 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLAConf: Calibrated Task-Success Confidence for Vision-Language-Action Models
May 28, 2026Confidence estimation for Vision-Language-Action (VLA) models is essential for robots to perform manipulation tasks in the open world, providing crucial signals for risk-sensitive decision-making and failure anticipation. Existing confidence estimation methods typically rely on ensemble-based paradigms or action-token probabilities to predict the likelihood of task success. However, they still encounter challenges in computational efficiency and cross-architecture generalizability. These methods usually require repeated sampling, leading to inference inefficiency, and are restricted to VLA models with discrete action outputs, making them difficult to apply to continuous action spaces. To address this issue, we propose VLAConf, a one-class discriminative confidence framework. By leveraging frozen pretrained VLA internal representations, VLAConf directly estimates step-wise anomaly scores in a single forward pass using a lightweight confidence head, thereby eliminating the overhead of exhaustive resampling. We additionally use step-conditioned modeling to encode rollout-phase information along the manipulation trajectory. Experiments on the LIBERO benchmark demonstrate that VLAConf significantly improves the quality of the confidence signal constructed for post-hoc calibration, outperforming existing baselines by a large margin in inference efficiency. The effectiveness of VLAConf is further validated in real-robot experiments. To access the source code and supplementary videos, visit https://sites.google.com/view/vlaconf.
Easy-IIL: Reducing Human Operational Burden in Interactive Imitation Learning via Assistant Experts
Mar 13, 2026Interactive Imitation Learning (IIL) typically relies on extensive human involvement for both offline demonstration and online interaction. Prior work primarily focuses on reducing human effort in passive monitoring rather than active operation. Interestingly, structured model-based imitation approaches achieve comparable performance with significantly fewer demonstrations than end-to-end imitation learning policies in the low-data regime. However, these methods are typically surpassed by end-to-end policies as the data increases. Leveraging this insight, we propose Easy-IIL, a framework that utilizes off-the-shelf model-based imitation methods as an assistant expert to replace active human operation for the majority of data collection. The human expert only provides a single demonstration to initialize the assistant expert and intervenes in critical states where the task is approaching failure. Furthermore, Easy-IIL can maintain IIL performance by preserving both offline and online data quality. Extensive simulation and real-world experiments demonstrate that Easy-IIL significantly reduces human operational burden while maintaining performance comparable to mainstream IIL baselines. User studies further confirm that Easy-IIL reduces subjective workload on the human expert. Project page: https://sites.google.com/view/easy-iil
RTAGrasp: Learning Task-Oriented Grasping from Human Videos via Retrieval, Transfer, and Alignment
Sep 24, 2024Task-oriented grasping (TOG) is crucial for robots to accomplish manipulation tasks, requiring the determination of TOG positions and directions. Existing methods either rely on costly manual TOG annotations or only extract coarse grasping positions or regions from human demonstrations, limiting their practicality in real-world applications. To address these limitations, we introduce RTAGrasp, a Retrieval, Transfer, and Alignment framework inspired by human grasping strategies. Specifically, our approach first effortlessly constructs a robot memory from human grasping demonstration videos, extracting both TOG position and direction constraints. Then, given a task instruction and a visual observation of the target object, RTAGrasp retrieves the most similar human grasping experience from its memory and leverages semantic matching capabilities of vision foundation models to transfer the TOG constraints to the target object in a training-free manner. Finally, RTAGrasp aligns the transferred TOG constraints with the robot's action for execution. Evaluations on the public TOG benchmark, TaskGrasp dataset, show the competitive performance of RTAGrasp on both seen and unseen object categories compared to existing baseline methods. Real-world experiments further validate its effectiveness on a robotic arm. Our code, appendix, and video are available at \url{https://sites.google.com/view/rtagrasp/home}.
