 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Posterior Sampling Based on Gradient Flows of the MMD with Negative Distance Kernel
Oct 04, 2023
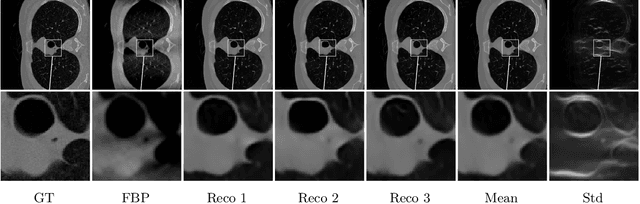



We propose conditional flows of the maximum mean discrepancy (MMD) with the negative distance kernel for posterior sampling and conditional generative modeling. This MMD, which is also known as energy distance, has several advantageous properties like efficient computation via slicing and sorting. We approximate the joint distribution of the ground truth and the observations using discrete Wasserstein gradient flows and establish an error bound for the posterior distributions. Further, we prove that our particle flow is indeed a Wasserstein gradient flow of an appropriate functional. The power of our method is demonstrated by numerical examples including conditional image generation and inverse problems like superresolution, inpainting and computed tomography in low-dose and limited-angle settings.
Self-supervised Learning of Contextualized Local Visual Embeddings
Oct 04, 2023We present Contextualized Local Visual Embeddings (CLoVE), a self-supervised convolutional-based method that learns representations suited for dense prediction tasks. CLoVE deviates from current methods and optimizes a single loss function that operates at the level of contextualized local embeddings learned from output feature maps of convolution neural network (CNN) encoders. To learn contextualized embeddings, CLoVE proposes a normalized mult-head self-attention layer that combines local features from different parts of an image based on similarity. We extensively benchmark CLoVE's pre-trained representations on multiple datasets. CLoVE reaches state-of-the-art performance for CNN-based architectures in 4 dense prediction downstream tasks, including object detection, instance segmentation, keypoint detection, and dense pose estimation.
* Pre-print. 4th Visual Inductive Priors for Data-Efficient Deep Learning Workshop ICCV 2023. Code at https://github.com/sthalles/CLoVE
Dataset Diffusion: Diffusion-based Synthetic Dataset Generation for Pixel-Level Semantic Segmentation
Sep 29, 2023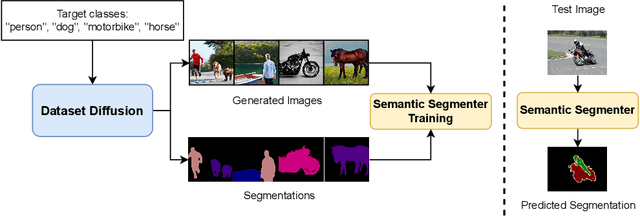
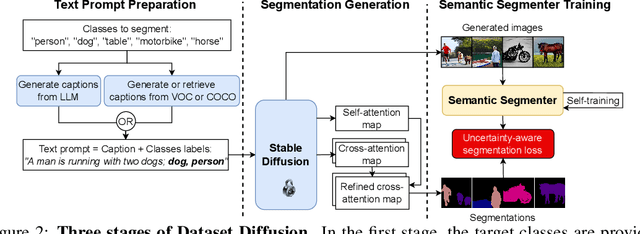
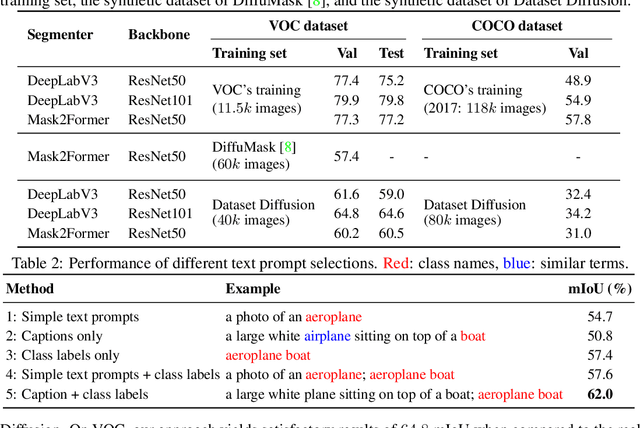

