 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChange-Aware Siamese Network for Surface Defects Segmentation under Complex Background
Sep 01, 2024



Despite the eye-catching breakthroughs achieved by deep visual networks in detecting region-level surface defects, the challenge of high-quality pixel-wise defect detection remains due to diverse defect appearances and data scarcity. To avoid over-reliance on defect appearance and achieve accurate defect segmentation, we proposed a change-aware Siamese network that solves the defect segmentation in a change detection framework. A novel multi-class balanced contrastive loss is introduced to guide the Transformer-based encoder, which enables encoding diverse categories of defects as the unified class-agnostic difference between defect and defect-free images. The difference presented by a distance map is then skip-connected to the change-aware decoder to assist in the location of both inter-class and out-of-class pixel-wise defects. In addition, we proposed a synthetic dataset with multi-class liquid crystal display (LCD) defects under a complex and disjointed background context, to demonstrate the advantages of change-based modeling over appearance-based modeling for defect segmentation. In our proposed dataset and two public datasets, our model achieves superior performances than the leading semantic segmentation methods, while maintaining a relatively small model size. Moreover, our model achieves a new state-of-the-art performance compared to the semi-supervised approaches in various supervision settings.
Transformer-based Multimodal Change Detection with Multitask Consistency Constraints
Oct 21, 2023



Change detection plays a fundamental role in Earth observation for analyzing temporal iterations over time. However, recent studies have largely neglected the utilization of multimodal data that presents significant practical and technical advantages compared to single-modal approaches. This research focuses on leveraging digital surface model (DSM) data and aerial images captured at different times for detecting change beyond 2D. We observe that the current change detection methods struggle with the multitask conflicts between semantic and height change detection tasks. To address this challenge, we propose an efficient Transformer-based network that learns shared representation between cross-dimensional inputs through cross-attention. It adopts a consistency constraint to establish the multimodal relationship, which involves obtaining pseudo change through height change thresholding and minimizing the difference between semantic and pseudo change within their overlapping regions. A DSM-to-image multimodal dataset encompassing three cities in the Netherlands was constructed. It lays a new foundation for beyond-2D change detection from cross-dimensional inputs. Compared to five state-of-the-art change detection methods, our model demonstrates consistent multitask superiority in terms of semantic and height change detection. Furthermore, the consistency strategy can be seamlessly adapted to the other methods, yielding promising improvements.
LSNet: Extremely Light-Weight Siamese Network For Change Detection in Remote Sensing Image
Jan 23, 2022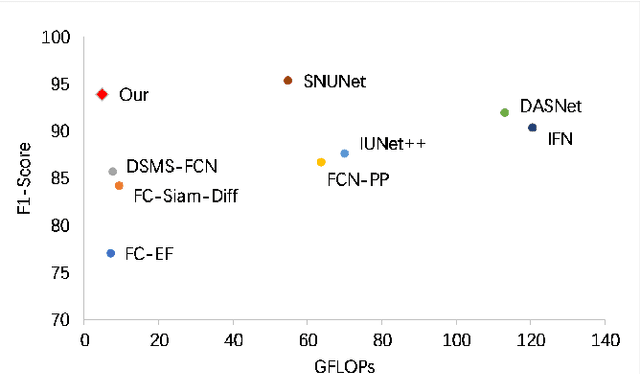
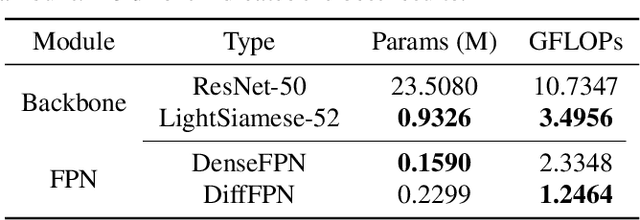
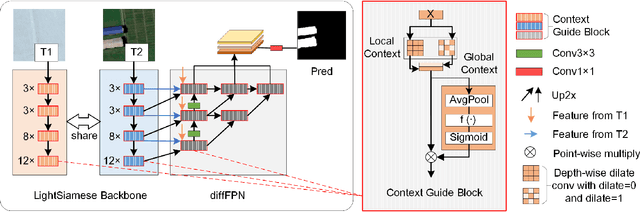
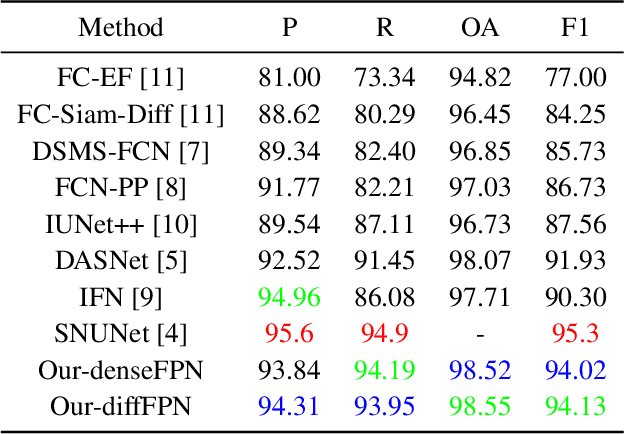
The Siamese network is becoming the mainstream in change detection of remote sensing images (RSI). However, in recent years, the development of more complicated structure, module and training processe has resulted in the cumbersome model, which hampers their application in large-scale RSI processing. To this end, this paper proposes an extremely lightweight Siamese network (LSNet) for RSI change detection, which replaces standard convolution with depthwise separable atrous convolution, and removes redundant dense connections, retaining only valid feature flows while performing Siamese feature fusion, greatly compressing parameters and computation amount. Compared with the first-place model on the CCD dataset, the parameters and the computation amount of LSNet is greatly reduced by 90.35\% and 91.34\% respectively, with only a 1.5\% drops in accuracy.