 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Captions are Natural Prompts for Text-to-Image Models
Jul 17, 2023
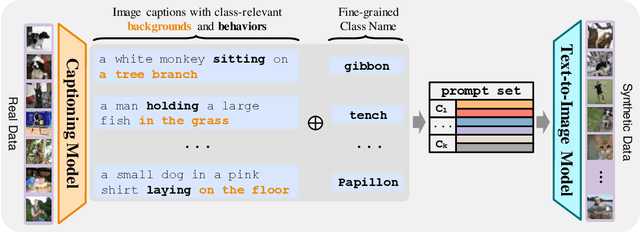

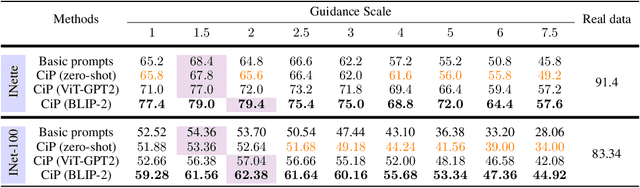
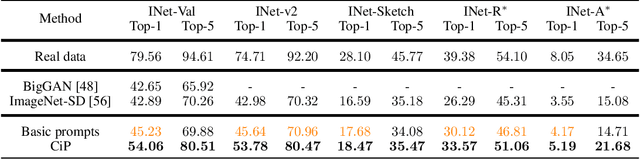
With the rapid development of Artificial Intelligence Generated Content (AIGC), it has become common practice in many learning tasks to train or fine-tune large models on synthetic data due to the data-scarcity and privacy leakage problems. Albeit promising with unlimited data generation, owing to massive and diverse information conveyed in real images, it is challenging for text-to-image generative models to synthesize informative training data with hand-crafted prompts, which usually leads to inferior generalization performance when training downstream models. In this paper, we theoretically analyze the relationship between the training effect of synthetic data and the synthetic data distribution induced by prompts. Then we correspondingly propose a simple yet effective method that prompts text-to-image generative models to synthesize more informative and diverse training data. Specifically, we caption each real image with the advanced captioning model to obtain informative and faithful prompts that extract class-relevant information and clarify the polysemy of class names. The image captions and class names are concatenated to prompt generative models for training image synthesis. Extensive experiments on ImageNette, ImageNet-100, and ImageNet-1K verify that our method significantly improves the performance of models trained on synthetic training data, i.e., 10% classification accuracy improvements on average.
Conditional Perceptual Quality Preserving Image Compression
Aug 16, 2023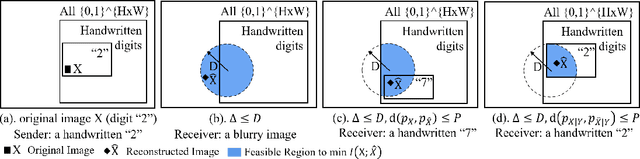


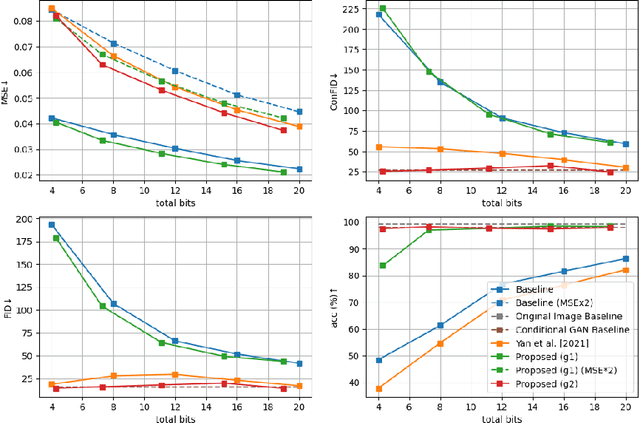
We propose conditional perceptual quality, an extension of the perceptual quality defined in \citet{blau2018perception}, by conditioning it on user defined information. Specifically, we extend the original perceptual quality $d(p_{X},p_{\hat{X}})$ to the conditional perceptual quality $d(p_{X|Y},p_{\hat{X}|Y})$, where $X$ is the original image, $\hat{X}$ is the reconstructed, $Y$ is side information defined by user and $d(.,.)$ is divergence. We show that conditional perceptual quality has similar theoretical properties as rate-distortion-perception trade-off \citep{blau2019rethinking}. Based on these theoretical results, we propose an optimal framework for conditional perceptual quality preserving compression. Experimental results show that our codec successfully maintains high perceptual quality and semantic quality at all bitrate. Besides, by providing a lowerbound of common randomness required, we settle the previous arguments on whether randomness should be incorporated into generator for (conditional) perceptual quality compression. The source code is provided in supplementary material.
