 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unveiling Fairness Biases in Deep Learning-Based Brain MRI Reconstruction
Sep 25, 2023
Deep learning (DL) reconstruction particularly of MRI has led to improvements in image fidelity and reduction of acquisition time. In neuroimaging, DL methods can reconstruct high-quality images from undersampled data. However, it is essential to consider fairness in DL algorithms, particularly in terms of demographic characteristics. This study presents the first fairness analysis in a DL-based brain MRI reconstruction model. The model utilises the U-Net architecture for image reconstruction and explores the presence and sources of unfairness by implementing baseline Empirical Risk Minimisation (ERM) and rebalancing strategies. Model performance is evaluated using image reconstruction metrics. Our findings reveal statistically significant performance biases between the gender and age subgroups. Surprisingly, data imbalance and training discrimination are not the main sources of bias. This analysis provides insights of fairness in DL-based image reconstruction and aims to improve equity in medical AI applications.
Toloka Visual Question Answering Benchmark
Sep 28, 2023
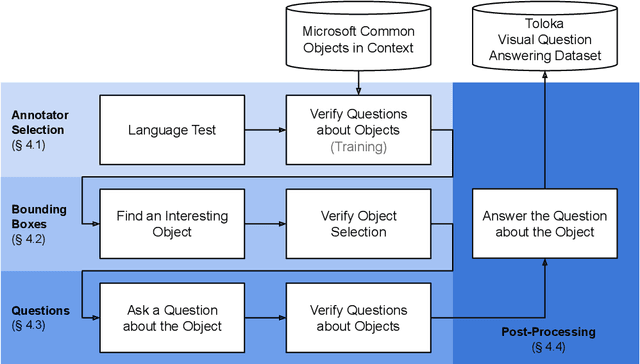

In this paper, we present Toloka Visual Question Answering, a new crowdsourced dataset allowing comparing performance of machine learning systems against human level of expertise in the grounding visual question answering task. In this task, given an image and a textual question, one has to draw the bounding box around the object correctly responding to that question. Every image-question pair contains the response, with only one correct response per image. Our dataset contains 45,199 pairs of images and questions in English, provided with ground truth bounding boxes, split into train and two test subsets. Besides describing the dataset and releasing it under a CC BY license, we conducted a series of experiments on open source zero-shot baseline models and organized a multi-phase competition at WSDM Cup that attracted 48 participants worldwide. However, by the time of paper submission, no machine learning model outperformed the non-expert crowdsourcing baseline according to the intersection over union evaluation score.
Neural architecture impact on identifying temporally extended Reinforcement Learning tasks
Oct 04, 2023Inspired by recent developments in attention models for image classification and natural language processing, we present various Attention based architectures in reinforcement learning (RL) domain, capable of performing well on OpenAI Gym Atari-2600 game suite. In spite of the recent success of Deep Reinforcement learning techniques in various fields like robotics, gaming and healthcare, they suffer from a major drawback that neural networks are difficult to interpret. We try to get around this problem with the help of Attention based models. In Attention based models, extracting and overlaying of attention map onto images allows for direct observation of information used by agent to select actions and easier interpretation of logic behind the chosen actions. Our models in addition to playing well on gym-Atari environments, also provide insights on how agent perceives its environment. In addition, motivated by recent developments in attention based video-classification models using Vision Transformer, we come up with an architecture based on Vision Transformer, for image-based RL domain too. Compared to previous works in Vision Transformer, our model is faster to train and requires fewer computational resources. 3
Explore the Effect of Data Selection on Poison Efficiency in Backdoor Attacks
Oct 15, 2023As the number of parameters in Deep Neural Networks (DNNs) scales, the thirst for training data also increases. To save costs, it has become common for users and enterprises to delegate time-consuming data collection to third parties. Unfortunately, recent research has shown that this practice raises the risk of DNNs being exposed to backdoor attacks. Specifically, an attacker can maliciously control the behavior of a trained model by poisoning a small portion of the training data. In this study, we focus on improving the poisoning efficiency of backdoor attacks from the sample selection perspective. The existing attack methods construct such poisoned samples by randomly selecting some clean data from the benign set and then embedding a trigger into them. However, this random selection strategy ignores that each sample may contribute differently to the backdoor injection, thereby reducing the poisoning efficiency. To address the above problem, a new selection strategy named Improved Filtering and Updating Strategy (FUS++) is proposed. Specifically, we adopt the forgetting events of the samples to indicate the contribution of different poisoned samples and use the curvature of the loss surface to analyses the effectiveness of this phenomenon. Accordingly, we combine forgetting events and curvature of different samples to conduct a simple yet efficient sample selection strategy. The experimental results on image classification (CIFAR-10, CIFAR-100, ImageNet-10), text classification (AG News), audio classification (ESC-50), and age regression (Facial Age) consistently demonstrate the effectiveness of the proposed strategy: the attack performance using FUS++ is significantly higher than that using random selection for the same poisoning ratio.
