 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Visual Instruction Inversion: Image Editing via Visual Prompting
Jul 26, 2023
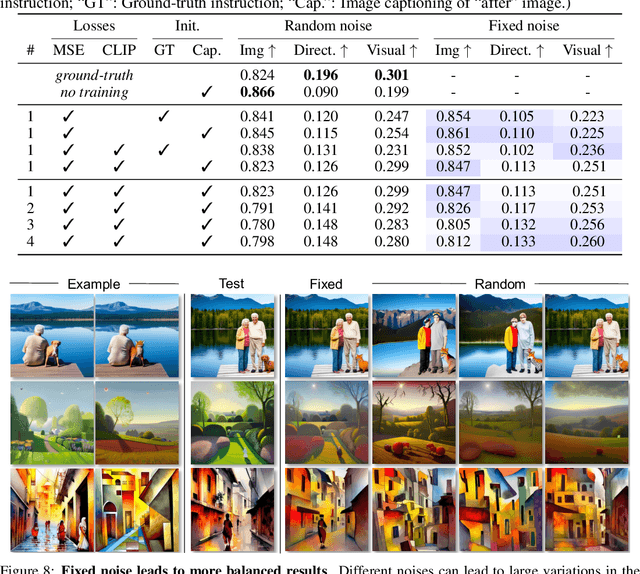
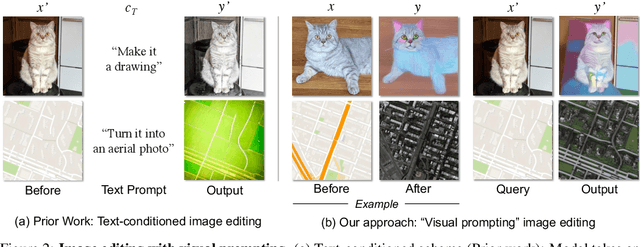
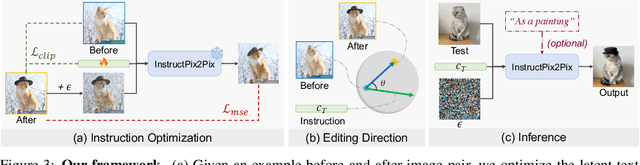

Text-conditioned image editing has emerged as a powerful tool for editing images. However, in many situations, language can be ambiguous and ineffective in describing specific image edits. When faced with such challenges, visual prompts can be a more informative and intuitive way to convey ideas. We present a method for image editing via visual prompting. Given pairs of example that represent the "before" and "after" images of an edit, our goal is to learn a text-based editing direction that can be used to perform the same edit on new images. We leverage the rich, pretrained editing capabilities of text-to-image diffusion models by inverting visual prompts into editing instructions. Our results show that with just one example pair, we can achieve competitive results compared to state-of-the-art text-conditioned image editing frameworks.
LayoutLLM-T2I: Eliciting Layout Guidance from LLM for Text-to-Image Generation
Aug 09, 2023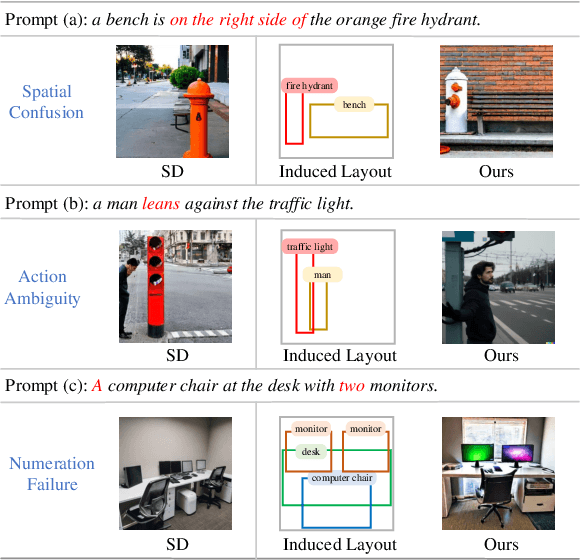
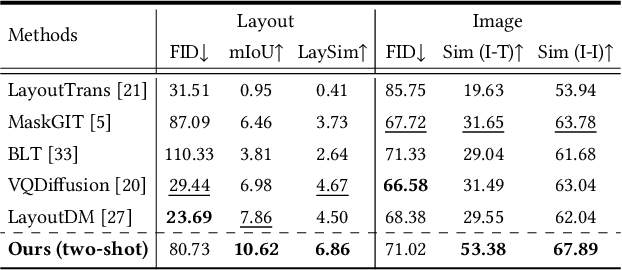
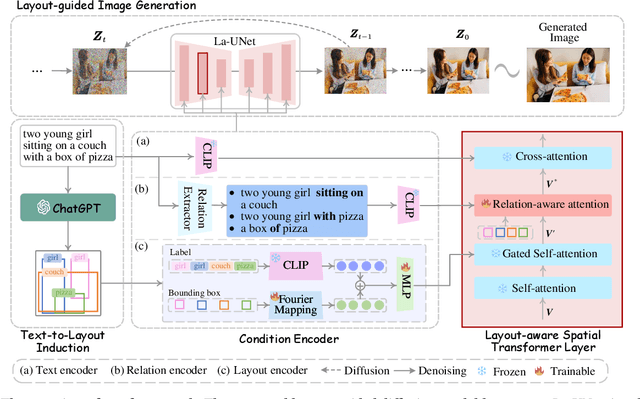

In the text-to-image generation field, recent remarkable progress in Stable Diffusion makes it possible to generate rich kinds of novel photorealistic images. However, current models still face misalignment issues (e.g., problematic spatial relation understanding and numeration failure) in complex natural scenes, which impedes the high-faithfulness text-to-image generation. Although recent efforts have been made to improve controllability by giving fine-grained guidance (e.g., sketch and scribbles), this issue has not been fundamentally tackled since users have to provide such guidance information manually. In this work, we strive to synthesize high-fidelity images that are semantically aligned with a given