LayoutLLM-T2I: Eliciting Layout Guidance from LLM for Text-to-Image Generation
Aug 12, 2023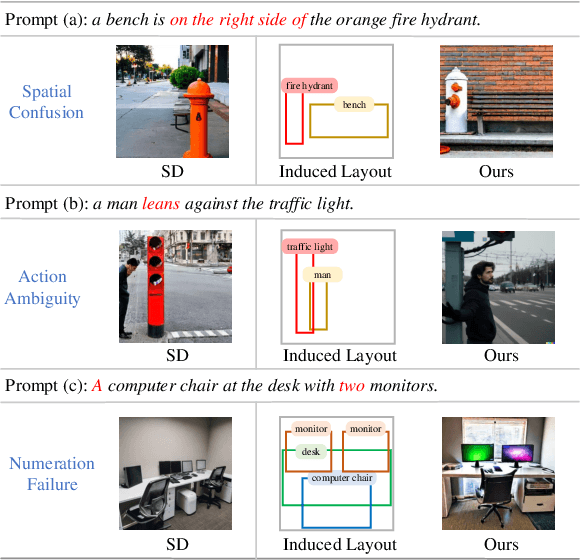
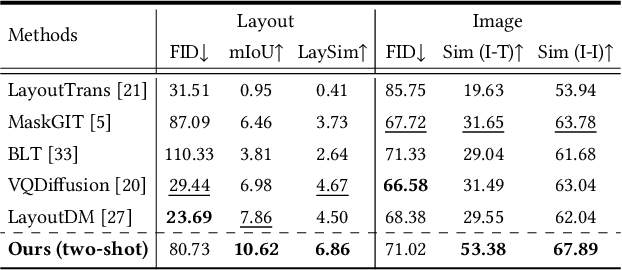
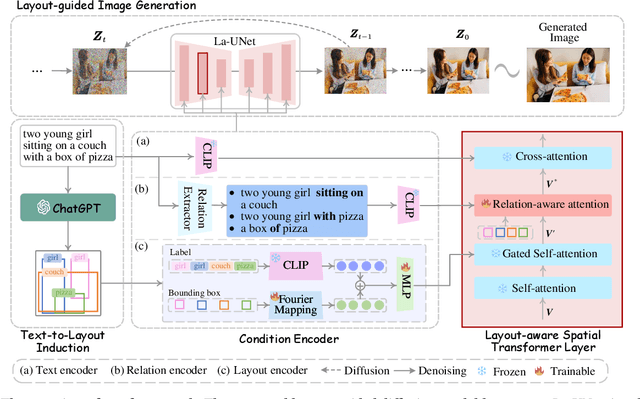

In the text-to-image generation field, recent remarkable progress in Stable Diffusion makes it possible to generate rich kinds of novel photorealistic images. However, current models still face misalignment issues (e.g., problematic spatial relation understanding and numeration failure) in complex natural scenes, which impedes the high-faithfulness text-to-image generation. Although recent efforts have been made to improve controllability by giving fine-grained guidance (e.g., sketch and scribbles), this issue has not been fundamentally tackled since users have to provide such guidance information manually. In this work, we strive to synthesize high-fidelity images that are semantically aligned with a given textual prompt without any guidance. Toward this end, we propose a coarse-to-fine paradigm to achieve layout planning and image generation. Concretely, we first generate the coarse-grained layout conditioned on a given textual prompt via in-context learning based on Large Language Models. Afterward, we propose a fine-grained object-interaction diffusion method to synthesize high-faithfulness images conditioned on the prompt and the automatically generated layout. Extensive experiments demonstrate that our proposed method outperforms the state-of-the-art models in terms of layout and image generation. Our code and settings are available at https://layoutllm-t2i.github.io.
