 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
JIST: Joint Image and Sequence Training for Sequential Visual Place Recognition
Mar 28, 2024
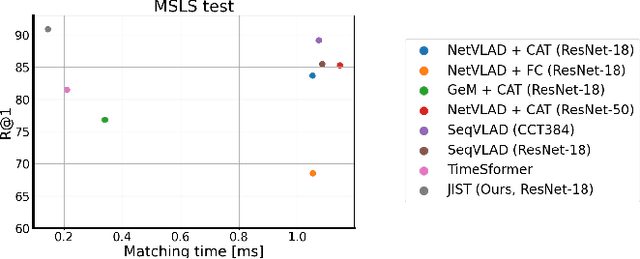
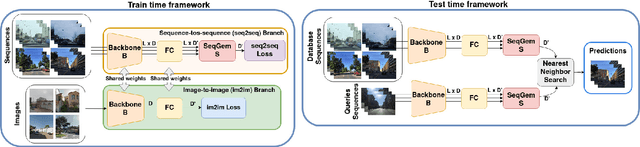
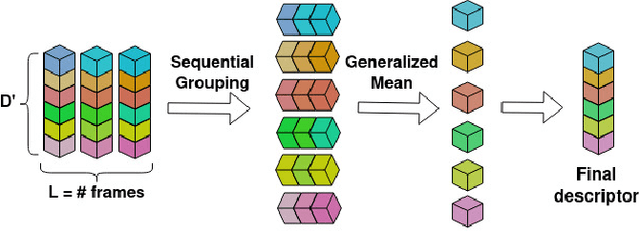
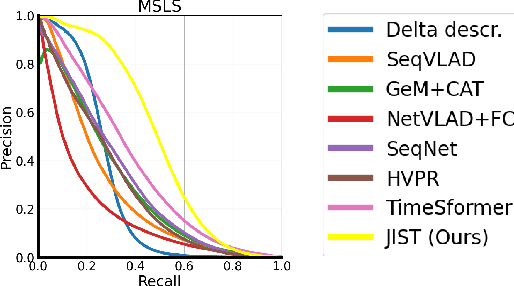
Visual Place Recognition aims at recognizing previously visited places by relying on visual clues, and it is used in robotics applications for SLAM and localization. Since typically a mobile robot has access to a continuous stream of frames, this task is naturally cast as a sequence-to-sequence localization problem. Nevertheless, obtaining sequences of labelled data is much more expensive than collecting isolated images, which can be done in an automated way with little supervision. As a mitigation to this problem, we propose a novel Joint Image and Sequence Training protocol (JIST) that leverages large uncurated sets of images through a multi-task learning framework. With JIST we also introduce SeqGeM, an aggregation layer that revisits the popular GeM pooling to produce a single robust and compact embedding from a sequence of single-frame embeddings. We show that our model is able to outperform previous state of the art while being faster, using 8 times smaller descriptors, having a lighter architecture and allowing to process sequences of various lengths. Code is available at https://github.com/ga1i13o/JIST
Automated Prediction of Breast Cancer Response to Neoadjuvant Chemotherapy from DWI Data
Apr 07, 2024Effective surgical planning for breast cancer hinges on accurately predicting pathological complete response (pCR) to neoadjuvant chemotherapy (NAC). Diffusion-weighted MRI (DWI) and machine learning offer a non-invasive approach for early pCR assessment. However, most machine-learning models require manual tumor segmentation, a cumbersome and error-prone task. We propose a deep learning model employing "Size-Adaptive Lesion Weighting" for automatic DWI tumor segmentation to enhance pCR prediction accuracy. Despite histopathological changes during NAC complicating DWI image segmentation, our model demonstrates robust performance. Utilizing the BMMR2 challenge dataset, it matches human experts in pCR prediction pre-NAC with an area under the curve (AUC) of 0.76 vs. 0.796, and surpasses standard automated methods mid-NAC, with an AUC of 0.729 vs. 0.654 and 0.576. Our approach represents a significant advancement in automating breast cancer treatment planning, enabling more reliable pCR predictions without manual segmentation.
