 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
FashionNTM: Multi-turn Fashion Image Retrieval via Cascaded Memory
Aug 20, 2023
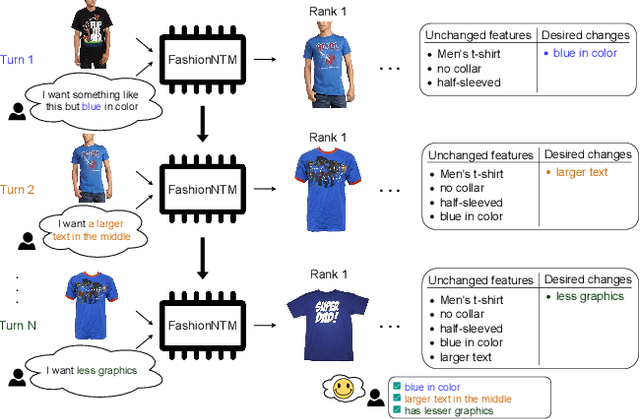
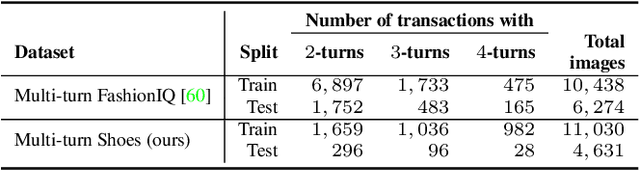
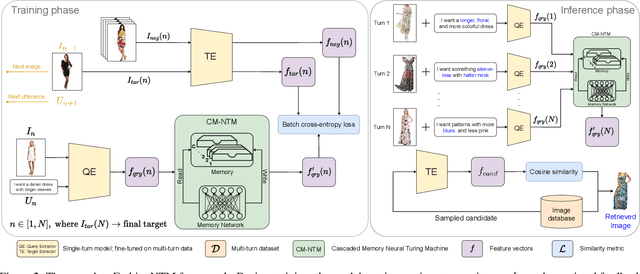
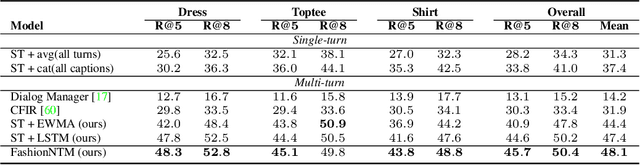
Multi-turn textual feedback-based fashion image retrieval focuses on a real-world setting, where users can iteratively provide information to refine retrieval results until they find an item that fits all their requirements. In this work, we present a novel memory-based method, called FashionNTM, for such a multi-turn system. Our framework incorporates a new Cascaded Memory Neural Turing Machine (CM-NTM) approach for implicit state management, thereby learning to integrate information across all past turns to retrieve new images, for a given turn. Unlike vanilla Neural Turing Machine (NTM), our CM-NTM operates on multiple inputs, which interact with their respective memories via individual read and write heads, to learn complex relationships. Extensive evaluation results show that our proposed method outperforms the previous state-of-the-art algorithm by 50.5%, on Multi-turn FashionIQ -- the only existing multi-turn fashion dataset currently, in addition to having a relative improvement of 12.6% on Multi-turn Shoes -- an extension of the single-turn Shoes dataset that we created in this work. Further analysis of the model in a real-world interactive setting demonstrates two important capabilities of our model -- memory retention across turns, and agnosticity to turn order for non-contradictory feedback. Finally, user study results show that images retrieved by FashionNTM were favored by 83.1% over other multi-turn models. Project page: https://sites.google.com/eng.ucsd.edu/fashionntm
T$^3$Bench: Benchmarking Current Progress in Text-to-3D Generation
Oct 04, 2023Recent methods in text-to-3D leverage powerful pretrained diffusion models to optimize NeRF. Notably, these methods are able to produce high-quality 3D scenes without training on 3D data. Due to the open-ended nature of the task, most studies evaluate their results with subjective case studies and user experiments, thereby presenting a challenge in quantitatively addressing the question: How has current progress in Text-to-3D gone so far? In this paper, we introduce T$^3$Bench, the first comprehensive text-to-3D benchmark containing diverse text prompts of three increasing complexity levels that are specially designed for 3D generation. To assess both the subjective quality and the text alignment, we propose two automatic metrics based on multi-view images produced by the 3D contents. The quality metric combines multi-view text-image scores and regional convolution to detect quality and view inconsistency. The alignment metric uses multi-view captioning and Large Language Model (LLM) evaluation to measure text-3D consistency. Both metrics closely correlate with different dimensions of human judgments, providing a paradigm for efficiently evaluating text-to-3D models. The benchmarking results, shown in Fig. 1, reveal performance differences among six prevalent text-to-3D methods. Our analysis further highlights the common struggles for current methods on generating surroundings and multi-object scenes, as well as the bottleneck of leveraging 2D guidance for 3D generation. Our project page is available at: https://t3bench.com.
