 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Instruction Composition for Automated LLM Red-Teaming
Apr 22, 2026Many approaches to LLM red-teaming leverage an attacker LLM to discover jailbreaks against a target. Several of them task the attacker with identifying effective strategies through trial and error, resulting in a semantically limited range of successes. Another approach discovers diverse attacks by combining crowdsourced harmful queries and tactics into instructions for the attacker, but does so at random, limiting effectiveness. This article introduces a novel framework, Adaptive Instruction Composition, that combines crowdsourced texts according to an adaptive mechanism trained to jointly optimize effectiveness with diversity. We use reinforcement learning to balance exploration with exploitation in a combinatorial space of instructions to guide the attacker toward diverse generations tailored to target vulnerabilities. We demonstrate that our approach substantially outperforms random combination on a set of effectiveness and diversity metrics, even under model transfer. Further, we show that it surpasses a host of recent adaptive approaches on Harmbench. We employ a lightweight neural contextual bandit that adapts to contrastive embedding inputs, and provide ablations suggesting that the contrastive pretraining enables the network to rapidly generalize and scale to the massive space as it learns.
Building Safe GenAI Applications: An End-to-End Overview of Red Teaming for Large Language Models
Mar 05, 2025

The rapid growth of Large Language Models (LLMs) presents significant privacy, security, and ethical concerns. While much research has proposed methods for defending LLM systems against misuse by malicious actors, researchers have recently complemented these efforts with an offensive approach that involves red teaming, i.e., proactively attacking LLMs with the purpose of identifying their vulnerabilities. This paper provides a concise and practical overview of the LLM red teaming literature, structured so as to describe a multi-component system end-to-end. To motivate red teaming we survey the initial safety needs of some high-profile LLMs, and then dive into the different components of a red teaming system as well as software packages for implementing them. We cover various attack methods, strategies for attack-success evaluation, metrics for assessing experiment outcomes, as well as a host of other considerations. Our survey will be useful for any reader who wants to rapidly obtain a grasp of the major red teaming concepts for their own use in practical applications.
Northeastern Uni at Multilingual Counterspeech Generation: Enhancing Counter Speech Generation with LLM Alignment through Direct Preference Optimization
Dec 19, 2024



The automatic generation of counter-speech (CS) is a critical strategy for addressing hate speech by providing constructive and informed responses. However, existing methods often fail to generate high-quality, impactful, and scalable CS, particularly across diverse linguistic contexts. In this paper, we propose a novel methodology to enhance CS generation by aligning Large Language Models (LLMs) using Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO). Our approach leverages DPO to align LLM outputs with human preferences, ensuring contextually appropriate and linguistically adaptable responses. Additionally, we incorporate knowledge grounding to enhance the factual accuracy and relevance of generated CS. Experimental results demonstrate that DPO-aligned models significantly outperform SFT baselines on CS benchmarks while scaling effectively to multiple languages. These findings highlight the potential of preference-based alignment techniques to advance CS generation across varied linguistic settings. The model supervision and alignment is done in English and the same model is used for reporting metrics across other languages like Basque, Italian, and Spanish.
* 10 pages, 6 tables, 1 figure, The First Workshop on Multilingual Counterspeech Generation (MCG) at The 31st International Conference on Computational Linguistics (COLING 2025)
FashionNTM: Multi-turn Fashion Image Retrieval via Cascaded Memory
Aug 20, 2023