AlignZeg: Mitigating Objective Misalignment for Zero-shot Semantic Segmentation
Apr 08, 2024A serious issue that harms the performance of zero-shot visual recognition is named objective misalignment, i.e., the learning objective prioritizes improving the recognition accuracy of seen classes rather than unseen classes, while the latter is the true target to pursue. This issue becomes more significant in zero-shot image segmentation because the stronger (i.e., pixel-level) supervision brings a larger gap between seen and unseen classes. To mitigate it, we propose a novel architecture named AlignZeg, which embodies a comprehensive improvement of the segmentation pipeline, including proposal extraction, classification, and correction, to better fit the goal of zero-shot segmentation. (1) Mutually-Refined Proposal Extraction. AlignZeg harnesses a mutual interaction between mask queries and visual features, facilitating detailed class-agnostic mask proposal extraction. (2) Generalization-Enhanced Proposal Classification. AlignZeg introduces synthetic data and incorporates multiple background prototypes to allocate a more generalizable feature space. (3) Predictive Bias Correction. During the inference stage, AlignZeg uses a class indicator to find potential unseen class proposals followed by a prediction postprocess to correct the prediction bias. Experiments demonstrate that AlignZeg markedly enhances zero-shot semantic segmentation, as shown by an average 3.8% increase in hIoU, primarily attributed to a 7.1% improvement in identifying unseen classes, and we further validate that the improvement comes from alleviating the objective misalignment issue.
CDAD-Net: Bridging Domain Gaps in Generalized Category Discovery
Apr 08, 2024In Generalized Category Discovery (GCD), we cluster unlabeled samples of known and novel classes, leveraging a training dataset of known classes. A salient challenge arises due to domain shifts between these datasets. To address this, we present a novel setting: Across Domain Generalized Category Discovery (AD-GCD) and bring forth CDAD-NET (Class Discoverer Across Domains) as a remedy. CDAD-NET is architected to synchronize potential known class samples across both the labeled (source) and unlabeled (target) datasets, while emphasizing the distinct categorization of the target data. To facilitate this, we propose an entropy-driven adversarial learning strategy that accounts for the distance distributions of target samples relative to source-domain class prototypes. Parallelly, the discriminative nature of the shared space is upheld through a fusion of three metric learning objectives. In the source domain, our focus is on refining the proximity between samples and their affiliated class prototypes, while in the target domain, we integrate a neighborhood-centric contrastive learning mechanism, enriched with an adept neighborsmining approach. To further accentuate the nuanced feature interrelation among semantically aligned images, we champion the concept of conditional image inpainting, underscoring the premise that semantically analogous images prove more efficacious to the task than their disjointed counterparts. Experimentally, CDAD-NET eclipses existing literature with a performance increment of 8-15% on three AD-GCD benchmarks we present.
Towards Efficient and Accurate CT Segmentation via Edge-Preserving Probabilistic Downsampling
Apr 05, 2024Downsampling images and labels, often necessitated by limited resources or to expedite network training, leads to the loss of small objects and thin boundaries. This undermines the segmentation network's capacity to interpret images accurately and predict detailed labels, resulting in diminished performance compared to processing at original resolutions. This situation exemplifies the trade-off between efficiency and accuracy, with higher downsampling factors further impairing segmentation outcomes. Preserving information during downsampling is especially critical for medical image segmentation tasks. To tackle this challenge, we introduce a novel method named Edge-preserving Probabilistic Downsampling (EPD). It utilizes class uncertainty within a local window to produce soft labels, with the window size dictating the downsampling factor. This enables a network to produce quality predictions at low resolutions. Beyond preserving edge details more effectively than conventional nearest-neighbor downsampling, employing a similar algorithm for images, it surpasses bilinear interpolation in image downsampling, enhancing overall performance. Our method significantly improved Intersection over Union (IoU) to 2.85%, 8.65%, and 11.89% when downsampling data to 1/2, 1/4, and 1/8, respectively, compared to conventional interpolation methods.
Shadow Generation for Composite Image Using Diffusion model
Mar 22, 2024In the realm of image composition, generating realistic shadow for the inserted foreground remains a formidable challenge. Previous works have developed image-to-image translation models which are trained on paired training data. However, they are struggling to generate shadows with accurate shapes and intensities, hindered by data scarcity and inherent task complexity. In this paper, we resort to foundation model with rich prior knowledge of natural shadow images. Specifically, we first adapt ControlNet to our task and then propose intensity modulation modules to improve the shadow intensity. Moreover, we extend the small-scale DESOBA dataset to DESOBAv2 using a novel data acquisition pipeline. Experimental results on both DESOBA and DESOBAv2 datasets as well as real composite images demonstrate the superior capability of our model for shadow generation task. The dataset, code, and model are released at https://github.com/bcmi/Object-Shadow-Generation-Dataset-DESOBAv2.
Fill in the ____ (a Diffusion-based Image Inpainting Pipeline)
Mar 24, 2024Image inpainting is the process of taking an image and generating lost or intentionally occluded portions. Inpainting has countless applications including restoring previously damaged pictures, restoring the quality of images that have been degraded due to compression, and removing unwanted objects/text. Modern inpainting techniques have shown remarkable ability in generating sensible completions for images with mask occlusions. In our paper, an overview of the progress of inpainting techniques will be provided, along with identifying current leading approaches, focusing on their strengths and weaknesses. A critical gap in these existing models will be addressed, focusing on the ability to prompt and control what exactly is generated. We will additionally justify why we think this is the natural next progressive step that inpainting models must take, and provide multiple approaches to implementing this functionality. Finally, we will evaluate the results of our approaches by qualitatively checking whether they generate high-quality images that correctly inpaint regions with the objects that they are instructed to produce.