Preparing training data for deep vision models is a labor-intensive task. To address this, generative models have emerged as an effective solution for generating synthetic data. While current generative models produce image-level category labels, we propose a novel method for generating pixel-level semantic segmentation labels using the text-to-image generative model Stable Diffusion (SD). By utilizing the text prompts, cross-attention, and self-attention of SD, we introduce three new techniques: class-prompt appending, class-prompt cross-attention, and self-attention exponentiation. These techniques enable us to generate segmentation maps corresponding to synthetic images. These maps serve as pseudo-labels for training semantic segmenters, eliminating the need for labor-intensive pixel-wise annotation. To account for the imperfections in our pseudo-labels, we incorporate uncertainty regions into the segmentation, allowing us to disregard loss from those regions. We conduct evaluations on two datasets, PASCAL VOC and MSCOCO, and our approach significantly outperforms concurrent work. Our benchmarks and code will be released at https://github.com/VinAIResearch/Dataset-Diffusion
HAvatar: High-fidelity Head Avatar via Facial Model Conditioned Neural Radiance Field
Sep 29, 2023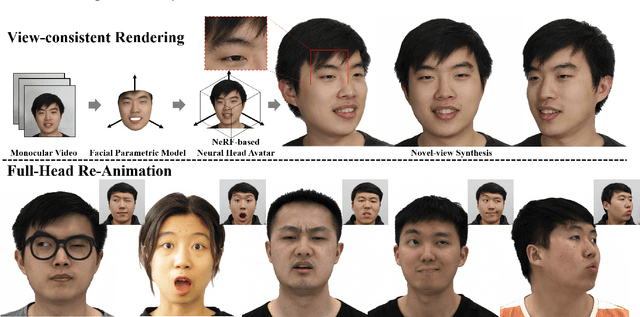
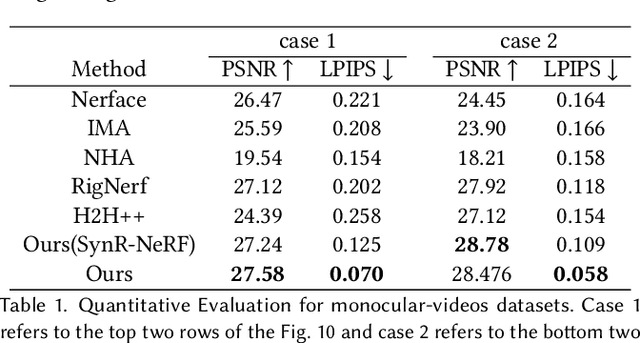
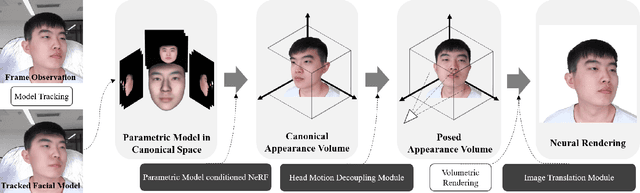
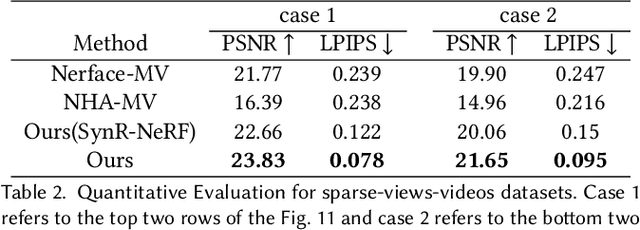
The problem of modeling an animatable 3D human head avatar under light-weight setups is of significant importance but has not been well solved. Existing 3D representations either perform well in the realism of portrait images synthesis or the accuracy of expression control, but not both. To address the problem, we introduce a novel hybrid explicit-implicit 3D representation, Facial Model Conditioned Neural Radiance Field, which integrates the expressiveness of NeRF and the prior information from the parametric template. At the core of our representation, a synthetic-renderings-based condition method is proposed to fuse the prior information from the parametric model into the implicit field without constraining its topological flexibility. Besides, based on the hybrid representation, we properly overcome the inconsistent shape issue presented in existing methods and improve the animation stability. Moreover, by adopting an overall GAN-based architecture using an image-to-image translation network, we achieve high-resolution, realistic and view-consistent synthesis of dynamic head appearance. Experiments demonstrate that our method can achieve state-of-the-art performance for 3D head avatar animation compared with previous methods.