Dual-Augmented Transformer Network for Weakly Supervised Semantic Segmentation
Sep 30, 2023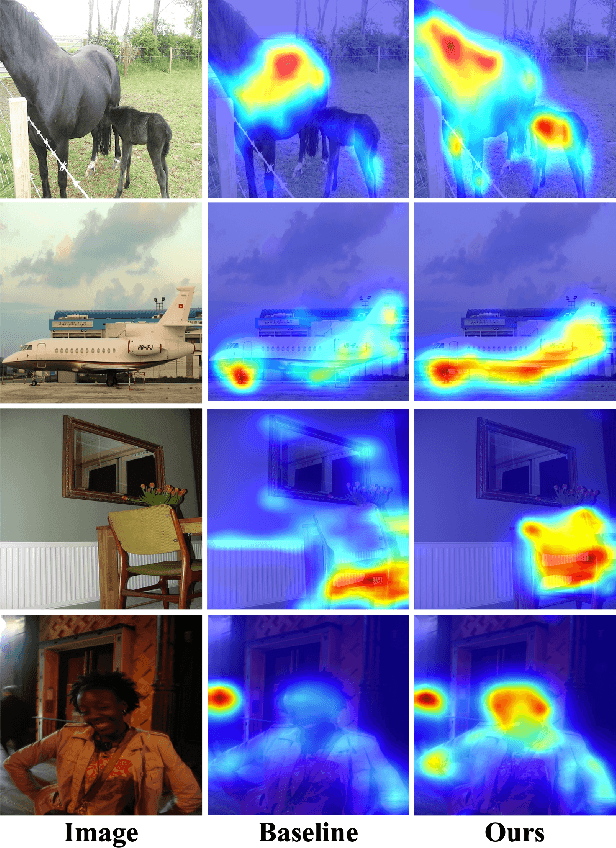
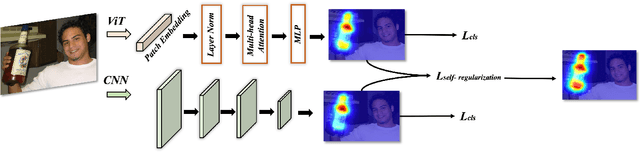

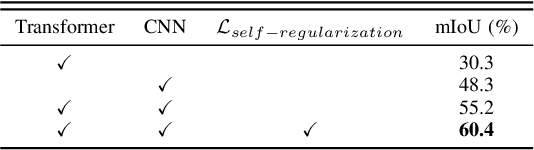
Weakly supervised semantic segmentation (WSSS), a fundamental computer vision task, which aims to segment out the object within only class-level labels. The traditional methods adopt the CNN-based network and utilize the class activation map (CAM) strategy to discover the object regions. However, such methods only focus on the most discriminative region of the object, resulting in incomplete segmentation. An alternative is to explore vision transformers (ViT) to encode the image to acquire the global semantic information. Yet, the lack of transductive bias to objects is a flaw of ViT. In this paper, we explore the dual-augmented transformer network with self-regularization constraints for WSSS. Specifically, we propose a dual network with both CNN-based and transformer networks for mutually complementary learning, where both networks augment the final output for enhancement. Massive systemic evaluations on the challenging PASCAL VOC 2012 benchmark demonstrate the effectiveness of our method, outperforming previous state-of-the-art methods.