Responsible Visual Editing
Apr 08, 2024With recent advancements in visual synthesis, there is a growing risk of encountering images with detrimental effects, such as hate, discrimination, or privacy violations. The research on transforming harmful images into responsible ones remains unexplored. In this paper, we formulate a new task, responsible visual editing, which entails modifying specific concepts within an image to render it more responsible while minimizing changes. However, the concept that needs to be edited is often abstract, making it challenging to locate what needs to be modified and plan how to modify it. To tackle these challenges, we propose a Cognitive Editor (CoEditor) that harnesses the large multimodal model through a two-stage cognitive process: (1) a perceptual cognitive process to focus on what needs to be modified and (2) a behavioral cognitive process to strategize how to modify. To mitigate the negative implications of harmful images on research, we create a transparent and public dataset, AltBear, which expresses harmful information using teddy bears instead of humans. Experiments demonstrate that CoEditor can effectively comprehend abstract concepts within complex scenes and significantly surpass the performance of baseline models for responsible visual editing. We find that the AltBear dataset corresponds well to the harmful content found in real images, offering a consistent experimental evaluation, thereby providing a safer benchmark for future research. Moreover, CoEditor also shows great results in general editing. We release our code and dataset at https://github.com/kodenii/Responsible-Visual-Editing.
Enhancing Ship Classification in Optical Satellite Imagery: Integrating Convolutional Block Attention Module with ResNet for Improved Performance
Apr 08, 2024This study presents an advanced Convolutional Neural Network (CNN) architecture for ship classification from optical satellite imagery, significantly enhancing performance through the integration of the Convolutional Block Attention Module (CBAM) and additional architectural innovations. Building upon the foundational ResNet50 model, we first incorporated a standard CBAM to direct the model's focus towards more informative features, achieving an accuracy of 87% compared to the baseline ResNet50's 85%. Further augmentations involved multi-scale feature integration, depthwise separable convolutions, and dilated convolutions, culminating in the Enhanced ResNet Model with Improved CBAM. This model demonstrated a remarkable accuracy of 95%, with precision, recall, and f1-scores all witnessing substantial improvements across various ship classes. The bulk carrier and oil tanker classes, in particular, showcased nearly perfect precision and recall rates, underscoring the model's enhanced capability in accurately identifying and classifying ships. Attention heatmap analyses further validated the improved model's efficacy, revealing a more focused attention on relevant ship features, regardless of background complexities. These findings underscore the potential of integrating attention mechanisms and architectural innovations in CNNs for high-resolution satellite imagery classification. The study navigates through the challenges of class imbalance and computational costs, proposing future directions towards scalability and adaptability in new or rare ship type recognition. This research lays a groundwork for the application of advanced deep learning techniques in the domain of remote sensing, offering insights into scalable and efficient satellite image classification.
No "Zero-Shot" Without Exponential Data: Pretraining Concept Frequency Determines Multimodal Model Performance
Apr 08, 2024Web-crawled pretraining datasets underlie the impressive "zero-shot" evaluation performance of multimodal models, such as CLIP for classification/retrieval and Stable-Diffusion for image generation. However, it is unclear how meaningful the notion of "zero-shot" generalization is for such multimodal models, as it is not known to what extent their pretraining datasets encompass the downstream concepts targeted for during "zero-shot" evaluation. In this work, we ask: How is the performance of multimodal models on downstream concepts influenced by the frequency of these concepts in their pretraining datasets? We comprehensively investigate this question across 34 models and five standard pretraining datasets (CC-3M, CC-12M, YFCC-15M, LAION-400M, LAION-Aesthetics), generating over 300GB of data artifacts. We consistently find that, far from exhibiting "zero-shot" generalization, multimodal models require exponentially more data to achieve linear improvements in downstream "zero-shot" performance, following a sample inefficient log-linear scaling trend. This trend persists even when controlling for sample-level similarity between pretraining and downstream datasets, and testing on purely synthetic data distributions. Furthermore, upon benchmarking models on long-tailed data sampled based on our analysis, we demonstrate that multimodal models across the board perform poorly. We contribute this long-tail test set as the "Let it Wag!" benchmark to further research in this direction. Taken together, our study reveals an exponential need for training data which implies that the key to "zero-shot" generalization capabilities under large-scale training paradigms remains to be found.