FoundationGrasp: Generalizable Task-Oriented Grasping with Foundation Models
Apr 16, 2024



Task-oriented grasping (TOG), which refers to the problem of synthesizing grasps on an object that are configurationally compatible with the downstream manipulation task, is the first milestone towards tool manipulation. Analogous to the activation of two brain regions responsible for semantic and geometric reasoning during cognitive processes, modeling the complex relationship between objects, tasks, and grasps requires rich prior knowledge about objects and tasks. Existing methods typically limit the prior knowledge to a closed-set scope and cannot support the generalization to novel objects and tasks out of the training set. To address such a limitation, we propose FoundationGrasp, a foundation model-based TOG framework that leverages the open-ended knowledge from foundation models to learn generalizable TOG skills. Comprehensive experiments are conducted on the contributed Language and Vision Augmented TaskGrasp (LaViA-TaskGrasp) dataset, demonstrating the superiority of FoudationGrasp over existing methods when generalizing to novel object instances, object classes, and tasks out of the training set. Furthermore, the effectiveness of FoudationGrasp is validated in real-robot grasping and manipulation experiments on a 7 DoF robotic arm. Our code, data, appendix, and video are publicly available at https://sites.google.com/view/foundationgrasp.
Efficient Object Rearrangement via Multi-view Fusion
Sep 16, 2023The prospect of assistive robots aiding in object organization has always been compelling. In an image-goal setting, the robot rearranges the current scene to match the single image captured from the goal scene. The key to an image-goal rearrangement system is estimating the desired placement pose of each object based on the single goal image and observations from the current scene. In order to establish sufficient associations for accurate estimation, the system should observe an object from a viewpoint similar to that in the goal image. Existing image-goal rearrangement systems, due to their reliance on a fixed viewpoint for perception, often require redundant manipulations to randomly adjust an object's pose for a better perspective. Addressing this inefficiency, we introduce a novel object rearrangement system that employs multi-view fusion. By observing the current scene from multiple viewpoints before manipulating objects, our approach can estimate a more accurate pose without redundant manipulation times. A standard visual localization pipeline at the object level is developed to capitalize on the advantages of multi-view observations. Simulation results demonstrate that the efficiency of our system outperforms existing single-view systems. The effectiveness of our system is further validated in a physical experiment.
GraspGPT: Leveraging Semantic Knowledge from a Large Language Model for Task-Oriented Grasping
Jul 30, 2023



Task-oriented grasping (TOG) refers to the problem of predicting grasps on an object that enable subsequent manipulation tasks. To model the complex relationships between objects, tasks, and grasps, existing methods incorporate semantic knowledge as priors into TOG pipelines. However, the existing semantic knowledge is typically constructed based on closed-world concept sets, restraining the generalization to novel concepts out of the pre-defined sets. To address this issue, we propose GraspGPT, a large language model (LLM) based TOG framework that leverages the open-end semantic knowledge from an LLM to achieve zero-shot generalization to novel concepts. We conduct experiments on Language Augmented TaskGrasp (LA-TaskGrasp) dataset and demonstrate that GraspGPT outperforms existing TOG methods on different held-out settings when generalizing to novel concepts out of the training set. The effectiveness of GraspGPT is further validated in real-robot experiments. Our code, data, appendix, and video are publicly available at https://sites.google.com/view/graspgpt/.
Task-Oriented Grasp Prediction with Visual-Language Inputs
Feb 28, 2023



To perform household tasks, assistive robots receive commands in the form of user language instructions for tool manipulation. The initial stage involves selecting the intended tool (i.e., object grounding) and grasping it in a task-oriented manner (i.e., task grounding). Nevertheless, prior researches on visual-language grasping (VLG) focus on object grounding, while disregarding the fine-grained impact of tasks on object grasping. Task-incompatible grasping of a tool will inevitably limit the success of subsequent manipulation steps. Motivated by this problem, this paper proposes GraspCLIP, which addresses the challenge of task grounding in addition to object grounding to enable task-oriented grasp prediction with visual-language inputs. Evaluation on a custom dataset demonstrates that GraspCLIP achieves superior performance over established baselines with object grounding only. The effectiveness of the proposed method is further validated on an assistive robotic arm platform for grasping previously unseen kitchen tools given the task specification. Our presentation video is available at: https://www.youtube.com/watch?v=e1wfYQPeAXU.