Diffusion-based Image Translation with Label Guidance for Domain Adaptive Semantic Segmentation
Aug 23, 2023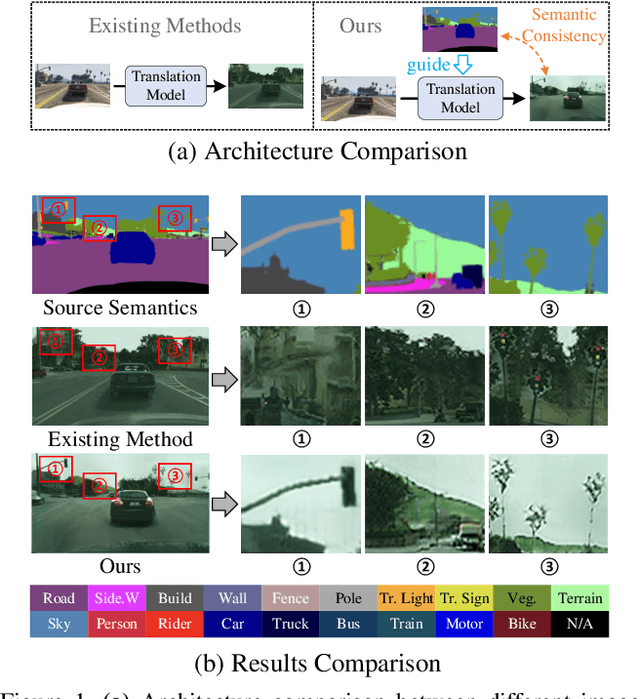
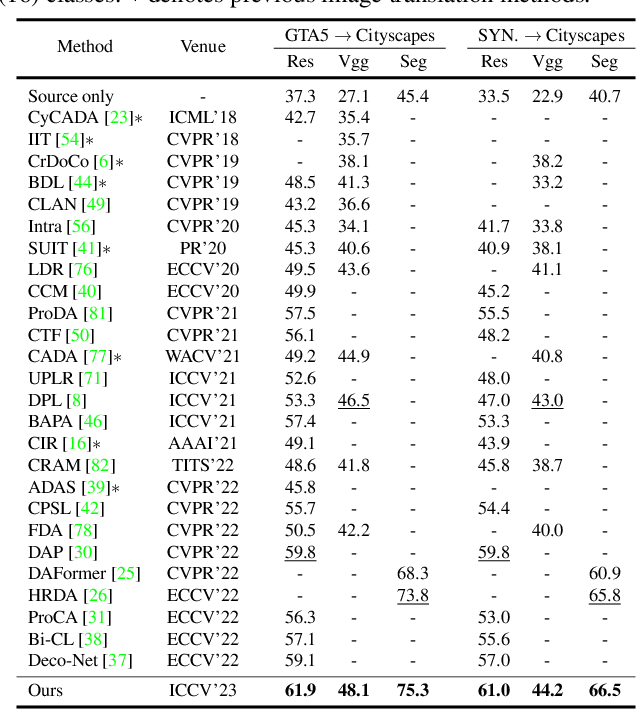
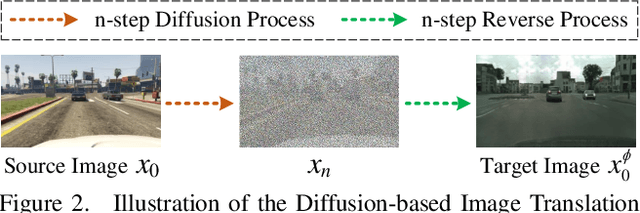
Translating images from a source domain to a target domain for learning target models is one of the most common strategies in domain adaptive semantic segmentation (DASS). However, existing methods still struggle to preserve semantically-consistent local details between the original and translated images. In this work, we present an innovative approach that addresses this challenge by using source-domain labels as explicit guidance during image translation. Concretely, we formulate cross-domain image translation as a denoising diffusion process and utilize a novel Semantic Gradient Guidance (SGG) method to constrain the translation process, conditioning it on the pixel-wise source labels. Additionally, a Progressive Translation Learning (PTL) strategy is devised to enable the SGG method to work reliably across domains with large gaps. Extensive experiments demonstrate the superiority of our approach over state-of-the-art methods.