Multi-turn textual feedback-based fashion image retrieval focuses on a real-world setting, where users can iteratively provide information to refine retrieval results until they find an item that fits all their requirements. In this work, we present a novel memory-based method, called FashionNTM, for such a multi-turn system. Our framework incorporates a new Cascaded Memory Neural Turing Machine (CM-NTM) approach for implicit state management, thereby learning to integrate information across all past turns to retrieve new images, for a given turn. Unlike vanilla Neural Turing Machine (NTM), our CM-NTM operates on multiple inputs, which interact with their respective memories via individual read and write heads, to learn complex relationships. Extensive evaluation results show that our proposed method outperforms the previous state-of-the-art algorithm by 50.5%, on Multi-turn FashionIQ -- the only existing multi-turn fashion dataset currently, in addition to having a relative improvement of 12.6% on Multi-turn Shoes -- an extension of the single-turn Shoes dataset that we created in this work. Further analysis of the model in a real-world interactive setting demonstrates two important capabilities of our model -- memory retention across turns, and agnosticity to turn order for non-contradictory feedback. Finally, user study results show that images retrieved by FashionNTM were favored by 83.1% over other multi-turn models. Project page: https://sites.google.com/eng.ucsd.edu/fashionntm
YELM: End-to-End Contextualized Entity Linking
Nov 10, 2019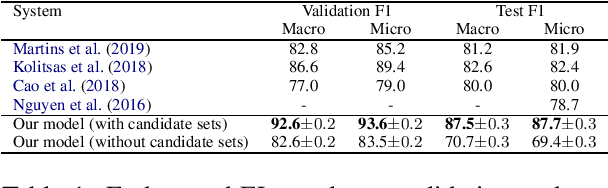
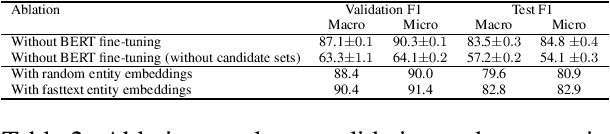
We propose yet another entity linking model (YELM) which links words to entities instead of spans. This overcomes any difficulties associated with the selection of good candidate mention spans and makes the joint training of mention detection (MD) and entity disambiguation (ED) easily possible. Our model is based on BERT and produces contextualized word embeddings which are trained against a joint MD and ED objective. We achieve state-of-the-art results on several standard entity linking (EL) datasets.
Evaluating the Readability of Force Directed Graph Layouts: A Deep Learning Approach
Aug 02, 2018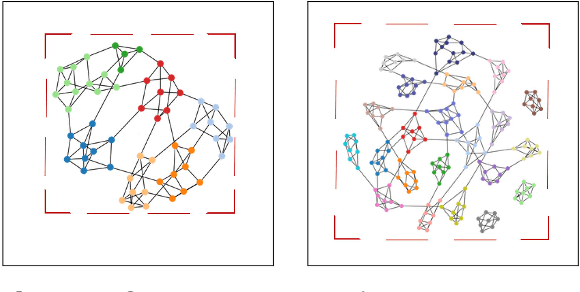

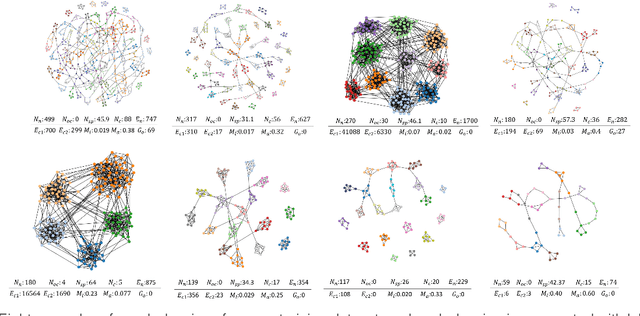

Existing graph layout algorithms are usually not able to optimize all the aesthetic properties desired in a graph layout. To evaluate how well the desired visual features are reflected in a graph layout, many readability metrics have been proposed in the past decades. However, the calculation of these readability metrics often requires access to the node and edge coordinates and is usually computationally inefficient, especially for dense graphs. Importantly, when the node and edge coordinates are not accessible, it becomes impossible to evaluate the graph layouts quantitatively. In this paper, we present a novel deep learning-based approach to evaluate the readability of graph layouts by directly using graph images. A convolutional neural network architecture is proposed and trained on a benchmark dataset of graph images, which is composed of synthetically-generated graphs and graphs created by sampling from real large networks. Multiple representative readability metrics (including edge crossing, node spread, and group overlap) are considered in the proposed approach. We quantitatively compare our approach to traditional methods and qualitatively evaluate our approach using a case study and visualizing convolutional layers. This work is a first step towards using deep learning based methods to evaluate images from the visualization field quantitatively.