Improving Medical Image Classification in Noisy Labels Using Only Self-supervised Pretraining
Aug 08, 2023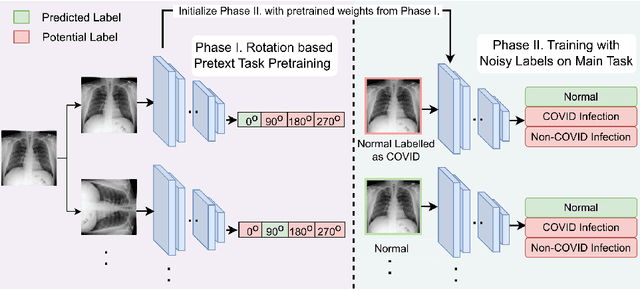
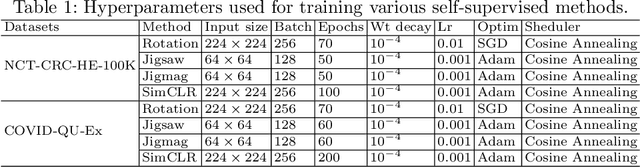
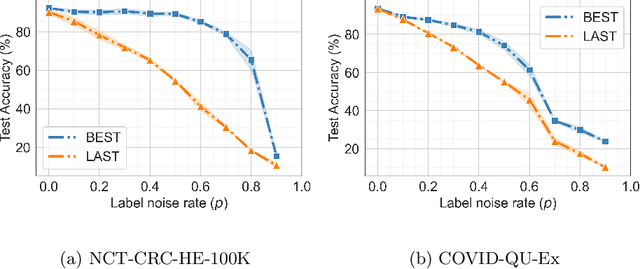
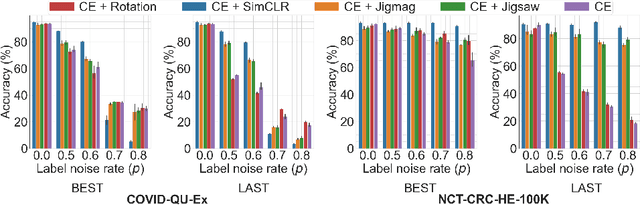
Noisy labels hurt deep learning-based supervised image classification performance as the models may overfit the noise and learn corrupted feature extractors. For natural image classification training with noisy labeled data, model initialization with contrastive self-supervised pretrained weights has shown to reduce feature corruption and improve classification performance. However, no works have explored: i) how other self-supervised approaches, such as pretext task-based pretraining, impact the learning with noisy label, and ii) any self-supervised pretraining methods alone for medical images in noisy label settings. Medical images often feature smaller datasets and subtle inter class variations, requiring human expertise to ensure correct classification. Thus, it is not clear if the methods improving learning with noisy labels in natural image datasets such as CIFAR would also help with medical images. In this work, we explore contrastive and pretext task-based self-supervised pretraining to initialize the weights of a deep learning classification model for two medical datasets with self-induced noisy labels -- NCT-CRC-HE-100K tissue histological images and COVID-QU-Ex chest X-ray images. Our results show that models initialized with pretrained weights obtained from self-supervised learning can effectively learn better features and improve robustness against noisy labels.
PromptPaint: Steering Text-to-Image Generation Through Paint Medium-like Interactions
Aug 09, 2023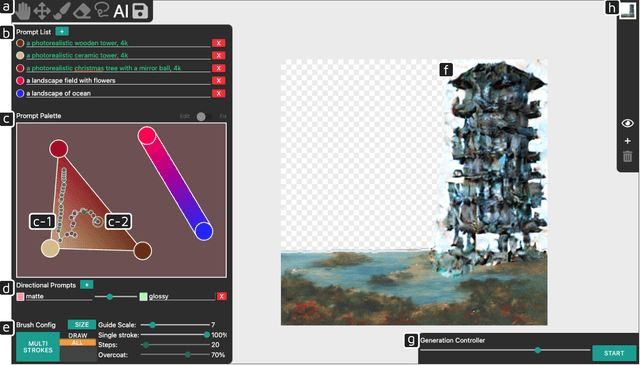

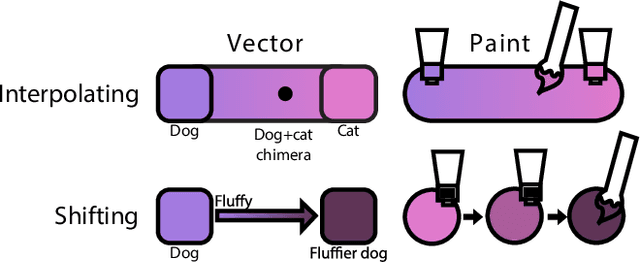

While diffusion-based text-to-image (T2I) models provide a simple and powerful way to generate images, guiding this generation remains a challenge. For concepts that are difficult to describe through language, users may struggle to create prompts. Moreover, many of these models are built as end-to-end systems, lacking support for iterative shaping of the image. In response, we introduce PromptPaint, which combines T2I generation with interactions that model how we use colored paints. PromptPaint allows users to go beyond language to mix prompts that express challenging concepts. Just as we iteratively tune colors through layered placements of paint on a physical canvas, PromptPaint similarly allows users to apply different prompts to different canvas areas and times of the generative process. Through a set of studies, we characterize different approaches for mixing prompts, design trade-offs, and socio-technical challenges for generative models. With PromptPaint we provide insight into future steerable generative tools.