textual prompt without any guidance. Toward this end, we propose a coarse-to-fine paradigm to achieve layout planning and image generation. Concretely, we first generate the coarse-grained layout conditioned on a given textual prompt via in-context learning based on Large Language Models. Afterward, we propose a fine-grained object-interaction diffusion method to synthesize high-faithfulness images conditioned on the prompt and the automatically generated layout. Extensive experiments demonstrate that our proposed method outperforms the state-of-the-art models in terms of layout and image generation. Our code and settings are available at \url{https://layoutllm-t2i.github.io}.
Depolarized Holography with Polarization-multiplexing Metasurface
Sep 26, 2023The evolution of computer-generated holography (CGH) algorithms has prompted significant improvements in the performances of holographic displays. Nonetheless, they start to encounter a limited degree of freedom in CGH optimization and physical constraints stemming from the coherent nature of holograms. To surpass the physical limitations, we consider polarization as a new degree of freedom by utilizing a novel optical platform called metasurface. Polarization-multiplexing metasurfaces enable incoherent-like behavior in holographic displays due to the mutual incoherence of orthogonal polarization states. We leverage this unique characteristic of a metasurface by integrating it into a holographic display and exploiting polarization diversity to bring an additional degree of freedom for CGH algorithms. To minimize the speckle noise while maximizing the image quality, we devise a fully differentiable optimization pipeline by taking into account the metasurface proxy model, thereby jointly optimizing spatial light modulator phase patterns and geometric parameters of metasurface nanostructures. We evaluate the metasurface-enabled depolarized holography through simulations and experiments, demonstrating its ability to reduce speckle noise and enhance image quality.