Transformer-based Multimodal Change Detection with Multitask Consistency Constraints
Oct 13, 2023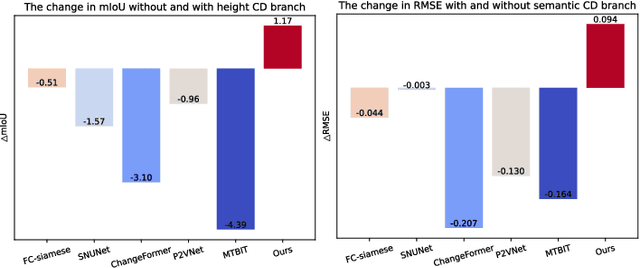
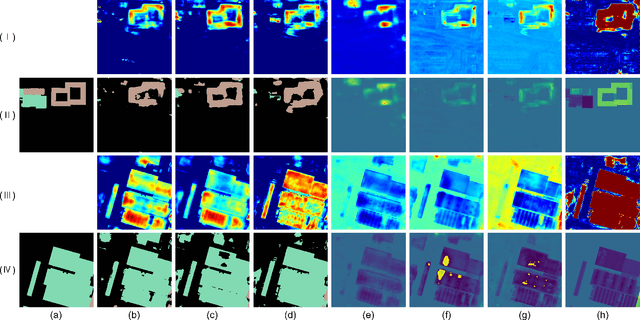
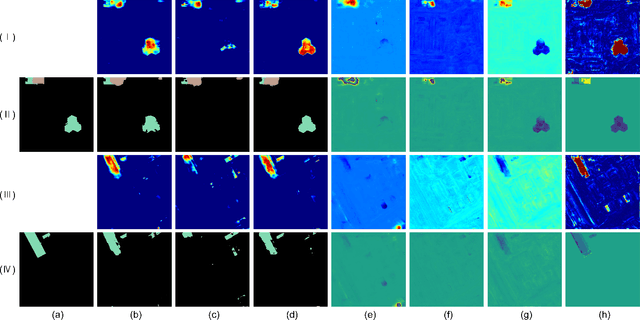

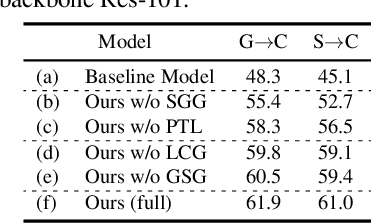
Change detection plays a fundamental role in Earth observation for analyzing temporal iterations over time. However, recent studies have largely neglected the utilization of multimodal data that presents significant practical and technical advantages compared to single-modal approaches. This research focuses on leveraging digital surface model (DSM) data and aerial images captured at different times for detecting change beyond 2D. We observe that the current change detection methods struggle with the multitask conflicts between semantic and height change detection tasks. To address this challenge, we propose an efficient Transformer-based network that learns shared representation between cross-dimensional inputs through cross-attention. It adopts a consistency constraint to establish the multimodal relationship, which involves obtaining pseudo change through height change thresholding and minimizing the difference between semantic and pseudo change within their overlapping regions. A DSM-to-image multimodal dataset encompassing three cities in the Netherlands was constructed. It lays a new foundation for beyond-2D change detection from cross-dimensional inputs. Compared to five state-of-the-art change detection methods, our model demonstrates consistent multitask superiority in terms of semantic and height change detection. Furthermore, the consistency strategy can be seamlessly adapted to the other methods, yielding promising improvements.
Adaptivity and Modularity for Efficient Generalization Over Task Complexity
Oct 13, 2023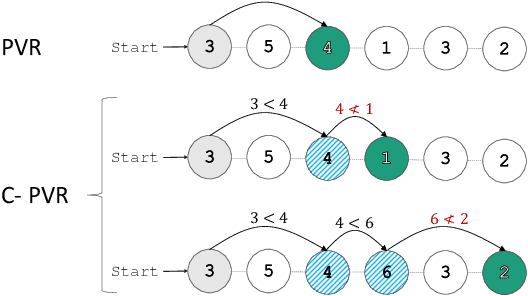


Can transformers generalize efficiently on problems that require dealing with examples with different levels of difficulty? We introduce a new task tailored to assess generalization over different complexities and present results that indicate that standard transformers face challenges in solving these tasks. These tasks are variations of pointer value retrieval previously introduced by Zhang et al. (2021). We investigate how the use of a mechanism for adaptive and modular computation in transformers facilitates the learning of tasks that demand generalization over the number of sequential computation steps (i.e., the depth of the computation graph). Based on our observations, we propose a transformer-based architecture called Hyper-UT, which combines dynamic function generation from hyper networks with adaptive depth from Universal Transformers. This model demonstrates higher accuracy and a fairer allocation of computational resources when generalizing to higher numbers of computation steps. We conclude that mechanisms for adaptive depth and modularity complement each other in improving efficient generalization concerning example complexity. Additionally, to emphasize the broad applicability of our findings, we illustrate that in a standard image recognition task, Hyper- UT's performance matches that of a ViT model but with considerably reduced computational demands (achieving over 70\% average savings by effectively using fewer layers).