YODA: You Only Diffuse Areas. An Area-Masked Diffusion Approach For Image Super-Resolution
Aug 15, 2023
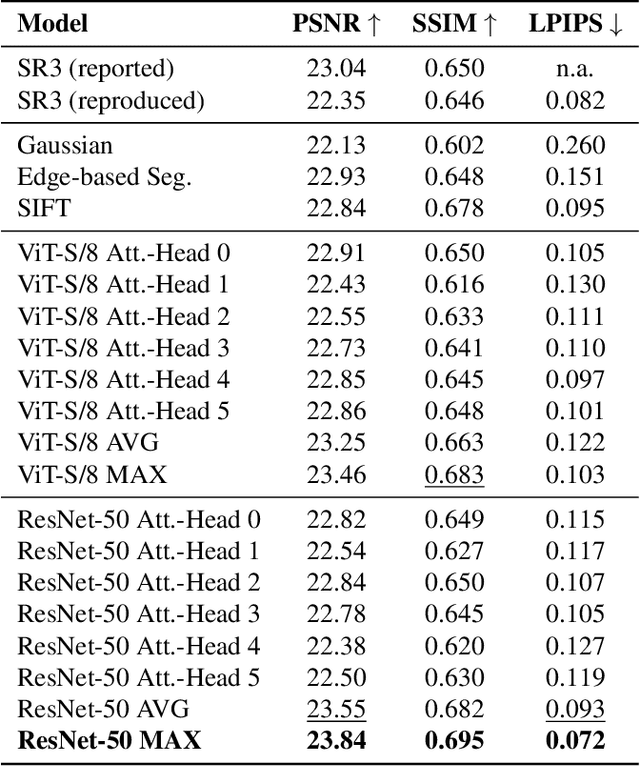
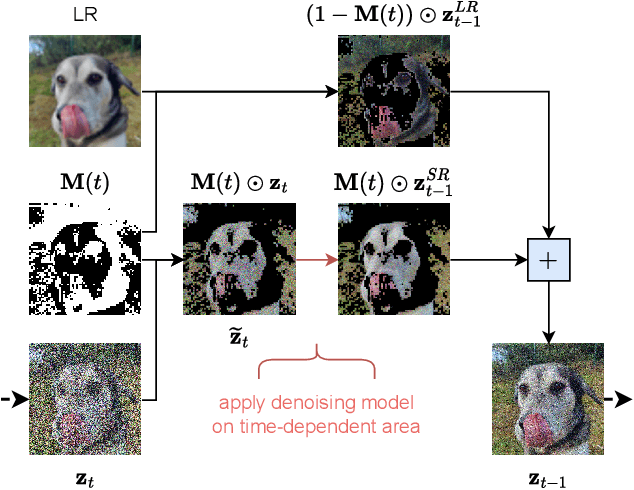
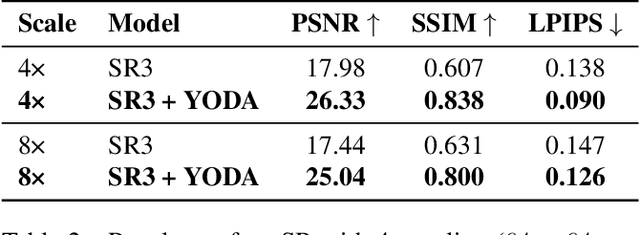
This work introduces "You Only Diffuse Areas" (YODA), a novel method for partial diffusion in Single-Image Super-Resolution (SISR). The core idea is to utilize diffusion selectively on spatial regions based on attention maps derived from the low-resolution image and the current time step in the diffusion process. This time-dependent targeting enables a more effective conversion to high-resolution outputs by focusing on areas that benefit the most from the iterative refinement process, i.e., detail-rich objects. We empirically validate YODA by extending leading diffusion-based SISR methods SR3 and SRDiff. Our experiments demonstrate new state-of-the-art performance gains in face and general SR across PSNR, SSIM, and LPIPS metrics. A notable finding is YODA's stabilization effect on training by reducing color shifts, especially when induced by small batch sizes, potentially contributing to resource-constrained scenarios. The proposed spatial and temporal adaptive diffusion mechanism opens promising research directions, including developing enhanced attention map extraction techniques and optimizing inference latency based on sparser diffusion.