PEACE: Prompt Engineering Automation for CLIPSeg Enhancement in Aerial Robotics
Sep 29, 2023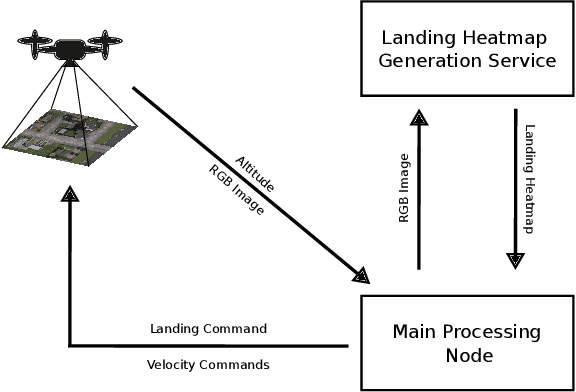
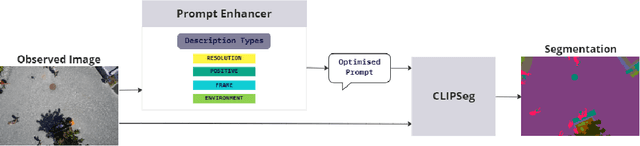
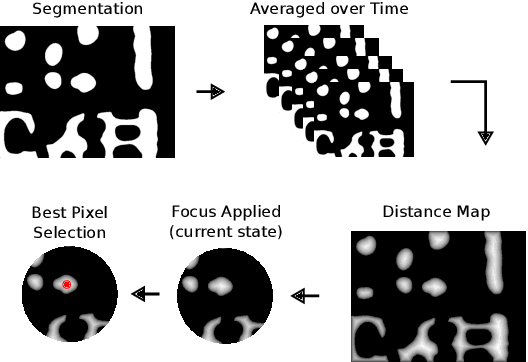
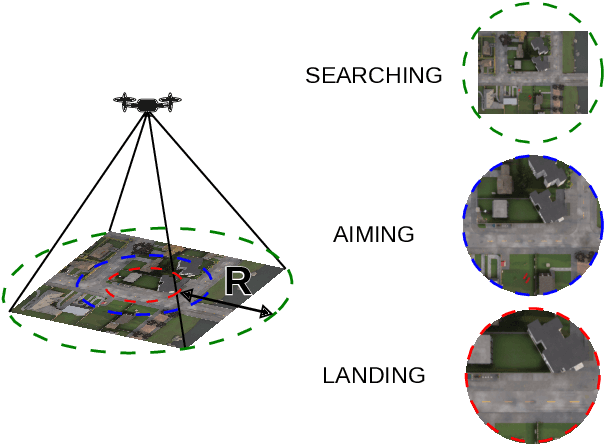
From industrial to space robotics, safe landing is an essential component for flight operations. With the growing interest in artificial intelligence, we direct our attention to learning based safe landing approaches. This paper extends our previous work, DOVESEI, which focused on a reactive UAV system by harnessing the capabilities of open vocabulary image segmentation. Prompt-based safe landing zone segmentation using an open vocabulary based model is no more just an idea, but proven to be feasible by the work of DOVESEI. However, a heuristic selection of words for prompt is not a reliable solution since it cannot take the changing environment into consideration and detrimental consequences can occur if the observed environment is not well represented by the given prompt. Therefore, we introduce PEACE (Prompt Engineering Automation for CLIPSeg Enhancement), powering DOVESEI to automate the prompt generation and engineering to adapt to data distribution shifts. Our system is capable of performing safe landing operations with collision avoidance at altitudes as low as 20 meters using only monocular cameras and image segmentation. We take advantage of DOVESEI's dynamic focus to circumvent abrupt fluctuations in the terrain segmentation between frames in a video stream. PEACE shows promising improvements in prompt generation and engineering for aerial images compared to the standard prompt used for CLIP and CLIPSeg. Combining DOVESEI and PEACE, our system was able improve successful safe landing zone selections by 58.62% compared to using only DOVESEI. All the source code is open source and available online.
