 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld Action Models Enable Continual Imitation Learning with Recurrent Generative Replays
Jun 25, 2026Going beyond predicting robot actions, World Action Models (WAMs) can also generate future visual observations. We build on this generative capability to propose Recurrent Generative Replay (REGEN), a continual imitation learning framework that synthesizes pseudo-replay trajectories, enabling a robot policy to rehearse previously learned tasks without storing their original human demonstrations. During continual adaptation, REGEN recursively queries the WAM to synthesize pseudo-replay trajectories conditioned only on prior task instructions and current-task observations. Experiments in both simulation and real-world manipulation settings show that REGEN reduces catastrophic forgetting by up to $50\%$ relative to sequential fine-tuning, while approaching the performance of privileged experience replay methods that require access to real replay data. Finally, we analyze the factors limiting generated replay, identifying long-horizon visual degradation and action-observation inconsistency as the primary bottlenecks. Our results establish WAMs as a promising foundation for continual robot learning without stored demonstrations.
Counting Trees from Satellite Imagery with Noisy Supervision
Jun 25, 2026Counting individual trees is a fundamental task for environmental monitoring, yet remains largely unexplored with satellite imagery. At these resolutions, isolated trees may still be identifiable, but crown boundaries become ambiguous in dense forests, making the notion of an individual tree inherently ill-defined. Moreover, large-scale manual annotations of individual trees are prohibitively expensive. While scalable supervision can be derived from airborne LiDAR, the resulting annotations are noisy and difficult to exploit effectively. We address these challenges by formulating tree counting as a spatial density matching problem supervised through Unbalanced Optimal Transport. This formulation naturally accommodates both precise localization of isolate trees and robust density estimation in dense forests. We further introduce a self-correction mechanism that leverages transport residuals to progressively refine noisy supervision during training. We evaluate our approach on TinyTrees, a new benchmark spanning three continents and three satellite sensors, comprising over 216 million tree annotations (including 639k manually verified instances) across $25\,890$ km$^2$. Our method consistently outperforms detection-based, regression-based, and transport-based distribution-matching baselines, demonstrating the effectiveness of unbalanced transport and reliability-aware supervision for large-scale tree counting from satellite imagery. Code, data and models are available at https://github.com/dgominski/treematch.
UNIEGO: Proxies as Mediators for Unified Egocentric Video Representation Learning
Jun 18, 2026Egocentric video understanding is inherently limited by the narrow perspective of wearable cameras: a single viewpoint, a single modality, a single model cannot capture the full richness of human action. We argue that a truly expressive egocentric representation must subsume complementary knowledge across viewpoints, modalities, and foundation model representations, yet remain deployable from egocentric video alone. To this end, we introduce a hierarchical multi-teacher distillation framework that produces UNIEGO, a unified egocentric encoder trained with nine teachers spanning ego-exo viewpoints, RGB, depth, and skeleton modalities, and four foundation models. Rather than distilling directly from heterogeneous teachers whose incompatible architectures and feature geometries induce conflicting gradients, our framework interposes a layer of representation-specific Proxy models that translate diverse teacher knowledge into a homogeneous egocentric space. A second distillation stage, Selective Proxy Distillation (SPD), then adaptively selects, for each training sample, the subset of proxies that are both correct and confident, distilling exclusively from reliable supervision and suppressing erroneous signals. SPD is further stabilized by initializing UNIEGO as a learned convex combination of proxy parameters, placing the unified model in a well-conditioned region of the loss landscape before distillation begins. UNIEGO achieves state-of-the-art performance across three egocentric video understanding tasks - action recognition, video retrieval, and action segmentation on three challenging ego-exo benchmarks, outperforming naive multi-teacher distillation baselines and demonstrating that structured, proxy-mediated knowledge transfer yields richer and more discriminative egocentric representations.
TimeProVe: Propose, then Verify for Efficient Long Video Temporal Reasoning in Activities of Daily Living
Jun 18, 2026Long Video Question Answering (LVQA) requires identifying sparse, query-relevant evidence within hours-long untrimmed videos. Existing approaches either process videos densely with large vision-language models (VLMs), incurring prohibitive computational cost, or rely on sparse caption-based reasoning, which often misses temporally localized and motion-centric evidence. We introduce TimeProVe, a cost-efficient hybrid framework for temporally grounded reasoning in long videos. TimeProVe first employs lightweight modules to generate action-grounded answer--evidence hypotheses and subsequently invokes an expensive VLM only for targeted verification. The core of our framework lies in the Action-based Candidate Evidence (ACE) module, which converts temporally localized actions into query-conditioned candidate answers and supporting evidence windows through lightweight LLM reasoning. We further introduce OpenTSUBench (OTB), an open-ended benchmark designed to evaluate temporally grounded reasoning in real-world Activities of Daily Living (ADL) scenarios. Experiments show that TimeProVe outperforms the strongest baseline on OTB by 7.3%, while reducing VLM calls by 75% and inference cost by 93%. Furthermore, without explicit temporal grounding training, TimeProVe achieves competitive performance on Charades-STA, and reaches state-of-the-art results when enhanced with grounding VLMs.