A Foundation Model for General Moving Object Segmentation in Medical Images
Sep 29, 2023
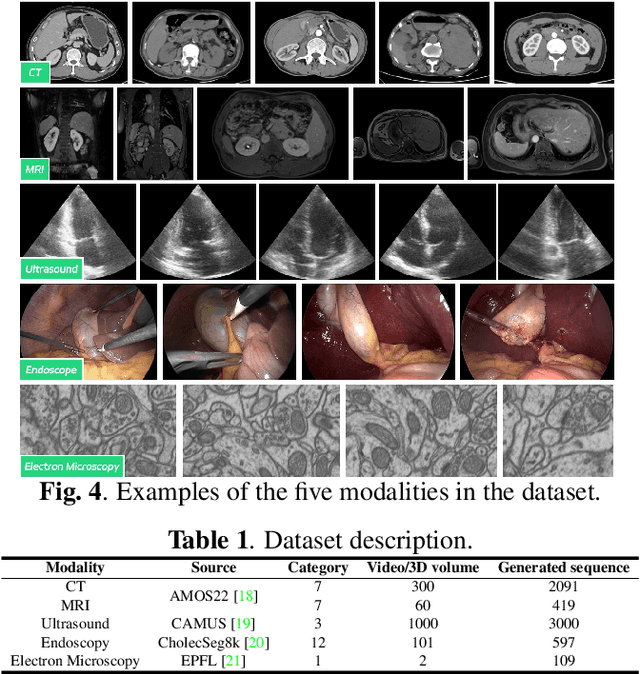
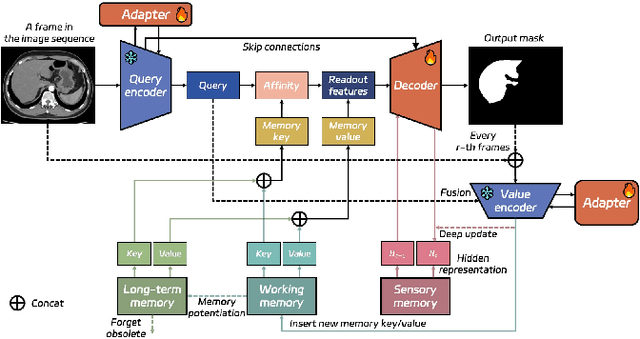
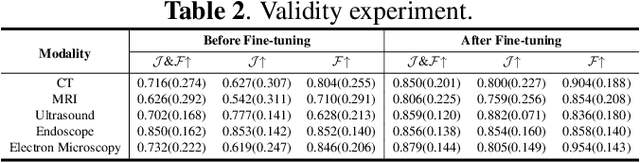
Medical image segmentation aims to delineate the anatomical or pathological structures of interest, playing a crucial role in clinical diagnosis. A substantial amount of high-quality annotated data is crucial for constructing high-precision deep segmentation models. However, medical annotation is highly cumbersome and time-consuming, especially for medical videos or 3D volumes, due to the huge labeling space and poor inter-frame consistency. Recently, a fundamental task named Moving Object Segmentation (MOS) has made significant advancements in natural images. Its objective is to delineate moving objects from the background within image sequences, requiring only minimal annotations. In this paper, we propose the first foundation model, named iMOS, for MOS in medical images. Extensive experiments on a large multi-modal medical dataset validate the effectiveness of the proposed iMOS. Specifically, with the annotation of only a small number of images in the sequence, iMOS can achieve satisfactory tracking and segmentation performance of moving objects throughout the entire sequence in bi-directions. We hope that the proposed iMOS can help accelerate the annotation speed of experts, and boost the development of medical foundation models.