Efficient Object Rearrangement via Multi-view Fusion
Sep 16, 2023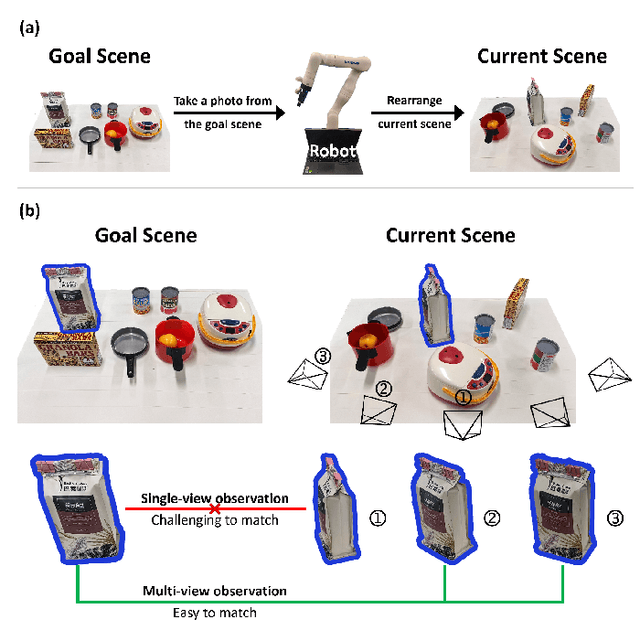
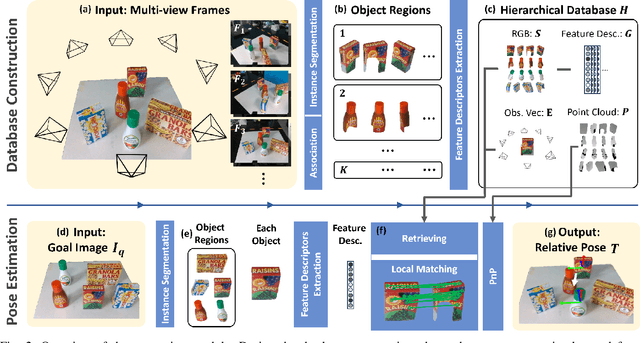
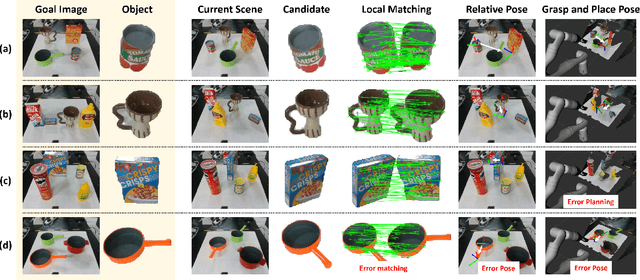
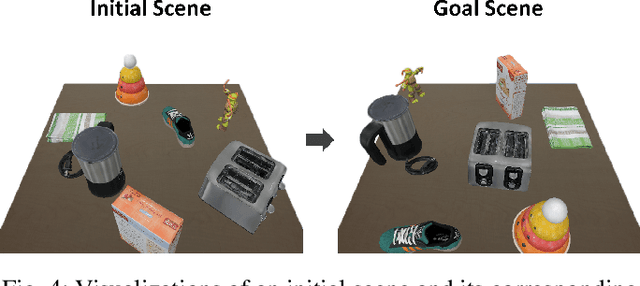
The prospect of assistive robots aiding in object organization has always been compelling. In an image-goal setting, the robot rearranges the current scene to match the single image captured from the goal scene. The key to an image-goal rearrangement system is estimating the desired placement pose of each object based on the single goal image and observations from the current scene. In order to establish sufficient associations for accurate estimation, the system should observe an object from a viewpoint similar to that in the goal image. Existing image-goal rearrangement systems, due to their reliance on a fixed viewpoint for perception, often require redundant manipulations to randomly adjust an object's pose for a better perspective. Addressing this inefficiency, we introduce a novel object rearrangement system that employs multi-view fusion. By observing the current scene from multiple viewpoints before manipulating objects, our approach can estimate a more accurate pose without redundant manipulation times. A standard visual localization pipeline at the object level is developed to capitalize on the advantages of multi-view observations. Simulation results demonstrate that the efficiency of our system outperforms existing single-view systems. The effectiveness of our system is further validated in a physical experiment.