Learning to Focus: CSI-Free Hierarchical MARL for Reconfigurable Reflectors
Apr 06, 2026Reconfigurable Intelligent Surfaces (RIS) has a potential to engineer smart radio environments for next-generation millimeter-wave (mmWave) networks. However, the prohibitive computational overhead of Channel State Information (CSI) estimation and the dimensionality explosion inherent in centralized optimization severely hinder practical large-scale deployments. To overcome these bottlenecks, we introduce a ``CSI-free" paradigm powered by a Hierarchical Multi-Agent Reinforcement Learning (HMARL) architecture to control mechanically reconfigurable reflective surfaces. By substituting pilot-based channel estimation with accessible user localization data, our framework leverages spatial intelligence for macro-scale wave propagation management. The control problem is decomposed into a two-tier neural architecture: a high-level controller executes temporally extended, discrete user-to-reflector allocations, while low-level controllers autonomously optimize continuous focal points utilizing Multi-Agent Proximal Policy Optimization (MAPPO) under a Centralized Training with Decentralized Execution (CTDE) scheme. Comprehensive deterministic ray-tracing evaluations demonstrate that this hierarchical framework achieves massive RSSI improvements of up to 7.79 dB over centralized baselines. Furthermore, the system exhibits robust multi-user scalability and maintains highly resilient beam-focusing performance under practical sub-meter localization tracking errors. By eliminating CSI overhead while maintaining high-fidelity signal redirection, this work establishes a scalable and cost-effective blueprint for intelligent wireless environments.
Bypassing the CSI Bottleneck: MARL-Driven Spatial Control for Reflector Arrays
Apr 06, 2026Reconfigurable Intelligent Surfaces (RIS) are pivotal for next-generation smart radio environments, yet their practical deployment is severely bottlenecked by the intractable computational overhead of Channel State Information (CSI) estimation. To bypass this fundamental physical-layer barrier, we propose an AI-native, data-driven paradigm that replaces complex channel modeling with spatial intelligence. This paper presents a fully autonomous Multi-Agent Reinforcement Learning (MARL) framework to control mechanically adjustable metallic reflector arrays. By mapping high-dimensional mechanical constraints to a reduced-order virtual focal point space, we deploy a Centralized Training with Decentralized Execution (CTDE) architecture. Using Multi-Agent Proximal Policy Optimization (MAPPO), our decentralized agents learn cooperative beam-focusing strategies relying on user coordinates, achieving CSI-free operation. High-fidelity ray-tracing simulations in dynamic non-line-of-sight (NLOS) environments demonstrate that this multi-agent approach rapidly adapts to user mobility, yielding up to a 26.86 dB enhancement over static flat reflectors and outperforming single-agent and hardware-constrained DRL baselines in both spatial selectivity and temporal stability. Crucially, the learned policies exhibit good deployment resilience, sustaining stable signal coverage even under 1.0-meter localization noise. These results validate the efficacy of MARL-driven spatial abstractions as a scalable, highly practical pathway toward AI-empowered wireless networks.
Automated Counting of Stacked Objects in Industrial Inspection
Mar 16, 2026Visual object counting is a fundamental computer vision task in industrial inspection, where accurate, high-throughput inventory tracking and quality assurance are critical. Moreover, manufactured parts are often too light to reliably deduce their count from their weight, or too heavy to move the stack on a scale safely and practically, making automated visual counting the more robust solution in many scenarios. However, existing methods struggle with stacked 3D items in containers, pallets, or bins, where most objects are heavily occluded and only a few are directly visible. To address this important yet underexplored challenge, we propose a novel 3D counting approach that decomposes the task into two complementary subproblems: estimating the 3D geometry of the stack and its occupancy ratio from multi-view images. By combining geometric reconstruction with deep learning-based depth analysis, our method can accurately count identical manufactured parts inside containers, even when they are irregularly stacked and partially hidden. We validate our 3D counting pipeline on large-scale synthetic and diverse real-world data with manually verified total counts, demonstrating robust performance under realistic inspection conditions.