3D Reconstruction with Generalizable Neural Fields using Scene Priors
Sep 29, 2023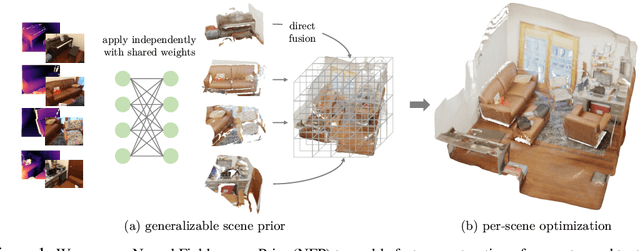
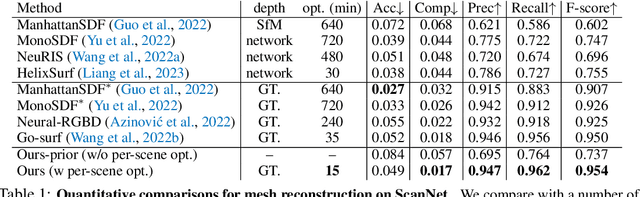
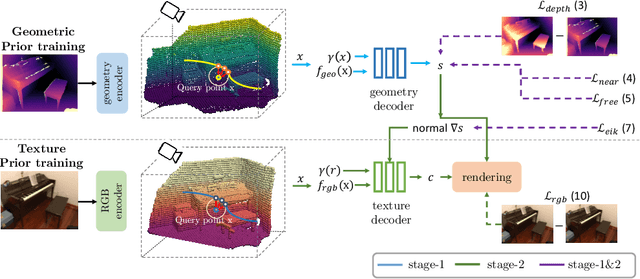
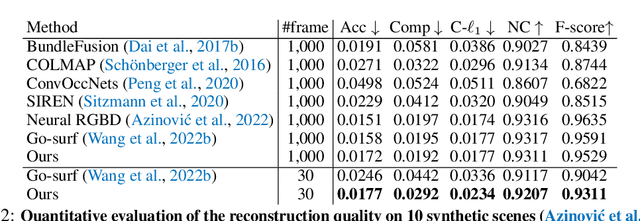
High-fidelity 3D scene reconstruction has been substantially advanced by recent progress in neural fields. However, most existing methods train a separate network from scratch for each individual scene. This is not scalable, inefficient, and unable to yield good results given limited views. While learning-based multi-view stereo methods alleviate this issue to some extent, their multi-view setting makes it less flexible to scale up and to broad applications. Instead, we introduce training generalizable Neural Fields incorporating scene Priors (NFPs). The NFP network maps any single-view RGB-D image into signed distance and radiance values. A complete scene can be reconstructed by merging individual frames in the volumetric space WITHOUT a fusion module, which provides better flexibility. The scene priors can be trained on large-scale datasets, allowing for fast adaptation to the reconstruction of a new scene with fewer views. NFP not only demonstrates SOTA scene reconstruction performance and efficiency, but it also supports single-image novel-view synthesis, which is underexplored in neural fields. More qualitative results are available at: https://oasisyang.github.io/neural-prior
HumanNorm: Learning Normal Diffusion Model for High-quality and Realistic 3D Human Generation
Oct 02, 2023
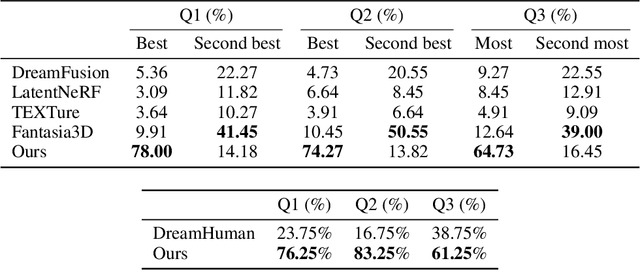

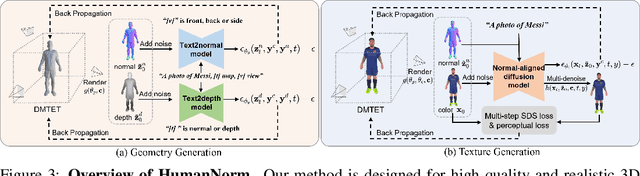
Recent text-to-3D methods employing diffusion models have made significant advancements in 3D human generation. However, these approaches face challenges due to the limitations of the text-to-image diffusion model, which lacks an understanding of 3D structures. Consequently, these methods struggle to achieve high-quality human generation, resulting in smooth geometry and cartoon-like appearances. In this paper, we observed that fine-tuning text-to-image diffusion models with normal maps enables their adaptation into text-to-normal diffusion models, which enhances the 2D perception of 3D geometry while preserving the priors learned from large-scale datasets. Therefore, we propose HumanNorm, a novel approach for high-quality and realistic 3D human generation by learning the normal diffusion