Bone Marrow Cell Recognition: Training Deep Object Detection with A New Loss Function
Oct 25, 2021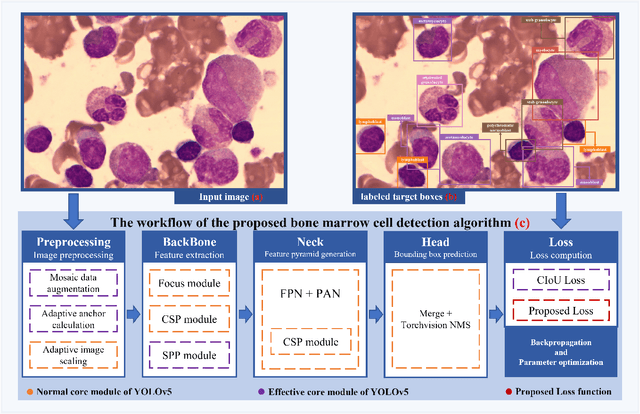
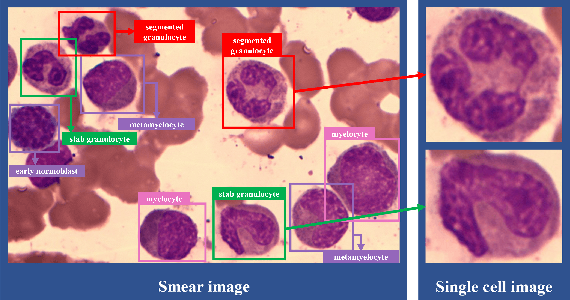
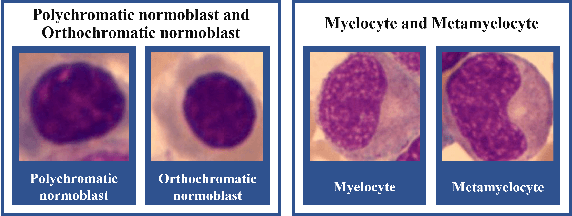
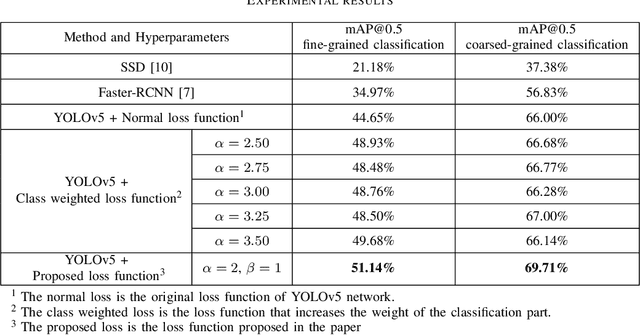
For a long time, bone marrow cell morphology examination has been an essential tool for diagnosing blood diseases. However, it is still mainly dependent on the subjective diagnosis of experienced doctors, and there is no objective quantitative standard. Therefore, it is crucial to study a robust bone marrow cell detection algorithm for a quantitative automatic analysis system. Currently, due to the dense distribution of cells in the bone marrow smear and the diverse cell classes, the detection of bone marrow cells is difficult. The existing bone marrow cell detection algorithms are still insufficient for the automatic analysis system of bone marrow smears. This paper proposes a bone marrow cell detection algorithm based on the YOLOv5 network, trained by minimizing a novel loss function. The classification method of bone marrow cell detection tasks is the basis of the proposed novel loss function. Since bone marrow cells are classified according to series and stages, part of the classes in adjacent stages are similar. The proposed novel loss function considers the similarity between bone marrow cell classes, increases the penalty for prediction errors between dissimilar classes, and reduces the penalty for prediction errors between similar classes. The results show that the proposed loss function effectively improves the algorithm's performance, and the proposed bone marrow cell detection algorithm has achieved better performance than other cell detection algorithms.