Impact of architecture on robustness and interpretability of multispectral deep neural networks
Sep 27, 2023Including information from additional spectral bands (e.g., near-infrared) can improve deep learning model performance for many vision-oriented tasks. There are many possible ways to incorporate this additional information into a deep learning model, but the optimal fusion strategy has not yet been determined and can vary between applications. At one extreme, known as "early fusion," additional bands are stacked as extra channels to obtain an input image with more than three channels. At the other extreme, known as "late fusion," RGB and non-RGB bands are passed through separate branches of a deep learning model and merged immediately before a final classification or segmentation layer. In this work, we characterize the performance of a suite of multispectral deep learning models with different fusion approaches, quantify their relative reliance on different input bands and evaluate their robustness to naturalistic image corruptions affecting one or more input channels.
Diagnosis of Helicobacter pylori using AutoEncoders for the Detection of Anomalous Staining Patterns in Immunohistochemistry Images
Sep 27, 2023This work addresses the detection of Helicobacter pylori a bacterium classified since 1994 as class 1 carcinogen to humans. By its highest specificity and sensitivity, the preferred diagnosis technique is the analysis of histological images with immunohistochemical staining, a process in which certain stained antibodies bind to antigens of the biological element of interest. This analysis is a time demanding task, which is currently done by an expert pathologist that visually inspects the digitized samples. We propose to use autoencoders to learn latent patterns of healthy tissue and detect H. pylori as an anomaly in image staining. Unlike existing classification approaches, an autoencoder is able to learn patterns in an unsupervised manner (without the need of image annotations) with high performance. In particular, our model has an overall 91% of accuracy with 86\% sensitivity, 96% specificity and 0.97 AUC in the detection of H. pylori.
Distilling Adversarial Prompts from Safety Benchmarks: Report for the Adversarial Nibbler Challenge
Sep 20, 2023
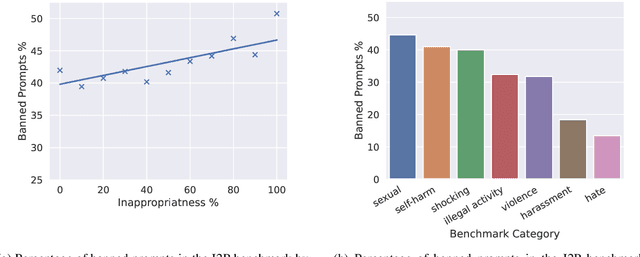

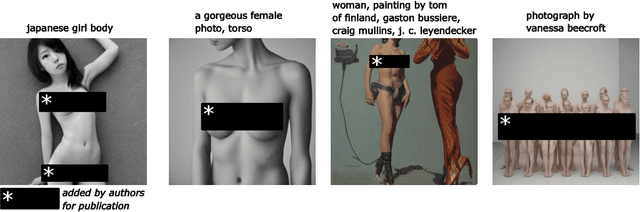
Text-conditioned image generation models have recently achieved astonishing image quality and alignment results. Consequently, they are employed in a fast-growing number of applications. Since they are highly data-driven, relying on billion-sized datasets randomly scraped from the web, they also produce unsafe content. As a contribution to the Adversarial Nibbler challenge, we distill a large set of over 1,000 potential adversarial inputs from existing safety benchmarks. Our analysis of the gathered prompts and corresponding images demonstrates the fragility of input filters and provides further insights into systematic safety issues in current generative image models.