CoNe: Contrast Your Neighbours for Supervised Image Classification
Aug 21, 2023



Image classification is a longstanding problem in computer vision and machine learning research. Most recent works (e.g. SupCon , Triplet, and max-margin) mainly focus on grouping the intra-class samples aggressively and compactly, with the assumption that all intra-class samples should be pulled tightly towards their class centers. However, such an objective will be very hard to achieve since it ignores the intra-class variance in the dataset. (i.e. different instances from the same class can have significant differences). Thus, such a monotonous objective is not sufficient. To provide a more informative objective, we introduce Contrast Your Neighbours (CoNe) - a simple yet practical learning framework for supervised image classification. Specifically, in CoNe, each sample is not only supervised by its class center but also directly employs the features of its similar neighbors as anchors to generate more adaptive and refined targets. Moreover, to further boost the performance, we propose ``distributional consistency" as a more informative regularization to enable similar instances to have a similar probability distribution. Extensive experimental results demonstrate that CoNe achieves state-of-the-art performance across different benchmark datasets, network architectures, and settings. Notably, even without a complicated training recipe, our CoNe achieves 80.8\% Top-1 accuracy on ImageNet with ResNet-50, which surpasses the recent Timm training recipe (80.4\%). Code and pre-trained models are available at \href{https://github.com/mingkai-zheng/CoNe}{https://github.com/mingkai-zheng/CoNe}.
Structure-Preserving Instance Segmentation via Skeleton-Aware Distance Transform
Oct 08, 2023Objects with complex structures pose significant challenges to existing instance segmentation methods that rely on boundary or affinity maps, which are vulnerable to small errors around contacting pixels that cause noticeable connectivity change. While the distance transform (DT) makes instance interiors and boundaries more distinguishable, it tends to overlook the intra-object connectivity for instances with varying width and result in over-segmentation. To address these challenges, we propose a skeleton-aware distance transform (SDT) that combines the merits of object skeleton in preserving connectivity and DT in modeling geometric arrangement to represent instances with arbitrary structures. Comprehensive experiments on histopathology image segmentation demonstrate that SDT achieves state-of-the-art performance.
EfficientOCR: An Extensible, Open-Source Package for Efficiently Digitizing World Knowledge
Oct 16, 2023Billions of public domain documents remain trapped in hard copy or lack an accurate digitization. Modern natural language processing methods cannot be used to index, retrieve, and summarize their texts; conduct computational textual analyses; or extract information for statistical analyses, and these texts cannot be incorporated into language model training. Given the diversity and sheer quantity of public domain texts, liberating them at scale requires optical character recognition (OCR) that is accurate, extremely cheap to deploy, and sample-efficient to customize to novel collections, languages, and character sets. Existing OCR engines, largely designed for small-scale commercial applications in high resource languages, often fall short of these requirements. EffOCR (EfficientOCR), a novel open-source OCR package, meets both the computational and sample efficiency requirements for liberating texts at scale by abandoning the sequence-to-sequence architecture typically used for OCR, which takes representations from a learned vision model as inputs to a learned language model. Instead, EffOCR models OCR as a character or word-level image retrieval problem. EffOCR is cheap and sample efficient to train, as the model only needs to learn characters' visual appearance and not how they are used in sequence to form language. Models in the EffOCR model zoo can be deployed off-the-shelf with only a few lines of code. Importantly, EffOCR also allows for easy, sample efficient customization with a simple model training interface and minimal labeling requirements due to its sample efficiency. We illustrate the utility of EffOCR by cheaply and accurately digitizing 20 million historical U.S. newspaper scans, evaluating zero-shot performance on randomly selected documents from the U.S. National Archives, and accurately digitizing Japanese documents for which all other OCR solutions failed.