder namely, Cascaded Graph Convolutional Attention Decoder (G-CASCADE), for 2D medical image segmentation. G-CASCADE progressively refines multi-stage feature maps generated by hierarchical transformer encoders with an efficient graph convolution block. The encoder utilizes the self-attention mechanism to capture long-range dependencies, while the decoder refines the feature maps preserving long-range information due to the global receptive fields of the graph convolution block. Rigorous evaluations of our decoder with multiple transformer encoders on five medical image segmentation tasks (i.e., Abdomen organs, Cardiac organs, Polyp lesions, Skin lesions, and Retinal vessels) show that our model outperforms other state-of-the-art (SOTA) methods. We also demonstrate that our decoder achieves better DICE scores than the SOTA CASCADE decoder with 80.8% fewer parameters and 82.3% fewer FLOPs. Our decoder can easily be used with other hierarchical encoders for general-purpose semantic and medical image segmentation tasks.
CP-BCS: Binary Code Summarization Guided by Control Flow Graph and Pseudo Code
Oct 24, 2023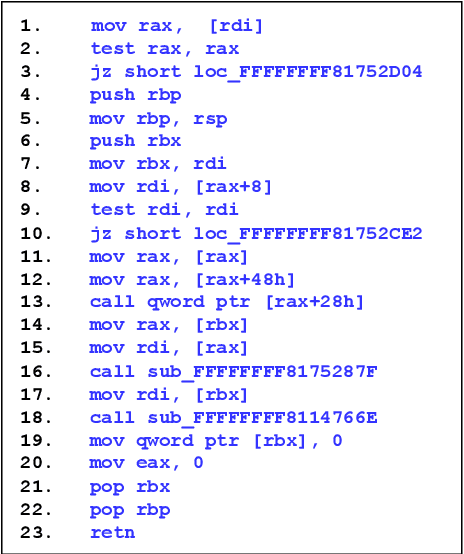
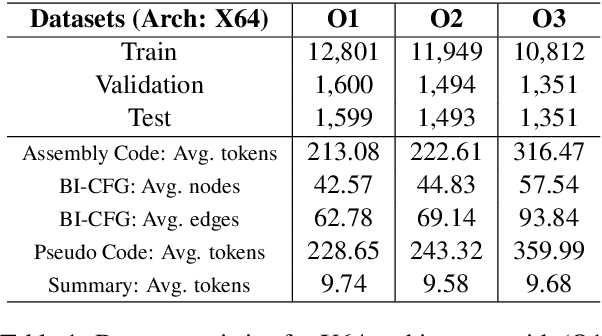
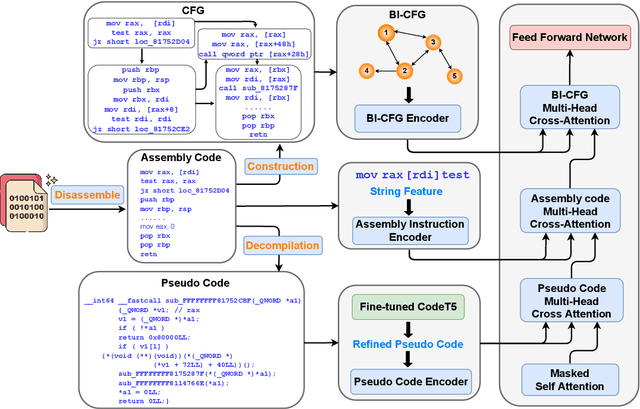
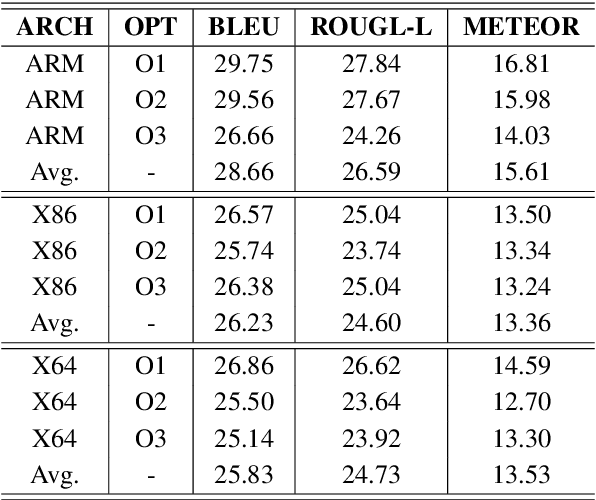
Automatically generating function summaries for binaries is an extremely valuable but challenging task, since it involves translating the execution behavior and semantics of the low-level language (assembly code) into human-readable natural language. However, most current works on understanding assembly code are oriented towards generating function names, which involve numerous abbreviations that make them still confusing. To bridge this gap, we focus on generating complete summaries for binary functions, especially for stripped binary (no symbol table and debug information in reality). To fully exploit the semantics of assembly code, we present a control flow graph and pseudo code guided binary code summarization framework called CP-BCS. CP-BCS utilizes a bidirectional instruction-level control flow graph and pseudo code that incorporates expert knowledge to learn the comprehensive binary function execution behavior and logic semantics. We evaluate CP-BCS on 3 different binary optimization levels (O1, O2, and O3) for 3 different computer architectures (X86, X64, and ARM). The evaluation results demonstrate CP-BCS is superior and significantly improves the efficiency of reverse engineering.
From Heuristic to Analytic: Cognitively Motivated Strategies for Coherent Physical Commonsense Reasoning
Oct 24, 2023Pre-trained language models (PLMs) have shown impressive performance in various language tasks. However, they are prone to spurious correlations, and often generate illusory information. In real-world applications, PLMs should justify decisions with formalized, coherent reasoning chains, but this challenge remains under-explored. Cognitive psychology theorizes that humans are capable of utilizing fast and intuitive heuristic thinking to make decisions based on past experience, then rationalizing the decisions through slower and deliberative analytic reasoning. We incorporate these interlinked dual processes in fine-tuning and in-context learning with PLMs, applying them to two language understanding tasks that require coherent physical commonsense reasoning. We show that our proposed Heuristic-Analytic Reasoning (HAR) strategies drastically improve the coherence of rationalizations for model decisions, yielding state-of-the-art results on Tiered Reasoning for Intuitive Physics (TRIP). We also find that this improved coherence is a direct result of more faithful attention to relevant language context in each step of reasoning. Our findings suggest that human-like reasoning strategies can effectively improve the coherence and reliability of PLM reasoning.