Masked-Attention Diffusion Guidance for Spatially Controlling Text-to-Image Generation
Aug 11, 2023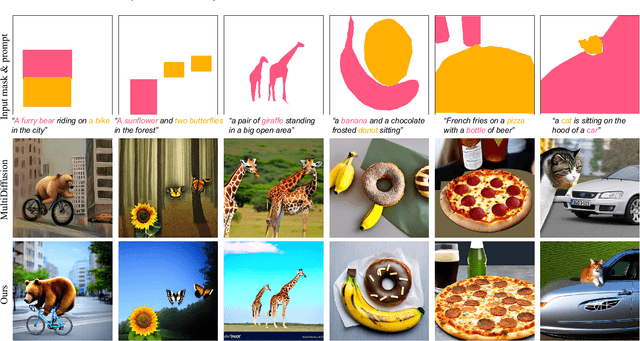

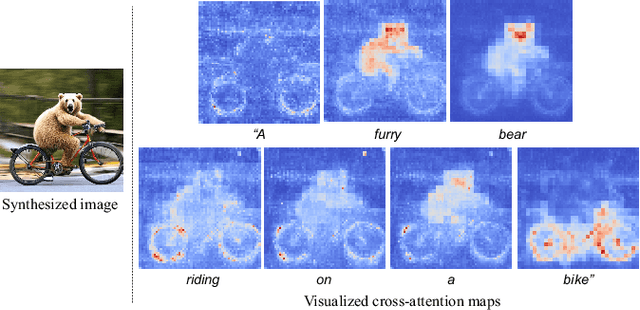
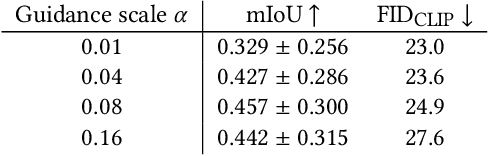
Text-to-image synthesis has achieved high-quality results with recent advances in diffusion models. However, text input alone has high spatial ambiguity and limited user controllability. Most existing methods allow spatial control through additional visual guidance (e.g, sketches and semantic masks) but require additional training with annotated images. In this paper, we propose a method for spatially controlling text-to-image generation without further training of diffusion models. Our method is based on the insight that the cross-attention maps reflect the positional relationship between words and pixels. Our aim is to control the attention maps according to given semantic masks and text prompts. To this end, we first explore a simple approach of directly swapping the cross-attention maps with constant maps computed from the semantic regions. Moreover, we propose masked-attention guidance, which can generate images more faithful to semantic masks than the first approach. Masked-attention guidance indirectly controls attention to each word and pixel according to the semantic regions by manipulating noise images fed to diffusion models. Experiments show that our method enables more accurate spatial control than baselines qualitatively and quantitatively.
MosaicFusion: Diffusion Models as Data Augmenters for Large Vocabulary Instance Segmentation
Sep 22, 2023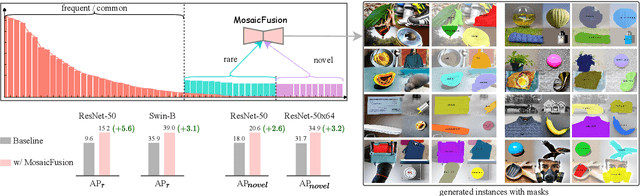

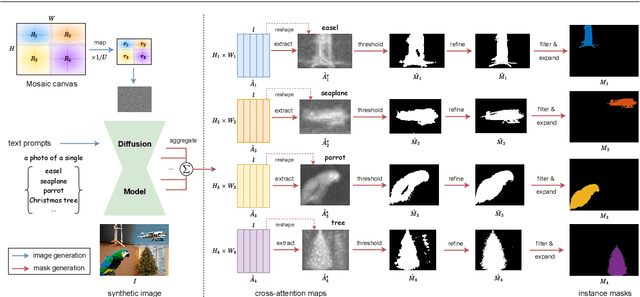

We present MosaicFusion, a simple yet effective diffusion-based data augmentation approach for large vocabulary instance segmentation. Our method is training-free and does not rely on any label supervision. Two key designs enable us to employ an off-the-shelf text-to-image diffusion model as a useful dataset generator for object instances and mask annotations. First, we divide an image canvas into several regions and perform a single round of diffusion process to generate multiple instances simultaneously, conditioning on different text prompts. Second, we obtain corresponding instance masks by aggregating cross-attention maps associated with object prompts across layers and diffusion time steps, followed by simple thresholding and edge-aware refinement processing. Without bells and whistles, our MosaicFusion can produce a significant amount of synthetic labeled data for both rare and novel categories. Experimental results on the challenging LVIS long-tailed and open-vocabulary benchmarks demonstrate that MosaicFusion can significantly improve the performance of existing instance segmentation models, especially for rare and novel categories. Code will be released at https://github.com/Jiahao000/MosaicFusion.