CCSPNet-Joint: Efficient Joint Training Method for Traffic Sign Detection Under Extreme Conditions
Sep 25, 2023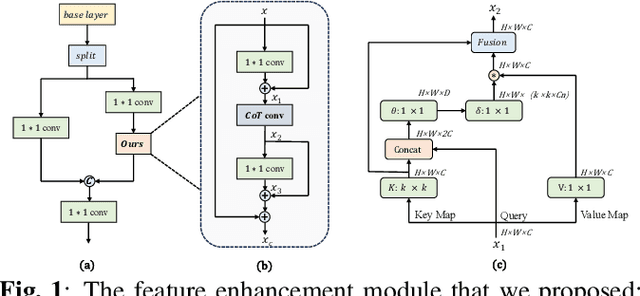
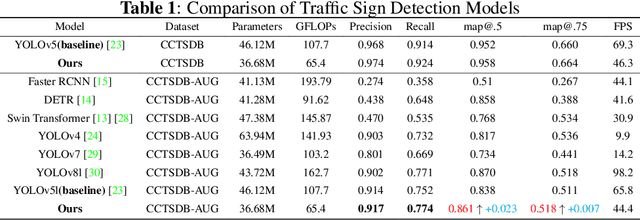
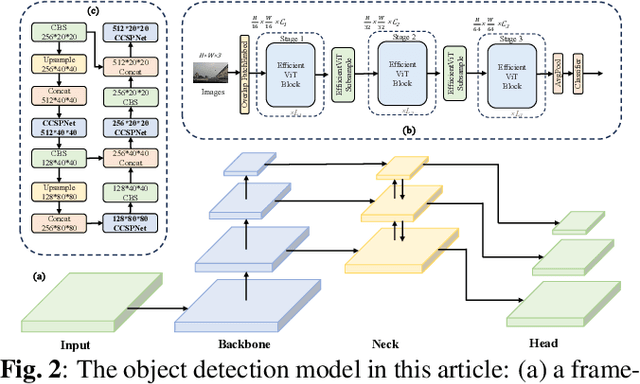
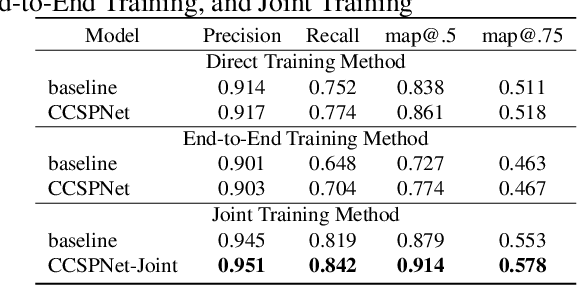
Traffic sign detection is an important research direction in intelligent driving. Unfortunately, existing methods often overlook extreme conditions such as fog, rain, and motion blur. Moreover, the end-to-end training strategy for image denoising and object detection models fails to utilize inter-model information effectively. To address these issues, we propose CCSPNet, an efficient feature extraction module based on Transformers and CNNs, which effectively leverages contextual information, achieves faster inference speed and provides stronger feature enhancement capabilities. Furthermore, we establish the correlation between object detection and image denoising tasks and propose a joint training model, CCSPNet-Joint, to improve data efficiency and generalization. Finally, to validate our approach, we create the CCTSDB-AUG dataset for traffic sign detection in extreme scenarios. Extensive experiments have shown that CCSPNet achieves state-of-the-art performance in traffic sign detection under extreme conditions. Compared to end-to-end methods, CCSPNet-Joint achieves a 5.32% improvement in precision and an 18.09% improvement in mAP@.5.