model including a normal-adapted diffusion model and a normal-aligned diffusion model. The normal-adapted diffusion model can generate high-fidelity normal maps corresponding to prompts with view-dependent text. The normal-aligned diffusion model learns to generate color images aligned with the normal maps, thereby transforming physical geometry details into realistic appearance. Leveraging the proposed normal diffusion model, we devise a progressive geometry generation strategy and coarse-to-fine texture generation strategy to enhance the efficiency and robustness of 3D human generation. Comprehensive experiments substantiate our method's ability to generate 3D humans with intricate geometry and realistic appearances, significantly outperforming existing text-to-3D methods in both geometry and texture quality. The project page of HumanNorm is https://humannorm.github.io/.
FFPN: Fourier Feature Pyramid Network for Ultrasound Image Segmentation
Aug 26, 2023
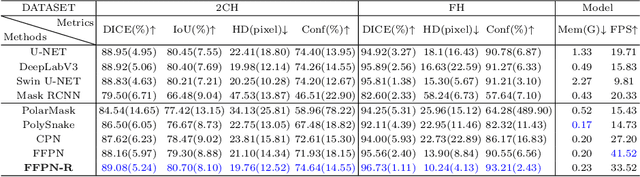
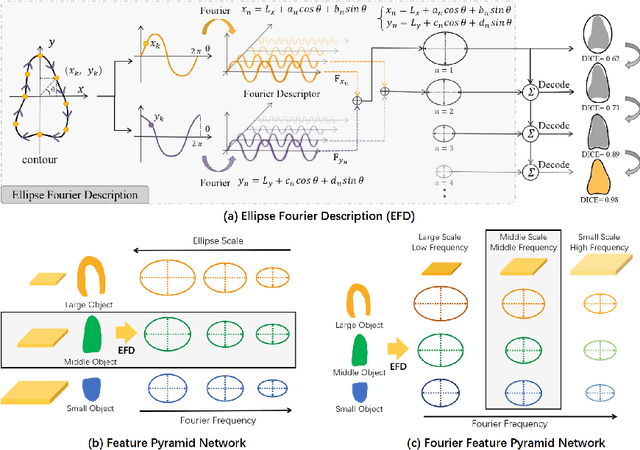
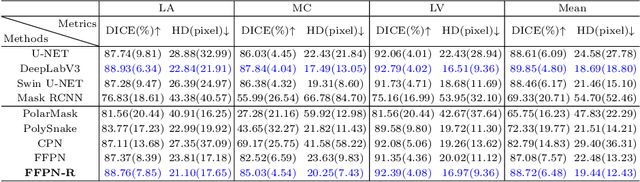
Ultrasound (US) image segmentation is an active research area that requires real-time and highly accurate analysis in many scenarios. The detect-to-segment (DTS) frameworks have been recently proposed to balance accuracy and efficiency. However, existing approaches may suffer from inadequate contour encoding or fail to effectively leverage the encoded results. In this paper, we introduce a novel Fourier-anchor-based DTS framework called Fourier Feature Pyramid Network (FFPN) to address the aforementioned issues. The contributions of this paper are two fold. First, the FFPN utilizes Fourier Descriptors to adequately encode contours. Specifically, it maps Fourier series with similar amplitudes and frequencies into the same layer of the feature map, thereby effectively utilizing the encoded Fourier information. Second, we propose a Contour Sampling Refinement (CSR) module based on the contour proposals and refined features produced by the FFPN. This module extracts rich features around the predicted contours to further capture detailed information and refine the contours. Extensive experimental results on three large and challenging datasets demonstrate that our method outperforms other DTS methods in terms of accuracy and efficiency. Furthermore, our framework can generalize well to other detection or segmentation tasks.