Zero-Shot Object Counting with Language-Vision Models
Sep 22, 2023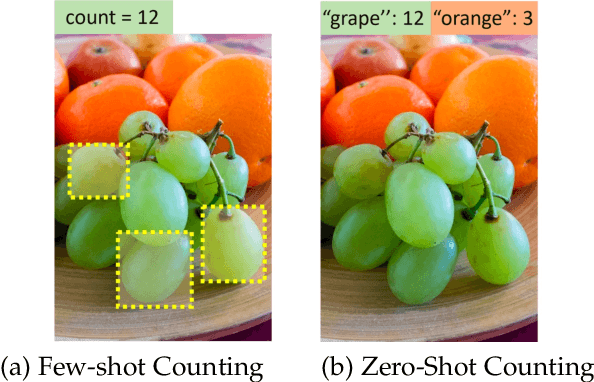
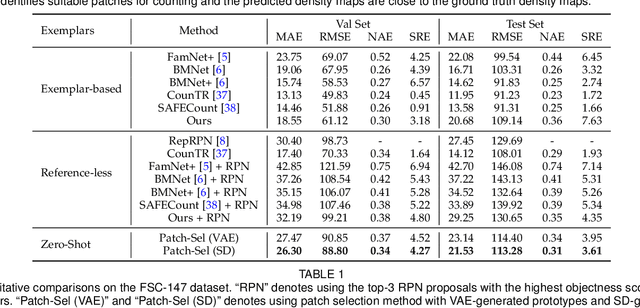
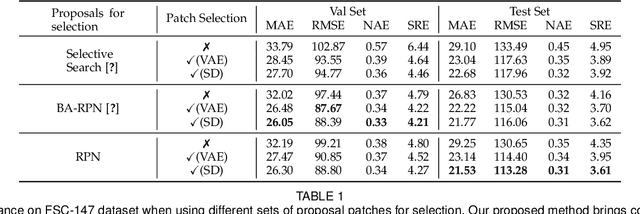

Class-agnostic object counting aims to count object instances of an arbitrary class at test time. It is challenging but also enables many potential applications. Current methods require human-annotated exemplars as inputs which are often unavailable for novel categories, especially for autonomous systems. Thus, we propose zero-shot object counting (ZSC), a new setting where only the class name is available during test time. This obviates the need for human annotators and enables automated operation. To perform ZSC, we propose finding a few object crops from the input image and use them as counting exemplars. The goal is to identify patches containing the objects of interest while also being visually representative for all instances in the image. To do this, we first construct class prototypes using large language-vision models, including CLIP and Stable Diffusion, to select the patches containing the target objects. Furthermore, we propose a ranking model that estimates the counting error of each patch to select the most suitable exemplars for counting. Experimental results on a recent class-agnostic counting dataset, FSC-147, validate the effectiveness of our method.
Uncertainty-Aware Multi-View Visual Semantic Embedding
Sep 15, 2023The key challenge in image-text retrieval is effectively leveraging semantic information to measure the similarity between vision and language data. However, using instance-level binary labels, where each image is paired with a single text, fails to capture multiple correspondences between different semantic units, leading to uncertainty in multi-modal semantic understanding. Although recent research has captured fine-grained information through more complex model structures or pre-training techniques, few studies have directly modeled uncertainty of correspondence to fully exploit binary labels. To address this issue, we propose an Uncertainty-Aware Multi-View Visual Semantic Embedding (UAMVSE)} framework that decomposes the overall image-text matching into multiple view-text matchings. Our framework introduce an uncertainty-aware loss function (UALoss) to compute the weighting of each view-text loss by adaptively modeling the uncertainty in each view-text correspondence. Different weightings guide the model to focus on different semantic information, enhancing the model's ability to comprehend the correspondence of images and texts. We also design an optimized image-text matching strategy by normalizing the similarity matrix to improve model performance. Experimental results on the Flicker30k and MS-COCO datasets demonstrate that UAMVSE outperforms state-of-the-art models.