LoRIF: Low-Rank Influence Functions for Scalable Training Data Attribution
Jan 29, 2026Training data attribution (TDA) identifies which training examples most influenced a model's prediction. The best-performing TDA methods exploits gradients to define an influence function. To overcome the scalability challenge arising from gradient computation, the most popular strategy is random projection (e.g., TRAK, LoGRA). However, this still faces two bottlenecks when scaling to large training sets and high-quality attribution: \emph{(i)} storing and loading projected per-example gradients for all $N$ training examples, where query latency is dominated by I/O; and \emph{(ii)} forming the $D \times D$ inverse Hessian approximation, which costs $O(D^2)$ memory. Both bottlenecks scale with the projection dimension $D$, yet increasing $D$ is necessary for attribution quality -- creating a quality-scalability tradeoff. We introduce \textbf{LoRIF (Low-Rank Influence Functions)}, which exploits low-rank structures of gradient to address both bottlenecks. First, we store rank-$c$ factors of the projected per-example gradients rather than full matrices, reducing storage and query-time I/O from $O(D)$ to $O(c\sqrt{D})$ per layer per sample. Second, we use truncated SVD with the Woodbury identity to approximate the Hessian term in an $r$-dimensional subspace, reducing memory from $O(D^2)$ to $O(Dr)$. On models from 0.1B to 70B parameters trained on datasets with millions of examples, LoRIF achieves up to 20$\times$ storage reduction and query-time speedup compared to LoGRA, while matching or exceeding its attribution quality. LoRIF makes gradient-based TDA practical at frontier scale.
Learning to Weight Parameters for Data Attribution
Jun 06, 2025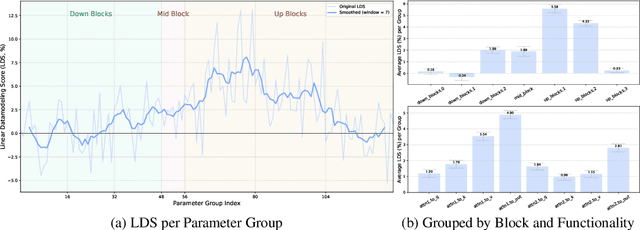

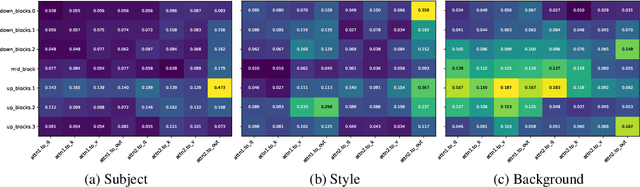
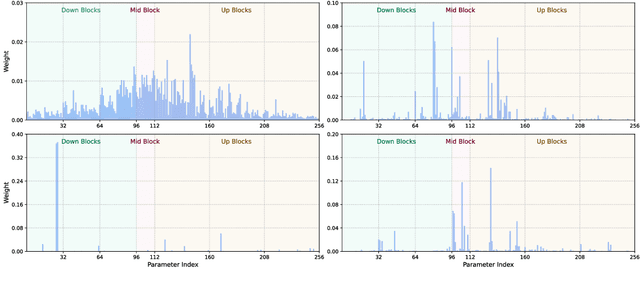
We study data attribution in generative models, aiming to identify which training examples most influence a given output. Existing methods achieve this by tracing gradients back to training data. However, they typically treat all network parameters uniformly, ignoring the fact that different layers encode different types of information and may thus draw information differently from the training set. We propose a method that models this by learning parameter importance weights tailored for attribution, without requiring labeled data. This allows the attribution process to adapt to the structure of the model, capturing which training examples contribute to specific semantic aspects of an output, such as subject, style, or background. Our method improves attribution accuracy across diffusion models and enables fine-grained insights into how outputs borrow from training data.