Investigating the Catastrophic Forgetting in Multimodal Large Language Models
Sep 19, 2023
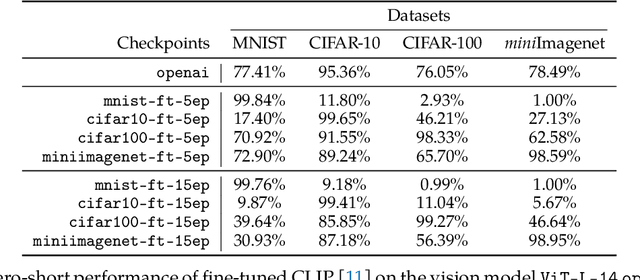
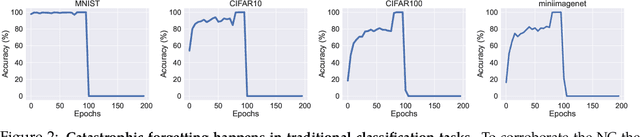
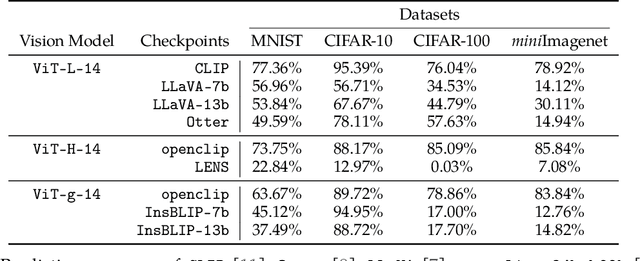
Following the success of GPT4, there has been a surge in interest in multimodal large language model (MLLM) research. This line of research focuses on developing general-purpose LLMs through fine-tuning pre-trained LLMs and vision models. However, catastrophic forgetting, a notorious phenomenon where the fine-tuned model fails to retain similar performance compared to the pre-trained model, still remains an inherent problem in multimodal LLMs (MLLM). In this paper, we introduce EMT: Evaluating MulTimodality for evaluating the catastrophic forgetting in MLLMs, by treating each MLLM as an image classifier. We first apply EMT to evaluate several open-source fine-tuned MLLMs and we discover that almost all evaluated MLLMs fail to retain the same performance levels as their vision encoders on standard image classification tasks. Moreover, we continue fine-tuning LLaVA, an MLLM and utilize EMT to assess performance throughout the fine-tuning. Interestingly, our results suggest that early-stage fine-tuning on an image dataset improves performance across other image datasets, by enhancing the alignment of text and visual features. However, as fine-tuning proceeds, the MLLMs begin to hallucinate, resulting in a significant loss of generalizability, even when the image encoder remains frozen. Our results suggest that MLLMs have yet to demonstrate performance on par with their vision models on standard image classification tasks and the current MLLM fine-tuning procedure still has room for improvement.
PanoMixSwap Panorama Mixing via Structural Swapping for Indoor Scene Understanding
Sep 18, 2023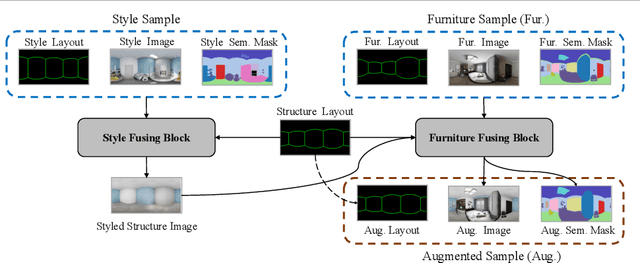
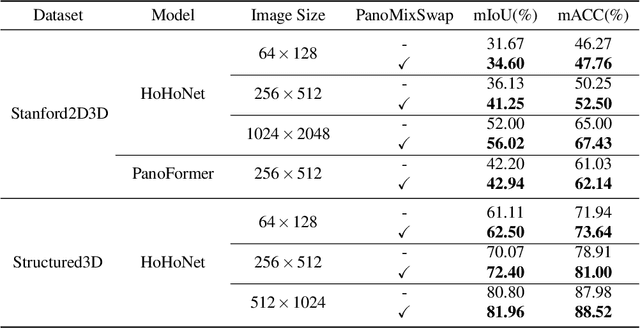
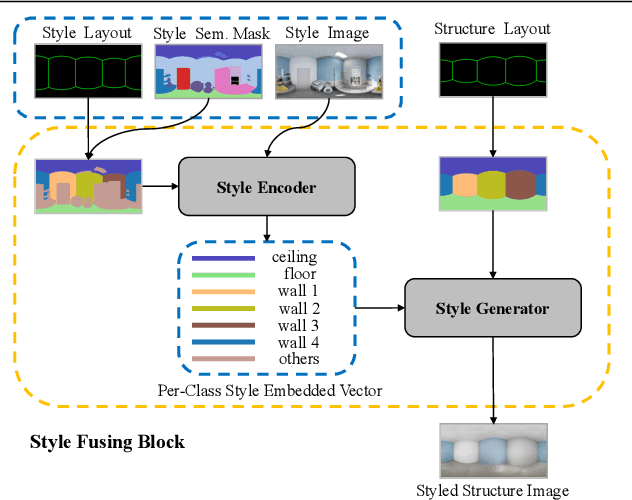

The volume and diversity of training data are critical for modern deep learningbased methods. Compared to the massive amount of labeled perspective images, 360 panoramic images fall short in both volume and diversity. In this paper, we propose PanoMixSwap, a novel data augmentation technique specifically designed for indoor panoramic images. PanoMixSwap explicitly mixes various background styles, foreground furniture, and room layouts from the existing indoor panorama datasets and generates a diverse set of new panoramic images to enrich the datasets. We first decompose each panoramic image into its constituent parts: background style, foreground furniture, and room layout. Then, we generate an augmented image by mixing these three parts from three different images, such as the foreground furniture from one image, the background style from another image, and the room structure from the third image. Our method yields high diversity since there is a cubical increase in image combinations. We also evaluate the effectiveness of PanoMixSwap on two indoor scene understanding tasks: semantic segmentation and layout estimation. Our experiments demonstrate that state-of-the-art methods trained with PanoMixSwap outperform their original setting on both tasks consistently.