DrivingDiffusion: Layout-Guided multi-view driving scene video generation with latent diffusion model
Oct 11, 2023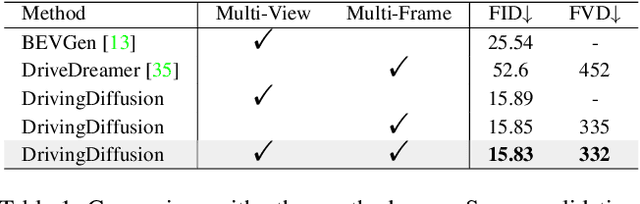
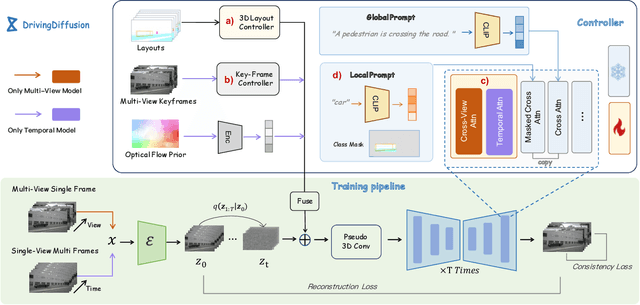
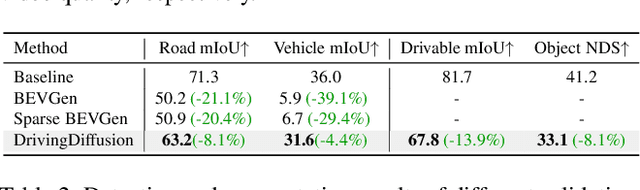
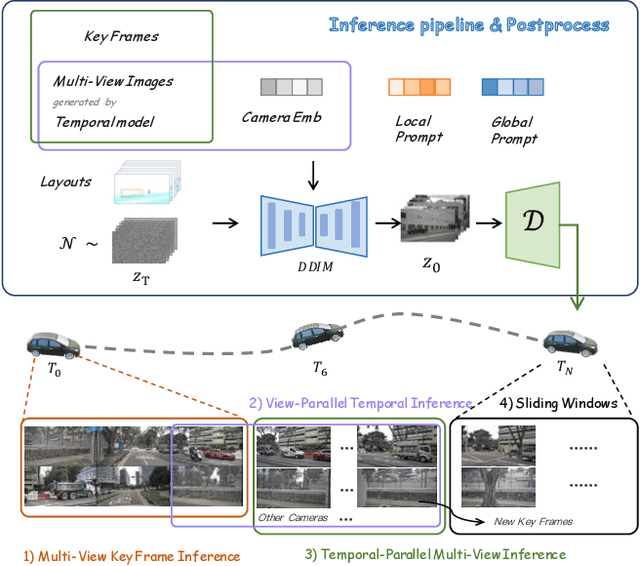
With the increasing popularity of autonomous driving based on the powerful and unified bird's-eye-view (BEV) representation, a demand for high-quality and large-scale multi-view video data with accurate annotation is urgently required. However, such large-scale multi-view data is hard to obtain due to expensive collection and annotation costs. To alleviate the problem, we propose a spatial-temporal consistent diffusion framework DrivingDiffusion, to generate realistic multi-view videos controlled by 3D layout. There are three challenges when synthesizing multi-view videos given a 3D layout: How to keep 1) cross-view consistency and 2) cross-frame consistency? 3) How to guarantee the quality of the generated instances? Our DrivingDiffusion solves the problem by cascading the multi-view single-frame image generation step, the single-view video generation step shared by multiple cameras, and post-processing that can handle long video generation. In the multi-view model, the consistency of multi-view images is ensured by information exchange between adjacent cameras. In the temporal model, we mainly query the information that needs attention in subsequent frame generation from the multi-view images of the first frame. We also introduce the local prompt to effectively improve the quality of generated instances. In post-processing, we further enhance the cross-view consistency of subsequent frames and extend the video length by employing temporal sliding window algorithm. Without any extra cost, our model can generate large-scale realistic multi-camera driving videos in complex urban scenes, fueling the downstream driving tasks. The code will be made publicly available.