Tuning Multi-mode Token-level Prompt Alignment across Modalities
Sep 25, 2023
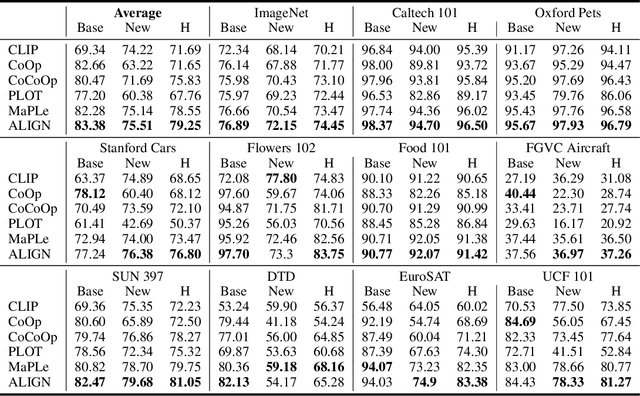
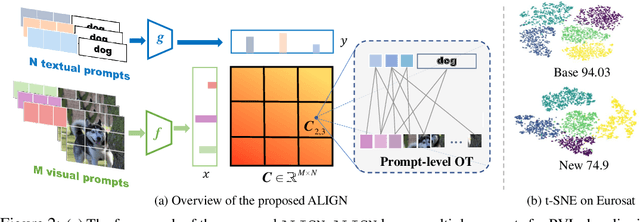
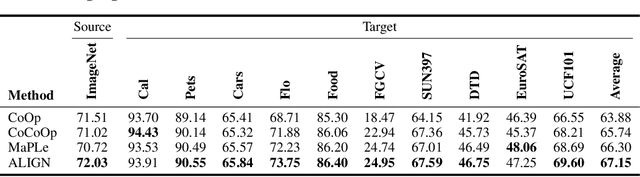
Prompt tuning pre-trained vision-language models have demonstrated significant potential in improving open-world visual concept understanding. However, prior works only primarily focus on single-mode (only one prompt for each modality) and holistic level (image or sentence) semantic alignment, which fails to capture the sample diversity, leading to sub-optimal prompt discovery. To address the limitation, we propose a multi-mode token-level tuning framework that leverages the optimal transportation to learn and align a set of prompt tokens across modalities. Specifically, we rely on two essential factors: 1) multi-mode prompts discovery, which guarantees diverse semantic representations, and 2) token-level alignment, which helps explore fine-grained similarity. Thus, the similarity can be calculated as a hierarchical transportation problem between the modality-specific sets. Extensive experiments on popular image recognition benchmarks show the superior generalization and few-shot abilities of our approach. The qualitative analysis demonstrates that the learned prompt tokens have the ability to capture diverse visual concepts.
Automatic Animation of Hair Blowing in Still Portrait Photos
Sep 25, 2023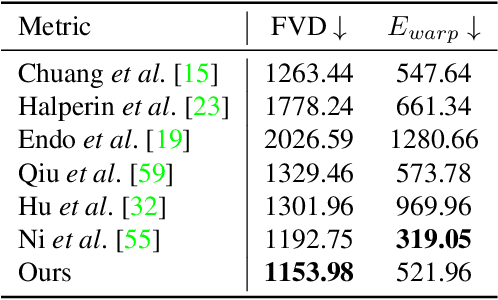
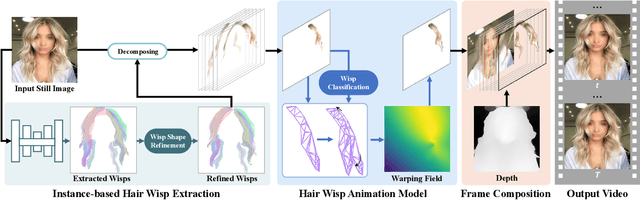

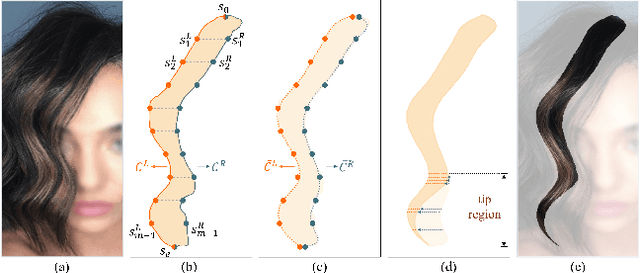
We propose a novel approach to animate human hair in a still portrait photo. Existing work has largely studied the animation of fluid elements such as water and fire. However, hair animation for a real image remains underexplored, which is a challenging problem, due to the high complexity of hair structure and dynamics. Considering the complexity of hair structure, we innovatively treat hair wisp extraction as an instance segmentation problem, where a hair wisp is referred to as an instance. With advanced instance segmentation networks, our method extracts meaningful and natural hair wisps. Furthermore, we propose a wisp-aware animation module that animates hair wisps with pleasing motions without noticeable artifacts. The extensive experiments show the superiority of our method. Our method provides the most pleasing and compelling viewing experience in the qualitative experiments and outperforms state-of-the-art still-image animation methods by a large margin in the quantitative evaluation. Project url: \url{https://nevergiveu.github.io/AutomaticHairBlowing/}
Retinex-guided Channel-grouping based Patch Swap for Arbitrary Style Transfer
Sep 19, 2023The basic principle of the patch-matching based style transfer is to substitute the patches of the content image feature maps by the closest patches from the style image feature maps. Since the finite features harvested from one single aesthetic style image are inadequate to represent the rich textures of the content natural image, existing techniques treat the full-channel style feature patches as simple signal tensors and create new style feature patches via signal-level fusion, which ignore the implicit diversities existed in style features and thus fail for generating better stylised results. In this paper, we propose a Retinex theory guided, channel-grouping based patch swap technique to solve the above challenges. Channel-grouping strategy groups the style feature maps into surface and texture channels, which prevents the winner-takes-all problem. Retinex theory based decomposition controls a more stable channel code rate generation. In addition, we provide complementary fusion and multi-scale generation strategy to prevent unexpected black area and over-stylised results respectively. Experimental results demonstrate that the proposed method outperforms the existing techniques in providing more style-consistent textures while keeping the content fidelity.