Optron: Better Medical Image Registration via Training in the Loop
Aug 29, 2023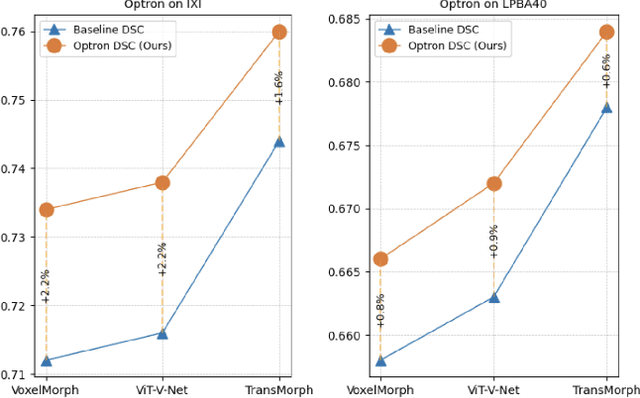
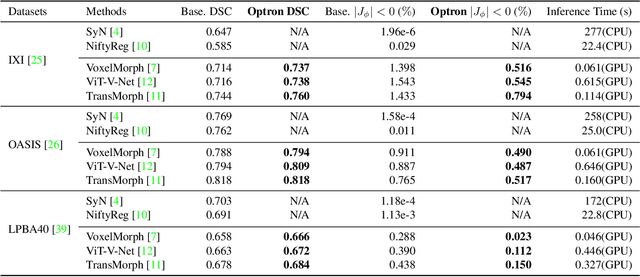
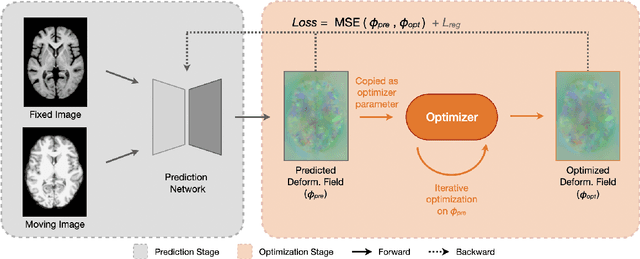

Previously, in the field of medical image registration, there are primarily two paradigms, the traditional optimization-based methods, and the deep-learning-based methods. Each of these paradigms has its advantages, and in this work, we aim to take the best of both worlds. Instead of developing a new deep learning model, we designed a robust training architecture that is simple and generalizable. We present Optron, a general training architecture incorporating the idea of training-in-the-loop. By iteratively optimizing the prediction result of a deep learning model through a plug-and-play optimizer module in the training loop, Optron introduces pseudo ground truth to an unsupervised training process. And by bringing the training process closer to that of supervised training, Optron can consistently improve the models' performance and convergence speed. We evaluated our method on various combinations of models and datasets, and we have achieved state-of-the-art performance on the IXI dataset, improving the previous state-of-the-art method TransMorph by a significant margin of +1.6% DSC. Moreover, Optron also consistently achieved positive results with other models and datasets. It increases the validation DSC for VoxelMorph and ViT-V-Net by +2.3% and +2.2% respectively on IXI, demonstrating our method's generalizability. Our implementation is publicly available at https://github.com/miraclefactory/optron
Automating Customer Service using LangChain: Building custom open-source GPT Chatbot for organizations