Robust Unsupervised Domain Adaptation by Retaining Confident Entropy via Edge Concatenation
Oct 11, 2023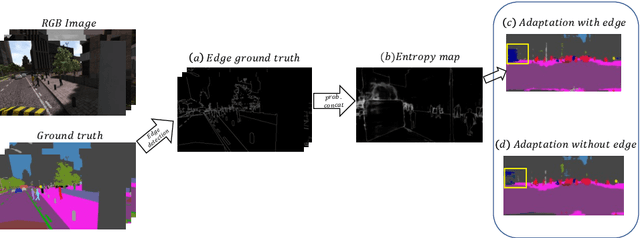
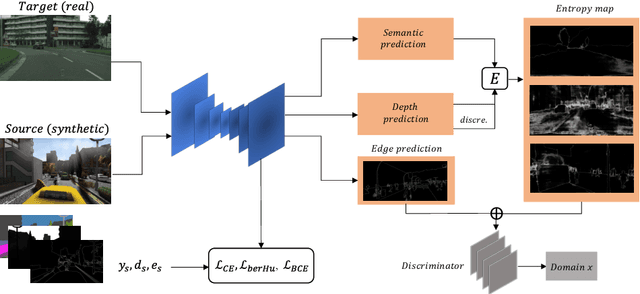
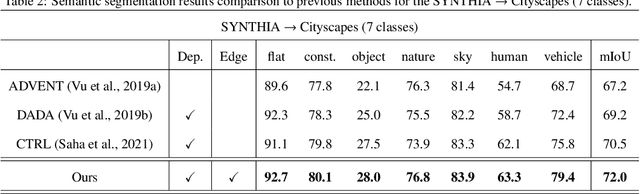

The generalization capability of unsupervised domain adaptation can mitigate the need for extensive pixel-level annotations to train semantic segmentation networks by training models on synthetic data as a source with computer-generated annotations. Entropy-based adversarial networks are proposed to improve source domain prediction; however, they disregard significant external information, such as edges, which have the potential to identify and distinguish various objects within an image accurately. To address this issue, we introduce a novel approach to domain adaptation, leveraging the synergy of internal and external information within entropy-based adversarial networks. In this approach, we enrich the discriminator network with edge-predicted probability values within this innovative framework to enhance the clarity of class boundaries. Furthermore, we devised a probability-sharing network that integrates diverse information for more effective segmentation. Incorporating object edges addresses a pivotal aspect of unsupervised domain adaptation that has frequently been neglected in the past -- the precise delineation of object boundaries. Conventional unsupervised domain adaptation methods usually center around aligning feature distributions and may not explicitly model object boundaries. Our approach effectively bridges this gap by offering clear guidance on object boundaries, thereby elevating the quality of domain adaptation. Our approach undergoes rigorous evaluation on the established unsupervised domain adaptation benchmarks, specifically in adapting SYNTHIA $\rightarrow$ Cityscapes and SYNTHIA $\rightarrow$ Mapillary. Experimental results show that the proposed model attains better performance than state-of-the-art methods. The superior performance across different unsupervised domain adaptation scenarios highlights the versatility and robustness of the proposed method.