Improving Contrastive Learning for Referring Expression Counting
May 28, 2025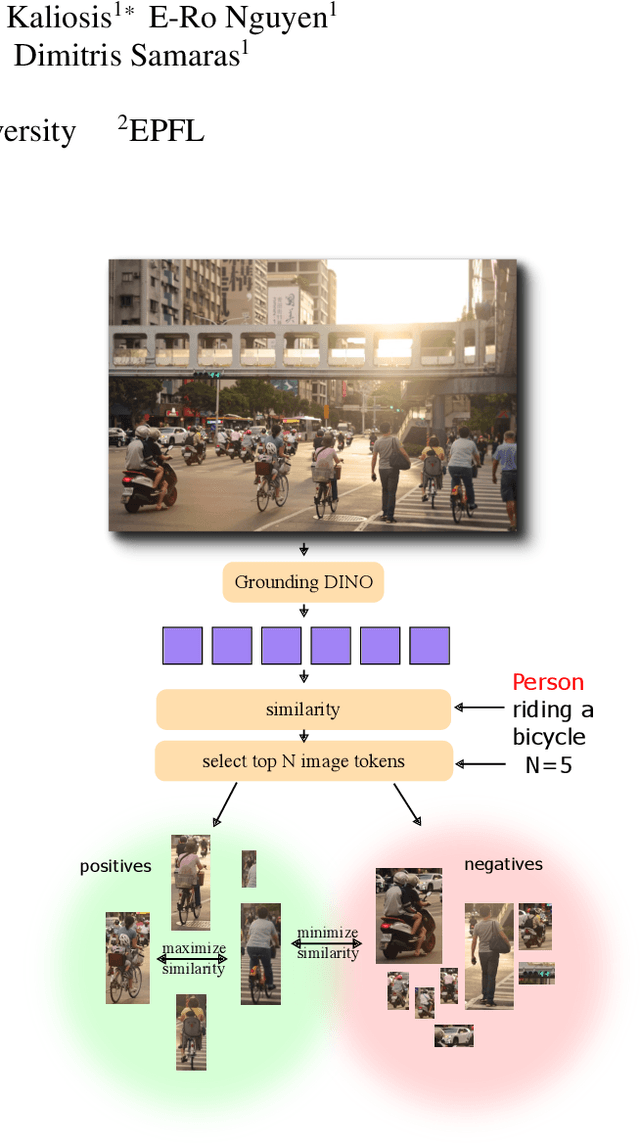
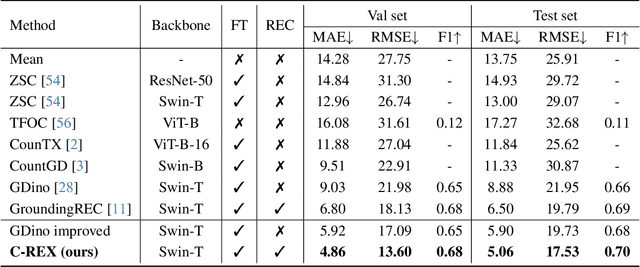

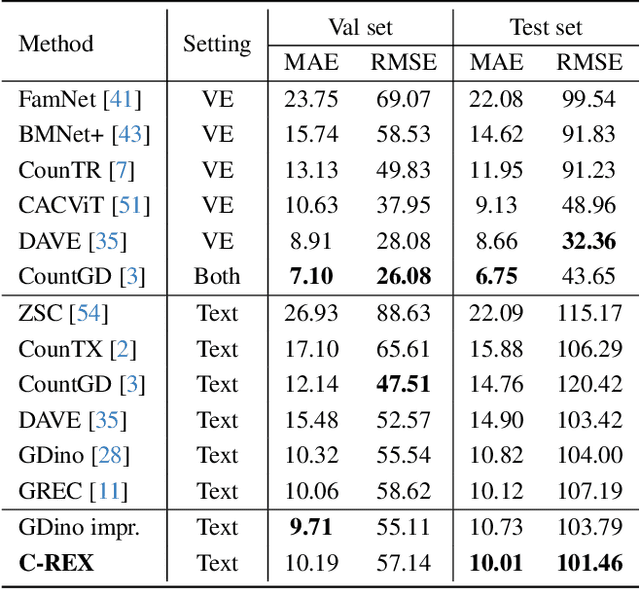
Object counting has progressed from class-specific models, which count only known categories, to class-agnostic models that generalize to unseen categories. The next challenge is Referring Expression Counting (REC), where the goal is to count objects based on fine-grained attributes and contextual differences. Existing methods struggle with distinguishing visually similar objects that belong to the same category but correspond to different referring expressions. To address this, we propose C-REX, a novel contrastive learning framework, based on supervised contrastive learning, designed to enhance discriminative representation learning. Unlike prior works, C-REX operates entirely within the image space, avoiding the misalignment issues of image-text contrastive learning, thus providing a more stable contrastive signal. It also guarantees a significantly larger pool of negative samples, leading to improved robustness in the learned representations. Moreover, we showcase that our framework is versatile and generic enough to be applied to other similar tasks like class-agnostic counting. To support our approach, we analyze the key components of sota detection-based models and identify that detecting object centroids instead of bounding boxes is the key common factor behind their success in counting tasks. We use this insight to design a simple yet effective detection-based baseline to build upon. Our experiments show that C-REX achieves state-of-the-art results in REC, outperforming previous methods by more than 22\% in MAE and more than 10\% in RMSE, while also demonstrating strong performance in class-agnostic counting. Code is available at https://github.com/cvlab-stonybrook/c-rex.