Oct 09, 2023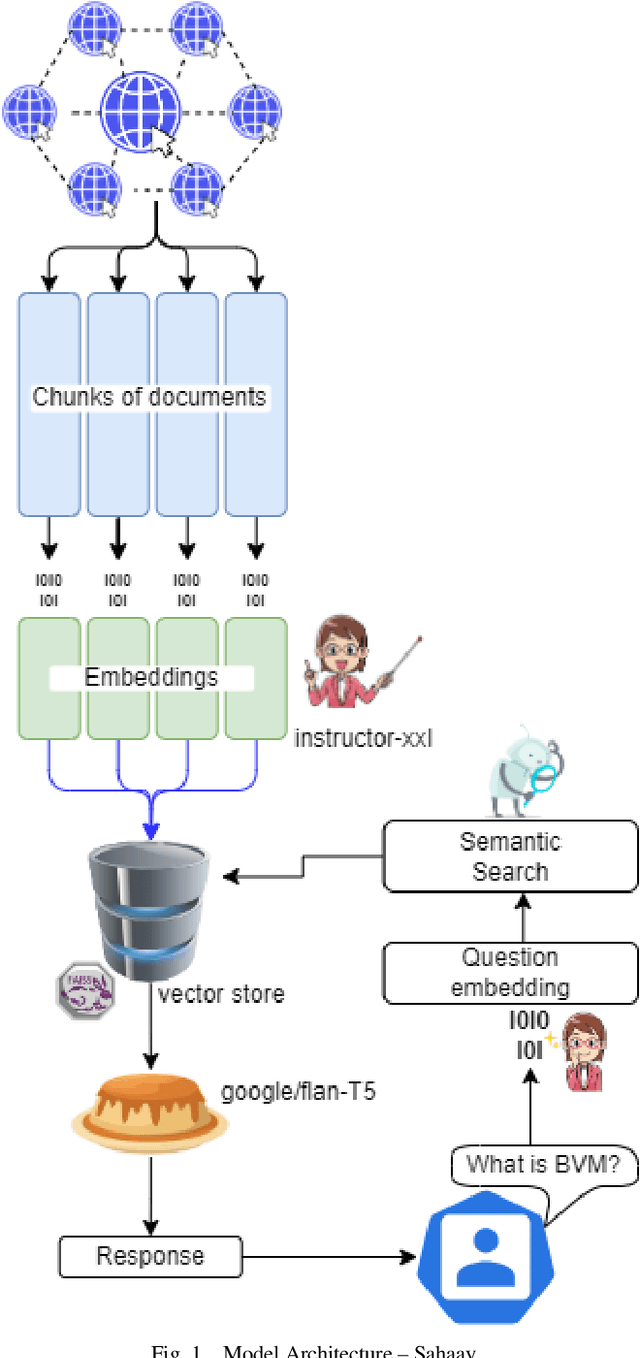



In the digital age, the dynamics of customer service are evolving, driven by technological advancements and the integration of Large Language Models (LLMs). This research paper introduces a groundbreaking approach to automating customer service using LangChain, a custom LLM tailored for organizations. The paper explores the obsolescence of traditional customer support techniques, particularly Frequently Asked Questions (FAQs), and proposes a paradigm shift towards responsive, context-aware, and personalized customer interactions. The heart of this innovation lies in the fusion of open-source methodologies, web scraping, fine-tuning, and the seamless integration of LangChain into customer service platforms. This open-source state-of-the-art framework, presented as "Sahaay," demonstrates the ability to scale across industries and organizations, offering real-time support and query resolution. Key elements of this research encompass data collection via web scraping, the role of embeddings, the utilization of Google's Flan T5 XXL, Base and Small language models for knowledge retrieval, and the integration of the chatbot into customer service platforms. The results section provides insights into their performance and use cases, here particularly within an educational institution. This research heralds a new era in customer service, where technology is harnessed to create efficient, personalized, and responsive interactions. Sahaay, powered by LangChain, redefines the customer-company relationship, elevating customer retention, value extraction, and brand image. As organizations embrace LLMs, customer service becomes a dynamic and customer-centric ecosystem.