Painterly Image Harmonization using Diffusion Model
Aug 04, 2023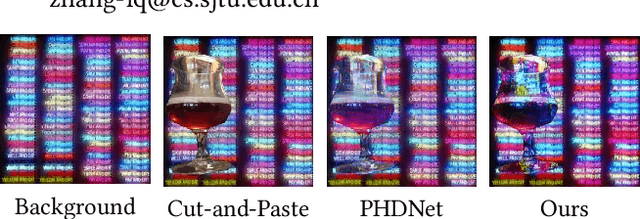

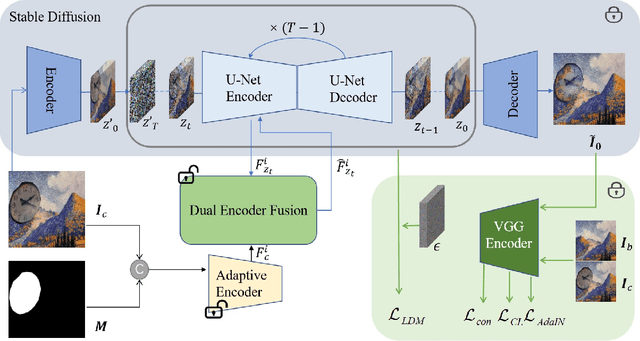
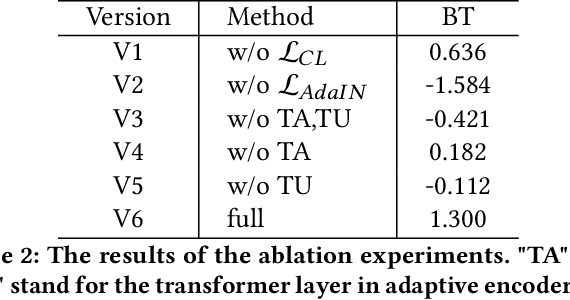
Painterly image harmonization aims to insert photographic objects into paintings and obtain artistically coherent composite images. Previous methods for this task mainly rely on inference optimization or generative adversarial network, but they are either very time-consuming or struggling at fine control of the foreground objects (e.g., texture and content details). To address these issues, we propose a novel Painterly Harmonization stable Diffusion model (PHDiffusion), which includes a lightweight adaptive encoder and a Dual Encoder Fusion (DEF) module. Specifically, the adaptive encoder and the DEF module first stylize foreground features within each encoder. Then, the stylized foreground features from both encoders are combined to guide the harmonization process. During training, besides the noise loss in diffusion model, we additionally employ content loss and two style losses, i.e., AdaIN style loss and contrastive style loss, aiming to balance the trade-off between style migration and content preservation. Compared with the state-of-the-art models from related fields, our PHDiffusion can stylize the foreground more sufficiently and simultaneously retain finer content. Our code and model are available at https://github.com/bcmi/PHDiffusion-Painterly-Image-Harmonization.